

最近,新论文推陈出新的速度着实太快有点读不过来的感觉。可以看到的是,语言视觉多模态大模型融合已经是业界共识了,UniPad 这篇文章就比较有代表性,多模态的输入,类世界模型的预训练基座模型,同时又方便扩展到多个传统视觉应用。并且还解决了将大语言模型的预训练方法用到 3D 场景的问题,所以给统一的感知基座大模型提供了可能。
UniPAD 是一种基于 MAE 和 3D 渲染的自监督学习方法,可以训练一个性能优秀的基座模型,进而在该模型上微调训练下游任务,如深度估计、目标检测和分割。该研究设计了一个统一的 3D 空间表示方法,使其能够轻松融入 2D 和 3D 框架,展现了较大的灵活性,符合基座模型的定位
掩码自编码技术 和 3D 可微分渲染技术的关系是什么?简单说:掩码自编码是为了利用 Autoencoder 的自监督训练能力,渲染技术是为了生成图片后和原始图片之间进行损失函数计算并进行监督训练。所以逻辑还是很清晰的。
这篇文章在使用基座模型预训练的方法,再微调下游的检测方法和分割方法。这个方法也可以帮助理解当下的大模型与下游任务的配合方法。
看起来是没有结合时序信息的。毕竟纯视觉 50.2 的 NuScenes NDS 目前在带时序的检测方法(StreamPETR、Sparse4D 等)比较中还是弱了一些。所以 4D 的 MAE 方法,也是值得一试的,其实 GAIA-1 已经提到了类似的思路。
请问运算量和内存使用量如何?
UniPAD 隐式地编码了 3D 空间信息,这里主要受到了掩码自编码(MAE、VoxelMAE 等)的启发,本文利用了生成式的 mask 来完成体素特征的加强,用来重建场景中连续的 3D 形状结构以及它们在 2D 平面上的复杂外观特征。
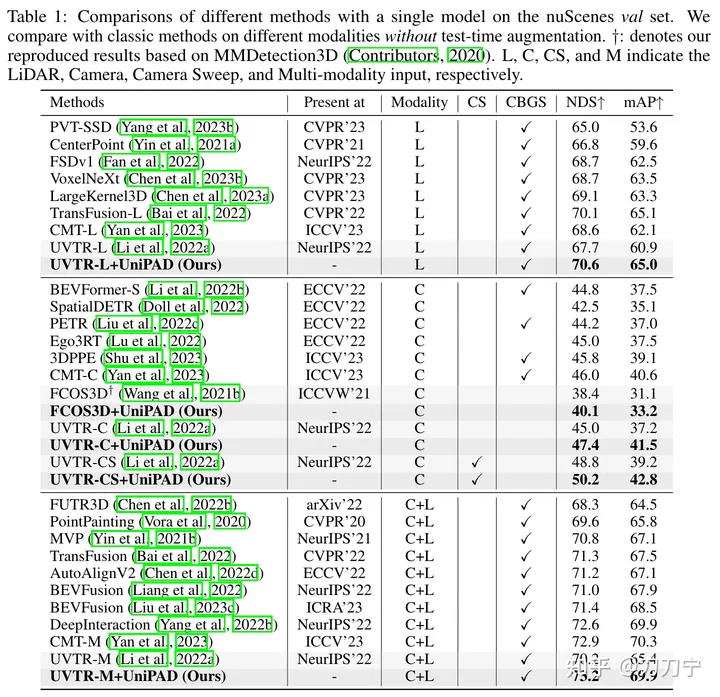
我们的实验结果充分证明了UniPAD的优越性。与传统的激光雷达、摄像头以及激光雷达-摄像头融合基线相比,UniPAD的NDS分别提高了9.1、7.7和6.9。值得注意的是,在nuScenes验证集上,我们的预训练流程实现了73.2的NDS,同时在3D语义分割任务上获得了79.4的mIoU分数,与以前的方法相比,取得了最佳成绩
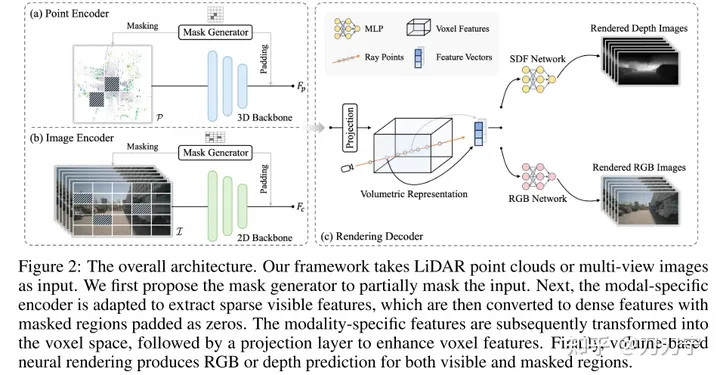
整体架构。该框架 LiDar 和多镜头图片作为输入,这些多模态数据会通过掩蔽生成器(Mask Generator)被填充为零。被掩码遮蔽的 embedding 会被转换到体素空间,在这样的 3D 空间中通过渲染技术生成RGB或深度预测结果。这时没有被掩码遮蔽的原始图像就可以做为生成数据进行监督学习了。
Masked AutoEncoder中的mask是通过Mask Generator生成的。可以将其理解为通过增加训练难度的方式来提高模型的表示能力和泛化能力。引入了一个Mask生成器,通过有选择性地遮挡某些区域来区分点云数据和图像数据。在点云数据中,采用了分块遮罩的策略;对于图像数据,采用了稀疏卷积的方法,只在可见区域进行计算。当输入数据被遮罩后,后续的编码特征在对应的被遮罩区域会被设置为0,在模型的处理中被忽略,同时也为后续的监督学习提供了可以用来预测目标和对应的groundtruth的信息
为了使预训练方法适用于各种不同的数据模态,寻找一个统一的表示形式就很重要。过往的BEV和OCC等方法都在寻找一个统一的标识形式,将3D点投影到图像平面中会导致深度信息的丢失,而将它们合并到BEV鸟瞰图中则会遗漏与高度相关的细节。因此,本文提出将两种模态都转换为3D体积空间,也就是类似OCC的3D体素空间
可微分渲染技术应该是作者认为论文最大的亮点了,本文通过类似 NERF 的采样射线穿过多视图图像或点云,通过神经网络结构预测每个 3D 点的颜色或深度,最后再通过射线穿过的路径获取 2D 的映射。这样可以更好地利用图像中的几何或纹理线索,提高模型的学习能力和应用范围。
我们将场景表示为 SDF(implicit signed distance function field),当输入是采样点的 3D 坐标 P(沿射线的相应深度 D)与 F(the feature embedding can be extracted from the volumetric representation by trilinear interpolation)时,SDF 可以看做一个 MLP ,来预测采样点的 SDF 值。这里 F 可以理解为 P 点所在的 encode 编码。继而得到输出:N(condition the color field on the surface normal)和 H(geometry feature vector),这时就可以通过一个以 P、D、F、N、H 为输入的 MLP 获取到 3D 采样点的 RGB 值和深度值,再通过射线叠加 3D 采样点到 2D 空间就得到了渲染结果。而这里射线 Ray 的采用方法,和 Nerf 的方法基本相同。
渲染方法还需要进行内存开支的优化工作,这里先按下不表。不过这个问题是个比较关键的落地问题。
Mask 与渲染方法的本质在于训练一个预训练模型,预训练模型可以根据预测的遮罩进行训练,甚至可以没有后续分支。预训练模型的后续工作通过不同的分支分别生成 RGB 和深度预测,结合目标检测/语义分割等任务进行微调,实现了即插即用的能力
Loss 函数并不复杂。

