

时序融合是提升自动驾驶3D目标检测感知能力的有效途径,但目前的方法在实际自动驾驶场景中应用存在成本开销等问题。最新研究文章《基于查询的显式运动时序融合用于3D目标检测》在NeurIPS 2023中提出了一种新的时序融合方法,将稀疏查询作为时序融合的对象,并利用显式运动信息来生成时序注意力矩阵,以适应大规模点云的特性。该方法由华中科技大学和百度的研究者提出,被称为QTNet:基于查询和显式运动的3D目标检测时序融合方法。实验证明,QTNet能够在几乎没有成本开销的情况下为点云、图像和多模态检测器带来一致的性能提升

得益于现实世界的时间连续性,时间维度上的信息可以使得感知信息更加完备,进而提高目标检测的精度和鲁棒性,例如时序信息可以帮助解决目标检测中的遮挡问题、提供目标的运动状态和速度信息、提供目标的持续性和一致性信息。因此如何高效地利用时序信息是自动驾驶感知的一个重要问题。现有的时序融合方法主要分为两类。一类是基于稠密的BEV特征进行时序融合(点云/图像时序融合都适用),另一类则是基于3D Proposal特征进行时序融合 (主要针对点云时序融合方法)。对于基于BEV特征的时序融合,由于BEV上超过90%的点都是背景,而该类方法没有更多地关注前景对象,这导致了大量没有必要的计算开销和次优的性能。对于基于3D Proposal的时序融合算法,其通过耗时的3D RoI Pooling来生成3D Proposal特征,尤其是在目标物较多,点云数量较多的情况下,3D RoI Pooling所带来的开销在实际应用中往往是难以接受的。此外,3D Proposal 特征严重依赖于Proposal的质量,这在复杂场景中往往是受限的。因此,目前的方法都难以以极低开销的方式高效地引入时序融合来增强3D目标检测的性能。
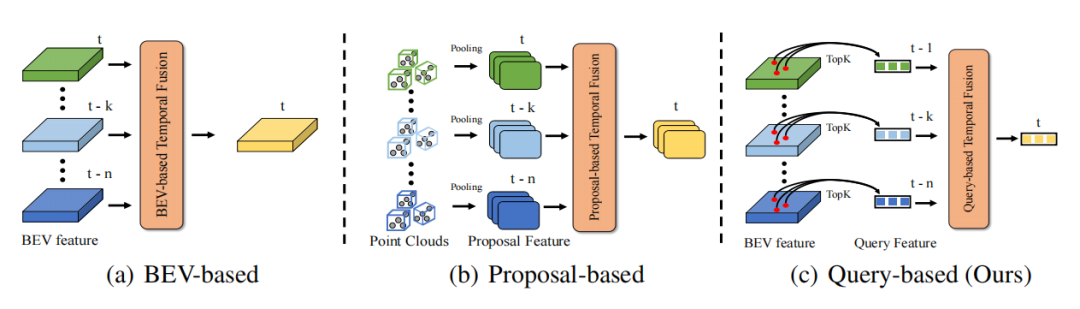
