

图像到视频生成(I2V)任务是计算机视觉领域的一项挑战,旨在将静态图像转化为动态视频。这个任务的难点在于从单张图像中提取并生成时间维度的动态信息,同时保持图像内容的真实性和视觉上的连贯性。现有的I2V方法通常需要复杂的模型架构和大量的训练数据来实现这一目标。
近期,快手主导的一项新研究成果《I2V-Adapter: A General Image-to-Video Adapter for Video Diffusion Models》发布。该研究引入了一种创新的图像到视频转换方法,提出了一种轻量级适配器模块,即I2V-Adapter。该适配器模块能够在不改变现有文本到视频生成(T2V)模型原始结构和预训练参数的情况下,将静态图像转换成动态视频。这一方法在图像到视频转换领域具有广泛的应用前景,能够为视频创作、媒体传播等领域带来更多可能性。该研究结果的发布对于推动图像和视频技术的发展具有重要意义,为相关领域的研究者提供了一种有效的工具和方法。

相对于现有方法而言,I2V-Adapter在可训练参数方面取得了巨大的改进,其参数数量最低可达到22M,仅为主流方案Stable Video Diffusion的1%。同时,该适配器还具备与Stable Diffusion社区开发的定制化T2I模型(如DreamBooth、Lora)和控制工具(如ControlNet)的兼容性。通过实验,研究者证明了I2V-Adapter在生成高质量视频内容方面的有效性,为I2V领域的创意应用开辟了新的可能性。

