

语言模型受不同词表的影响有哪些?如何平衡这些影响?
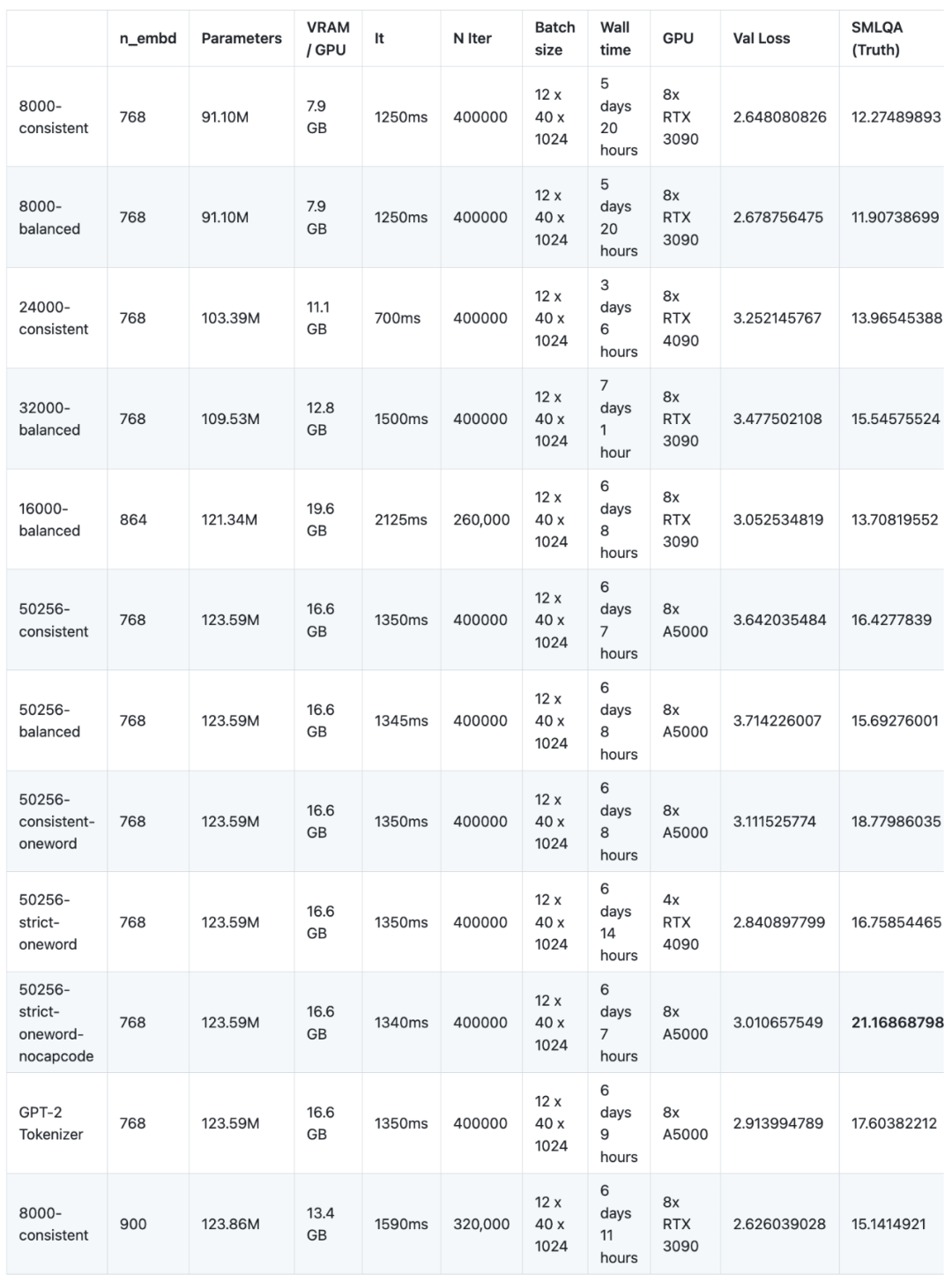
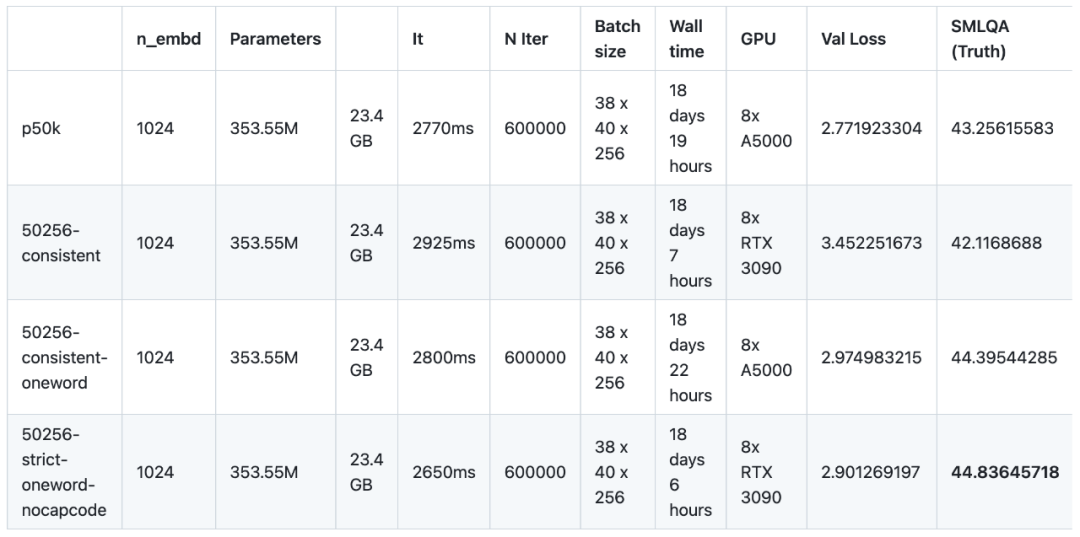
在最近的一项实验中,研究者对16个语言模型进行了不同的语料预训练和微调。这次实验使用了NanoGPT,一种小规模的架构(基于GPT-2 SMALL),共训练了12个模型。NanoGPT的网络架构配置为:12个注意力头、12层transformer,词嵌入维度为768,进行了大约400,000次迭代(约10个epoch)。然后在GPT-2 MEDIUM上训练了4个模型,GPT-2 MEDIUM的架构设置为16个注意力头、24层transformer,词嵌入维度为1024,并进行了600,000次迭代。所有模型都使用了NanoGPT和OpenWebText数据集进行预训练。在微调方面,研究者使用了baize-chatbot提供的指令数据集,在两类模型中分别补充了额外的20,000和500,000个“字典”条目
在未来,研究人员计划发布代码、预训练模型、指令调整模型和微调数据集
然而,由于缺乏GPU赞助商(这是一个免费的开源项目),为了降低成本,研究者目前没有继续进行下去,尽管还有进一步完善研究内容的空间。在预训练阶段,这16个模型需要在8个GPU上累计运行147天(单个GPU需要使用1,176天),成本为8,000美元
研究结果可总结为:
根据实验结果,englishcode-32000-consistent 的结果是最好的。然而,如上所述,当使用在单个 token 对应多个单词的 TokenMonster 时,SMLQA( Ground Truth)的准确性和字词比之间会存在一种权衡,这增加了学习曲线的斜率。研究者坚信,通过强制 80% 的 token 对应一个单词,20% 的 token 对应多个单词,可以最大限度地减少这种权衡,实现 “两全其美” 的词表。研究者认为这种方法在性能上与 one-word 词表相同,同时字词比还能提高约 50%。
