


这是 UG 的全景图。
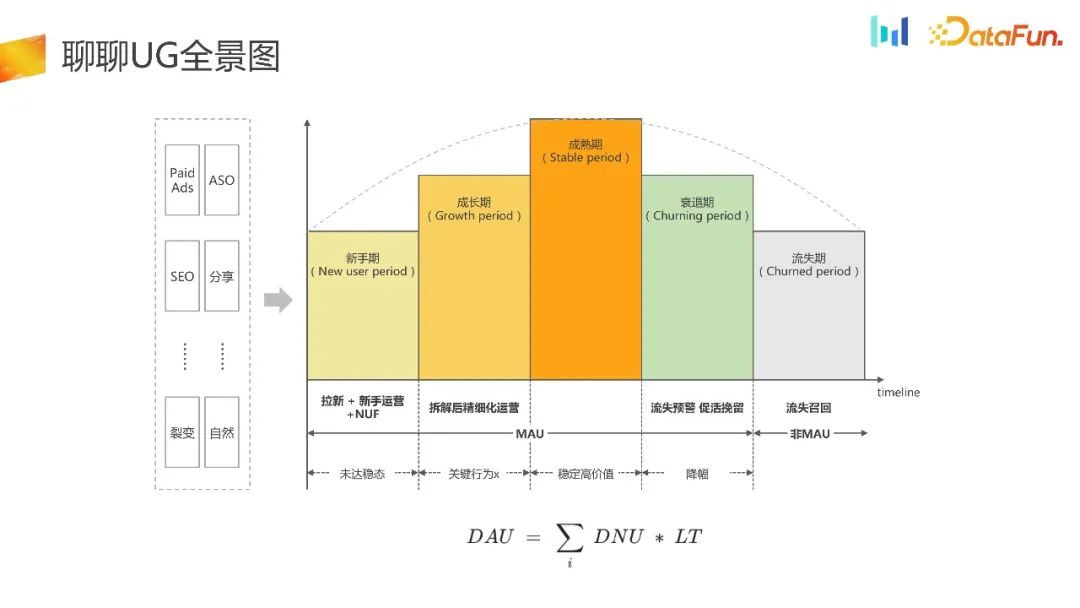
UG 通过渠道,比如 Paid Ads、 ASO、SEO 等渠道,获客引流到 APP。接下来,会做一些新手的运营和引导,来促活用户,使其进入成熟期。后续用户可能会慢慢地失活,进入衰退期,甚至进入流失期。在这期间会做一些流失的预警,促活的召回,后面还有一些对流失用户的召回。
可以概括为上图中的公式, 即 DAU 等于 DNU 乘上 LT。UG 场景下的所有工作都可以基于这一公式来拆解。
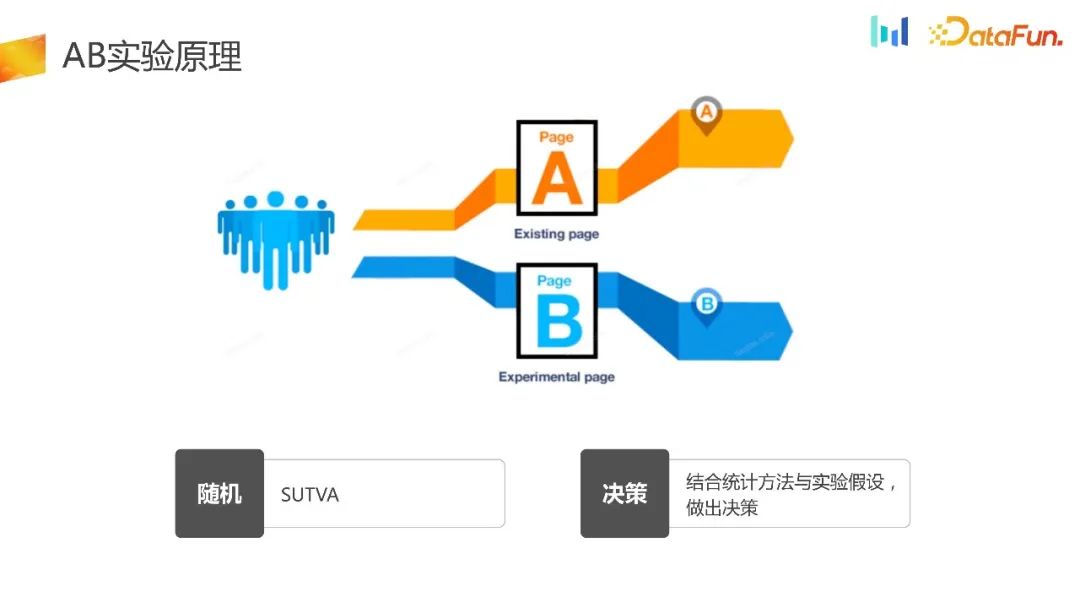
AB实验的目的是对流量进行完全随机的分配,针对实验组和不同的对照组采用不同的策略。最终结合统计方法和实验假设做出科学决策,这构成了整个实验的框架。目前市面上的实验分流类型大致分为两种:实验平台分流和客户端本地分流
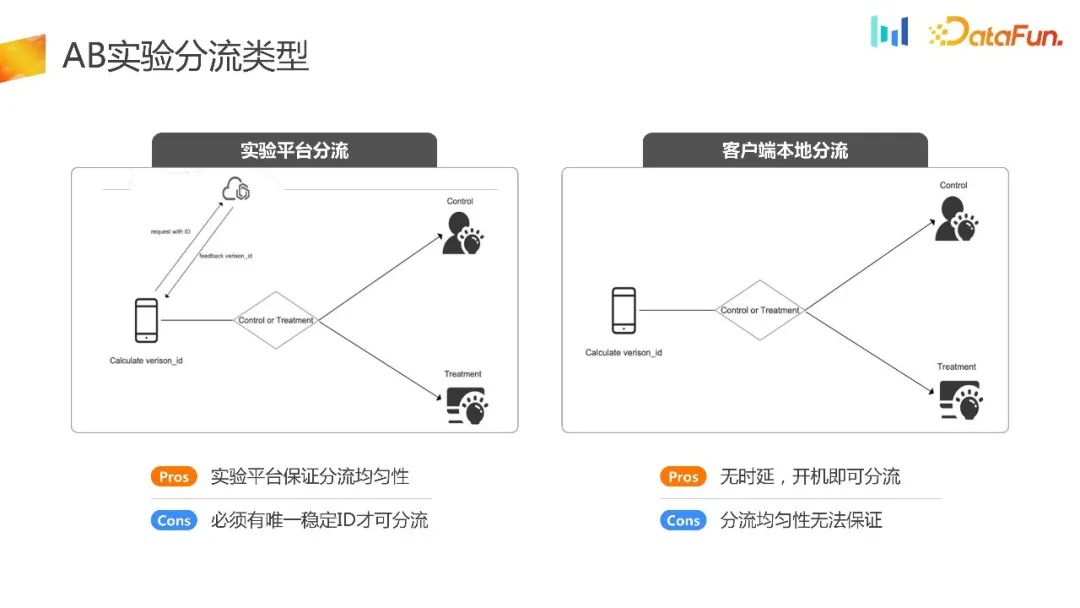
实验平台分流是有前提的,需要设备完成初始化以后能获取到稳定的 ID,基于这个 ID 向实验平台请求实验平台完成分流相关的逻辑,把分流 ID 返回给端上,然后端上基于收到的 ID 做相应的策略。它的优点是有一个实验平台,能够保证分流的均匀性和稳定性。它的缺点是设备必须完成初始化以后才能进行实验分流。
