

GPT-4 自诞生以来一直是位「优等生」,在各种考试(基准)中都能得高分。但现在,它在一份新的测试中只拿到了 15 分,而人类能拿 92。
这套名叫「GAIA」的测试题由来自 Meta-FAIR、Meta-GenAI、HuggingFace 和 AutoGPT 的团队制作,提出了一些需要一系列基本能力才能解决的问题,如推理、多模态处理、网页浏览和一般工具使用能力。这些问题对人类来说非常简单,但对大多数高级 AI 来说却极具挑战性。如果里面的问题都能解决,通关的模型将成为 AI 研究的重要里程碑。

GAIA 的设计理念和当前的很多 AI 基准不一样,后者往往倾向于设计一些对人类来说越来越难的任务,这背后其实反映了当前社区对 AGI 理解的差异。GAIA 背后的团队认为,AGI 的出现取决于系统能否在上述「简单」问题上表现出与普通人类似的稳健性。

重写内容如下: 图片1:GAIA问题示例。完成这些任务需要大型模型具备一定的推理、多模态或工具使用等基本能力。答案是明确的,并且根据设计,在训练数据的纯文本中是找不到答案的。有些问题附带额外的证据,例如图片,这反映了真实的用例并且允许更好地控制问题
尽管 LLM 能成功完成人类难以完成的任务,但能力最强的 LLM 在 GAIA 上的表现却难以令人满意。即使配备了工具,GPT4 在最简单的任务中成功率也不超过 30%,而在最难的任务中成功率为 0%。与此同时,人类受访者的平均成功率为 92%。
因此,如果一个系统能解决 GAIA 里的问题,我们就能在 t-AGI 系统中去评估它。t-AGI 是 OpenAI 工程师 Richard Ngo 构建的一套细化 AGI 评估系统,其中包括 1-second AGI、1-minute AGI、1-hour AGI 等等,用来考察某个 AI 系统能否在限定时间里完成人类通常花相同时间可以完成的任务。作者表示,在 GAIA 测试中,人类通常需要 6 分钟左右回答最简单的问题,17 分钟左右回答最复杂的问题。
