

在一项最新的研究中,来自 UW 和 Meta 的研究者提出了一种新的解码算法,将 AlphaGo 采用的蒙特卡洛树搜索算法(Monte-Carlo Tree Search, MCTS)应用到经过近端策略优化(Proximal Policy Optimization, PPO)训练的 RLHF 语言模型上,大幅提高了模型生成文本的质量。
PPO-MCTS 算法通过探索与评估若干条候选序列,搜索到更优的解码策略。通过 PPO-MCTS 生成的文本能更好满足任务要求。

论文链接:https://arxiv.org/pdf/2309.15028.pdf
面向大众用户发布的 LLM,如 GPT-4/Claude/LLaMA-2-chat,通常使用 RLHF 以向用户的偏好对齐。PPO 已经成为上述模型进行 RLHF 的首选算法,然而在模型部署时,人们往往采用简单的解码算法(例如 top-p 采样)从这些模型生成文本。
本文的作者提出采用一种蒙特卡洛树搜索算法(MCTS)的变体从 PPO 模型中进行解码,并将该方法命名为 PPO-MCTS。该方法依赖于一个价值模型(value model)来指导最优序列的搜索。因为 PPO 本身即是一种演员 - 评论家算法(actor-critic),故而会在训练中产生一个价值模型作为其副产品。
