


大数据文摘出品
家人们,继人工智能(AI)攻占象棋、围棋、Dota之后,转笔这一技能也被 AI 机器人学会了。

上面这个笔转的贼溜的机器人,得益于名叫Eureka的智能体(Agent),是来自英伟达、宾夕法尼亚大学、加州理工学院和得克萨斯大学奥斯汀分校的一项研究。
得Eureka“指点”后的机器人还可以打开抽屉和柜子、扔球和接球,或者使用剪刀。据英伟达介绍,Eureka有10种不同的类型,可执行29种不同的任务。
要知道在之前,单就转笔这一功能,仅靠人类专家手工编程,是无法如此顺滑的实现的。

机器人盘核桃
而Eureka 能够自主编写奖励算法来训练机器人,且码力强劲:自编的奖励程序在 83% 的任务中超越了人类专家,能使机器人的性能平均提升52%。
Eureka开创了一种从人类反馈中无梯度学习的新途径,它能够轻松吸收人类提供的奖励和文字反馈,从而进一步完善自己的奖励生成机制。
具体而言,Eureka 利用了 OpenAI 的 GPT-4 来编写用于机器人的试错学习的奖励程序。这意味着该系统并不依赖于人类特定任务的提示或预设的奖励模式。
Eureka 通过在 Isaac Gym 中使用 GPU 加速的仿真,能够快速评估大量候选奖励的优劣,从而实现更有效率的训练。接着,Eureka 会生成训练结果的关键统计信息摘要,并指导 LLM(Language Model,语言模型)改进奖励函数的生成。通过这种方式,AI 智能体能够独立地改善对机器人的指令。
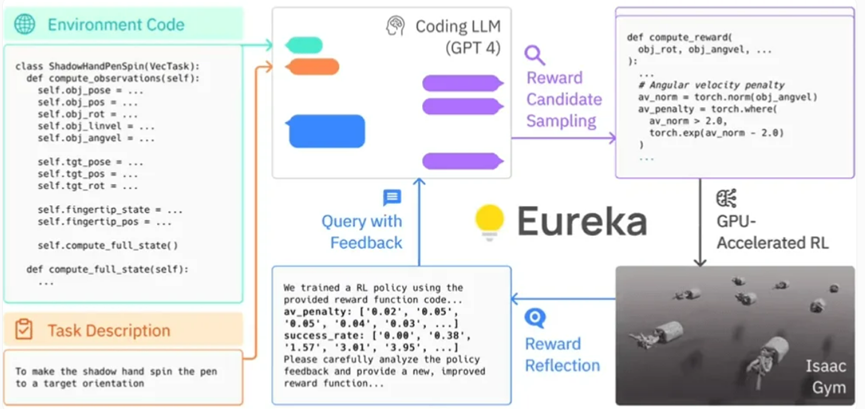
Eureka的框架
研究人员还发现,任务越复杂,GPT-4 的指令就越能优于所谓的"奖励工程师"的人类指令。参与该研究的研究员甚至称 Eureka 为“超人类奖励工程师”。
Eureka 成功地弥补了高层推理(编码)和低层运动控制之间的鸿沟。其采用了一种被称为 "混合梯度架构":一个纯推理的黑盒子 LLM(Language Model,语言模型)引导一个可学习的神经网络。在这个架构中,外层循环运行 GPT-4 来优化奖励函数(无梯度),而内层循环则运行强化学习以训练机器人的控制器(基于梯度)。
——NVIDIA的高级研究科学家Linxi "Jim" Fan
Eureka 可以整合人类的反馈,以便更好地调整奖励,使其更符合开发者的期望。Nvidia 把这个过程称为"in-context RLHF"(从人类反馈中进行上下文学习)
值得注意的是,Nvidia 的研究团队已经开源了 Eureka 的 AI 算法库。这将使得个人和机构能够通过 Nvidia Isaac Gym 来探索和实验这些算法。Isaac Gym 是建立在 Nvidia Omniverse 平台上的,这是一个基于 Open USD 框架用于创建 3D 工具和应用程序的开发框架。

在过去的十年中,强化学习取得了巨大的成功,但我们必须承认其中仍存在持续的挑战。之前虽然有尝试引入类似的技术,但与使用语言模型(LLM)来辅助奖励设计的 L2R(Learning to Reward)相比,Eureka 更为突出,因为它消除了特定任务提示的需要。Eureka 之所以能比 L2R 更出色,是因为它能够创建自由表达的奖励算法,并利用环境源代码作为背景信息。
英伟达的研究团队进行了一项调查,以探索在使用人类奖励函数启动时,是否能提供一些优势。实验的目的是想看看是否你们能顺利地用初始 Eureka 迭代的输出替代原始的人类奖励函数。
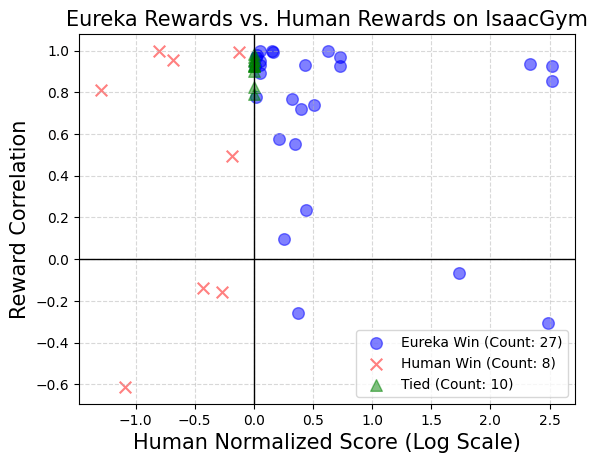
在测试中,英伟达的研究团队在每个任务的情境下,使用相同的强化学习算法和相同的超参数对所有最终奖励函数进行了优化。为了测试这些特定任务的超参数是否经过良好调整以确保人工设计的奖励的有效性,他们采用了经过充分调整的近端策略优化(PPO)实现,这个实现基于之前的工作,没有进行任何修改。对于每个奖励,研究人员进行了五次独立的 PPO 训练运行,并报告了策略检查点达到的最大任务指标值的平均值,作为奖励性能的度量。
结果显示:人类设计者通常对相关状态变量有很好的理解,但在设计有效奖励方面可能缺乏一定的熟练度。
Nvidia 的这项开创性研究在强化学习和奖励设计领域开辟了新的疆界。他们的通用奖励设计算法 Eureka 利用了大型语言模型和上下文进化搜索的力量,能够在广泛的机器人任务领域生成人类水平的奖励,而无需特定任务提示或人工干预,这在很大程度上改变了我们对 AI 和机器学习的理解。
以上是机器人学会转笔、盘核桃了!GPT-4加持,任务越复杂,表现越优秀的详细内容。更多信息请关注PHP中文网其他相关文章!





