这句话的含义是,分词器中的缺陷和复杂性对模型学习事实的能力的影响大于对其语言能力的影响
这种现象是训练过程中发现的一个有趣的特征,从模型训练的工作方式去思考,也能说得通。研究者没有证据证明其推理是合理的。但从本质上讲,因为在反向传播过程中,语言的流畅性比语言的事实性(它们是极其微妙和依赖上下文的)更容易纠正,这意味着分词器效率若有任何提高,与事实性无关,都会产生直接转化为信息保真度提高的连锁反应,如在 SMLQA(Ground Truth)基准中所见。简单地说:一个更好的分词器就是一个更真实的模型,但不一定是一个更流畅的模型。反过来说:一个拥有低效分词器的模型仍然能学会流利地写作,但流利性的额外成本会降低模型的可信度。
在进行这些测试之前,研究人员认为32000是最佳的词表规模,并且实验结果也证实了这一点。50256-balanced模型的性能仅比SMLQA(Ground Truth)基准上的32000-balanced模型好1%,但是模型的尺寸却增加了13%。为了明确证明这一观点,在基于MEDIUM的多个模型中,本文通过在词表规模为24000、32000、50256和100256的词表中进行二八开划分的方法进行了实验
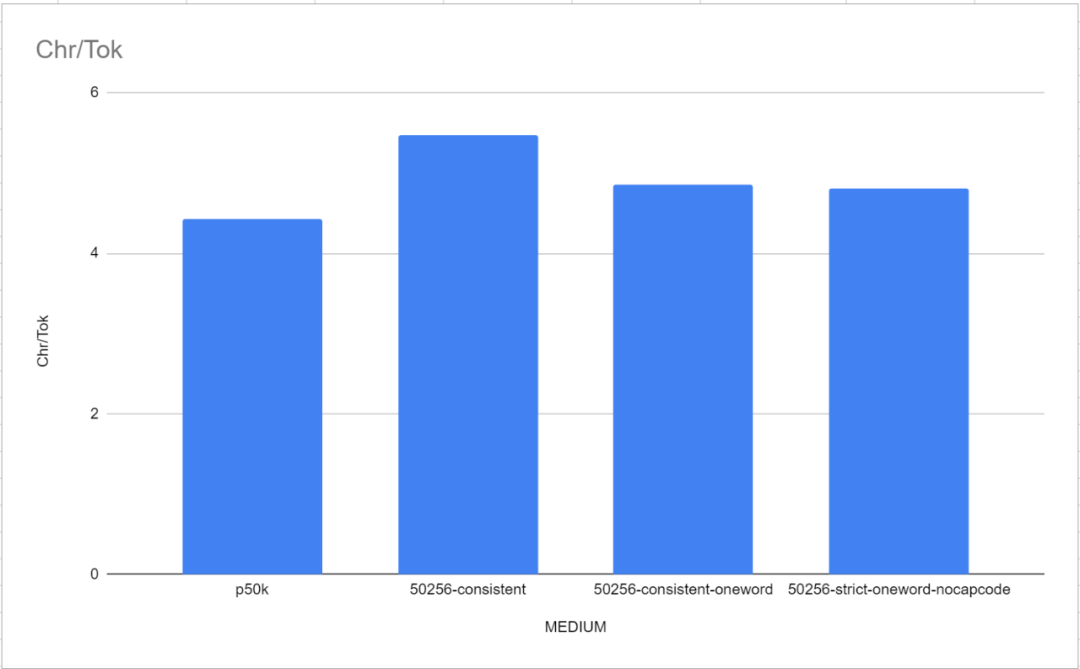
研究者对TokenMonster进行了测试,测试了三种特定的优化模式:balanced、consistent和strict。不同的优化模式会影响标点符号与capcode与单词token的组合方式。研究者最初预测consistent模式会表现更好(因为它不那么复杂),尽管字词比(即字符与token的比值)会稍低
