

为了不改变原始意思,需要重新表达的内容是:首先需要弄清楚为什么需要进行交叉验证?
交叉验证是机器学习和统计学中常用的一种技术,用于评估预测模型的性能和泛化能力,特别是在数据有限或评估模型对新的未见数据的泛化能力时,交叉验证非常有价值。

在哪些情况下会使用交叉验证呢?
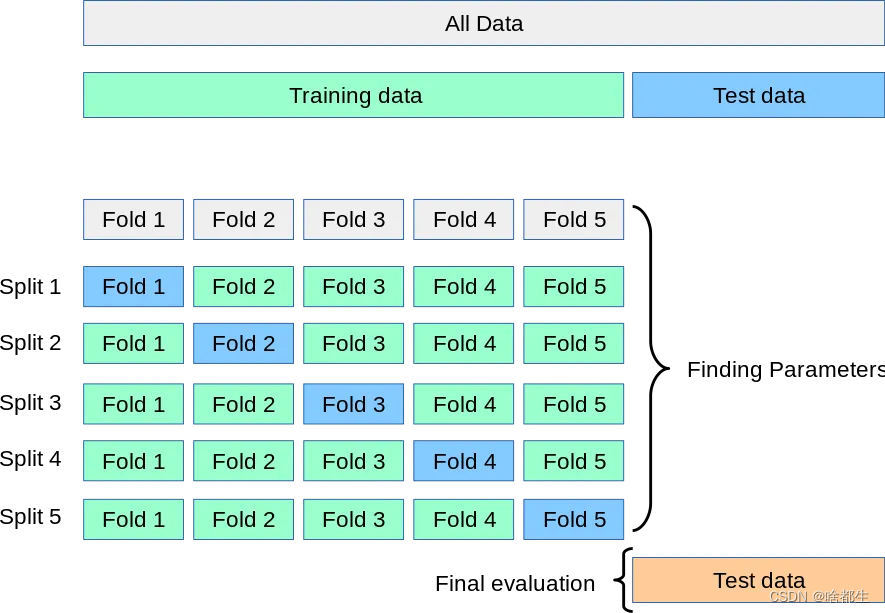
交叉验证的大致思想可如图5折交叉所示,在每次迭代中,新模型在四个子数据集上训练,并在最后一个保留的子数据集上进行测试,确保所有数据得到利用。通过平均分数及标准差等指标,提供了对模型性能的真实度量
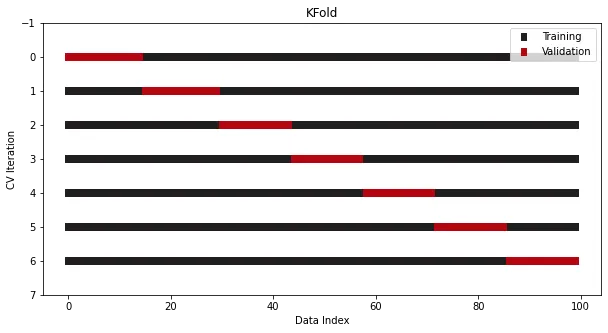
一切还得从K折交叉开始。
在Sklearn中已经集成了K折交叉验证,这里以7折为例:
from sklearn.datasets import make_regressionfrom sklearn.model_selection import KFoldx, y = make_regression(n_samples=100)# Init the splittercross_validation = KFold(n_splits=7)
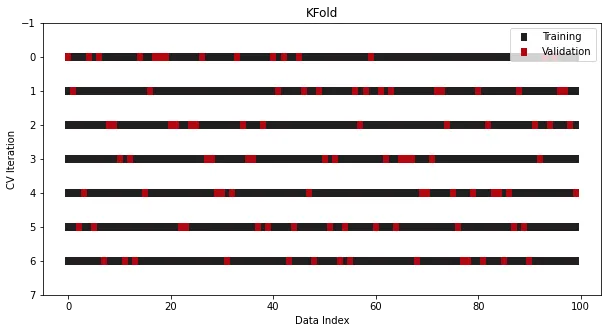
还有一个常用操作是在执行拆分前进行Shuffle,通过破坏样本的原始顺序进一步最小化了过度拟合的风险:
cross_validation = KFold(n_splits=7, shuffle=True)
这样,一个简单的k折交叉验证就能够完成了,请务必查看源代码!请务必查看源代码!请务必查看源代码!
StratifiedKFold是专门为分类问题而设计。
在有的分类问题中,即使将数据分成多个集合,目标分布也应该保持不变。比如大多数情况下,具有30到70类别比例的二元目标在训练集和测试集中仍应保持相同的比例,在普通的KFold中,这个规则被打破了,因为在拆分之前对数据进行shuffle时,类别比例将无法保持。
为了解决这个问题,在Sklearn中使用了另一个专门用于分类的拆分器类——StratifiedKFold:
from sklearn.datasets import make_classificationfrom sklearn.model_selection import StratifiedKFoldx, y = make_classification(n_samples=100, n_classes=2)cross_validation = StratifiedKFold(n_splits=7, shuffle=True, random_state=1121218)
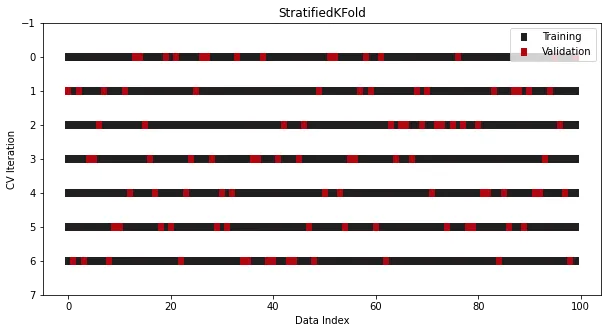
尽管与KFold看起来相似,但现在在所有的split和迭代中,类别比例保持一致
有时只需多次重复进行训练/测试集分割的过程,这种方式与交叉验证非常相似
在逻辑上来说,通过使用不同的随机种子生成多个训练/测试集,应该在足够多的迭代中,类似于一个稳健的交叉验证过程
Scikit-learn库中也提供了相应的接口:
from sklearn.model_selection import ShuffleSplitcross_validation = ShuffleSplit(n_splits=7, train_size=0.75, test_size=0.25)