另外一种分流方式是客户端本地分流。这种方式相对来说比较小众,主要适用于一些UG场景、广告开屏场景以及性能初始化场景。在这种方式下,所有的分流逻辑都在客户端初始化时完成。它的优点很明显,即无时延,开机即可进行分流。从逻辑上来说,它的分流均匀性也能够得到保证。然而,在实际的业务场景中,它的分流均匀性常常存在问题。接下来将介绍其原因
UG 场景实际面临的第一个问题是尽可能早的分流。
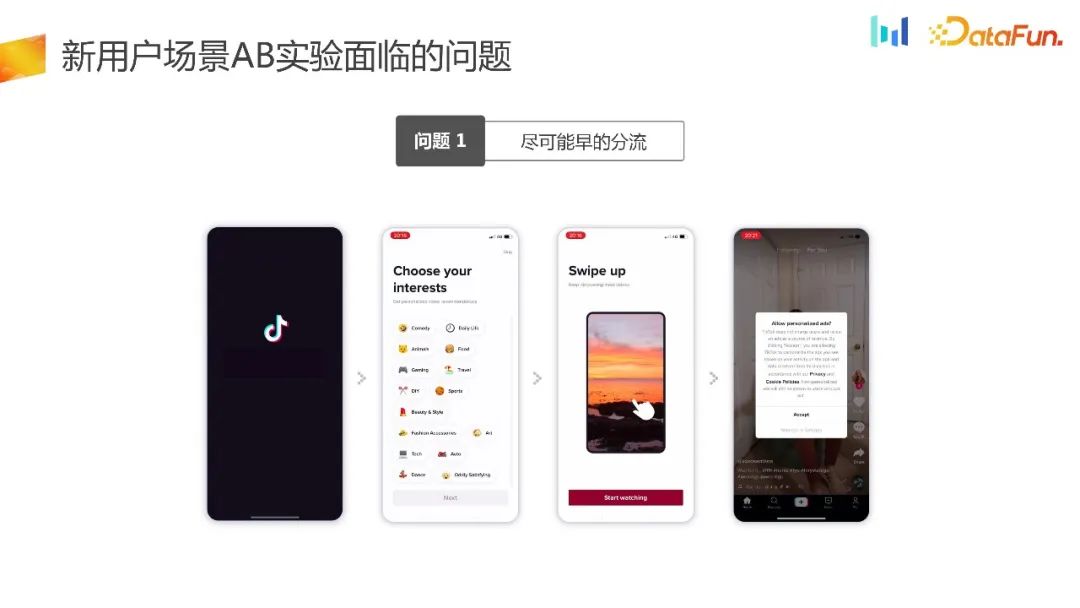
这里举个例子,比如这里的流量承接页面,产品经理觉得 UI 可以再优化一下,进而提升核心指标。在这样的场景下,我们希望实验尽早地进行分流。
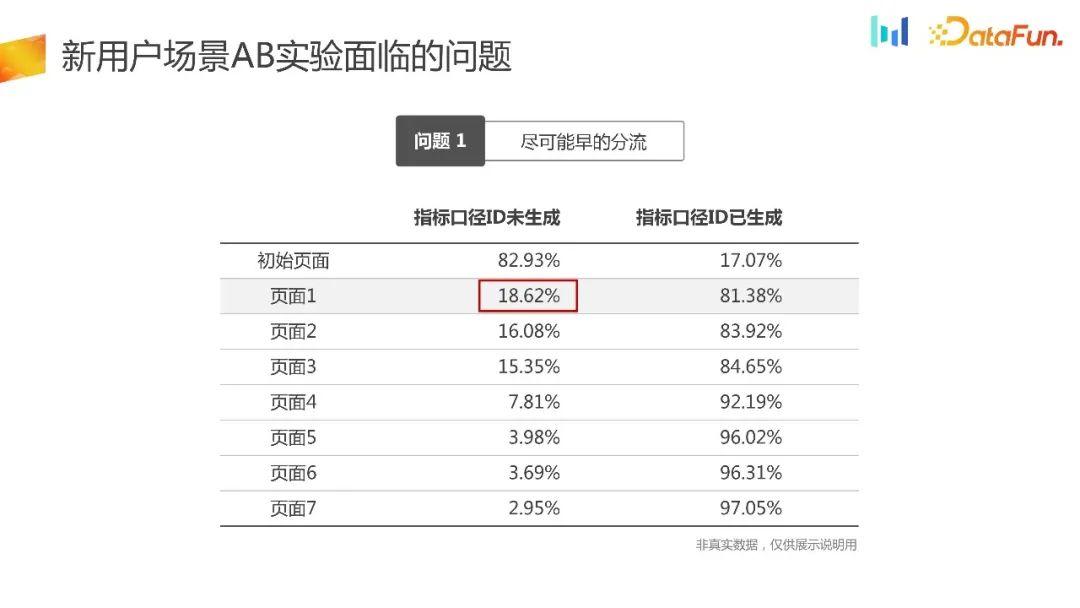
在页面1的分流过程中,设备会进行初始化并获取ID。有18.62%的用户无法生成ID。如果使用传统的实验平台分流方式,将会有18.62%的用户无法被分组,从而导致固有的选择偏差问题
另外,新用户的流量是非常宝贵的,有 18. 62% 的新用户不能被用于实验,对于实验的时长和流量利用效率也是有很大损失的。
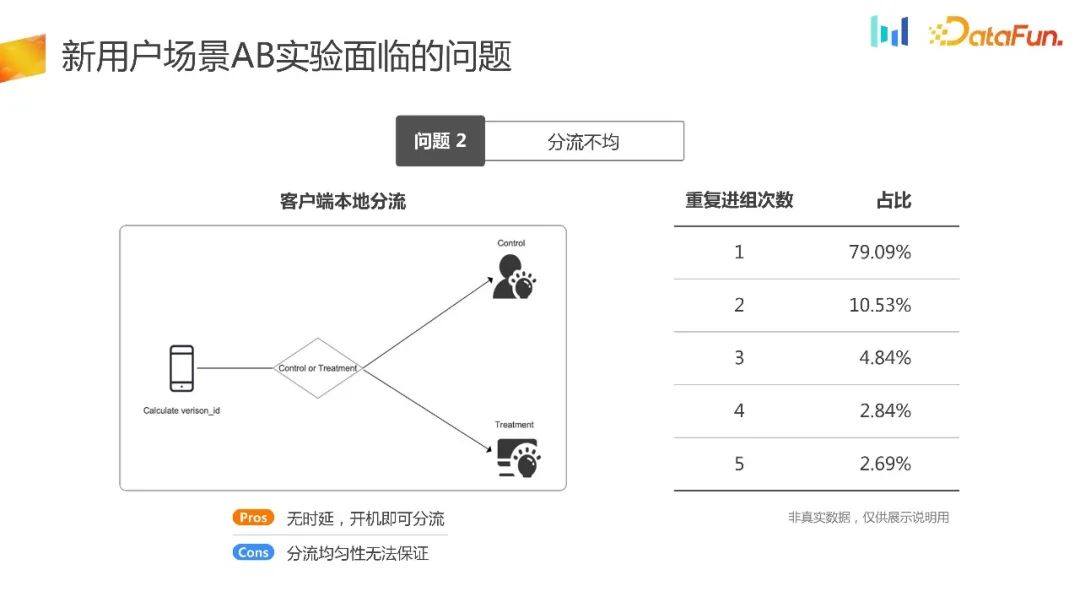
