

这几天,家务活都被机器人抢着干了。
前脚来自斯坦福的会用锅的机器人刚刚登场,后脚又来了个会用咖啡机的机器人 Figure-01 。

Figure-01只需观看示范视频,再进行10小时的训练,就能熟练操作咖啡机。从放入咖啡胶囊到按下启动键,一气呵成。
然而,要使机器人能够独立学会使用各种家具和家电,遇到它们时不需要示范视频,这是一个难以解决的问题。这需要机器人具备强大的视觉感知和决策规划能力,以及精确的操纵技能。

论文链接:https://arxiv.org/abs/2312.01307
项目主页:https://geometry.stanford.edu/projects/sage/
代码:https://github.com/geng-haoran/SAGE
研究问题概述

图 1:根据人类指令,机械臂能够无师自通地使用各种家用电器。
近日,PaLM-E 和 GPT-4V 带动了图文大模型在机器人任务规划中的应用,视觉语言引导下的泛化机器人操控成为了热门研究领域。
以往的常见方法是建立一个两层的系统,上层的图文大模型做规划和技能调度,下层的操控技能策略模型负责物理地执行动作。但当机器人在家务活中面对各种各样从未见过并且需要多步操作的家用电器时,现有方法中的上下两层都将束手无策。
以目前最先进的图文大模型 GPT-4V 为例,虽然它可以对单张图片进行文字描述,但涉及可操作零部件检测、计数、定位及状态估计时,它仍然错误百出。图二中的红色高亮部分是 GPT-4V 在描述抽屉柜、烤箱和立柜的图片时出现的各种错误。基于错误的描述,机器人再进行技能调度,显然不太可靠。

图 2:GPT-4V 不能很好处理计数,检测,定位,状态估计等泛化操控所关注的任务。
下层的操控技能策略模型负责在各种各样的实际情况中执行上层图文大模型给出的任务。现有的研究成果大部分是基于规则生硬地对一些已知物体的抓取点位和操作方式进行了编码,无法泛应对没见过的新物体类别。而基于端到端的操作模型(如 RT-1,RT-2 等)只使用了 RGB 模态,缺乏对距离的准确感知,对新环境中如高度等变化的泛化性较差。
受王鹤教授团队之前的 CVPR Highlight 工作 GAPartNet [1] 启迪,研究团队将重点放在了各种类别的家用电器中的通用零部件(GAPart)之上。虽然家用电器千变万化,但总有几样零件不可或缺,每个家电和这些通用的零件之间存在相似的几何和交互模式。
由此,研究团队在 GAPartNet [1] 这篇论文中引入了 GAPart 这一概念。GAPart 指可泛化可交互的零部件。GAPart 出现在不同类别的铰接物体上,例如,在保险箱,衣柜,冰箱中都能找到铰接门这种零件。如图 3,GAPartNet [1] 在各类物体上标注了 GAPart 的语义和位姿。

图3:GAPart:可泛化可交互的零部件[1]。
在之前研究的基础上,研究团队创造性地将基于三维视觉的 GAPart 引入了机器人的物体操控系统 SAGE 。SAGE 将通过可泛化的三维零件检测 (part detection),精确的位姿估计 (pose estimation) 为 VLM 和 LLM 提供信息。新方法在决策层解决了二维图文模型精细计算和推理能力不足的问题;在执行层,新方法通过基于 GAPart 位姿的鲁棒物理操作 API 实现了对各个零件的泛化性操作。
SAGE 构成了首个三维具身图文大模型系统,为机器人从感知、物理交互再到反馈的全链路提供了新思路,为机器人能够智能、通用地操控家具家电等复杂物体探寻了一条可行的道路。
系统介绍
图 4 展示了 SAGE 的基本流程。首先,一个能够解读上下文的指令解释模块将解析输入机器人的指令和其观察结果,将这些解析转化为下一步机器人动作程序以及与其相关的语义部分。接下来,SAGE 将语义部分(如容器 container)与需要进行操作部分(如滑动按钮 slider button)对应起来,并生成动作(如按钮的 「按压 press」 动作)来完成任务。

