

你以为这是一个普通的自动驾驶视频吗?
 图片
图片
这个内容需要重新写成中文,而不改变原来的意思
没有一帧是“真的”。
 图片
图片
不同路况、各种天气,20多种情况都能模拟,效果以假乱真。
 图片
图片
世界模型再次立大功了!这不LeCun看了都激情转发。
 图片
图片
根据上述效果,这是由GAIA-1的最新版本带来的
这个项目的规模达到了90亿参数,通过4700小时的驾驶视频训练,成功实现了输入视频、文本或操作生成自动驾驶视频的效果
带来的最直接好处就是——能更好预测未来事件,20多种场景都能模拟,从而进一步提升了自动驾驶的安全性、还降低了成本。
 图片
图片
我们的主创团队直言不讳地表示,这将彻底改变自动驾驶的游戏规则!
所以GAIA-1是如何实现的?
GAIA-1是一个具有多种模式的生成式世界模型
通过利用视频、文本和动作作为输入,该系统可以生成逼真的驾驶场景视频,并且可以对自主车辆的行为和场景特征进行精细控制
可以通过仅使用文本提示来生成视频
 图片
图片
其模型原理类似于大型语言模型,即预测下一个标记
模型可以利用向量量化表示将视频帧离散,然后预测未来场景,就转换成了预测序列中的下一个token。然后再利用扩散模型从世界模型的语言空间里生成高质量视频。
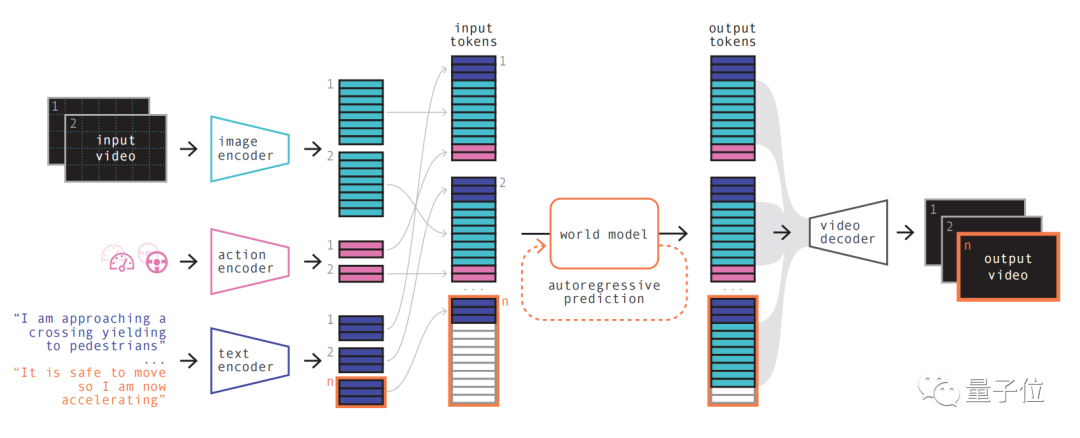
具体步骤如下:
 图片
图片
第一步简单理解,就是对各种输入进行重新编码和排列组合。
通过使用专门的编码器对各种输入进行编码,并将不同的输入投射到共享表示中。文本和视频编码器将输入分离、嵌入,而操作表示则被单独投射到共享表示中
这些编码的表示具有时间一致性。
在进行排列之后,关键部分世界模型登场。
作为一个自回归Transformer,它能预测序列中的下一组图像token。而且它不仅考虑了之前的图像token,还要兼顾文本和操作的上下文信息。
模型生成的内容不仅保持了图像的一致性,还能与预测的文本和动作保持一致
团队介绍,GAIA-1中的世界模型规模为65亿参数,在64块A100上训练15天而成。
最后再利用视频解码器、视频扩散模型,将这些token转换回视频。
这一步的重要性在于确保视频的语义质量、图像准确性和时间一致性
