

最近,微软进行的一项研究揭示了视频处理软件PS的灵活程度有多高
在这项研究中,你只要给 AI 一张照片,它就能生成照片中人物的视频,而且人物的表情、动作都是可以通过文字进行控制的。比如,如果你给的指令是「张嘴」,视频中的人物就会真的张开嘴。

如果你给的指令是「伤心」,她就会做出伤心的表情和头部动作。
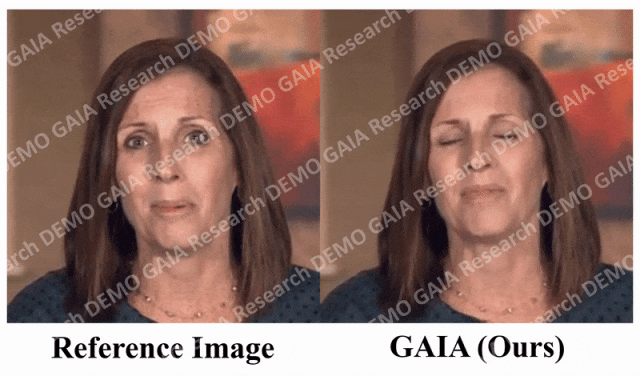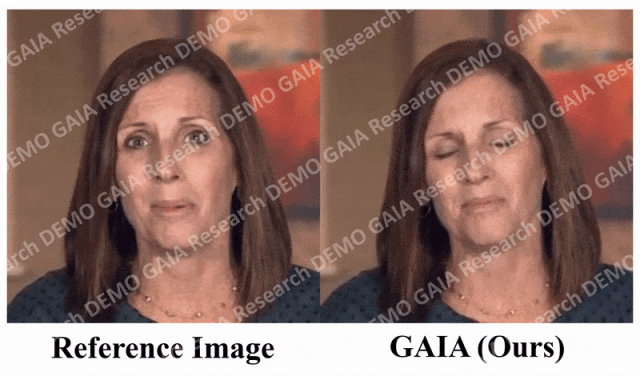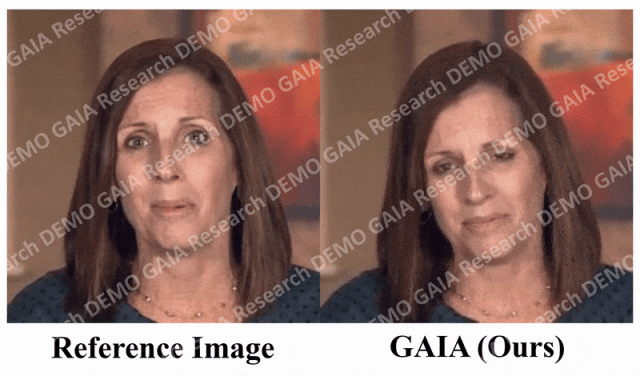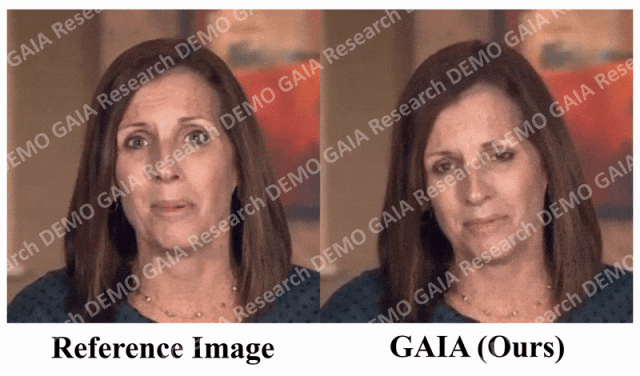
当给出指令「惊讶」,虚拟人物的抬头纹都挤到一起了。

除此之外,您还可以提供一段语音,使虚拟角色的嘴型和动作与语音同步。或者,您可以提供一段真人视频供虚拟角色模仿
如果你对虚拟人物的动作有更多的自定义编辑需求,例如让他们点头、转头或歪头,这项技术也是支持的

这项研究名叫 GAIA(Generative AI for Avatar,用于虚拟形象的生成式 AI),其 demo 已经开始在社交媒体传播。不少人对其效果表示赞叹,并希望用它来「复活」逝者。
但也有人担心,这些技术的持续进化会让网络视频变得更加真假难辨,或者被不法分子用于诈骗。看来,反诈手段要继续升级了。
零样本会说话的虚拟人物生成技术旨在根据语音合成自然视频,确保生成的嘴型、表情和头部姿势与语音内容一致。以往的研究通常需要针对每个虚拟人物进行特定训练或调整特定模型,或在推理过程中利用模板视频以实现高质量的结果。最近,研究人员致力于设计和改进零样本会说话的虚拟人物的生成方法,只需使用一张目标虚拟人物的肖像图片作为外貌参考即可。不过,这些方法通常采用基于warping的运动表示、3D Morphable Model(3DMM)等领域先验来降低任务难度。这类启发式方法虽然有效,但可能会限制多样性,导致不自然的结果。因此,从数据分布中直接学习是未来研究的重点
本文中,来自微软的研究者提出了 GAIA(Generative AI for Avatar),其能够从语音和单张肖像图片合成自然的会说话的虚拟人物视频,在生成过程中消除了领域先验。

