

本周,国际计算机视觉大会 ICCV(International Conference on Computer Vision)在法国巴黎开幕。

作为全球计算机视觉领域顶级的学术会议,ICCV 每两年召开一次。
和 CVPR 一样,ICCV 的热度屡创新高。
在今天的开幕式上,ICCV 官方公布了今年的论文数据:本届 ICCV 投稿总数达到 8068 篇,其中有 2160 篇被接收,录用率为 26.8%,略高于上一届 ICCV 2021 的录用率 25.9%
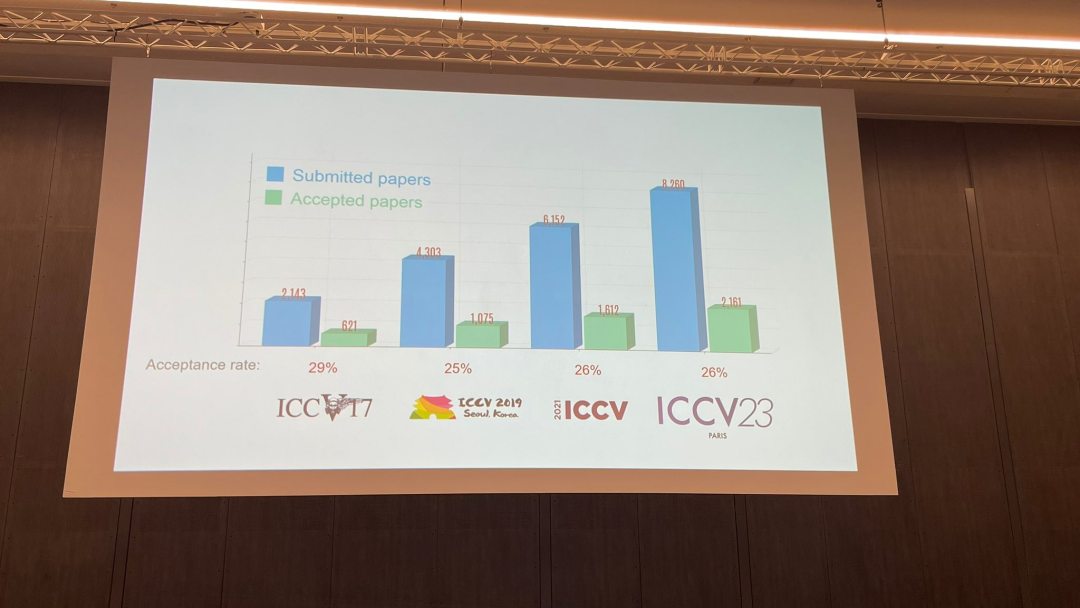
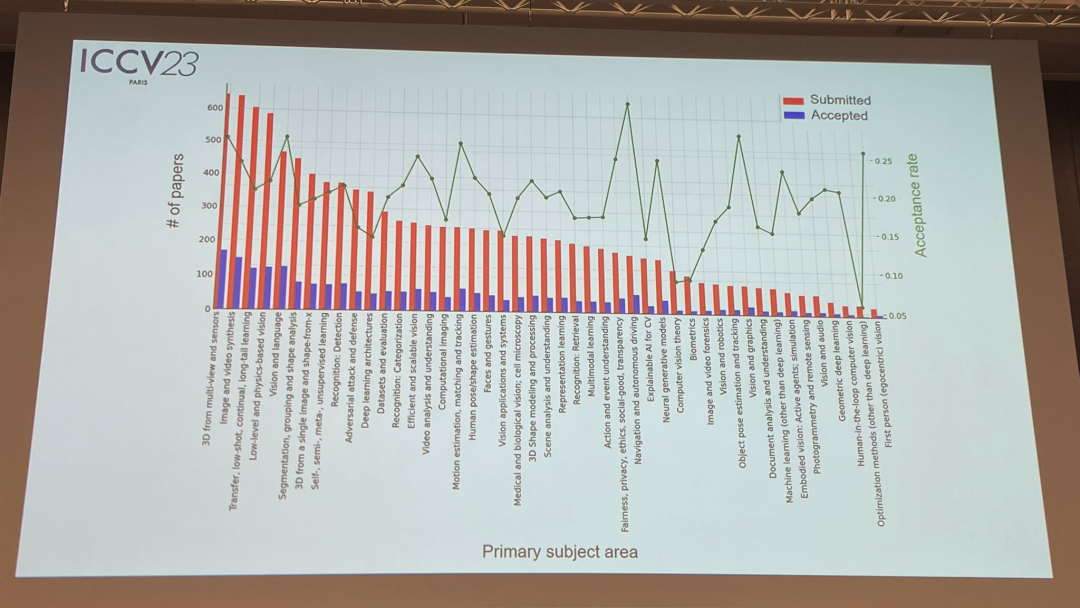
关于论文主题,官方也发布了相关数据:多视角和传感器的3D技术热度最高
在今天的开幕式上,最重要的部分是宣布获奖信息。现在,让我们逐一揭晓最佳论文、最佳论文提名和最佳学生论文
共有两篇论文获得今年的最佳论文(马尔奖)。
第一篇来自多伦多大学的研究者。