图 4:方法概览。
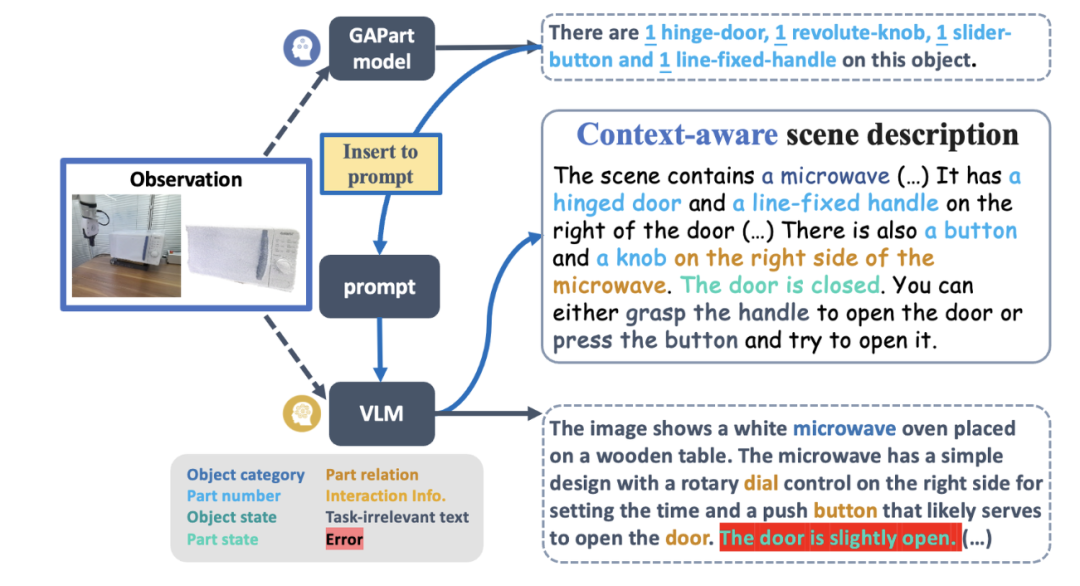
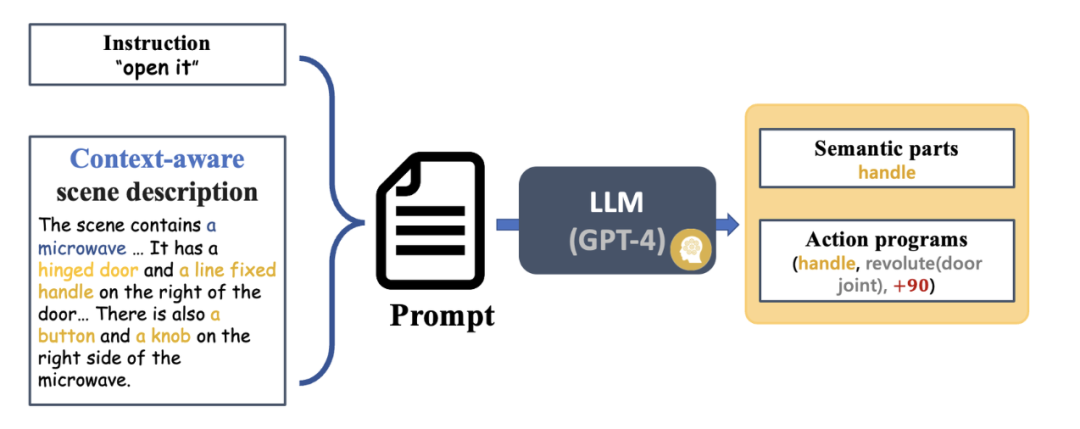
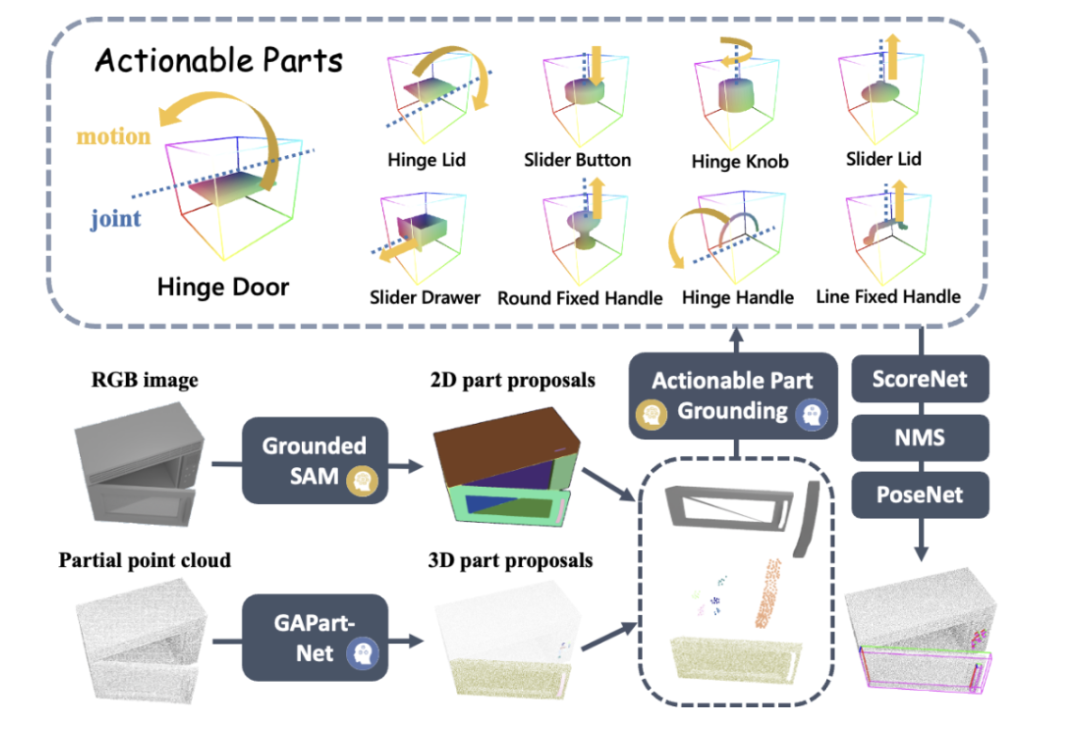