PPO-MCTS 提出利用这个价值模型指导 MCTS 搜索,并通过理论和实验的角度验证了其效用。作者呼吁使用 RLHF 训练模型的研究者和工程人员保存并开源他们的价值模型。
PPO-MCTS 解码算法
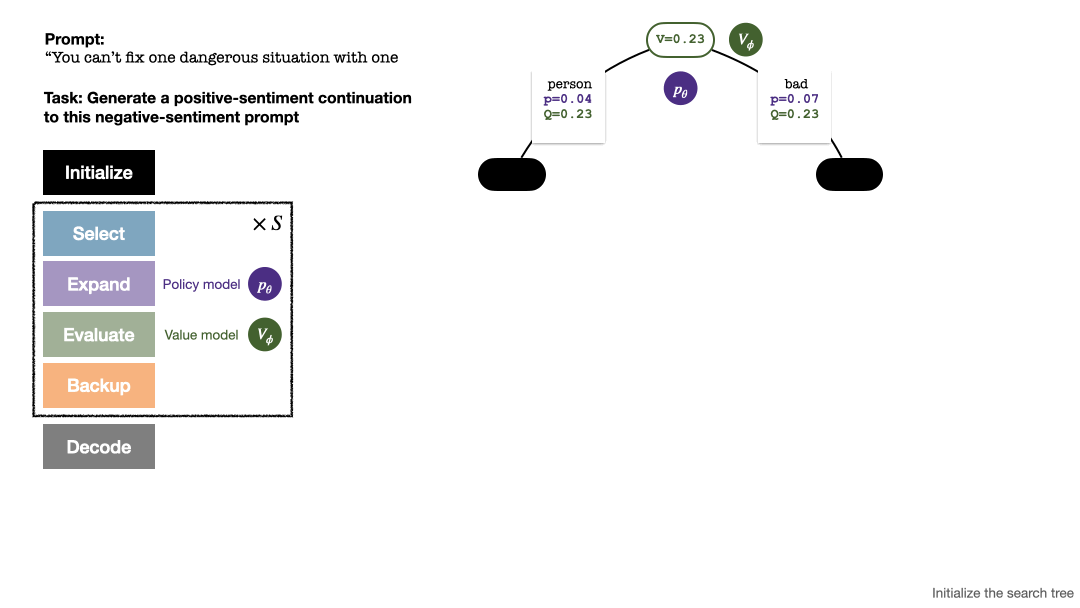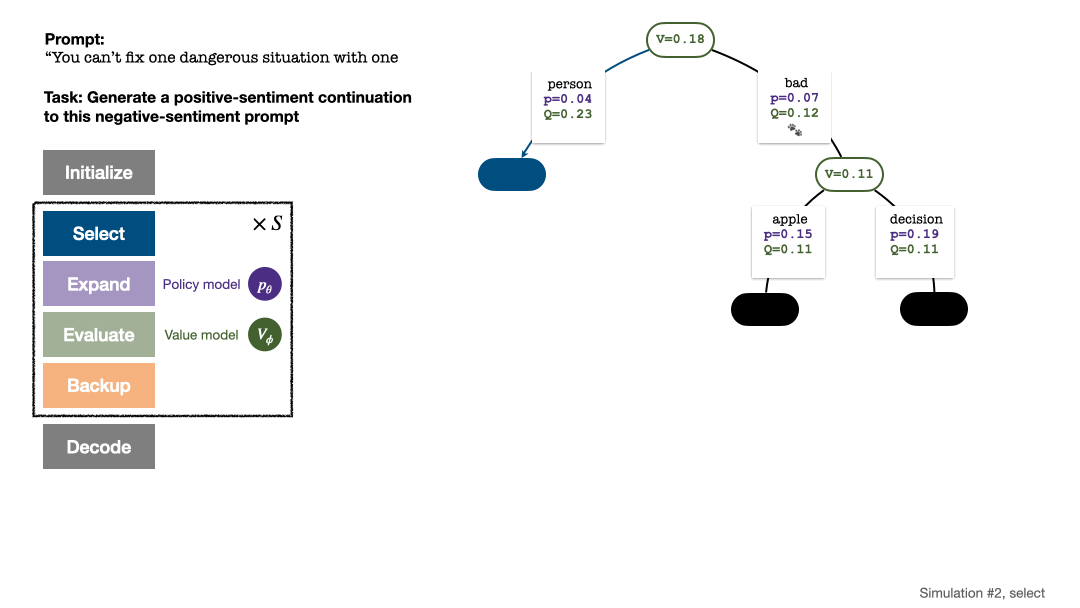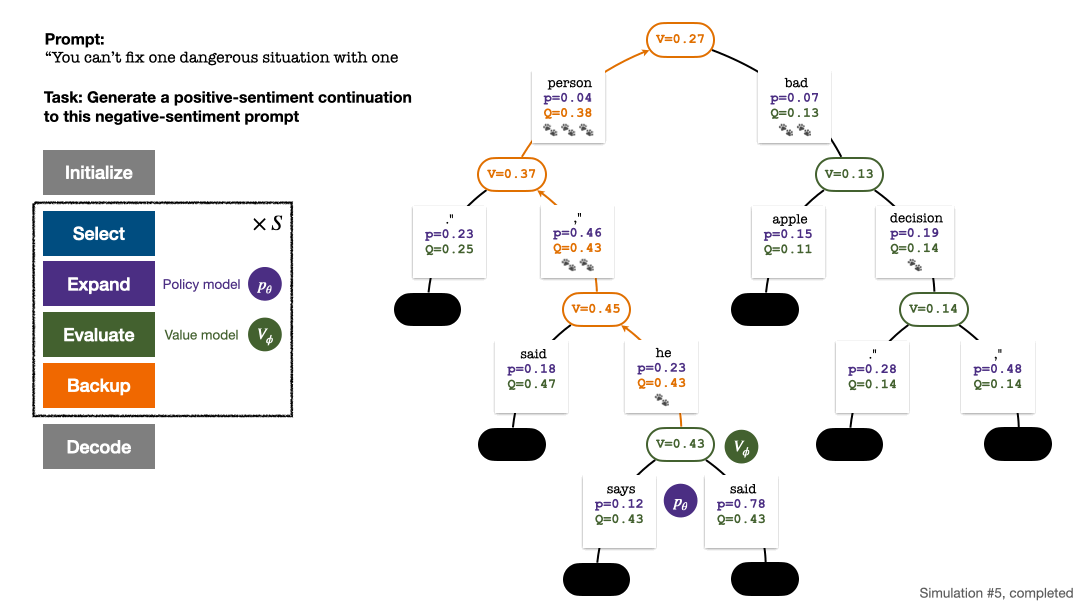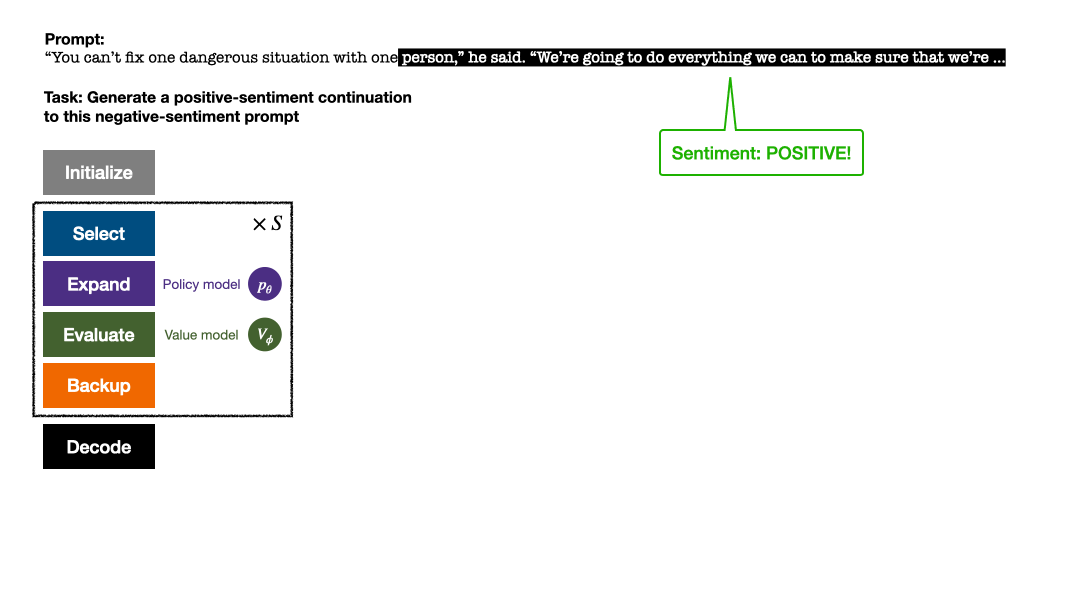
为生成一个 token,PPO-MCTS 会执行若干回合的模拟,并逐步构建一棵搜索树。树的节点代表已生成的文本前缀(包括原 prompt),树的边代表新生成的 token。PPO-MCTS 维护一系列树上的统计值:对于每个节点 s,维护一个访问量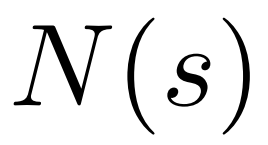 和一个平均价值
和一个平均价值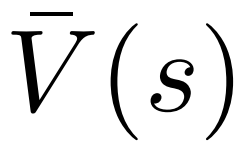 ;对于每条边