实验结果似乎证实了上述猜想,但是研究者也观察到了一些现象。首先,在 SMLQA(Ground Truth)基准上,consistent 模式似乎比 balanced 模式的效果好约 5%。然而,consistent 模式在 SQuAD(Data Extraction)基准上的表现明显较差(28%)。但是,SQuAD 基准表现出很大的不确定性(重复运行的结果不同),也不具有说服力。研究者并没有对 balanced 与 consistent 测试至收敛,所以这可能只代表 consistent 模式更容易学习。事实上,consistent 可能在 SQuAD(数据提取)上做得更好,因为 SQuAD 更难学习,也不太可能产生幻觉。
这本身就是一个有趣的发现,因为它意味着将标点符号和单词合并到一个 token 中并不存在明显的问题。迄今为止,所有其他分词器都认为标点符号应与字母分开,但从这里的结果可以看出,单词和标点符号可以合并到一个 token 中,不会有明显的性能损失。50256-consistent-oneword 也证实了这一点,这个组合与 50256-strict-oneword-nocapcode 的性能相当,而且优于 p50k_base。50256-consistent-oneword 将简单的标点符号与单词 token 合并在一起(而其他两个组合则不是这样)。
在启用 capcode 的 strict 模式之后,会带来明显的负面影响。在 SMLQA 上,50256-strict-oneword-nocapcode 得分为21.2,在 SQuAD 上得分为23.8,而 50256-strict-oneword 的得分分别为16.8和20.0。