

生成式 AI 元年,大家的工作节奏快了一大截。
特别是,今年大家都在努力卷大模型:最近国内外科技巨头、创业公司都在轮番推出大模型,发布会一开,个个都是重大突破,每一家都是刷新了重要 Benchmark 榜单,要么排第一,要么第一梯队。
在兴奋于技术进展速度之快后,很多人发现似乎也有些不对味:为什么排行榜第一人人有份?这是个什么机制?
于是乎,「刷榜」这个问题也开始备受关注。
近日,我们关注到朋友圈和知乎社区对大模型「刷榜」这一问题的讨论越来越多。特别是,知乎一篇帖子:如何评价天工大模型技术报告中指出很多大模型用领域内数据刷榜的现象?引起了大家的讨论。
链接:https://www.zhihu.com/question/628957425
该研究来自昆仑万维的「天工」大模型研究团队,他们上个月底把一份技术报告发布在了预印版论文平台 arXiv 上。

论文链接:https://arxiv.org/abs/2310.19341
论文本身是在介绍 Skywork-13B,这是天工的一个大型语言模型(LLM)系列。作者引入了使用分段语料库的两阶段训练方法,分别针对通用训练和特定领域的增强训练。
和往常有关大模型的新研究一样,作者表示在流行的测试基准上,他们的模型不仅表现出色,而且在很多中文的分支任务上取得了 state-of-art 水平(就是业内最佳)。
重点是,该报告还验证了下很多大模型的真实效果,指出了一些其他一些国产大模型存在投机取巧的嫌疑。说的就是这个表格 8:
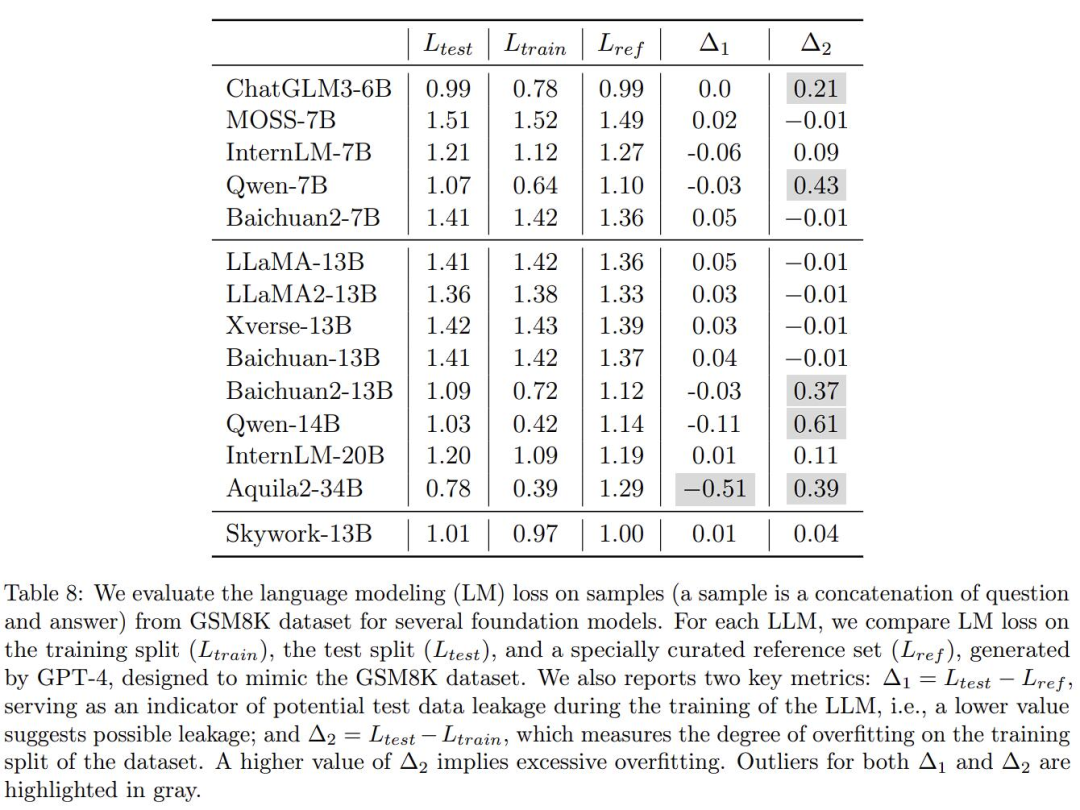
在这里,作者为了验证目前业内几个常见大模型在数学应用问题基准 GSM8K 上的过拟合程度,使用 GPT-4 生成了一些与 GSM8K 形式上相同的样本,人工核对了正确性,并让这些模型在生成的数据集,和 GSM8K 原本的训练集、测试集上比了比,计算了损失。然后还有两个指标:
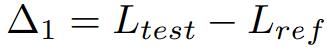
Δ1 作为模型训练期间潜在测试数据泄漏的指标,较低的值表明可能存在泄漏。没有用测试集训练,那数值应该为零。
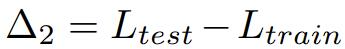
Δ2 衡量数据集训练分割的过度拟合程度。较高的 Δ2 值意味着过拟合。如果没有用训练集训练过,那数值应该为零。
用简单的话来解释就是:如果有模型在训练的时候,直接拿基准测试里面的「真题」和「答案」来当学习资料,想以此来刷分,那么此处就会有异常。
好的,Δ1 和 Δ2 有问题的地方,上面都贴心地以灰色突出显示了。
网友对此评论道,终于有人把「数据集污染」这个公开的秘密说出来了。
也有网友表示,大模型的智力水平,还是要看 zero-shot 能力,现有的测试基准都做不到。