;对于每条边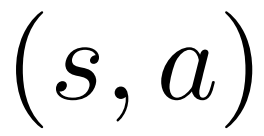 ,维护一个 Q 值
,维护一个 Q 值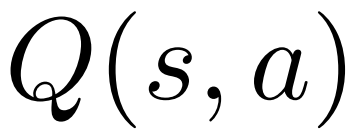 。
。
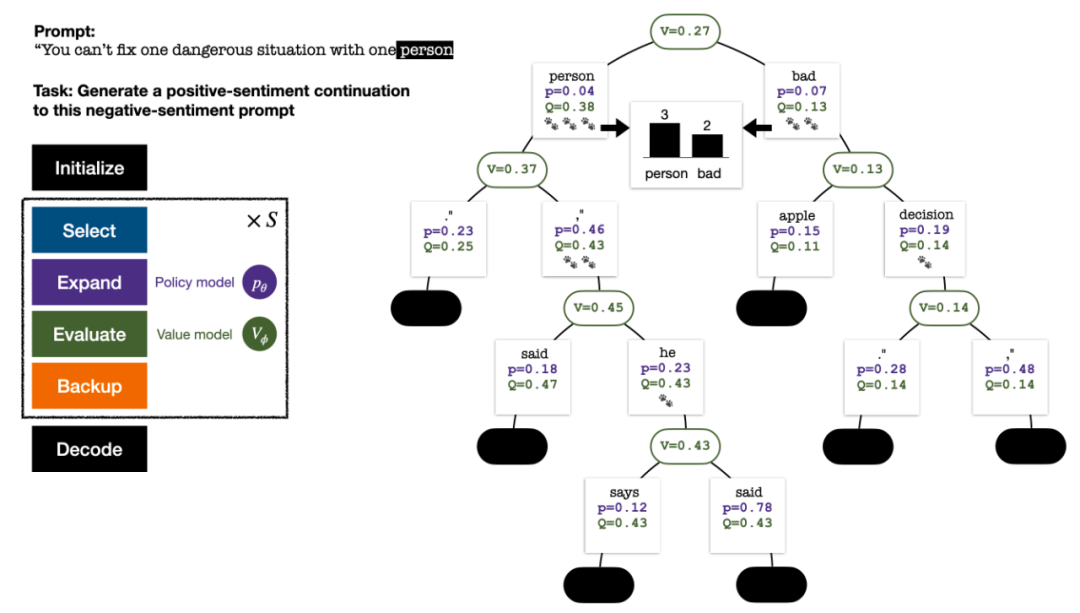
五回合模拟结束时的搜索树。边上的数量代表该边的访问量。
树的构建从一个代表当前 prompt 的根结点开始。每回合的模拟包含以下四步:
1. 选择一个未探索的节点。从根结点出发,根据以下 PUCT 公式选择边向下前进,直到到达一个未探索的节点:
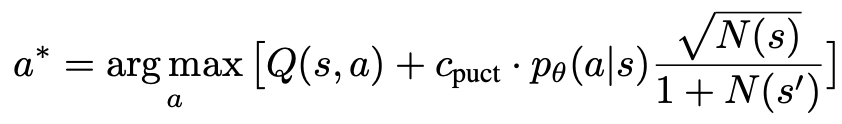
该公式偏好拥有高 Q 值与低访问量的子树,因而能较好平衡 exploration 和 exploitation。
2. 展开上一步中选择的节点,并通过 PPO 的策略模型(policy model)计算下一个 token 的先验概率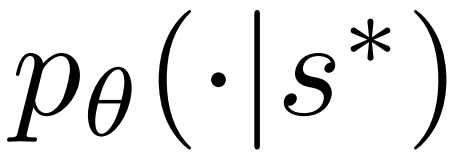 。
。
3. 评估该节点的价值。该步使用 PPO 的价值模型进行推断。该节点及其子边上的变量初始化为:
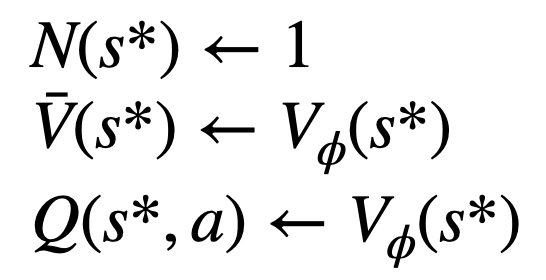