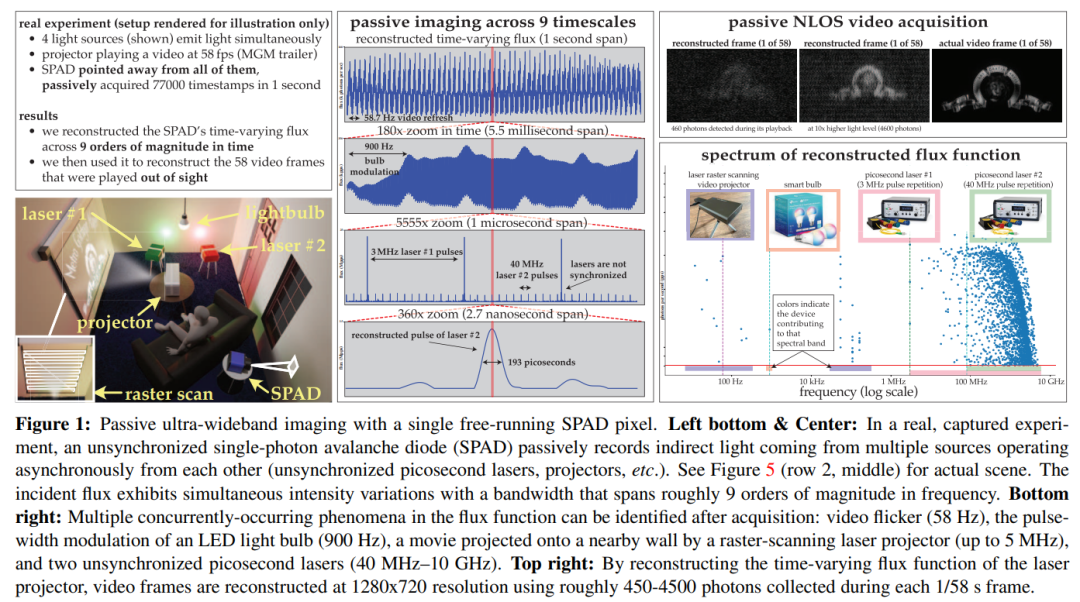
摘要:本文考虑在极端的时间尺度范围内,同时(秒到皮秒)对动态场景进行成像的问题,并且是被动地进行成像,没有太多的光,也没有来自发射它的光源的任何定时信号。由于单光子相机现有的通量估计(flux estimation)技术在这种情况下会失效,因此本文开发了一种通量探测理论,该理论从随机微积分中汲取见解,从而能够从单调增加的光子检测时间戳流中重建像素的时变通量。
本文利用这一理论来表明,无源自由运行SPAD相机在低通量条件下具有可实现的频率带宽,可以跨越整个DC到31 GHz的范围。同时,本文还推导出了一种新颖的傅里叶域通量重建算法,并确保该算法的噪声模型在非常低的光子计数或不可忽略的死区时间下仍然有效
通过实验展示了这种异步成像机制的潜力:(1)对于由以不同速度运行的光源(如灯泡、投影仪、多个脉冲激光器)同时照明的场景进行成像,无需同步;(2)实现被动非视距视频采集;(3)记录超宽带视频,稍后以30 Hz的速度播放以展示日常运动,也可以以慢十亿倍的速度播放以展示光本身的传播
第二篇就是我们所熟知的 ControNet。