Temporal modeling with Stable Diffusion
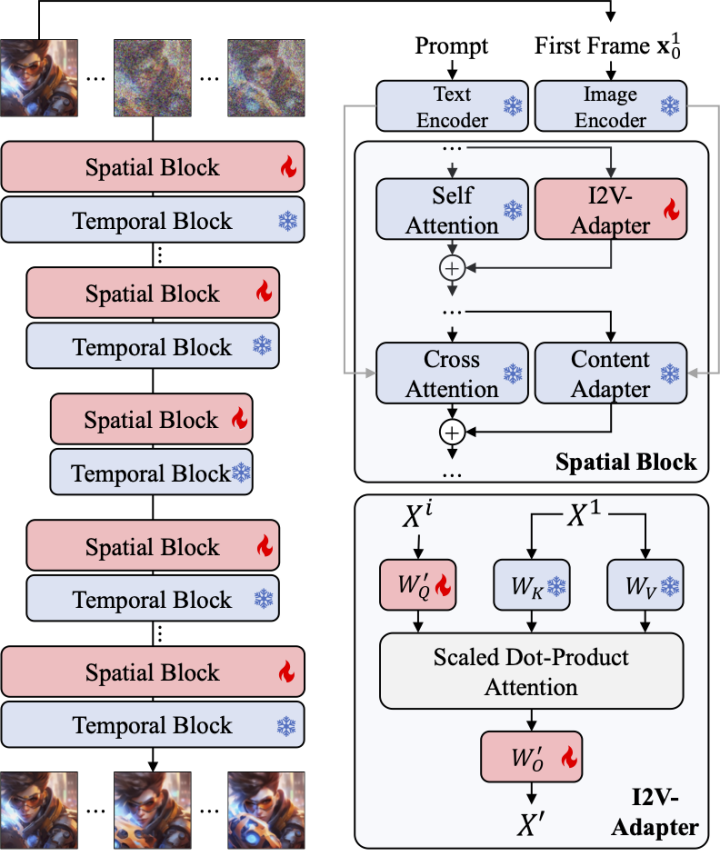
相较于图像生成,视频生成面临着独特的挑战,即建模视频帧之间的时序连贯性。目前的大多数方法都是基于预训练的T2I模型,例如Stable Diffusion和SDXL,通过引入时序模块对视频中的时序信息进行建模。受到AnimateDiff的启发,这是一个最初设计用于定制化T2V任务的模型,它通过引入与T2I模型解耦的时序模块来建模时序信息,并保留了原始T2I模型的能力,能够生成流畅的视频。因此,研究者认为预训练的时序模块可以被视为通用的时序表征,并可以应用于其他视频生成场景,如I2V生成,而无需进行任何微调。因此,研究者直接使用预训练的AnimateDiff时序模块,并保持其参数固定。
Adapter for attention layers
I2V任务中的另一个挑战是保持输入图像的ID信息。目前的解决方案主要有两种:一种是使用预训练的图像编码器对输入图像进行编码,并通过交叉关注机制将编码后的特征注入到模型中以指导去噪过程;另一种是将图像与有噪声的输入在通道维度上进行拼接,然后一起输入到后续的网络中。然而,前一种方法由于图像编码器难以捕捉底层信息,可能导致生成的视频ID发生变化;而后一种方法往往需要改变T2I模型的结构和参数,训练代价高且兼容性较差。
为了解决上述问题,研究者提出了 I2V-Adapter。具体来说,研究者将输入图像与 noised input 并行输入给网络,在模型的 spatial block 中,所有帧都会额外查询一次首帧信息,即 key,value 特征都来自于不加噪的首帧,输出结果与原始模型的 self attention 相加。此模块中的输出映射矩阵使用零初始化并且只训练输出映射矩阵与 query 映射矩阵。为了进一步加强模型对输入图像语义信息的理解,研究者引入了预训练的 content adapter(本文使用的是 IP-Adapter [8])注入图像的语义特征。
Frame Similarity Prior
为了进一步增强生成结果的稳定性,研究者提出了帧间相似性先验,用于在生成视频的稳定性和运动强度之间取得平衡。其关键假设是,在相对较低的高斯噪声水平上,带噪声的第一帧和带噪声的后续帧足够接近,如下图所示:
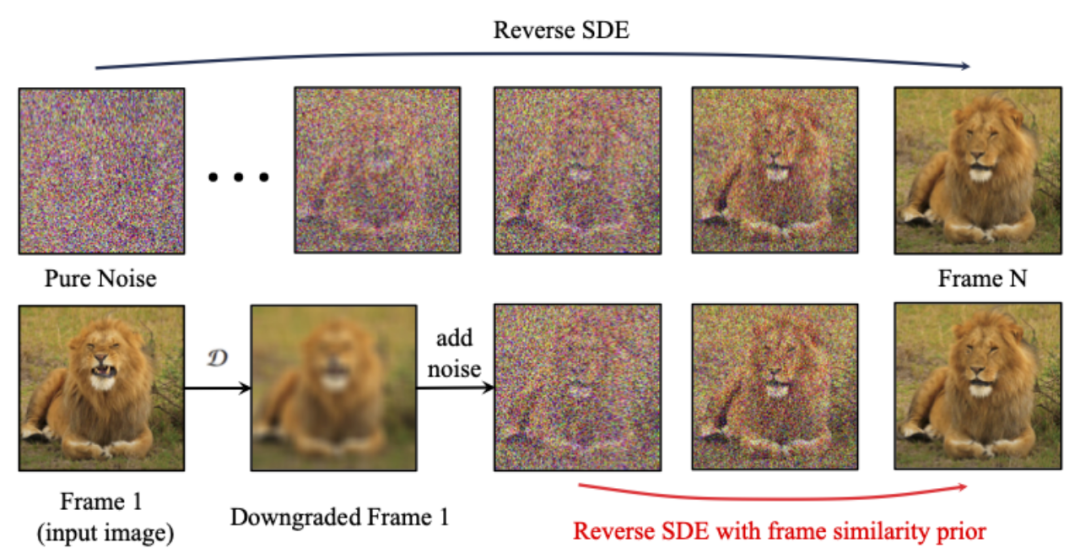
于是,研究者假设所有帧结构相似,并在加入一定量的高斯噪声后变得难以区分,因此可以把加噪后的输入图像作为后续帧的先验输入。为了排除高频信息的误导,研究者还使用了高斯模糊算子和随机掩码混合。具体来说,运算由下式给出:

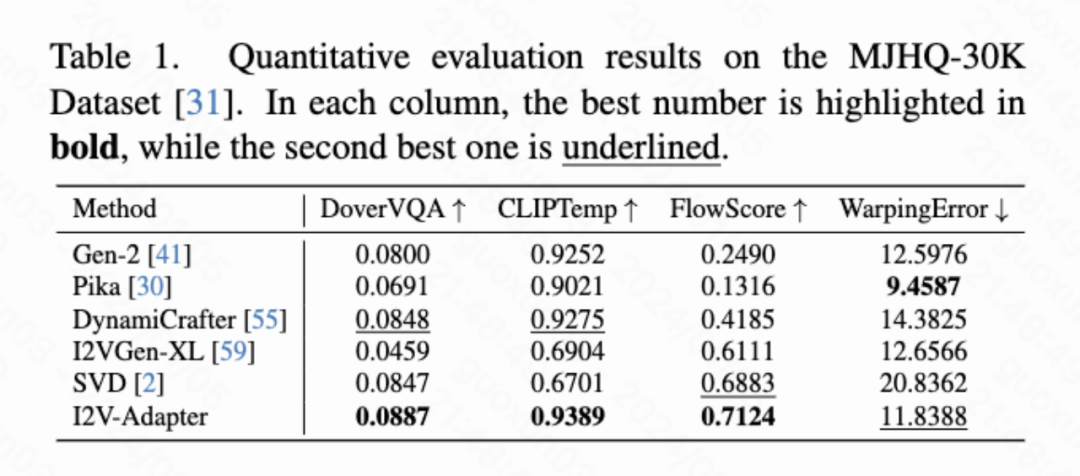
定量结果
本文计算了四种定量指标分别是 DoverVQA (美学评分)、CLIPTemp (首帧一致性)、FlowScore (运动幅度) 以及 WarppingError (运动误差) 用于评价生成视频的质量。表 1 显示 I2V-Adapter 得到了最高的美学评分,在首帧一致性上也超过了所有对比方案。此外,I2V-Adapter 生成的视频有着最大的运动幅度,并且相对较低的运动误差,表明此模型的能够生成更加动态的视频并且同时保持时序运动的准确性。
定性结果
Image Animation(左为输入,右为输出):