原因很明显:strict 优化模式阻止了 capcode 与单词 token 的合并,导致需要更多的 token 来表示相同的文本,结果就是字词比降低了8%。实际上,与 strict 模式相比,strict-nocapcode 更类似于 consistent。在各个指标上,50256-consistent-oneword 和 50256-strict-oneword-nocapcode 几乎相等
在大多数情况下,研究者得出的结论是,模型对于学习包含标点符号和单词的 token 的含义并没有太大困难。也就是说,与平衡模型相比,一致性模型在语法准确性方面更高,语法错误更少。综合考虑,研究者建议大家使用一致性模式。严格模式只能在禁用 capcode 的情况下使用
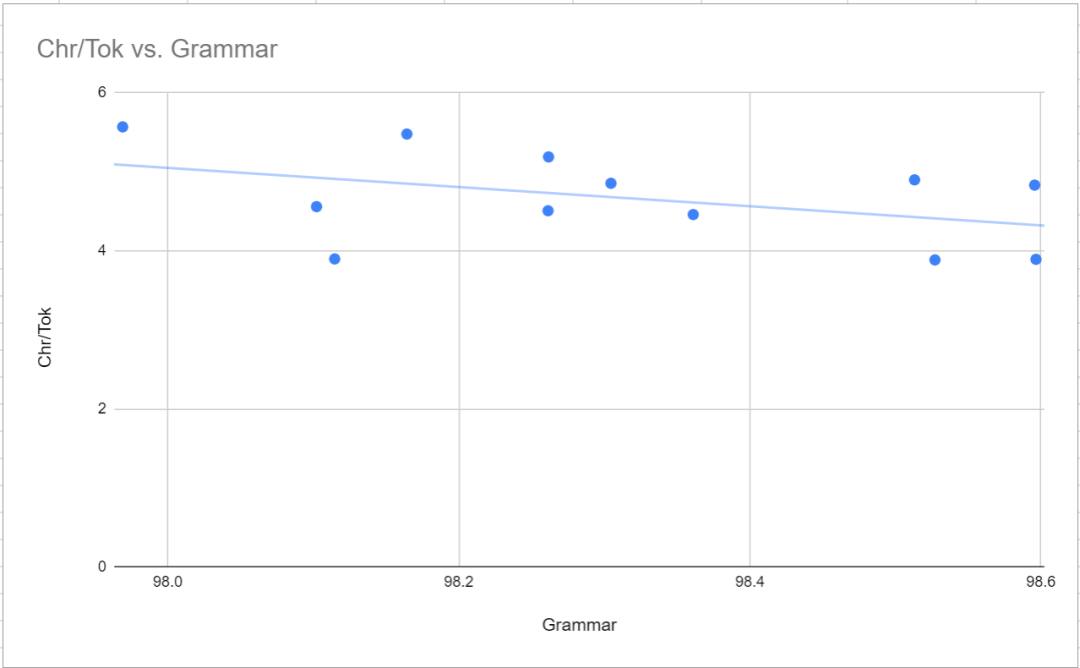
如上所述,与 balanced 模式相比,consistent 模式的语法准确性更高(语法错误更少)。这反映在字词比和语法之间存在非常轻微的负相关,如下图所示。除此之外,最值得注意的一点是,同样与 TokenMonster 的 50256-strict-oneword-nocapcode (98.6% 和 98.4%)相比,GPT-2 分词器和 tiktoken p50k_base 的语法结果都很糟糕(分别为 98.1% 和 97.5%)。研究者最初认为这只是巧合,但多次采样都会得到相同范围的结果。至于原因是什么尚不清楚。
MTLD 是用来表示生成样本文本的语言多样性的。它似乎与 n_embed 参数密切相关,而与词汇量大小、优化模式或每个 token 的最大字数等特征无关。这一点在 6000-balanced 模型(n_embd 为 864)和 8000-consistent 模型(n_embd 为 900)中表现得尤为明显