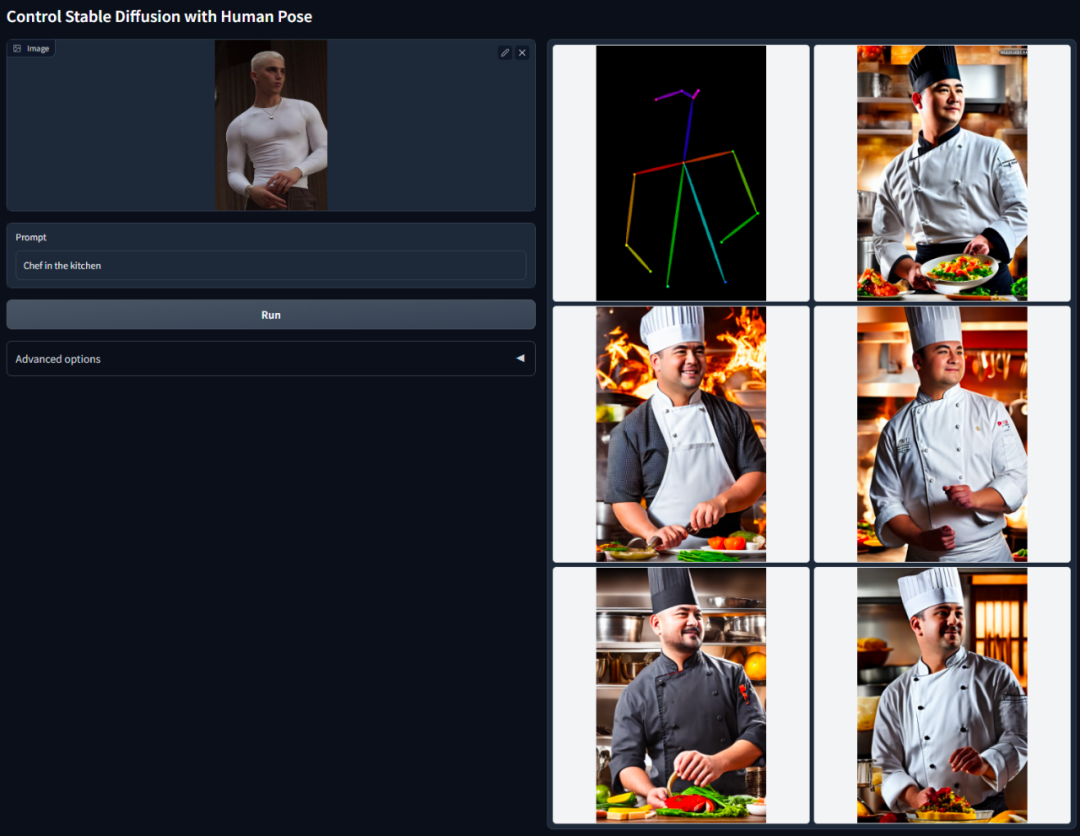
摘要:本研究提出了一种名为ControlNet的端到端神经网络架构。该架构通过添加额外的条件来控制扩散模型(如稳定扩散),以改善图像生成效果。同时,ControlNet能够实现线稿生成全彩图、生成具有相同深度结构的图像,并通过手部关键点优化手部生成效果等
ControlNet 的核心思想是在文本描述之外添加一些额外条件来控制扩散模型(如 Stable Diffusion),从而更好地控制生成图像的人物姿态、深度、画面结构等信息。
这里的额外条件以图像的形式来输入,模型可以基于这张输入图像进行 Canny 边缘检测、深度检测、语义分割、霍夫变换直线检测、整体嵌套边缘检测(HED)、人体姿态识别等,然后在生成的图像中保留这些信息。利用这一模型,我们可以直接把线稿或涂鸦转换成全彩图,生成具有同样深度结构的图等等,通过手部关键点还能优化人物手部的生成。
请参阅机器之心的报道《AI降维打击人类画家,文生图引入ControlNet,深度、边缘信息全能复用》以获取更详细的介绍
今年四月,Meta发布了名为「分割一切(SAM)」的人工智能模型,该模型能够为任何图像或视频中的物体生成掩码,这让计算机视觉领域的研究者们感到非常震惊,有人甚至说「计算机视觉不复存在了」
如今,这篇备受关注的论文摘的最佳论文提名。

重写后的内容:在解决分割问题之前,通常有两种方法。第一种是交互式分割,这种方法可以用来分割任何类别的对象,但需要一个人通过迭代细化掩码来指导该方法。第二种是自动分割,可以用来分割预先定义的特定对象类别(例如猫或椅子),但需要大量手动注释对象来进行训练(例如数千甚至数万个分割猫的例子)。然而,这两种方法都没有提供通用的、全自动的分割方法
Meta 提出的 SAM 很好的概括了这两种方法。它是一个单一的模型,可以轻松地执行交互式分割和自动分割。该模型的可提示界面允许用户以灵活的方式使用它,只需为模型设计正确的提示(点击、框选、文本等),就可以完成范围广泛的分割任务
总结一下,这些功能使得SAM能够适应新的任务和领域。这种灵活性在图像分割领域是独一无二的
详细介绍请参考机器之心报道:《CV 不存在了?Meta 发布「分割一切」AI 模型,CV 或迎来 GPT-3 时刻》
该研究由来自康奈尔大学、谷歌研究院和 UC 伯克利的研究者共同完成,一作是来自 Cornell Tech 的博士生 Qianqian Wang。他们联合提出了一种完整且全局一致的运动表征 OmniMotion,并提出一种新的测试时(test-time)优化方法,对视频中每个像素进行准确、完整的运动估计。

摘要:在计算机视觉领域,常用的运动估计方法有两种:稀疏特征追踪和密集光流。但这两种方法各有缺点,稀疏特征追踪不能建模所有像素的运动;密集光流无法长时间捕获运动轨迹。
该研究提出的 OmniMotion 使用 quasi-3D 规范体积来表征视频,并通过局部空间和规范空间之间的双射(bijection)对每个像素进行追踪。这种表征能够保证全局一致性,即使在物体被遮挡的情况下也能进行运动追踪,并对相机和物体运动的任何组合进行建模。该研究通过实验表明所提方法大大优于现有 SOTA 方法。
请参考机器之心报道《随时随地,追踪每个像素,连遮挡都不怕的「追踪一切」视频算法来了》以获取更详细的介绍
今年 ICCV 除了这些获奖论文外,还有许多其他优秀论文值得大家关注。以下是17篇获奖论文的初始清单

以上是ICCV 2023宣布ControlNet和「分割一切」等热门论文获奖的详细内容。更多信息请关注PHP中文网其他相关文章!





