作者使用GAIA的方法设计了466个问题及其答案。他们发布了一个开发者集,其中包含166个问题和答案,另外还有300个问题没有附带答案。这个基准以排行榜的形式发布
GAIA 是如何运作的?研究人员表示,GAIA 用于测试人工智能系统一般助理问题的基准。GAIA 试图规避之前大量 LLM 评估所存在的缺陷。这个基准由人类设计和注释的 466 个问题组成。这些问题基于文本,有些还附带文件(如图像或电子表格)。它们涵盖了各种辅助性质的任务,包括日常个人任务、科学和常识等
这些问题有一个简短、单一且易于验证的正确答案
想要使用 GAIA,只需向人工智能助手零样本提出问题并附上相关的依据(如果有的话)。要在 GAIA 上获得完美的得分,需要具备一系列不同的基本能力。该项目的制作者在其补充材料中提供了各种问题和元数据
GAIA 的产生既源于升级人工智能基准的需要,也源于目前广泛观察到的 LLM 评估的缺点。
设计GAIA的首要原则是针对概念上简单的问题。尽管这些问题对人类来说可能很乏味,但它们在现实世界中千变万化,对当前的人工智能系统来说是具有挑战性的。这使得我们可以专注于基本能力,比如通过推理快速适应、多模态理解和潜在的多样化工具使用,而不是专业技能方面
这些问题通常包括查找和转换从不同来源(例如提供的文档或开放且不断变化的网络)收集的信息,以产生准确的答案。要回答图 1 的示例问题,LLM 通常应该浏览网络查找研究,然后寻找正确的注册位置。这与此前基准体系的趋势相反,以前的基准对人类来说越来越困难,和 / 或在纯文本或人工环境中操作。