未来解决实验尽可能早的分流的问题,我们就会用客户端本地分流实验。其优点是在设备初始化的时候,就完成了分流。其原理为,首先是在端上面初始化的时候,它本身就可以生成随机数,对随机数进行哈希以后进行同样的分组,进而产生了实验组和对照组。从原理上看,应该能够保证分流是均匀的,但通过上图中的一组数据会发现,有超过 21% 的用户是重复进到不同的组的。
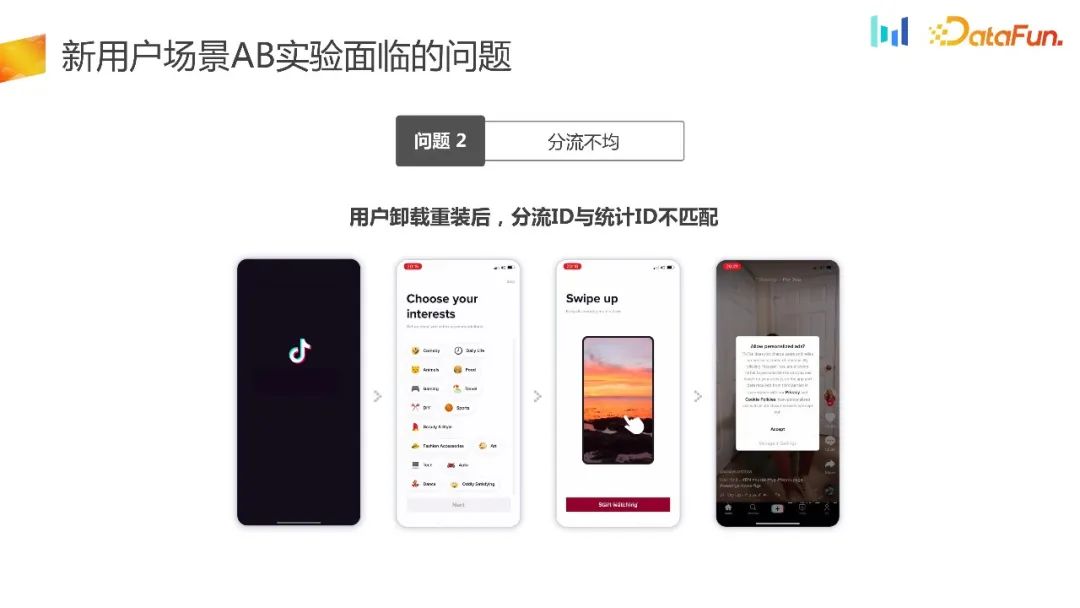
有一种场景是,一些很受欢迎的产品,比如王者荣耀或者抖音,用户很容易上瘾。新用户在实验周期里面会有多次的卸载重装。按照刚刚讲的本地分流的逻辑,随机数的产生和分流以后会让用户进入不同的组,这样就会出现分流的 ID 和统计 ID 不能一对一匹配。造成了分流不均匀的问题。
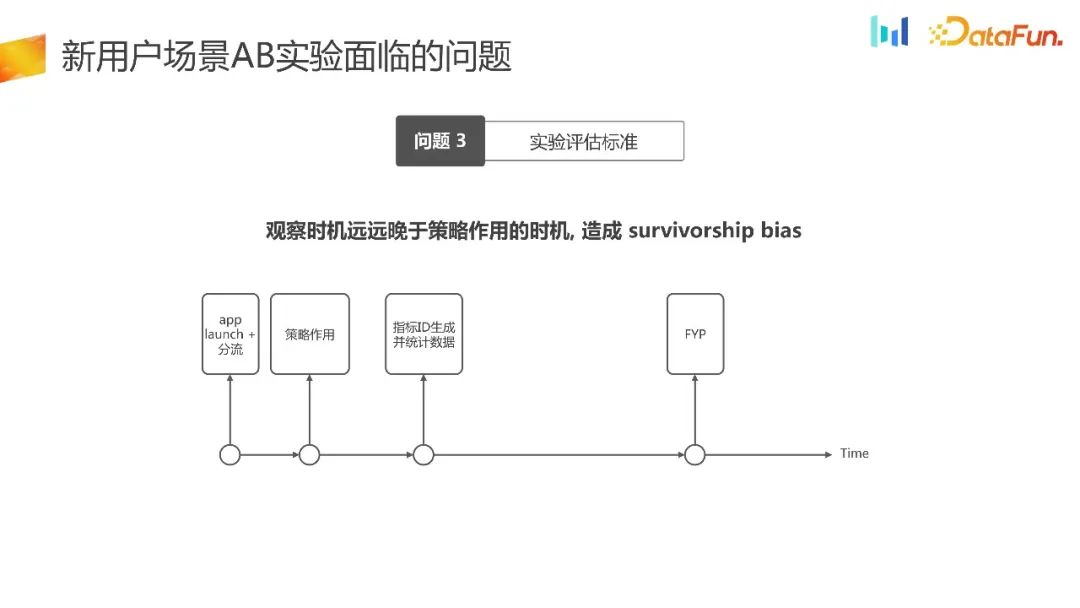
在新用户场景下,我们还面临着实验评估标准的问题。
我们重新梳理了新用户流量承接这一场景的时间图。在应用程序启动时,我们选择了进行分流。假设我们能够在分流的时机做到均匀,并且同时产生相应的策略效果。接下来,生成指标统计ID的时机比策略效果的时机要晚,只有在这时才能观测到数据。数据观测的时机远远落后于策略效果的时机,这将导致幸存者偏差
为了解决上述问题,我们提出了一个新的实验体系,并对其进行了科学性验证