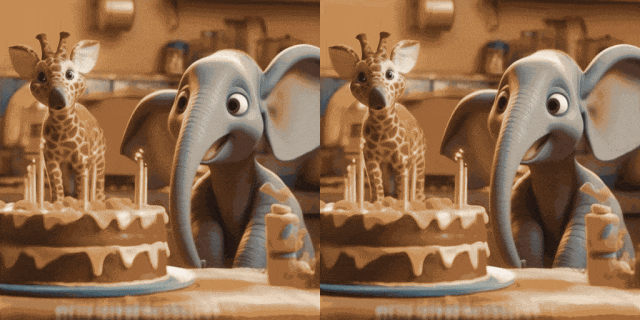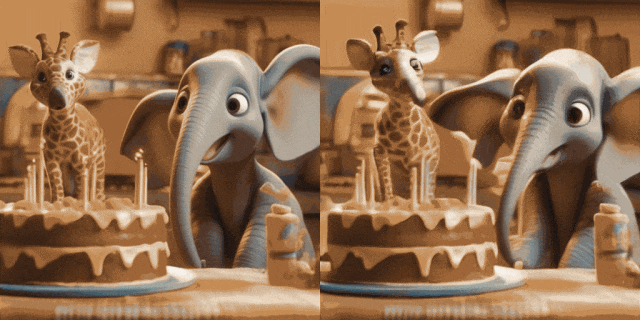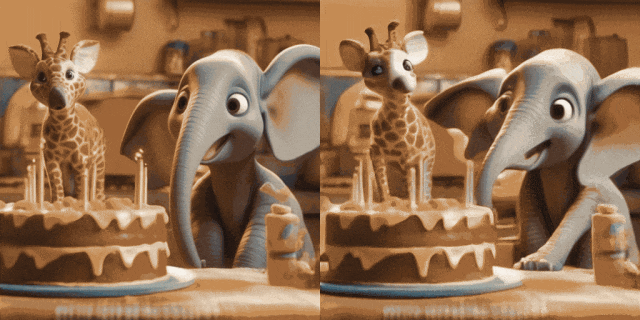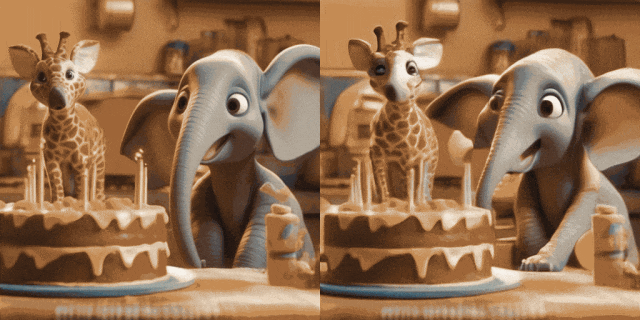
w/ Personalized T2Is(左为输入,右为输出):




w/ ControlNet(左为输入,右为输出):



本文提出了 I2V-Adapter,一种即插即用的轻量级模块,用于图像到视频生成任务。该方法保留原始 T2V 模型的 spatial block 与 motion block 结构与参数固定,并行输入不加噪的第一帧与加噪的后续帧,通过注意力机制允许所有帧与无噪声的第一帧交互,从而产生时序连贯且与首帧一致的视频。研究者们通过定量与定性实验证明了该方法在 I2V 任务上的有效性。此外,其解耦设计使得该方案能够直接结合 DreamBooth、Lora 与 ControlNet 等模块,证明了该方案的兼容性,也促进了定制化与可控图像到视频生成的研究。
以上是SD社区的I2V-Adapter:无需配置,即插即用,完美兼容图生视频插件的详细内容。更多信息请关注PHP中文网其他相关文章!





