在中型模型中, p50k_base 的 MTLD 最高,为 43.85,但语法得分也最低。造成这种情况的原因尚不清楚,但研究者猜测可能是训练数据的选择有些奇特。
SQuAD基准测试的目的是评估模型从一段文字中提取数据的能力。具体方法是提供一段文字,并提出一个问题,要求答案必须在该段文字中找到。测试结果并没有太大的意义,没有明显的模式或相关性,也不受模型总参数的影响。实际上,拥有9100万参数的8000-balanced模型在SQuAD中得分高于拥有35400万参数的50256-consistent-oneword模型。造成这种情况的原因可能是这种风格的样例不够多,或者在微调数据集中有太多的问答对。或者,这只是一个不太理想的基准测试
SMLQA 基准通过提出具有客观答案的常识性问题来测试 "真值",例如 "哪个国家的首都是雅加达?" 和 "《哈利 - 波特》系列丛书是谁写的?"。
值得注意的是,在这个基准测试中,GPT-2 Tokenizer和p50k_base这两个参考用的分词器表现非常出色。研究者最初认为他们浪费了几个月的时间和几千美元,但结果证明tiktoken的性能比TokenMonster更好。然而,事实证明问题与每个token所对应的字数有关。这一点在"中等"(MEDIUM)模型中表现得尤为明显,如下图所示
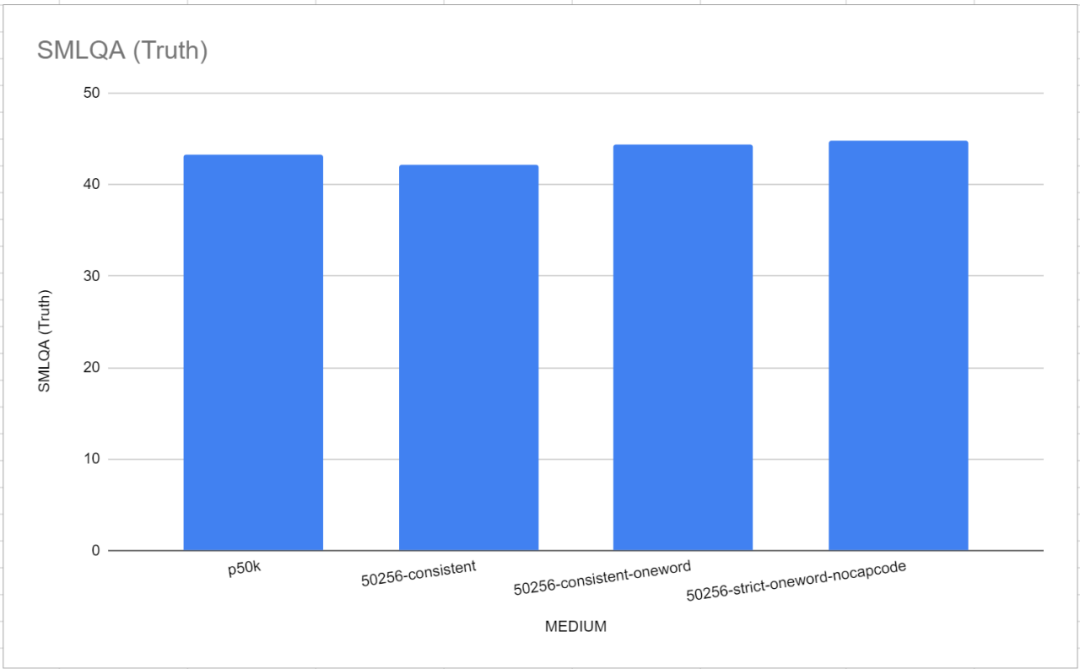
 单字词表的性能略好于 TokenMonster 默认的每个 token 对应多个字的词表。
单字词表的性能略好于 TokenMonster 默认的每个 token 对应多个字的词表。
