

首个中英双语的语音对话开源大模型来了!
这几天,一篇关于语音-文本多模态大模型的论文出现在arXiv上,署名公司中出现了李开复旗下大模型公司01.ai——零一万物的名字。
 图片
图片
这篇论文介绍了一个名为LLaSM的中英双语可商用对话模型。该模型不仅支持录音和文本输入,而且能够实现“混合双打”的功能
 图片
图片
研究指出,“语音聊天”是AI与人之间更方便自然的交互方式,不仅仅是通过文本输入
用上大模型,有网友已经在想象“躺着说话就能写代码”的场景了。
 图片
图片
这项研究是由LinkSoul.AI、北京大学和零一万物共同完成的,目前已经开源,并且可以直接在抱抱脸中进行试玩
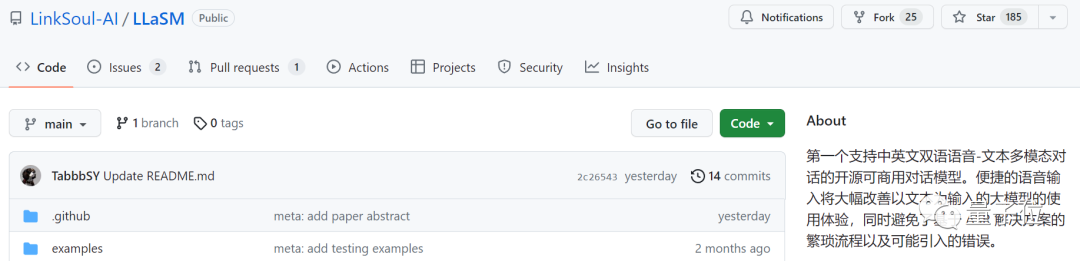 图片