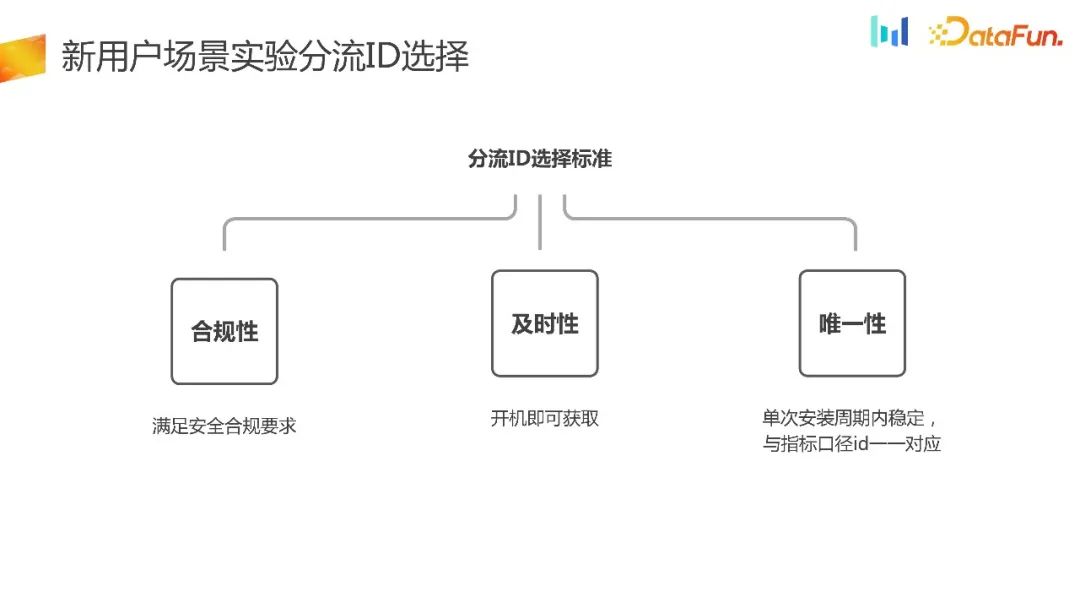
在前面已经提到,对于新用户的分流选择要求会比较高,那么如何选择新用户实验的分流 ID 呢?以下是几个原则:

选择好分流 ID 以后,分流能力往往是通过两种方式,第一种是通过实验平台,第二种是通过端上完成。
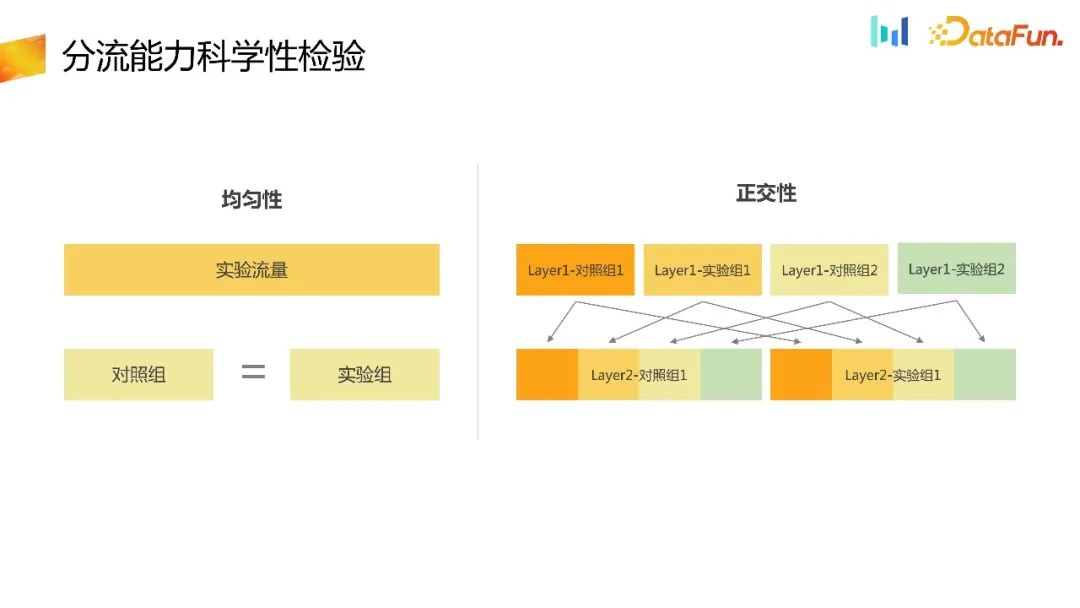
有了分流的 ID 以后,把分流 ID 提供给实验平台,在实验平台里完成分流的能力。作为分流平台,最基本的是需要验证它的随机性。首先就是均匀性。在同一层实验里面,把流量均匀地分到了很多个分桶,每个分桶进组的数量应该是均匀的。在这里可以简化一下,假如一层只有一个实验,分成 a、 b 两组,进组的对照组和实验组的用户数应该是近似相等的,进而验证分流能力的均匀性。其次,对于多层实验,多层实验之间应该是相互正交,不受影响的,同理这里也需要去验证不同层实验之间的正交性。可以通过统计学上的 category test 去验证均匀性和正交性。
介绍完分流选择的 ID 和分流的能力,最后要从指标结果层面去验证新提出来的分流结果,是否符合 AB 实验的要求。
通过利用内部平台,我们进行了多次AA模拟
比较对照组和实验组在对应的指标上面是否满足实验的要求。接下来看一下这一组数据。