另一个重要的观察结果是,词汇量低于32,000个时,即使调整模型的n_embd参数以弥补模型规模的缩小,词汇量也会直接影响真值。这一点与直觉相悖,因为研究者原本以为n_embd为864的16000-balanced(参数为1.2134亿)和n_embd为900的8000-consistent(参数为1.2386亿)会比n_embd为768的50256-consistent(参数为1.2359亿)表现更好,但事实并非如此——两者的表现都差得多(13.7和15.1对比50256-consistent的16.4)。不过,这两个“调整后”的模型都接受了相同的训练时间,这导致预训练的次数显着减少(尽管时间相同)
研究人员在默认的NanoGPT架构上进行了12个模型的训练。该架构基于12个注意力头和12层的GPT-2架构,嵌入参数大小为768。这些模型都没有达到收敛状态,简单来说,就是没有达到最大的学习能力。模型的训练经历了400,000次迭代,但似乎需要600,000次迭代才能达到最大的学习能力。造成这种情况的原因很简单,一是预算问题,二是收敛点的不确定性
小模型的结果:
小模型的皮尔逊相关性:
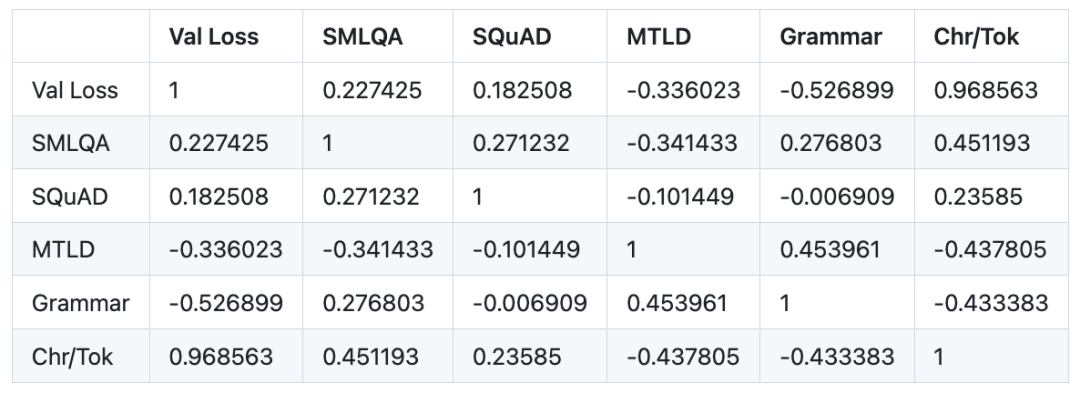
小模型的结论:
重写后的内容:在词汇量为32,000时,达到了最佳的词汇量水平。在从8,000到32,000的词汇量增加阶段中,增加词汇量可以提高模型的准确度。然而,当词汇量从32,000增加到50,257时,模型的总参数也相应增加,但对准确度的提升仅为1%。超过32,000后,增益迅速减少
糟糕的分词器设计会对模型的准确性产生影响,但不会影响语法的正确性或语言的多样性。在参数范围为9000万至1.25亿之间,语法规则更复杂的分词器(例如对应多个词、词和标点符号组合的标记、capcode编码标记以及减少总词汇量)在真值基准上的表现较差。然而,这种复杂的分词器设计并没有对生成文本的语言多样性或语法正确性产生显着的统计学影响。