图片
让我们一起来看看它的效果如何吧
据研究人员表示,LLaSM是第一个支持中英文双语语音-文本多模态对话的开源可商用对话模型。
那么,就来看看它的语音文本输入和中英双语能力如何。
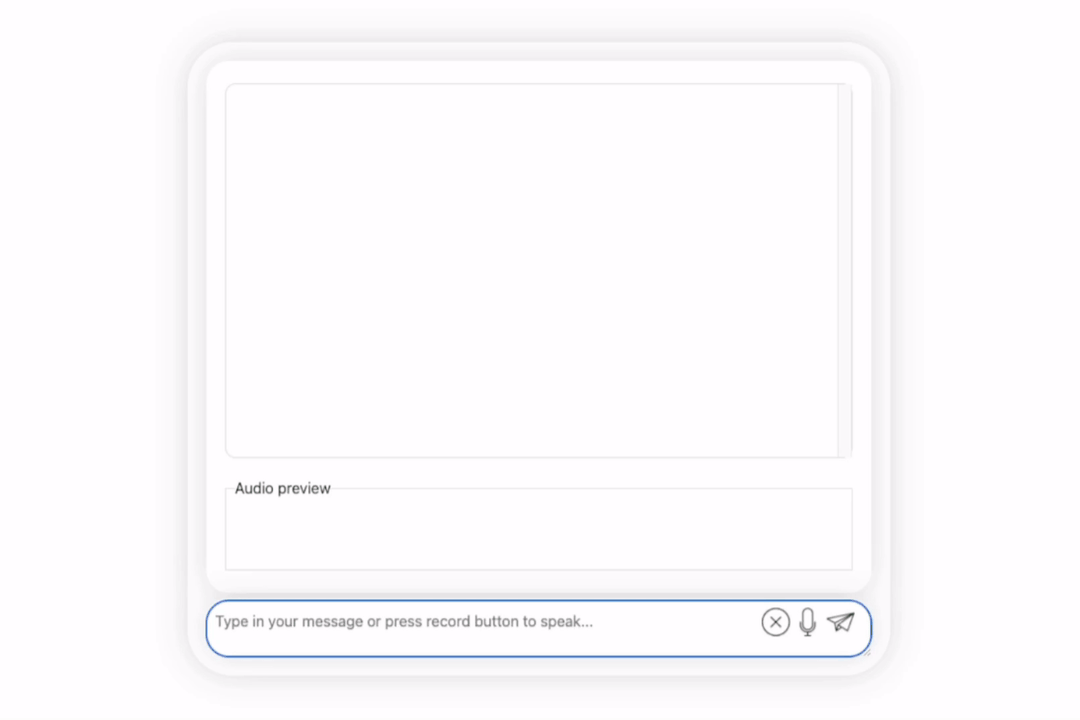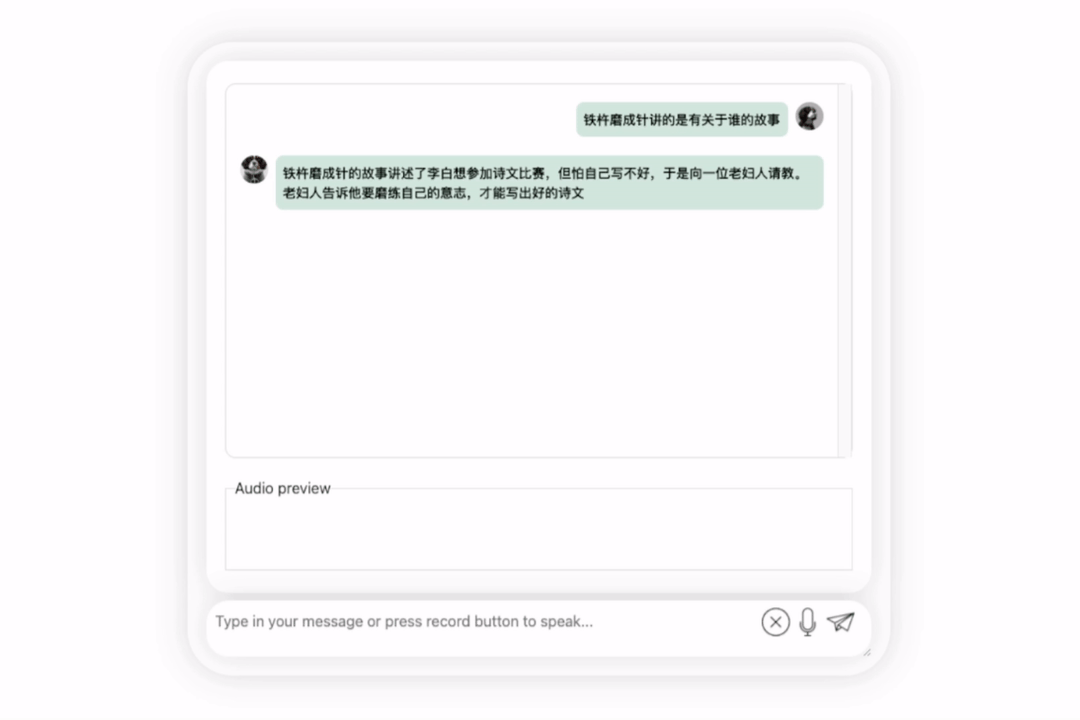