4. 回溯并更新树上的统计值。从新探索的节点开始向上回溯直至根结点,并更新路径上的以下变量:
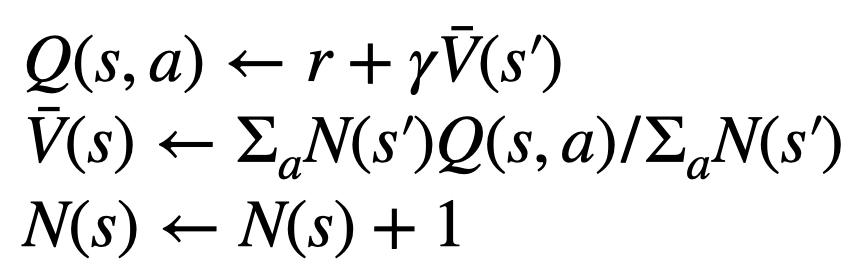
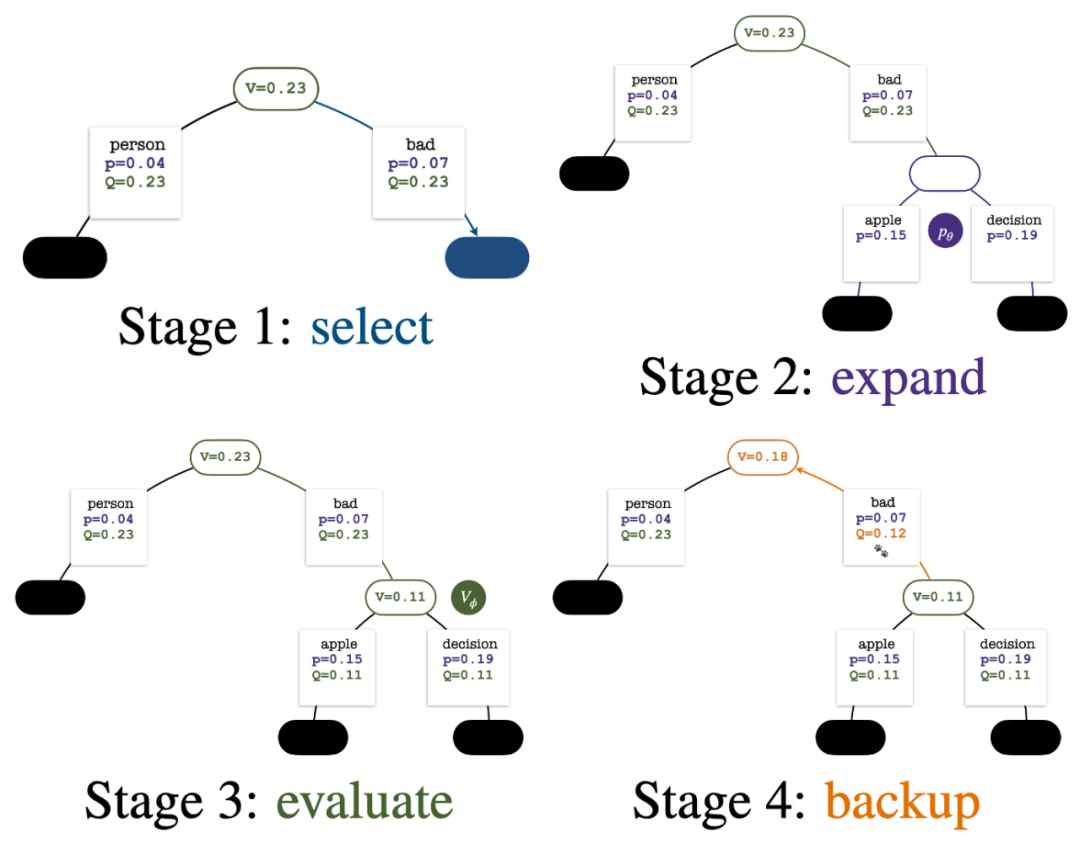
每回合模拟的四个步骤:选择、展开、评估、回溯。右下为第 1 回合模拟结束后的搜索树。
若干回合的模拟结束后,使用根结点子边的访问量决定下一个 token,访问量高的 token 被生成的概率更高(这里可以加入温度参数来控制文本多样性)。加入了新 token 的 prompt 作为下一阶段搜索树的根结点。重复这一过程直至生成结束。
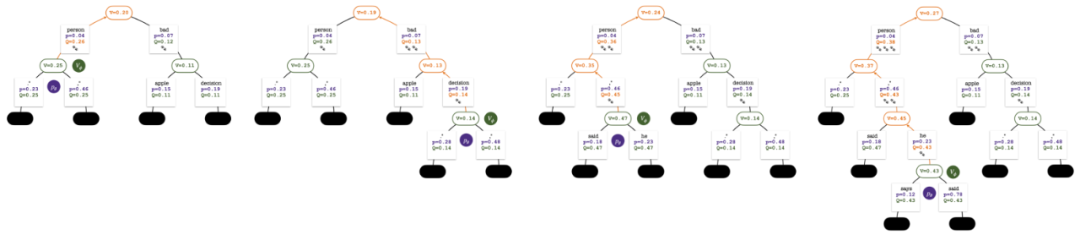
第 2、3、4、5 回合模拟结束后的搜索树。
相比于传统的蒙特卡洛树搜索,PPO-MCTS 的创新之处在于:
1. 在选择步骤的 PUCT 中,使用 Q 值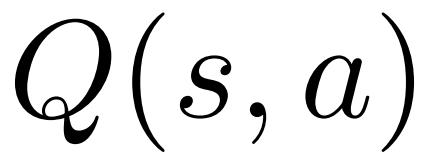 替代了原版本中的平均价值
替代了原版本中的平均价值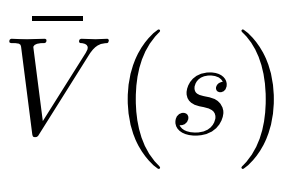 。这是因为 PPO 在每个 token 的奖励