即使是一个紧凑的模型,如参数为9000万的模型,也能有效地利用更复杂的标记。更复杂的词汇需要更长的学习时间,从而减少了获取与基本事实相关信息的时间。由于这些模型都没有经过完整的训练,因此进一步训练以缩小性能差距的潜力还有待观察
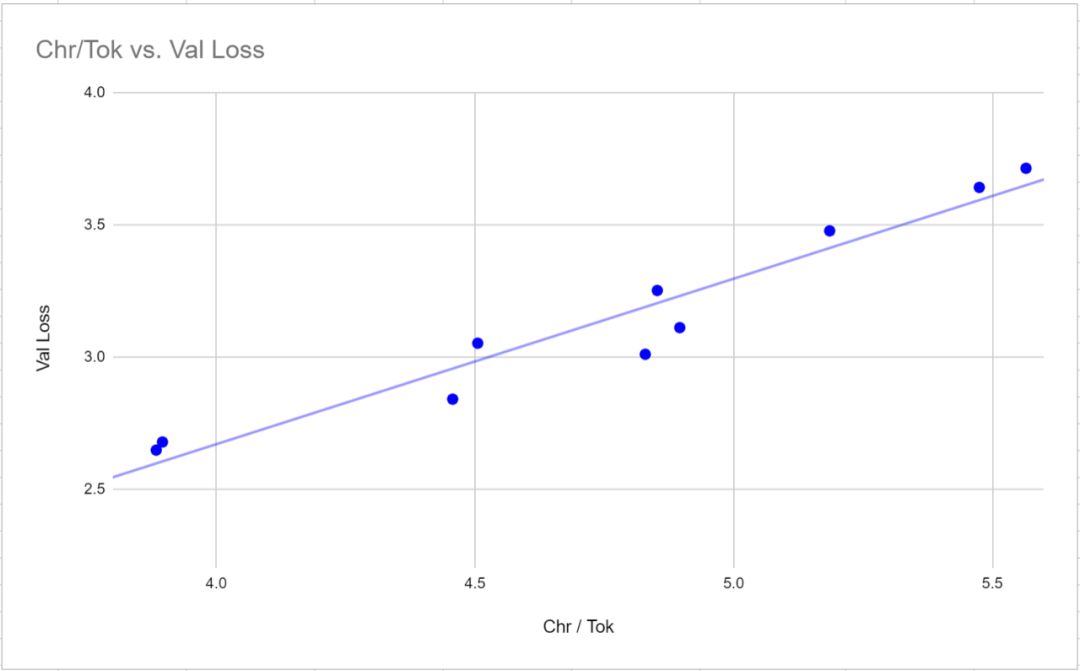
重新写成中文: 3. 验证损失不是比较使用不同分词器模型的有效指标。验证损失与给定分词器的字词比(每个标记对应的平均字符数)具有非常强的相关性(0.97 皮尔逊相关性)。要想比较分词器之间的损失值,测量相对于字符而非标记的损失可能更有效,因为损失值与每个标记对应的平均字符数成正比
4. F1分数不适合作为评估语言模型的指标,因为这些语言模型是被训练成生成可变长度的回应(通过文本结束标记来表示完成)。这是因为文本序列越长,F1公式的惩罚越严厉。 F1评分倾向于产生较短的回应模型
所有的模型(从90M参数开始)以及所有被测试的分词器(大小从8000到50257不等)都证明了它们通过微调能够产生语法连贯的答案的能力。尽管这些答案往往是不正确的或幻觉的,但它们都相对连贯,并展示了对上下文背景的理解能力
当嵌入大小增加时,生成文本的词汇多样性和语法准确性显着增加,并且与字词比呈微微的负相关。这意味着,具有较大字词比的词汇会使学习语法和词汇多样性稍微困难一些
7. 在调整模型参数大小时,字词比与SMLQA(Ground Truth)或SQuAD(Information Extraction )基准之间没有统计学上显着相关性。这意味着具有更高字词比的分词器不会对模型的性能产生负面影响。
与“平衡”的相比,“一致”的类别在SMLQA(Ground Truth)基准上表现似乎稍好,但在SQuAD(信息提取)基准上则差得多。虽然还需要更多的数据来证实这一点