抽样了一部分 t 检验的一些指标组,可以理解为对于做的这么多次试验,放 type one error rate 应该是在很小的概率,假设 type one error rate 预定是在 0. 055% 左右,它的置信区间其实应该在 1000 次左右,应该是在 0. 0365- 0. 0635 之间。可以看到第一列抽样出来的一些指标,都在这个执行区间之内,所以从 type one error rate 视角来看现有的这个实验体系是 OK 的。
同时考虑到检验是对于 t 统计量的检验,相应的 t 统计量在大流量的分布下面,应该是近似地服从正态分布的。也可以对 t 检验的统计量做正态分布的检验。这里用了正态分布的检验,可以看到检验出来的结果也是远远大于 0.05 的,即原假设成立,也就是 t 统计量是近似服从正态分布的。
对于每次检验 t 统计量检验出来的结果的 pvalue,在这么多次实验里面来看,也是近似地服从均匀分布的,同时也可以对pvalue 做均匀分布的检验,pvalue_uniform_test,也可以看到类似的结果,它也是远远大于 0.05 的。所以原假设 pvalue 近似服从均匀分布也是 OK 的。
以上从分流 ID 和指标计算口径的一一对应关系,从分流的能力和分流的结果指标结果上面都去验证了新提出来的这种实验分流体系的科学性。