DETR是一种十分优秀的目标检测范式,其提出的Query设计和Set Prediction思想有效地实现了无需任何后处理的优雅检测范式。在DETR中,每个Query代表一个物体,并且Query相对于稠密的特征来说十分稀疏(一般Query的数目会被设置为一个相对较少的固定数目)。如果以Quey作为时序融合的对象,那计算开销的问题自然下降一个层次。因此DETR的Query范式是一种天然适合于时序融合的范式。时序融合需要构建多帧之间的物体关联,以此实现时序上下文信息的综合。那么主要问题在于如何构建基于Query的时序融合pipeline和两帧间的Query建立关联。
QTNet的核心思想是利用Memory Bank存储在历史帧中获得的Query特征及其对应的检测结果,以避免重复计算历史帧的开销。在两帧Query之间,使用运动引导的注意力矩阵进行关系建模
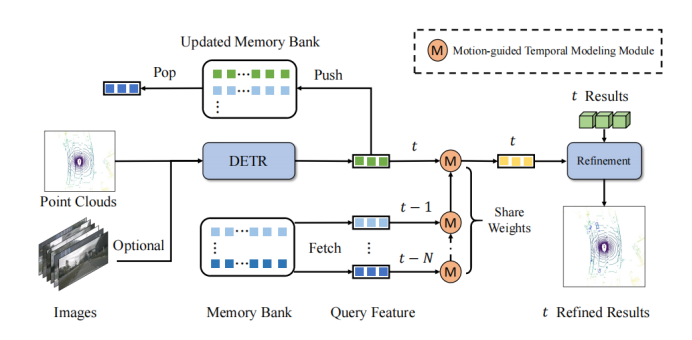
如框架图所示,QTNet包含3D DETR结构的3D目标检测器(LiDAR、Camera和多模态均可),Memory Bank和用于时序融合的Motion-guided Temporal Modeling Module (MTM)。QTNet通过DETR结构的3D目标检测器获取对应帧的Query特征及其检测结果,并将得到的Query特征及其检测结果以先进先出队列(FIFO)的方式送入Memory Bank中。Memory Bank的数目设置为时序融合所需的帧数。对于时序融合,QTNet从Memory Bank中从最远时刻开始读取数据,通过MTM模块以迭代的方式从帧到帧融合MemoryBank中的所有特征以用来增强当前帧的Query特征,并根据增强后的Query特征来Refine对应的当前帧的检测结果。