在对小型模型进行训练和基准测试后,研究者明显发现,衡量的结果反映的是模型的学习速度,而不是模型的学习能力。此外,研究者没有优化 GPU 的计算潜力,因为使用的是默认的 NanoGPT 的参数。为了解决这个问题,研究者选择使用有着 50257 个 token 的分词器及中等语言模型,对四种变体进行了研究。研究者将 batch 的大小从 12 调整到 36,并将 block 的大小从 1024 缩减到 256,确保充分利用了 24GB GPU 的 VRAM 功能。然后进行了 600000 次迭代,而不是小模型中的 400000 次。每种模型的预训练平均需要 18 天多一点的时间,是小模型需要的 6 天的三倍。
对模型进行收敛训练确实显着降低了更简单词汇表和更复杂词汇表之间的性能差异。 SMLQA(Ground Truth)和 SQuAD(Data Extration)的基准结果非常接近。主要区别在于 50256-consistent 有着比 p50k_base 高 23.5% 的字词比的优势。不过,对于每个 token 对应多个单词的词表来说,真值的性能代价较小,不过这可以用我在页首讨论的方法来解决。
中模型的结果:
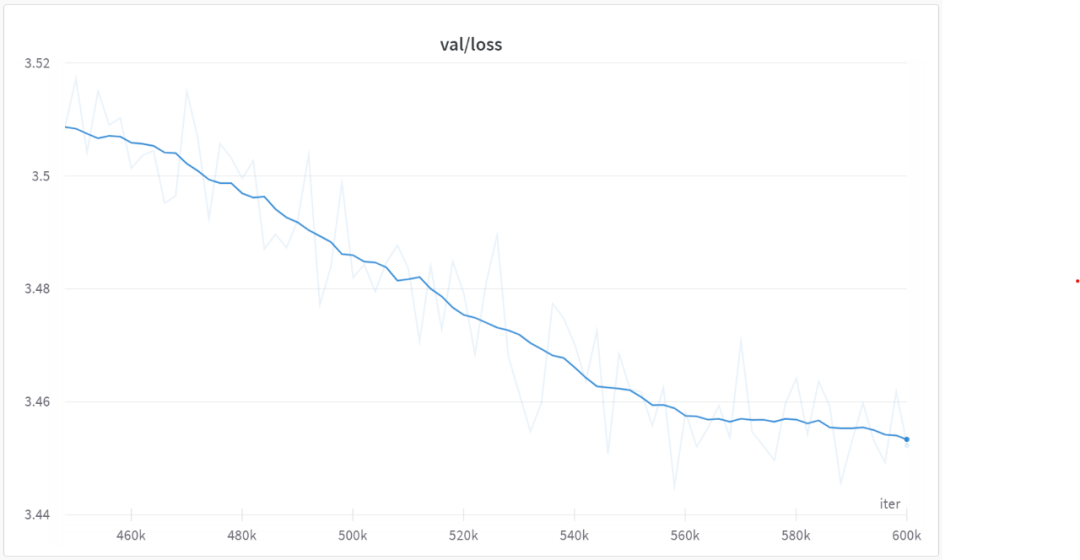
在 560000 次迭代之后,所有模型都开始收敛,如下图所示:
在下一阶段,我们将使用 englishcode-32000-consistent 来训练和基准测试 MEDIUM 的模型。这个词汇表中有80%的单词 token 和20%的多词 token
以上是探究词表选择对语言模型训练的影响:一项具有突破性的研究的详细内容。更多信息请关注PHP中文网其他相关文章!





