下面将结合UG场景下的实际应用案例,详细讲解如何进行实验评估,以解决前面提到的第三个问题
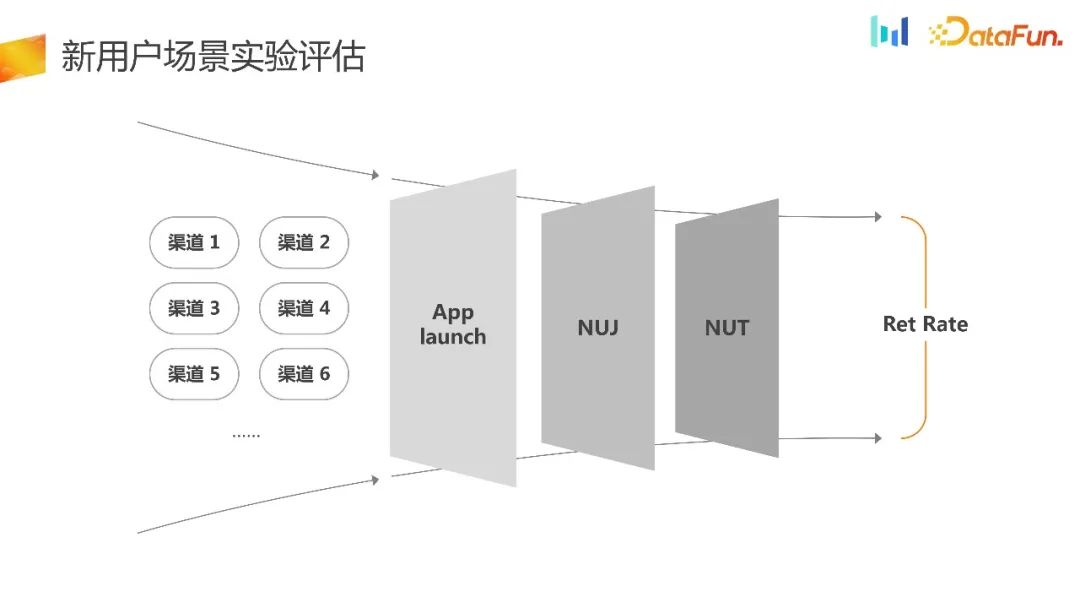
这里是典型的 UG 流量承接场景,在 NUJ 新用户引导或者新用户任务的时候会做很多的优化,从而提升流量利用率。这个时候的评估标准往往都会是 retention rate,这是业界现有的常规理解。
假设从新用户下载到安装再到首启的这个流程, PM 觉得这样的流程对于用户使用,特别是从未体验过产品使用的这一部分用户来说门槛太高了,是不是应该先让用户熟悉产品,体验到产品的嘻哈 moment 以后,再引导登录。
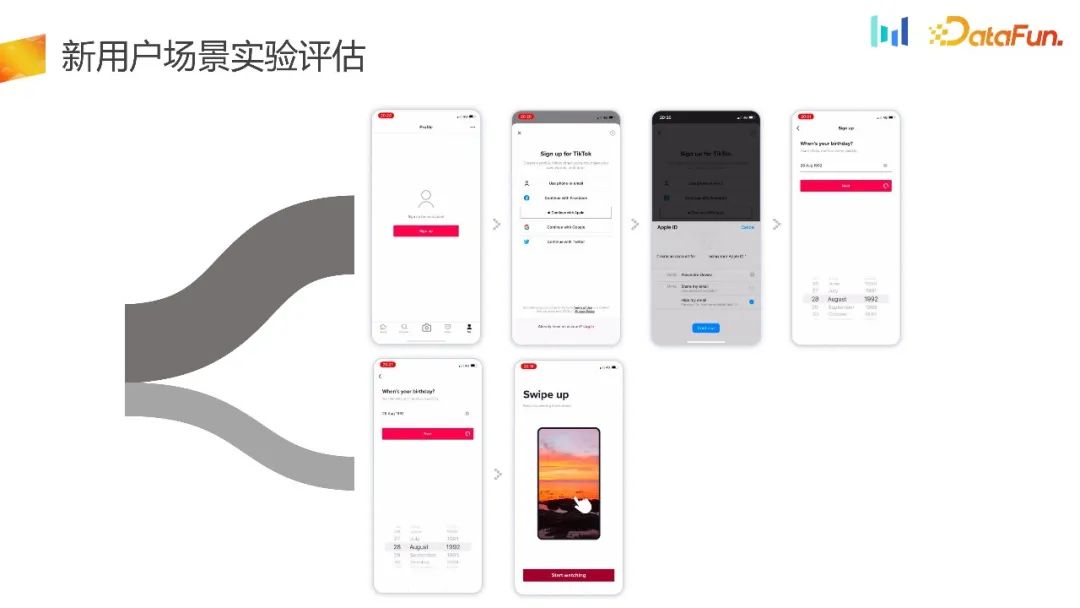
进一步,产品经理提出了另一种假设,即对于从未体验过产品的用户,在新用户登录或新用户 NUJ 场景中降低阻力。对于已经体验过产品的用户和换机用户,则仍然采用线上流程
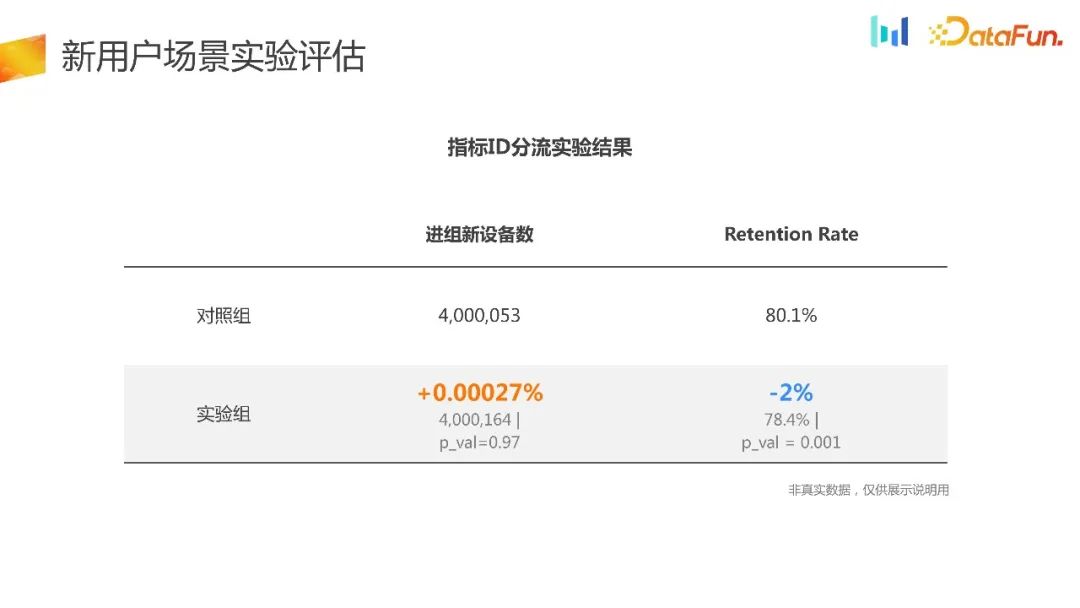
基于指标 ID 进行分流的方法首先获取指标的 ID,然后进行分流。这种分流方法通常是均匀的,从实验结果和保留率上看,没有太大的区别。从这样的结果来看,很难做出全面的决策。这种实验实际上浪费了一部分流量,并且存在选择偏差的问题。因此,我们会进行本地分流实验,下图展示了本地分流实验的结果