项目地址:https://microsoft.github.io/GAIA/可以在此链接上找到相关项目的详细信息
论文链接: https://arxiv.org/pdf/2311.15230.pdf
盖亚揭示了两个关键洞见:
根据上述两个洞见,本文提出了 GAIA 框架,其由变分自编码器 (VAE)(橙色模块)和扩散模型(蓝色和绿色模块)组成。
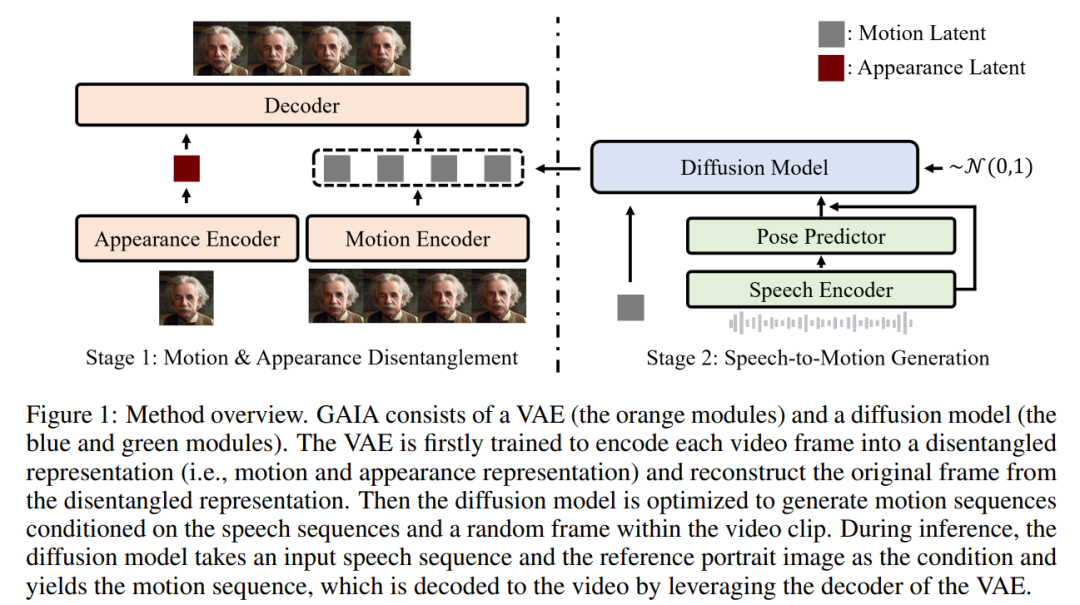
VAE的主要功能是分解运动和外貌。它由两个编码器(运动编码器和外貌编码器)和一个解码器组成。在训练时,运动编码器的输入为面部关键点(landmarks)的当前帧,而外貌编码器的输入为当前视频剪辑中的随机采样帧
根据这两个编码器的输出,随后优化解码器以重建当前帧。一旦获得训练完成的VAE,就会得到所有训练数据的潜在动作(即运动编码器的输出)
然后,这篇文章使用扩散模型训练,以预测基于语音和视频剪辑中随机采样帧的运动潜在序列,从而为生成过程提供外貌信息
在推理过程中,给定目标虚拟人物的参考肖像图像,扩散模型将图像和输入语音序列作为条件,生成符合语音内容的运动潜在序列。然后,生成的运动潜在序列和参考肖像图像经过 VAE 解码器合成说话视频输出。
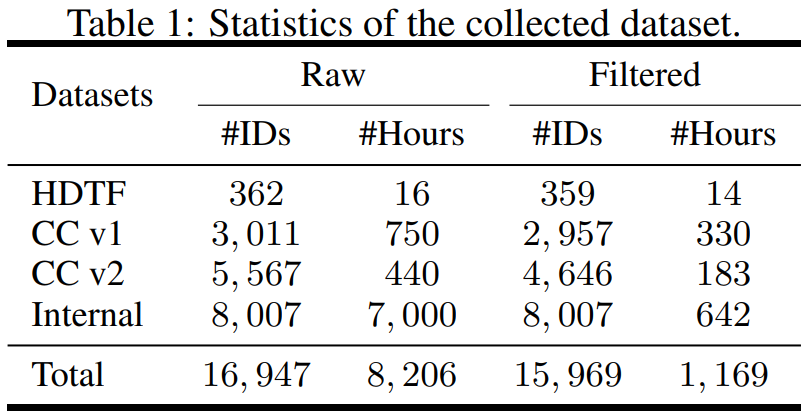
该研究在数据方面进行了构建,从不同的来源收集了数据集,包括 High-Definition Talking Face Dataset (HDTF) 和 Casual Conversation datasets v1&v2 (CC v1&v2)。除了这三个数据集之外,研究还收集了一个大规模的内部说话虚拟人物数据集,其中包含 7K 小时的视频和 8K 说话者 ID。数据集的统计概述如表 1 所示