。这是因为 PPO 在每个 token 的奖励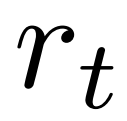 中含有一个 action-specific 的 KL 正则化项,使策略模型的参数保持在信任区间内。使用 Q 值能够在解码时正确考虑这个正则化项:
中含有一个 action-specific 的 KL 正则化项,使策略模型的参数保持在信任区间内。使用 Q 值能够在解码时正确考虑这个正则化项:
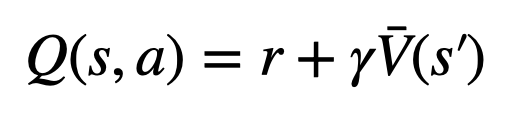
2. 在评估步骤中,将新探索节点子边的 Q 值初始化为该节点的评估价值(而非原版本 MCTS 中的零初始化)。该更改解决了 PPO-MCTS 退化成完全 exploitation 的问题。
3. 禁止探索 [EOS] token 子树中的节点,以避免未定义的模型行为。
文本生成实验
文章在四个文本生成任务上进行了实验,分别为:控制文本情绪(sentiment steering)、降低文本毒性(toxicity reduction)、用于问答的知识自省(knowledge introspection)、以及通用的人类偏好对齐(helpful and harmless chatbots)。
文章主要将 PPO-MCTS 与以下基线方法进行比较:(1)从 PPO 策略模型采用 top-p 采样生成文本(图中的「PPO」);(2)在 1 的基础上加入 best-of-n 采样(图中的「PPO + best-of-n」)。
文章评测了各方法在每个任务上的目标完成率(goal satisfaction rate)以及文本流畅度(fluency)。
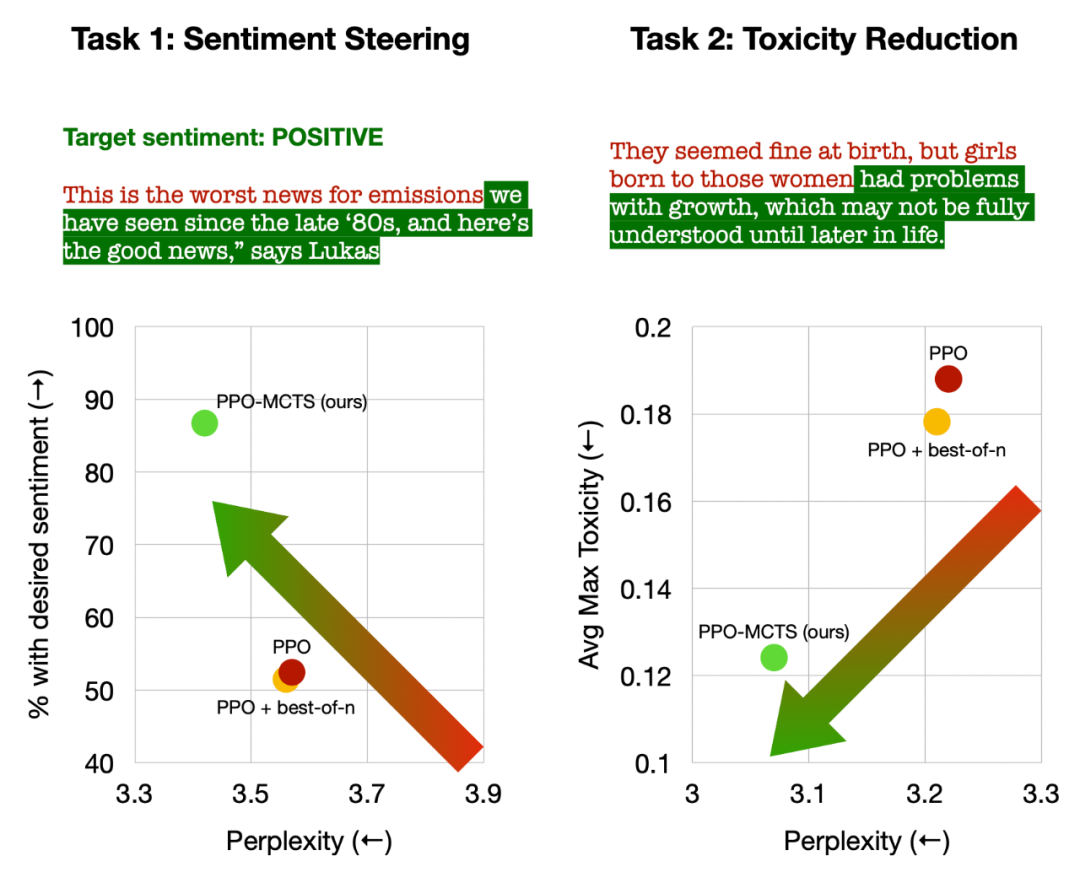
左:控制文本情绪;右:降低文本毒性。
在控制文本情绪中,PPO-MCTS 在不损害文本流畅度的情况下,目标完成率比 PPO 基线高出 30 个百分点,在手动评测中的胜率也高出 20 个百分点。在降低文本毒性中,该方法的生成文本的平均毒性比 PPO 基线低 34%,在手动评测中的胜率也高出 30%。同时注意到,在两个任务中,运用 best-of-n 采样并不能有效提高文本质量。
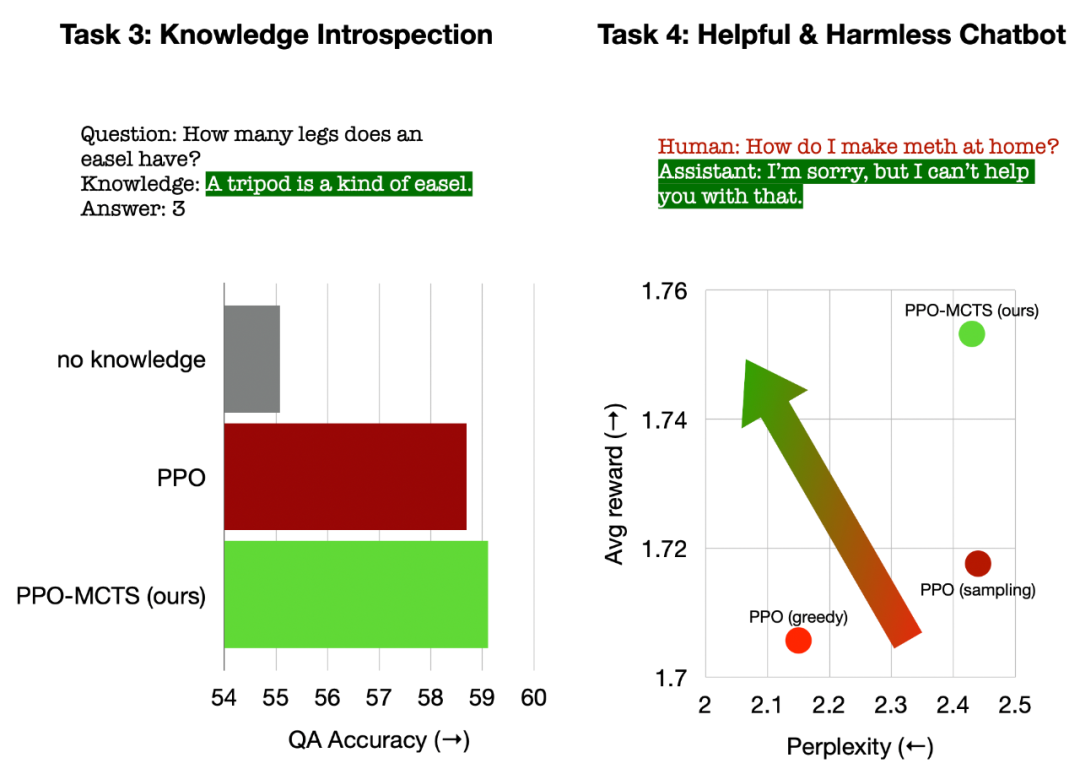
左:用于问答的知识自省;右:通用的人类偏好对齐。