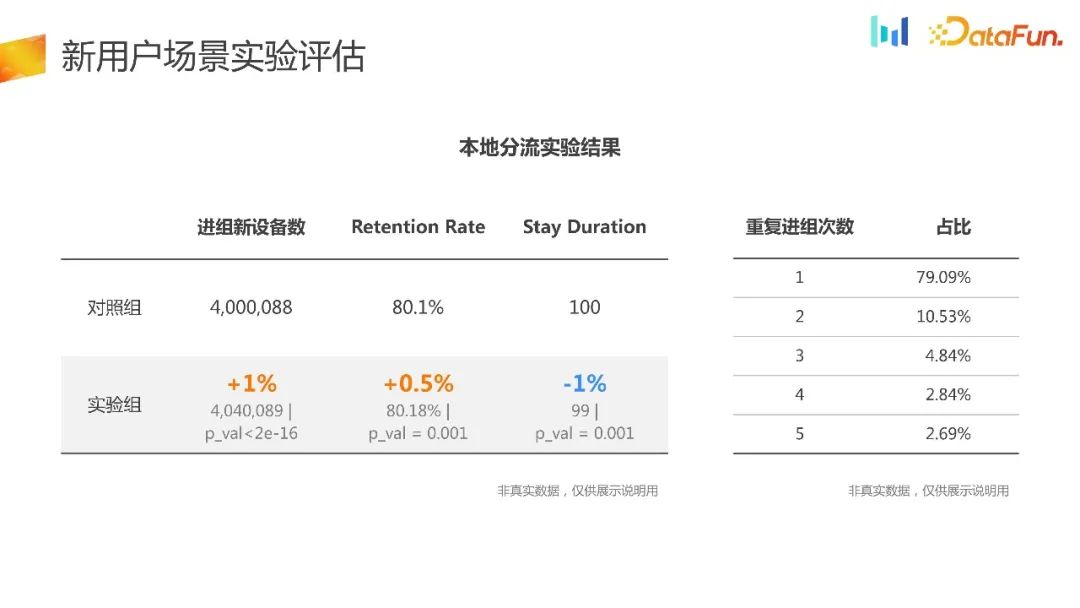
进组的新设备数上面会有显著性的差异,而且是置信的。同时在 retention rate 上面有提升,但在其它核心指标上其实是有负向的,而且这个负向很难被理解,因为它跟留存其实是强相关的。所以基于这样的数据,也很难去解释或者去归因,也很难去做出推全的决策。
可以观察一下重复进组的用户情况,会发现超过20%的用户被重复分到不同的组。这破坏了AB实验的分流随机性,导致很难做出科学比较的决策
最后,看一下用提出的新的分流的实验的结果。
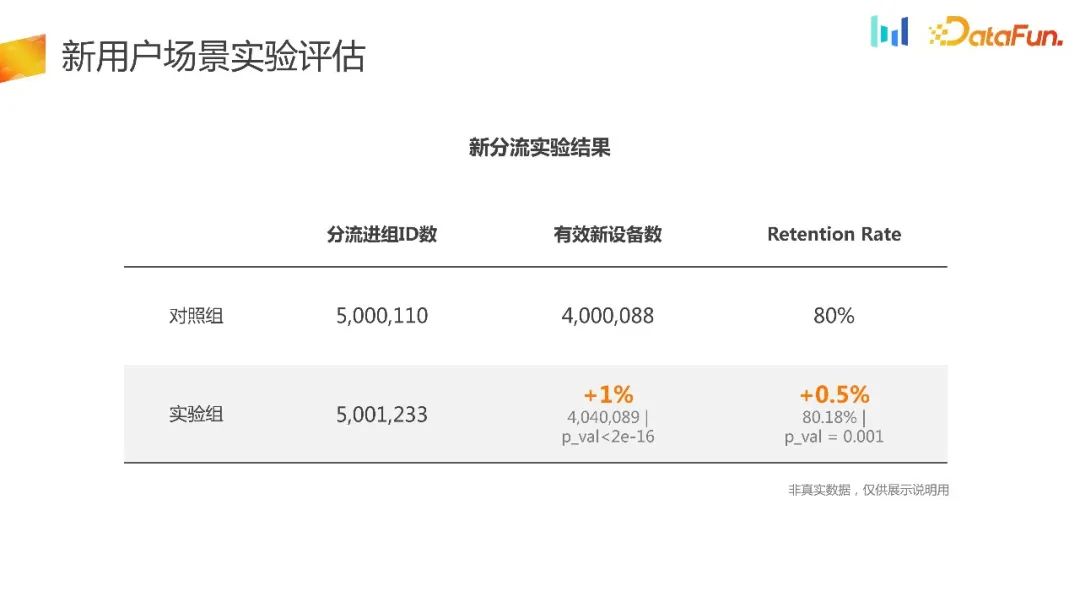
开机即可分流,分流能力是由内部平台来保证的,它能够极大程度地保证分流的均匀性和稳定性。从实验的数据来看,几乎是接近的,在做开方检验的时候也能够看到它是完全满足需求的。同时看到有效的新设备数是有极大的增加的,增加了1%,同时在 retention rate 上面也有所提升。同时从对照组或者单看实验组,能够看到基于分流 ID 到最终产生的新设备的流量转化率,实验组比对照组提升了 1% 。之所以出现这样的结果,实验组其实是放大了用户在 NUJ 和 NUT 的这个入水口,有更多的用户更容易进来体验到产品,进而留下来。