为了学习到所需的信息,文章提出了几种自动过滤策略以确保训练数据的质量:
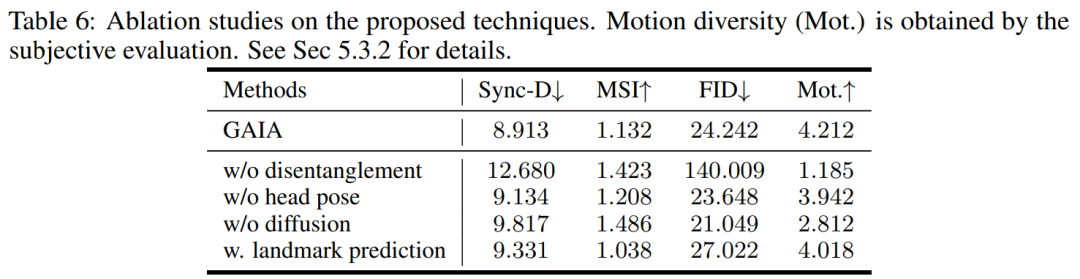
本文在过滤后的数据上训练 VAE 和扩散模型。从实验结果来看,本文得到了三个关键结论:
实验过程中,该研究将 GAIA 与三个强大的基线进行比较,包括 FOMM、HeadGAN 和 Face-vid2vid。结果如表 2 所示:GAIA 中的 VAE 比以前的视频驱动基线实现了持续的改进,这说明 GAIA 成功地分解了外貌和运动表示。
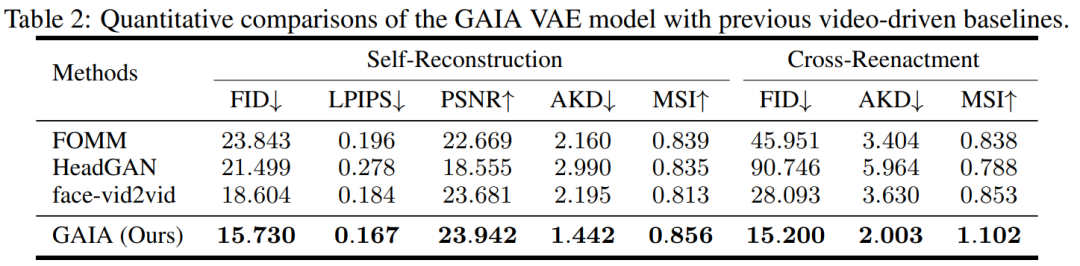
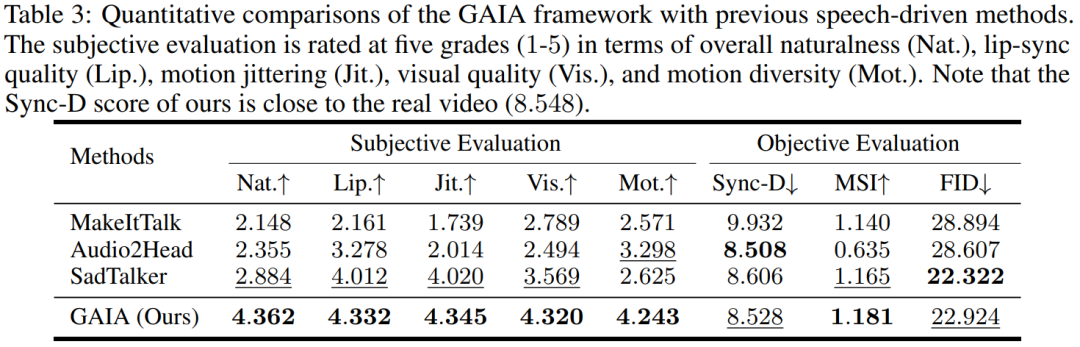
语音驱动结果。用语音驱动说话虚拟人物生成是通过从语音预测运动实现的。表 3 和图 2 提供了 GAIA 与 MakeItTalk、Audio2Head 和 SadTalker 方法的定量和定性比较。
从数据中可以清楚地看出,GAIA 在主观评价方面远远超过了所有基准方法。更具体地说,如图 2 所示,即使参考图像是闭眼或头部姿态不寻常,基准方法的生成结果通常高度依赖于参考图像;相比之下,GAIA 对各种参考图像都表现出鲁棒性,并生成具有更高自然度、口型高度同步、视觉质量更好以及运动多样性的结果

根据表3,最佳的MSI分数表明GAIA生成的视频具有出色的运动稳定性。Sync-D得分为8.528,接近真实视频得分(8.548),表明生成的视频具有出色的唇形同步性。该研究获得了与基线相当的FID分数,这可能是受到了不同头部姿态的影响,因为该研究发现未经扩散训练的模型在表中实现了更好的FID分数,详见表6
以上是一张照片生成视频,张嘴、点头、喜怒哀乐,都可以打字控制的详细内容。更多信息请关注PHP中文网其他相关文章!





