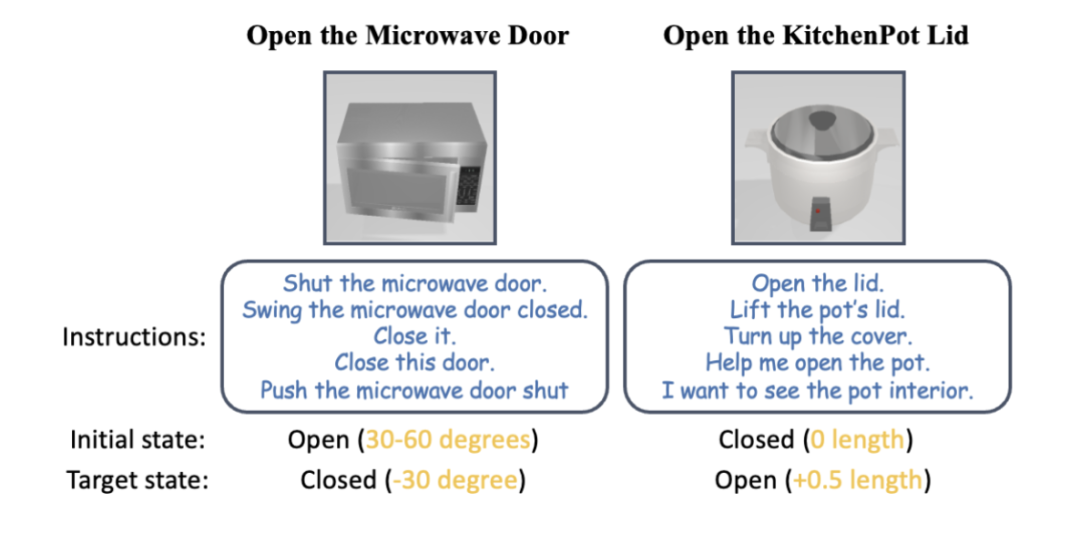
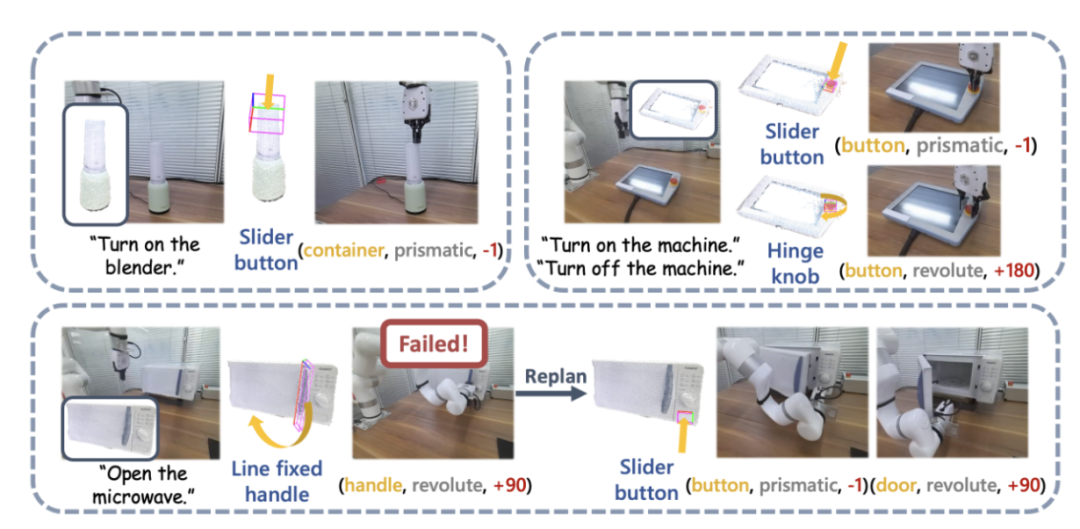
图 12:真机演示。
研究团队同时也进行了大规模真实世界实验,他们使用 UFACTORY xArm 6 和多种不同的铰接物体进行操作。上图的左上部分展示了一个启动搅拌器的案例。搅拌器的顶部被感知为一个用于装果汁的容器,但其实际功能需要按下一个按钮来开启。 SAGE 的框架有效地连接了其语义和动作理解,并成功执行了任务。
上图右上部分展示了机器人,需要按下(下压)紧急停止按钮来停止操作,旋转(向上)来重启。借助用户手册的辅助输入,在 SAGE 指导下的机械臂完成了这两个任务。上图底部的图片展示了开启微波炉任务中的更多细节。