具体而言,QTNet在帧融合和帧的Query特征和,并得到增强后的帧的Query特征。接着,QTNet再将与帧的Query特征进行融合。以此通过迭代的方式不断融合至帧。注意,这里从帧到帧所使用的MTM全部是共享参数的。
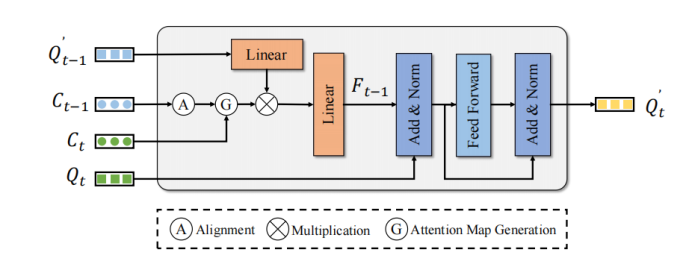
MTM使用物体的中心点位置来显式生成帧Query和帧Query的注意力矩阵。给定ego pose矩阵和、物体中心点、速度。首先,MTM使用ego pose和物体预测的速度信息将上一帧的物体移动到下一帧并对齐两帧的坐标系:
接着通过帧物体中心点和帧经过矫正的中心点构建欧式代价矩阵。此外,为了避免可能发生的错误匹配,本文使用类别和距离阈值构造注意力掩码:
将代价矩阵转换成注意力矩阵是最终目标
将注意力矩阵作用在帧的增强后的Query特征来聚合时序特征以增强帧的Query特征:
最终增强后的帧的Query特征经过简单的FFN来Refine对应的检测结果,以实现增强检测性能的作用。
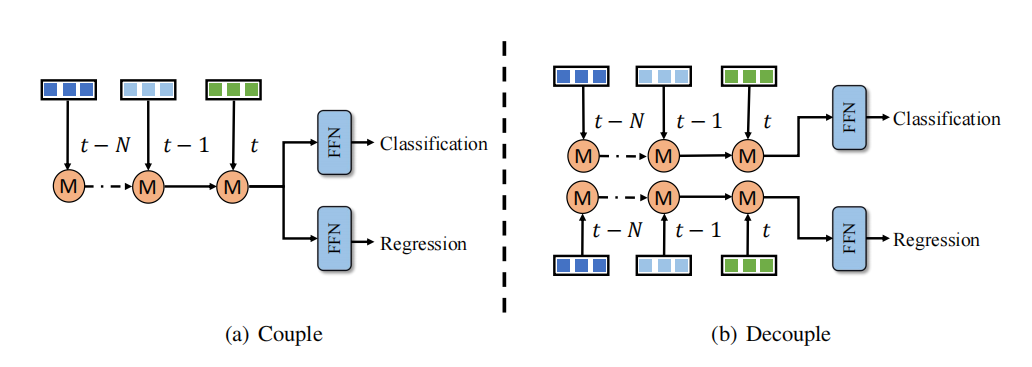
观察到时序融合的分类和回归学习存在不平衡问题,一种解决办法是分别为分类和回归设计时序融合分支。然而,这种解耦方式会增加更多的计算成本和延迟,对于大多数方法而言不可接受。相比之下,QTNet利用高效的时序融合设计,其计算成本和延迟可以忽略不计,与整个3D检测网络相比表现更优。因此,本文采取了分类和回归分支在时序融合上的解耦方式,以在可忽略不计的成本情况下取得更好的检测性能,如图所示
QTNet在点云/图像/多模态上实现一致涨点
在nuScenes数据集上进行验证后发现,QTNet在不使用未来信息、TTA和模型集成的情况下,取得了68.4的mAP和72.2的NDS,达到了SOTA性能。与使用了未来信息的MGTANet相比,在3帧时序融合的情况下,QTNet的性能优于MGTANet,分别提高了3.0的mAP和1.0的NDS