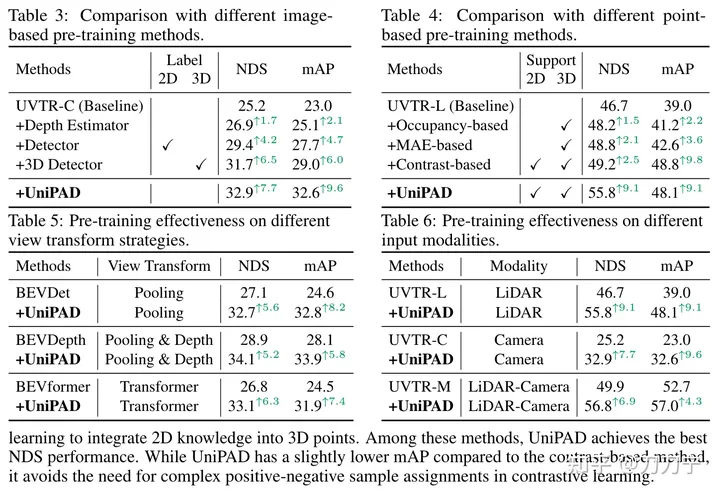
其实 GAIA-1 已经在用时序上的 Mask AutoEncoder 思路,只不过作为监督数据的是不同时刻的一整帧数据,但是 UniPAD 则是在 3D 空间中去随机抠出一部分 mask 来监督预测。倒是蛮期待能看到两者结合的方法的。
另外,UniPAD 完全可以看成是一种多模态大模型的尝试,也可以看做是一种世界模型。虽然文章中没有非常强调这些。
本文应该算是 3D 领域较为新颖的 Masked Autoencoder 方法了。因为 MAE 方法是用在了基座模型预训练阶段,所以支持了多个不同模态的信息,所以自然而然的可以扩展到微调下游很多任务,这和 LLM 的设计思路非常的接近,都注重于在预训练阶段捕捉多模态信息,为各种任务提供统一的基础。这种方法为3D领域的研究提供了新的思路和可能性。
该方法不仅在3D领域具有潜力,还可以扩展到 4D 时序领域,以及优化其内存与计算量等方面还可以产生很多新的工作,为未来的研究提供了新的思路和可能性。

原文链接:https://mp.weixin.qq.com/s/e_reCS-Lwr-KVF80z56_ow
以上是UniPAD:通用自动驾驶预训练模式!各类感知任务都可支持的详细内容。更多信息请关注PHP中文网其他相关文章!





