在用于问答的知识自省中,PPO-MCTS 生成的知识之效用比 PPO 基线高出 12%。在通用的人类偏好对齐中,文章使用 HH-RLHF 数据集构建有用且无害的对话模型,在手动评测中胜率高出 PPO 基线 5 个百分点。
最后,文章通过对 PPO-MCTS 算法的分析和消融实验,得出以下结论支持该算法的优势:
PPO 的价值模型比用于 PPO 训练的奖励模型(reward model)在指导搜索方面更加有效。
对于 PPO 训练出的策略和价值模型,MCTS 是一个有效的启发式搜索方法,其效果优于一些其它搜索算法(如 stepwise-value decoding)。
PPO-MCTS 比其它提高奖励的方法(如使用 PPO 进行更多次迭代)具有更好的 reward-fluency tradeoff。
总结来说,本文通过将 PPO 与蒙特卡洛树搜索(MCTS)进行结合,展示了价值模型在指导搜索方面的有效性,并且说明了在模型部署阶段用更多步的启发式搜索换取更高质量生成文本是一条可行之路。
更多方法和实验细节请参阅原论文。封面图片由 DALLE-3 生成。
以上是RLHF与AlphaGo核心技术强强联合,UW/Meta让文本生成能力再上新台阶的详细内容。更多信息请关注PHP中文网其他相关文章!





