图:截图自知乎网友评论
在作者与读者中互动中,作者也表示,希望「让大家更理性看待刷榜这个事情,很多模型和 GPT4 的差距还很大」。
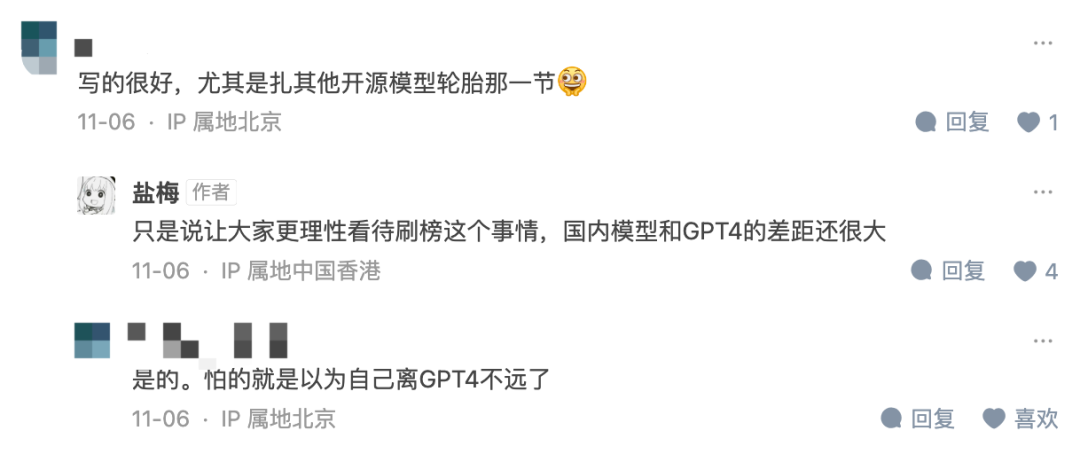
图:截图自知乎文章 https://zhuanlan.zhihu.com/p/664985891
其实,这并不是一时的现象。自从有了 Benchmark,此类问题时常会有发生,就像今年 9 月份 arXiv 上一篇极具嘲讽意味的文章标题指出的一样 Pretraining on the Test Set Is All You Need。

除此之外,最近人民大学、伊利诺伊大学香槟分校一个正式研究同样指出了大模型评估中存在的问题。标题很扎眼《Don't Make Your LLM an Evaluation Benchmark Cheater》:

论文链接:https://arxiv.org/abs/2311.01964
论文指出,当前火热的大模型领域让人们关心基准测试的排名,但其公平性和可靠性正在受到质疑。其中主要的问题就是数据污染和泄露,这样的问题可能会被无意识地触发,因为我们在准备预训练语料库时可能不知道未来的评估数据集。例如,GPT-3 发现预训练语料库中包含了 Children's Book Test 数据集,LLaMA-2 的论文曾提到提取了 BoolQ 数据集中的上下文网页内容。
数据集是需要很多人花费大量精力收集、整理和标注的,优质的数据集如果优秀到能被用于评测,那自然也有可能会被另一些人用于训练大模型。
另一方面,在使用现有基准进行评估时,我们评测的大模型的结果大多是通过在本地服务器上运行或通过 API 调用来获得的。在此过程中,没有严格检查任何可能导致评估绩效异常提高的不当方式(例如数据污染)。
更糟糕的是,训练语料库的详细组成(例如数据源)通常被视为现有大模型的核心「秘密」。这就更难去探究数据污染的问题了。
也就是说,优秀数据的数量是有限的,在很多测试集上,GPT-4 和 Llama-2 也不一定就没问题。比如在第一篇论文中提到的 GSM8K,GPT-4 在官方 technical report 里提到过使用了它的训练集。
你不是说数据很重要吗,那么用「真题」刷分的大模型,性能会不会因为训练数据更优秀而变得更好呢?答案是否定的。
研究人员实验发现,基准泄漏会导致大模型跑出夸张的成绩:例如 1.3B 的模型可以在某些任务上超越 10 倍体量的模型。但副作用是,如果我们仅使用这些泄露的数据来微调或训练模型,这些专门应试的大模型在其他正常测试任务上的表现可能会受到不利影响。
因此作者建议,以后研究人员在评测大模型,或是研究新技术时应该:
最后想说,好在这个问题开始逐渐引起大家的关注,无论是技术报告、论文研究还是社区讨论,都开始重视大模型「刷榜」的问题了。
对此,你有什么看法与有效建议呢?
以上是大模型走捷径「刷榜」?数据污染问题值得重视的详细内容。更多信息请关注PHP中文网其他相关文章!





