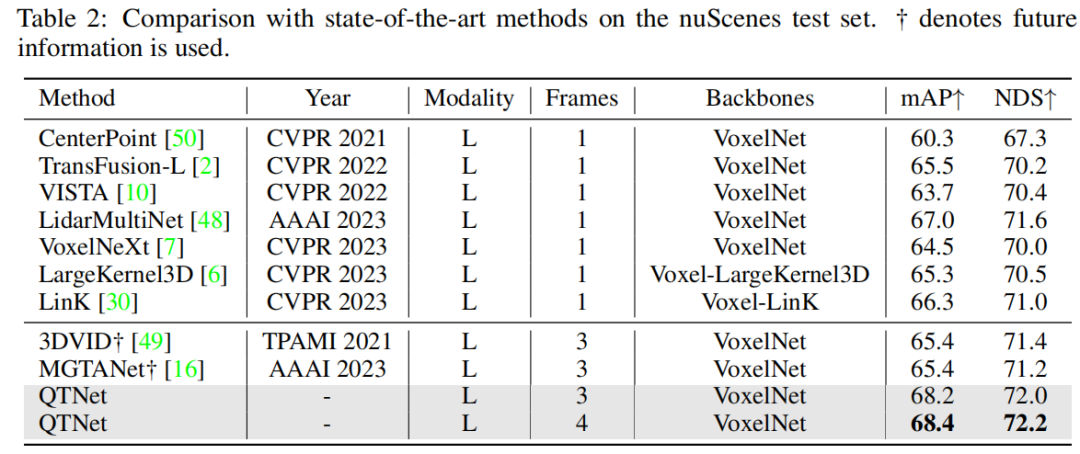
此外,本文也在多模态和基于环视图的方法上进行了验证,在nuScenes验证集上的实验结果证明了QTNet在不同模态上的有效性。
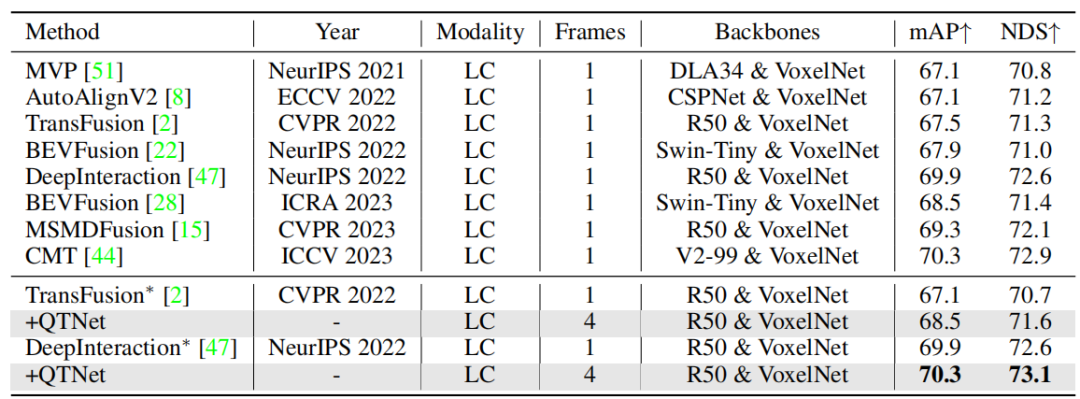

对于实际应用来说,时序融合的成本开销非常重要。本文对QTNet在计算量、时延和参数量三个方面进行了分析实验。结果表明,与整个网络相比,QTNet对于不同基准线所带来的计算开销、时间延迟和参数量都可以忽略不计,尤其是计算量仅仅使用了0.1G FLOPs(LiDAR基准线)
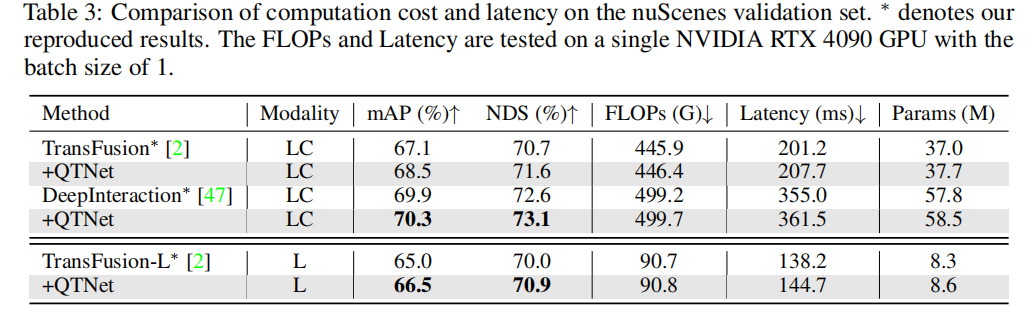
为了验证基于Query的时序融合范式的优越性,我们选择了具有代表性的不同前沿时序融合方法进行比较。通过实验结果发现,基于Query范式的时序融合算法相较于基于BEV和基于Proposal范式更加高效。在仅使用0.1G FLOPs和4.5ms的开销下,QTNet表现出更加优秀的性能,同时整体参数量仅为0.3M
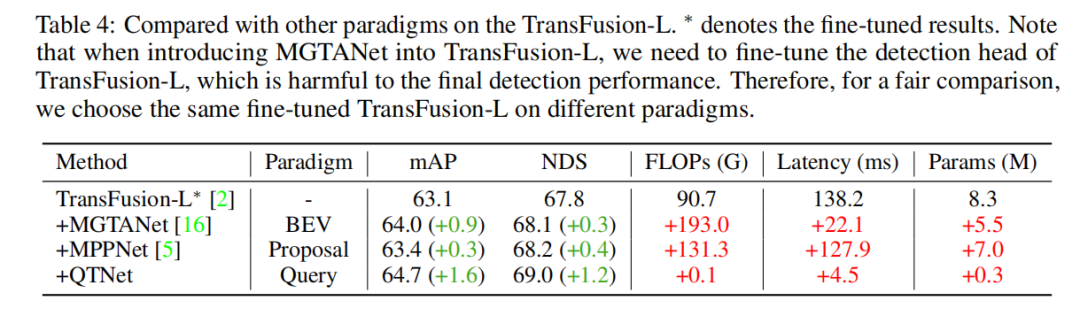
本研究在nuScenes验证集上进行了基于LiDAR baseline的消融实验,通过3帧时序融合的方式。实验结果表明,简单地使用Cross Attention来建模时序关系并没有明显的效果。然而,当使用MTM后,检测性能显著提升,这说明在大规模点云下显式运动引导的重要性。此外,通过消融实验还发现,QTNet的整体设计非常轻量且高效。在使用4帧数据进行时序融合时,QTNet的计算量仅为0.24G FLOPs,延迟也只有6.5毫秒
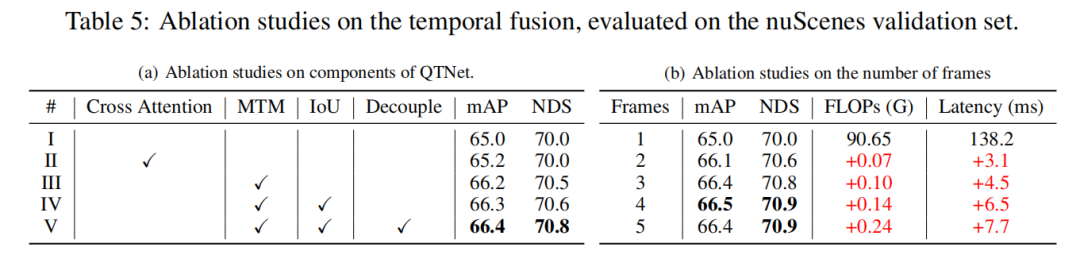