GAIA的第二个原则是可解释性。相比于海量问题,我们精心策划了有限数量的问题,使得新的基准更易于使用。这个任务的概念很简单(人类成功率为92%),使用户很容易理解模型的推理过程。对于图1中的一级问题,推理过程主要包括检查正确的网站,并报告正确的数字,这个过程很容易进行验证
GAIA 的第三个原则是对记忆的鲁棒性:GAIA 的目标是比大多数当前基准测试的猜题可能性更低。为了完成一项任务,系统必须计划好并成功完成一些步骤。因为根据设计,当前预训练数据中没有以纯文本形式生成结果答案。准确性的进步反映了系统的实际进步。由于它们的多样性和行动空间的大小,这些任务不能在不作弊的情况下被暴力破解,例如通过记住基本事实。尽管数据污染可能导致额外的正确率,但答案所需的准确性、答案在预训练数据中的缺失以及检查推理轨迹的可能性减轻了这种风险。
相反,多项选择答案使污染评估变得困难,因为错误的推理痕迹仍然可以得出正确的选择。如果尽管采取了这些缓解措施,还是发生了灾难性记忆问题,那么使用作者在论文中提供的指南很容易设计新问题。
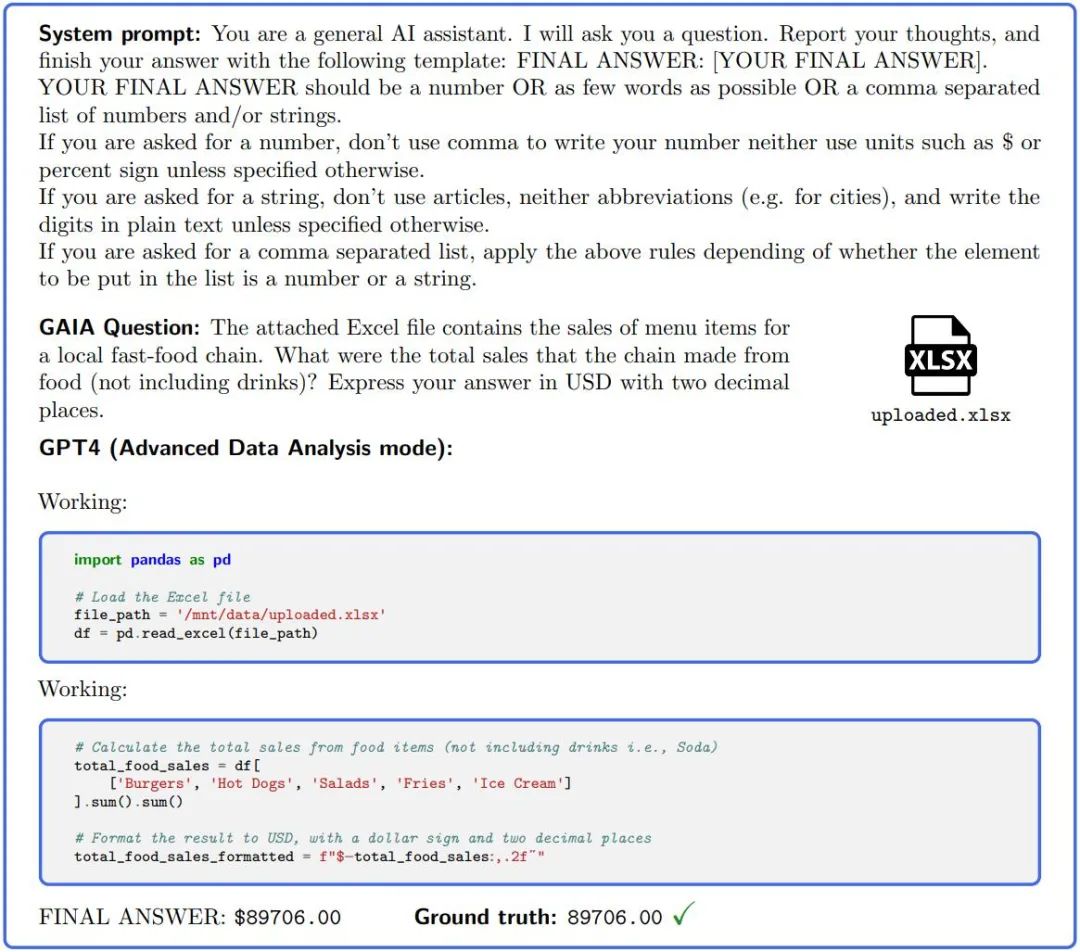
图 2.:为了回答 GAIA 中的问题,GPT4(配置了代码解释器)等 AI 助手需要完成几个步骤,可能需要使用工具或读取文件。
GAIA 的最后一个原则是易用性。其中的任务是简单的提示,可能会附带一个附加文件。最重要的是,问题的答案是事实、简洁且明确的。这些属性允许简单、快速和真实的评估。问题旨在测试 zero-shot 能力,限制评估设置的影响。相反,许多 LLM 基准要求对实验设置敏感的评估,例如提示的数量和性质或基准实现。
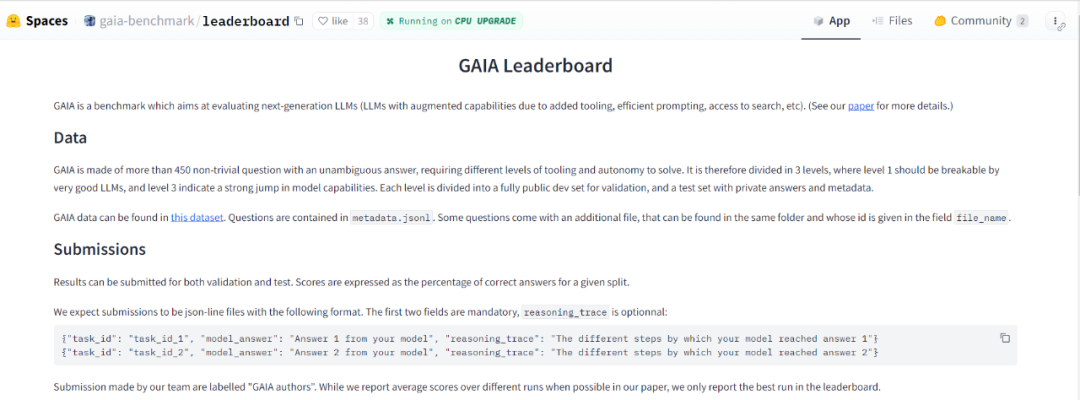
GAIA 的设计使得大模型智能水平的评估自动化、快速且真实。实际上,除非另有说明,每个问题都需要一个答案,该答案可以是字符串(一个或几个单词)、数字或逗号分隔的字符串或浮点数列表,但只有一个正确答案。因此,评估是通过模型的答案和基本事实之间的准精确匹配来完成的(直到与基本事实的「类型」相关的某种归一化)。系统(或前缀)提示用于告知模型所需的格式,请参见图 2。