GAIA-1的视频解码器规模达26亿参数规模,利用32台A100训练15天而来。
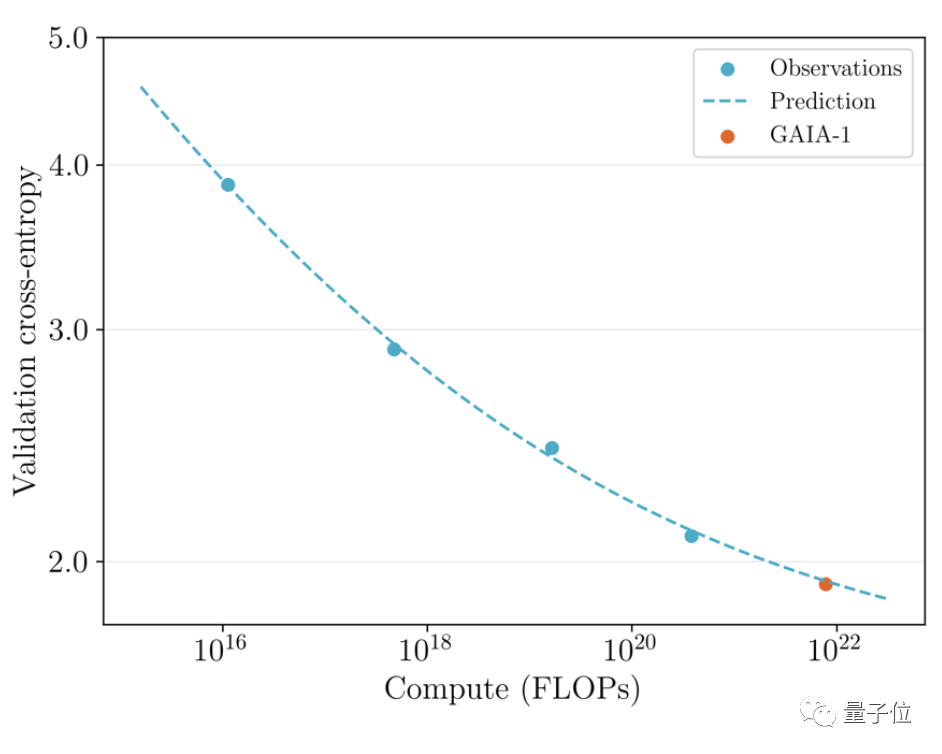
值得一提的是,GAIA-1不仅与大型语言模型的原理相似,而且还展现出随着模型规模扩大,生成质量提升的特点
 图片
图片
团队对之前发布的六月早期版本和最新效果进行了比较
后者规模为前者的480倍。
可以直观看到视频在细节、分辨率等方面都有明显提升。
 图片
图片
从实际应用的角度来看,GAIA-1的出现也带来了一些影响,其主创团队表示,这将改变自动驾驶的规则
 图片
图片
原因可以从三个方面来解释:
首先安全方面,世界模型能够通过模拟未来,让AI有能力意识到自己的决定,这对自动驾驶的安全性来说很关键。
其次,对于自动驾驶来说,训练数据也是非常重要的。生成的数据具有更高的安全性和成本效益,并且可以无限扩展
生成式AI可以解决自动驾驶面临的长尾场景挑战之一。它可以处理更多边缘场景,例如在大雾天气中遇到横穿马路的行人。这将进一步提高自动驾驶的能力
GAIA-1是由英国自动驾驶初创公司Wayve开发的
Wayve成立于2017年,投资方有微软等,估值已经达到了独角兽。
创始人是亚历克斯·肯德尔和艾玛尔·沙,他们都是剑桥大学的机器学习博士
 图片
图片
技术路线上,和特斯拉一样,Wayve主张利用摄像头的纯视觉方案,很早就抛弃高精地图,坚定的走“即时感知”路线。
前不久,该团队发布的另一个大模型LINGO-1也引起了广泛关注
这个自动驾驶模型能够在行车过程中实时生成解说,从而进一步提高了模型的可解释性
今年3月,比尔·盖茨还曾试乘过过Wayve的自动驾驶汽车。
 图片
图片
论文地址://m.sbmmt.com/link/1f8c4b6a0115a4617e285b4494126fbf
参考链接:
[1]//m.sbmmt.com/link/85dca1d270f7f9aef00c9d372f114482[2]//m.sbmmt.com/link/a4c22565dfafb162a17a7c357ca9e0be
以上是LeCun对自动驾驶独角兽的造假行为深感失望的详细内容。更多信息请关注PHP中文网其他相关文章!


