当数据集为时间序列时,不能使用传统的交叉验证,这将完全打乱顺序,为了解决这个问题,参考Sklearn提供了另一个拆分器——TimeSeriesSplit,
from sklearn.model_selection import TimeSeriesSplitcross_validation = TimeSeriesSplit(n_splits=7)
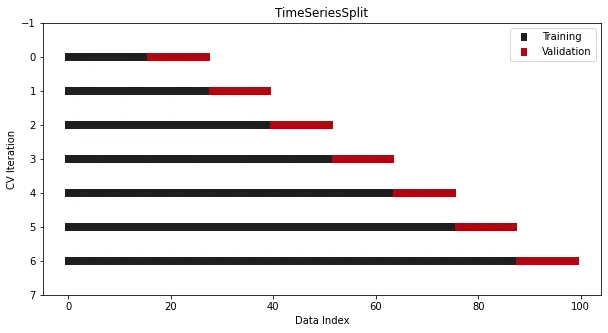
在验证集始终位于训练集的索引之后的情况下,我们可以看到图形。这是由于索引是日期,这意味着我们不会意外地在未来的日期上进行时间序列模型的训练,并对之前的日期进行预测
以上方法是针对独立同分布数据集进行处理的,即生成数据的过程不会受到其他样本的影响
然而,在某些情况下,数据并不满足独立同分布(IID)的条件,即一些样本之间存在依赖关系。这种情况在Kaggle竞赛中也有出现,比如Google Brain Ventilator Pressure竞赛。该数据记录了人工肺在数千个呼吸过程中(吸入和呼出)的气压值,并且对每次呼吸的每个时刻进行了记录。每个呼吸过程大约有80行数据,这些行之间是相互关联的。在这种情况下,传统的交叉验证方法无法使用,因为数据的划分可能会“刚好发生在一个呼吸过程的中间”
这可以被理解为需要对这些数据进行“分组”,因为组内数据是有关联的。举个例子,当从多个患者收集医疗数据时,每个患者都有多个样本。然而,这些数据很可能会受到患者个体差异的影响,因此也需要进行分组
往往我们希望在一个特定组别上训练的模型是否能够很好地泛化到其他未见过的组别,所以在进行交差验证时给这些组别数据打上“tag”,告诉他们如何区分别瞎拆。
在Sklearn中提供了若干接口处理这些情况:
强烈建议搞清楚交叉验证的思想,以及如何实现,搭配看Sklearn源码是一个肥肠不错的方式。此外,需要对自己的数据集有着清晰的定义,数据预处理真的很重要。
以上是交叉验证的重要性不容忽视!的详细内容。更多信息请关注PHP中文网其他相关文章!





