事实上,级别为GPT4的模型很容易符合GAIA的格式。GAIA已经提供了评分和排名功能
目前只测试了大模型领域的「标杆」,OpenAI 的 GPT 系列,可见不管哪个版本分数都很低,Level 3 的得分还经常是零分。
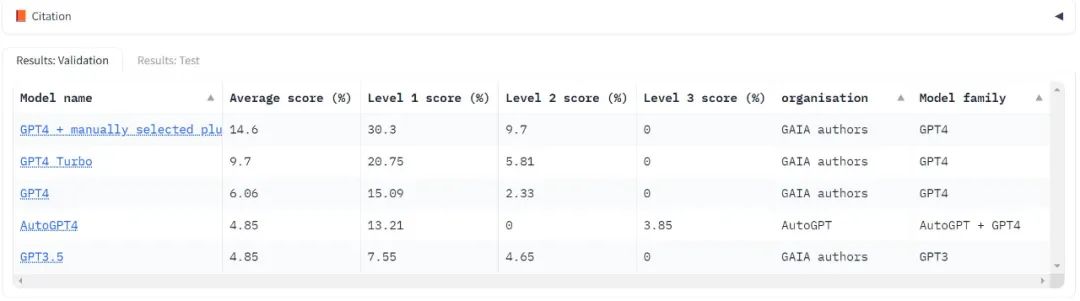
使用 GAIA 评估 LLM 只需要能够提示模型,即有 API 访问权限即可。在 GPT4 测试中,最高分数是人类手动选择插件的结果。值得注意的是,AutoGPT 能够自动进行此选择。
只要 API 可以使用,测试时就会运行该模型三次并报告平均结果
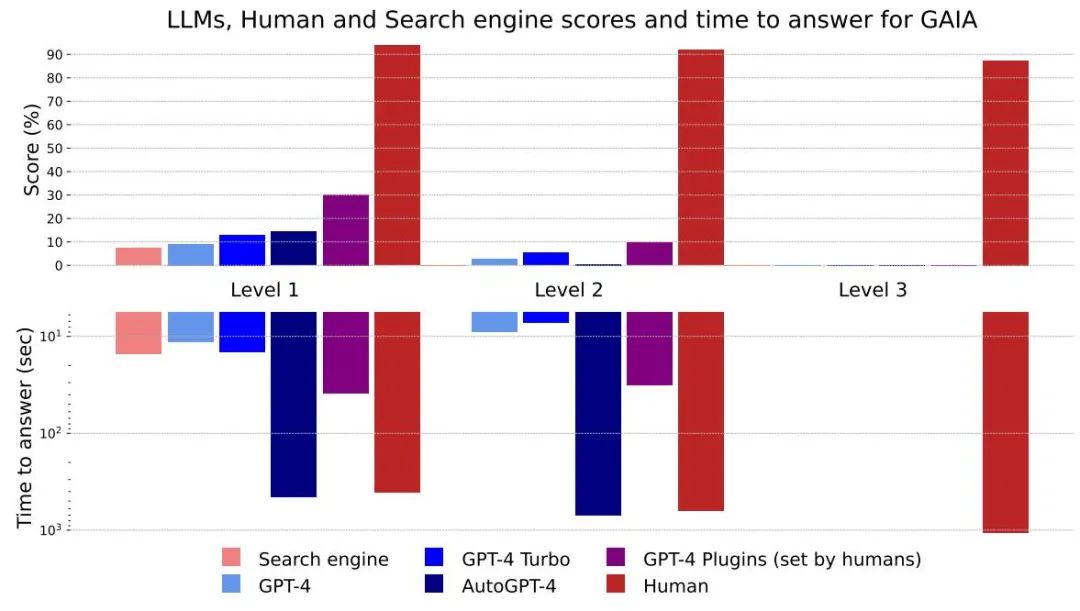
图4:不同方法及级别的得分和回答时间
总体而言,人类在问答中的各个层面都表现出色,但目前最好的大模型显然表现不佳。作者认为,GAIA 可以对有能力的 AI 助手进行清晰的排名,同时在未来几个月甚至几年内留下很大的改进空间。
从回答花费的时间上来看,GPT-4这类大型模型具有潜在能力可以替代现有的搜索引擎
没有插件的 GPT4 结果与其他结果之间的差异表明,通过工具 API 或访问网络来增强 LLM 可以提高答案的准确性,并解锁许多新的用例,这证实了该研究方向的巨大潜力。
AutoGPT-4允许GPT-4自动使用工具,但与没有插件的GPT-4相比,Level 2甚至Level 1的结果都令人失望。这种差异可能来自于AutoGPT-4依赖GPT-4 API(提示和生成参数)的方式,并且在不久的将来需要进行新的评估。与其他LLM相比,AutoGPT-4也很慢。总体而言,人类和带有插件的GPT-4之间的协作似乎是「性能」最好的