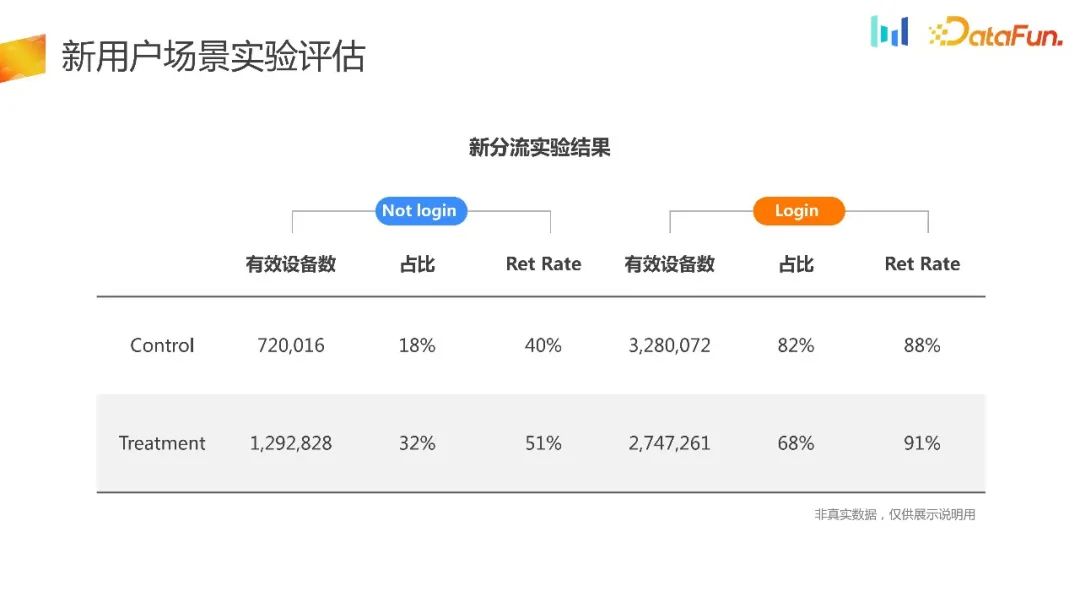
将实验数据分为登录和非登录两部分,可以发现对于实验组的用户来说,更多的用户选择了非登录模式来体验产品,并且留存率也有所提升,这个结果也符合预期
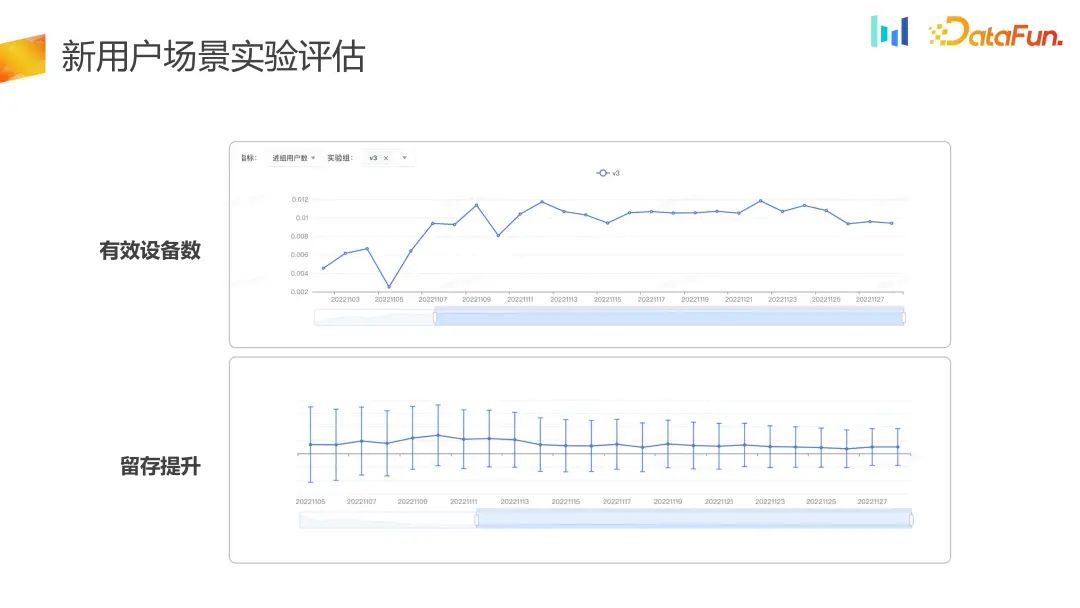
可以看到 by daily 的指标,进组的用户数,其实是有长期写,by daily 来看是稳定增加的,同时留存指标也有提升。实验组相比对照组在有效设备数和留存上都是有提升的。
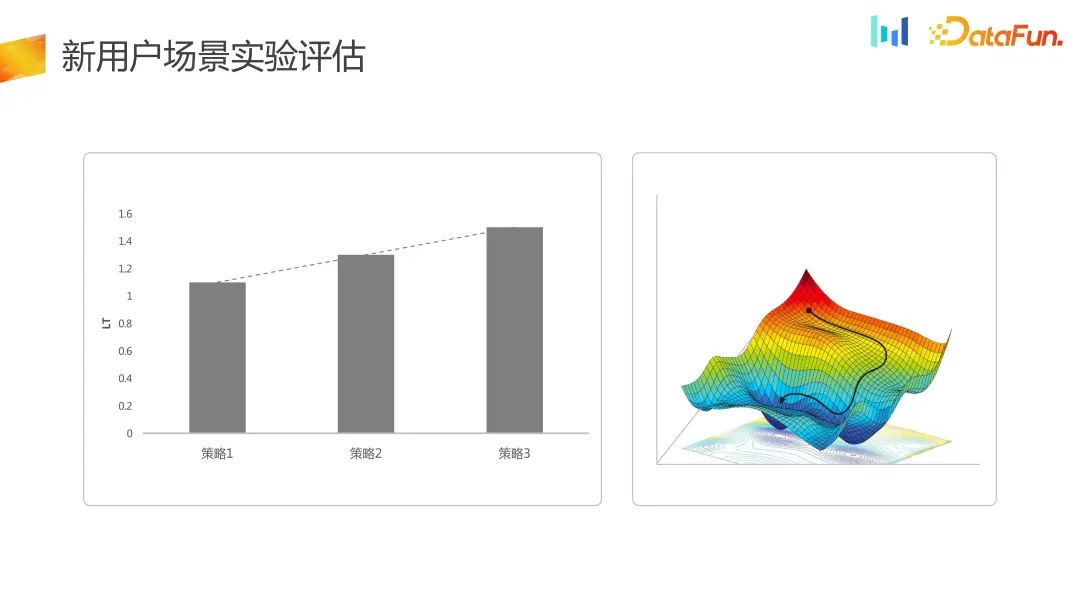
对于新用户流量承接的场景,评估指标更多地从留存或短期的LT维度进行评估。在这里,优化实际上只是在LT层级的一维空间上进行的
而在新的实验体系里面,把一维优化变成了二维优化, DNU 神尚 LT 整体得到了提升,这样策略空间从以前的一维变成了二维,同时在有些场景下是能接受一部分 LT 的损失的。
最后,对新用户场景下实验能力建设和实验评估标准进行一下总结。
以上是如何构建用户增长场景下的AB实验体系?的详细内容。更多信息请关注PHP中文网其他相关文章!





