为了探究MTM优于Cross Attention的原因,本文将两帧间物体的注意力矩阵进行可视化,其中相同的ID代表两帧间同一个物体。可以发现由MTM生成的注意力矩阵(b)比Cross Attention生成的注意力矩阵(a)更加具有区分度,尤其是小物体之间的注意力矩阵。这表明由显式运动引导的注意力矩阵通过物理建模的方式使得模型更加容易地建立起两帧间物体的关联。本文仅仅只是初步探索了在时序融合中以物理方式建立时序关联问题,对于如何更好构建时序关联仍然是值得探索的。
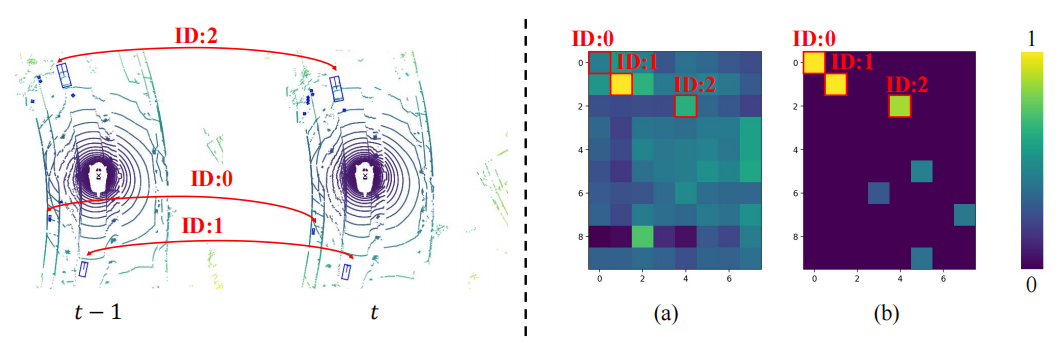
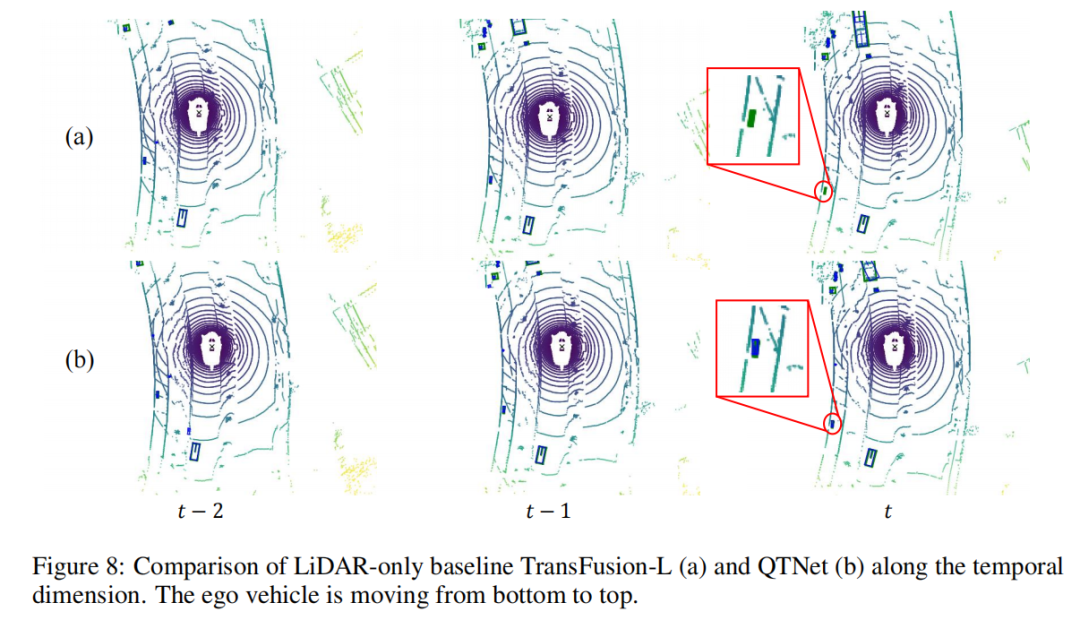
本文以场景序列为对象进行了检测结果的可视化分析。可以发现左下角的小物体从帧开始快速远离自车,这导致baseline在帧漏检了该物体,然而QTNet在帧仍然可以检测到该物体,这证明了QTNet在时序融合上的有效性。
本文针对目前3D目标检测任务提出了更加高效的基于Query的时序融合方法QTNet。其主要核心有两点:一是使用稀疏Query作为时序融合的对象并通过Memory Bank存储历史信息以避免重复的计算,二是使用显式的运动建模来引导时序Query间的注意力矩阵的生成,以此实现时序关系建模。通过这两个关键思路,QTNet能够高效地实现可应用于LiDAR、Camera、多模态的时序融合,并以可忽略不计的成本开销一致性地增强3D目标检测的性能。

需要重新改写的内容是:原文链接:https://mp.weixin.qq.com/s/s9tkF_rAP2yUEkn6tp9eUQ
以上是QTNet:全新时序融合方案解决方案,适用于点云、图像和多模态检测器(NeurIPS 2023)的详细内容。更多信息请关注PHP中文网其他相关文章!


