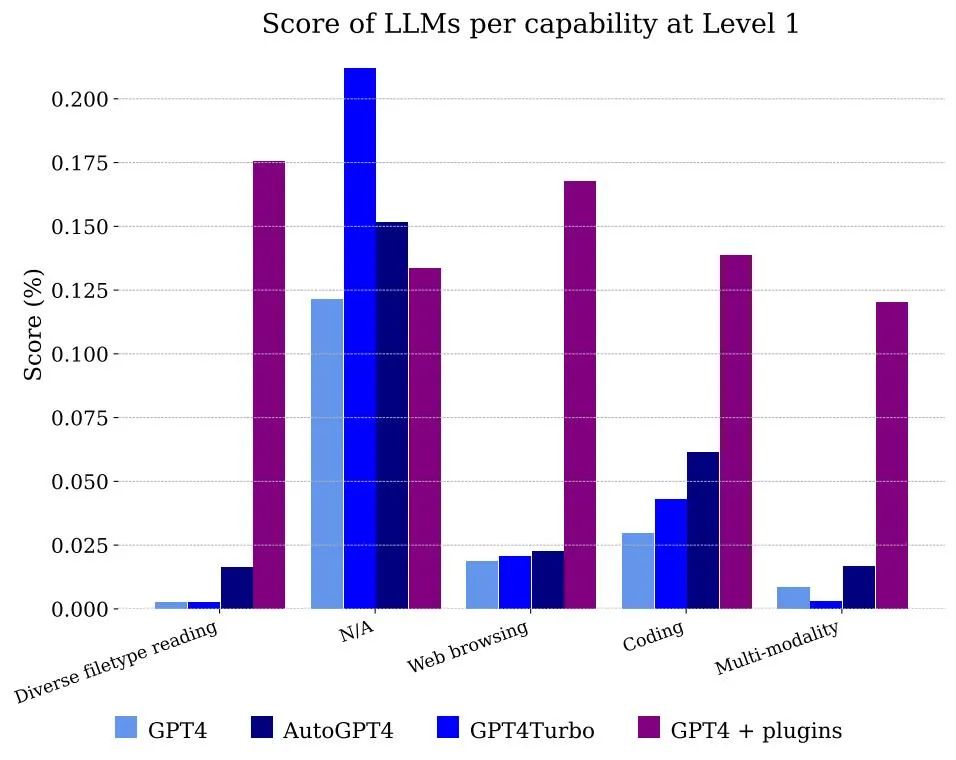
图 5 展示了按照功能分类的模型所获得的分数。显然,仅仅使用 GPT-4 是无法处理文件和多模态的,但它能够解决注释者使用网页浏览的问题,主要是因为它能够正确地记忆需要组合的信息片段以获得答案
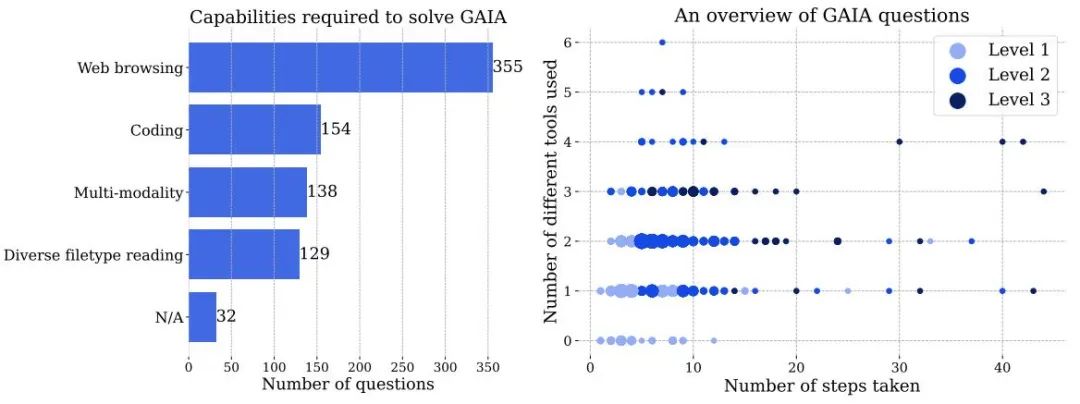
图 3 左:解决 GAIA 中问题需要使用的能力的数量。右:每个点对应一个 GAIA 问题。在给定位置,点的大小与问题数量成正比,并且仅显示问题数量最多的级别。这两个数字都是基于人类注释者在回答问题时报告的信息,人工智能系统的处理方式可能会有所不同。
在 GAIA 上获得完美得分需要 AI 具备先进的推理、多模态理解、编码能力和一般工具使用能力,例如网页浏览。AI 还包括需要处理各种数据模态,例如 PDF、 电子表格,图像、视频或音频。
尽管网页浏览是 GAIA 的关键组成部分,但我们不需要 AI 助手在网站上执行除「点击」之外的操作,例如上传文件、发表评论或预订会议。在真实环境中测试这些功能,同时避免制造垃圾信息需要谨慎,这个方向会留在未来的工作中。
题目难度逐渐加大:根据解决问题所需的步骤和回答问题所需的不同工具数量,该题可分为三个难度逐渐加大的等级。这些步骤或工具没有一个单一的定义,可能有多种路径可用于回答给定的问题
GAIA 针对现实世界的 AI 助理设计问题,设计中的问题还包括面向残障人士的任务,如在小音频文件中查找信息。最后,该基准尽最大努力涵盖各种主题领域和文化,尽管数据集的语言仅限于英语。
请参阅原始论文以获得更多详细信息
以上是人类考92分的题,GPT-4只能考15分:测试一升级,大模型全都现原形了的详细内容。更多信息请关注PHP中文网其他相关文章!





