图 13:更多真机演示和指令解读示例。
总结
团队介绍
SAGE 这一研究成果来自斯坦福大学 Leonidas Guibas 教授实验室、北京大学王鹤教授具身感知和交互(EPIC Lab)以及智源人工智能研究院。论文的作者为北京大学学生、斯坦福大学访问学者耿浩然(共同一作)、北京大学博士生魏松林(共同一作)、斯坦福大学博士生邓丛悦,沉博魁,指导老师为 Leonidas Guibas 教授和王鹤教授。
参考文献:
[1] Haoran Geng,Helin Xu,Chengyang Zhao,Chao Xu,Li Yi,Siyuan Huang,and He Wang。 Gapartnet: Cross-category domaingeneralizable object perception and manipulation via generalizable and actionable parts。 arXiv preprint arXiv:2211.05272,2022.
[2] Kirillov,Alexander,Eric Mintun,Nikhila Ravi,Hanzi Mao,Chloe Rolland,Laura Gustafson,Tete Xiao et al。 "Segment anything." arXiv preprint arXiv:2304.02643 (2023).
[3] 张,Hao,Feng Li,Shilong Liu,Lei Zhang,Hang Su,Jun Zhu,Lionel M.Ni,and Heung-Yeung Shum。”Dino:采用改进的去噪锚框进行端到端的 Detr终端物体检测。” arXiv 预印本 arXiv:2203.03605 (2022).
[4] 项翔,范博,秦宇哲,莫凯春,夏一宽,朱浩,刘芳辰,刘明华等人。《Sapien:一种基于部件的模拟》互动环境。” IEEE/CVF 计算机视觉与模式识别会议论文集,pp。11097-11107。2020.
以上是家具家电通用三维图文大模型系统中的首创无需指导、泛化使用形象化模型的详细内容。更多信息请关注PHP中文网其他相关文章!





