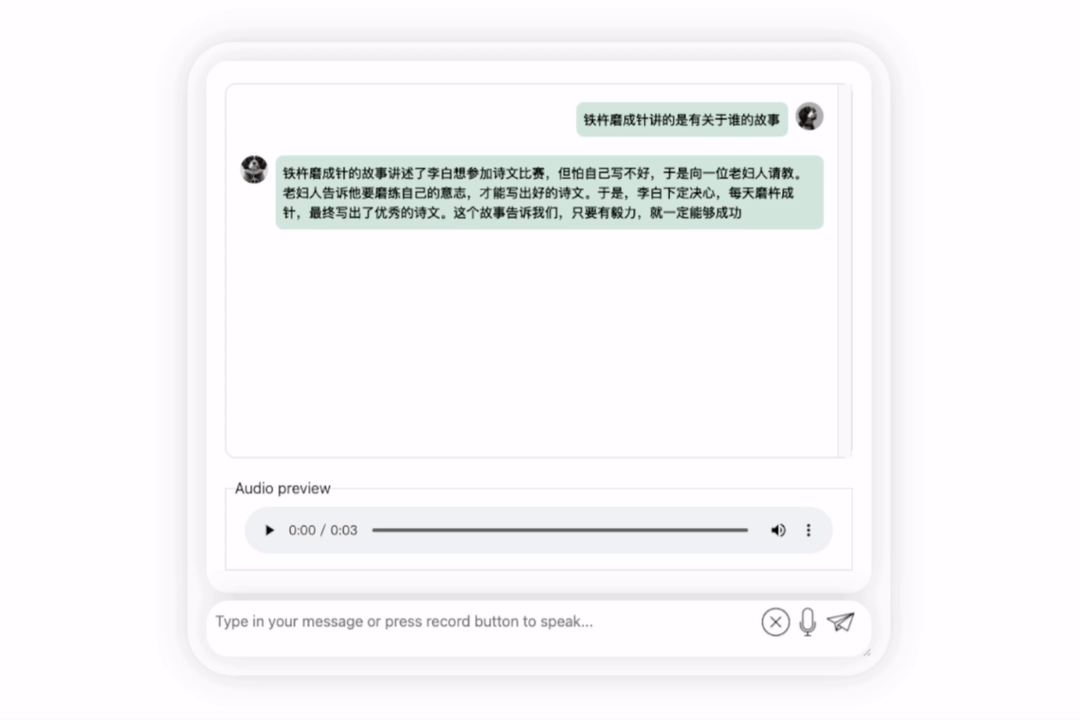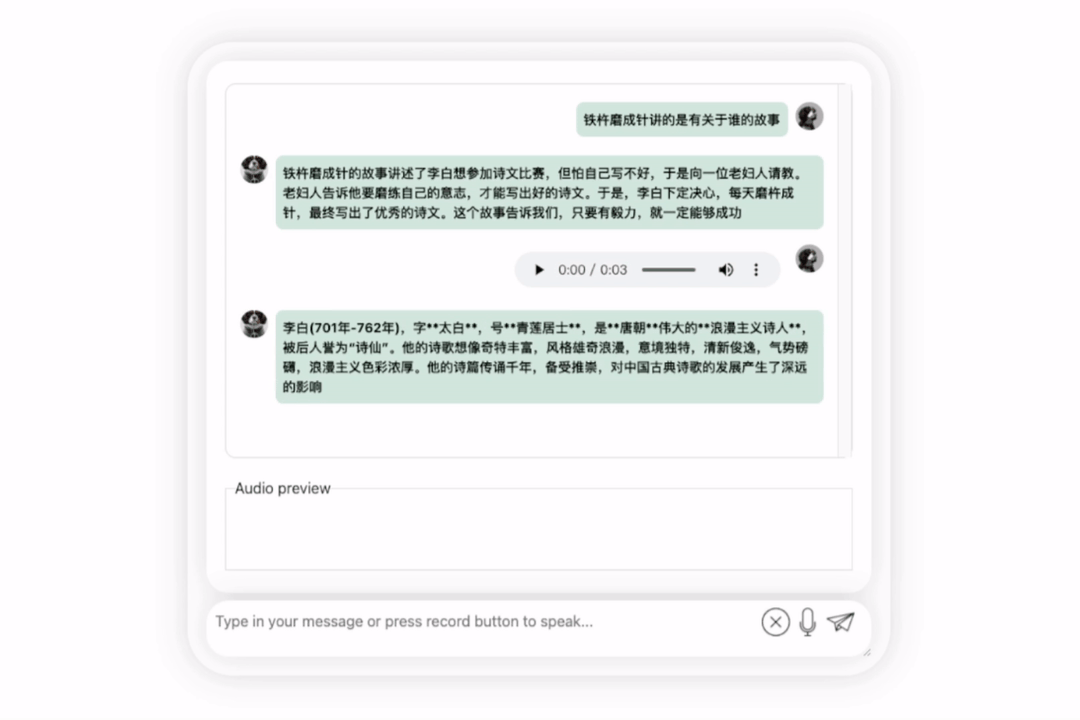
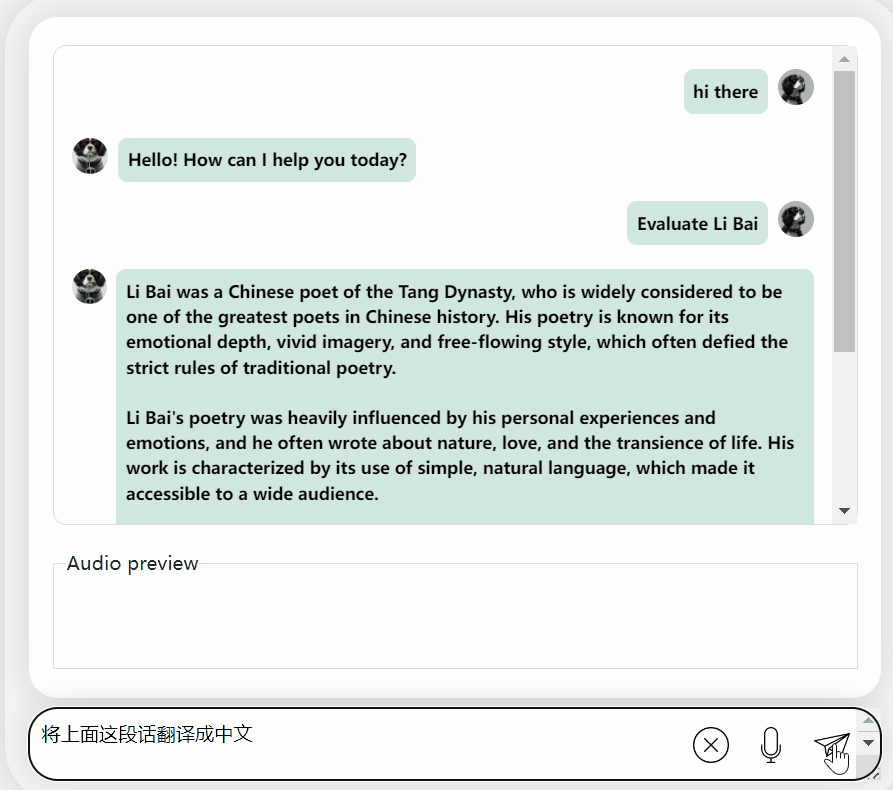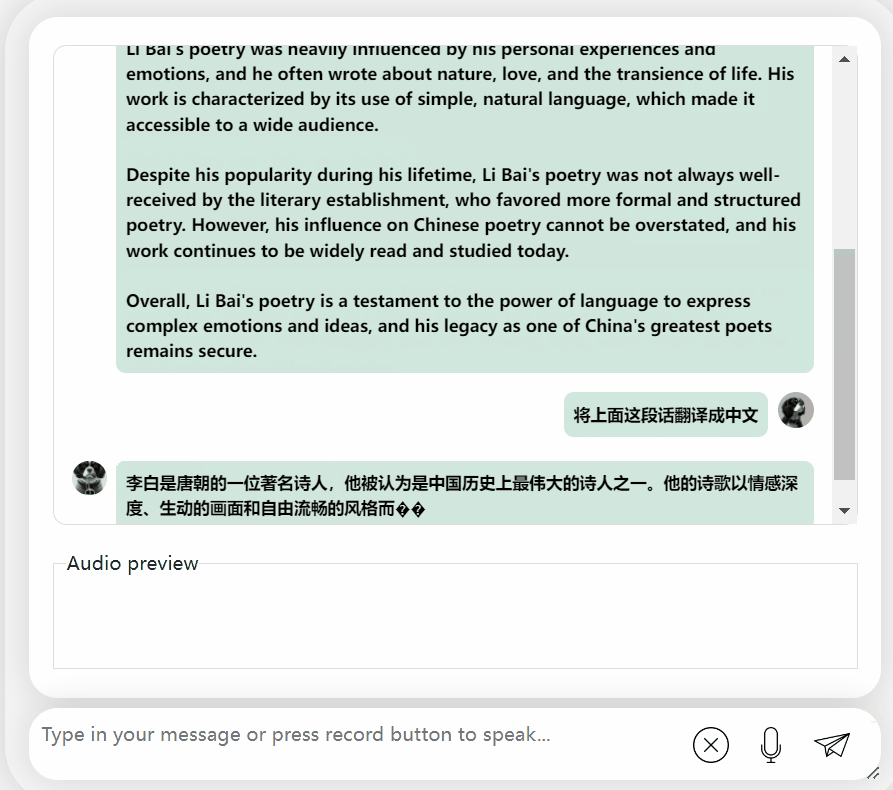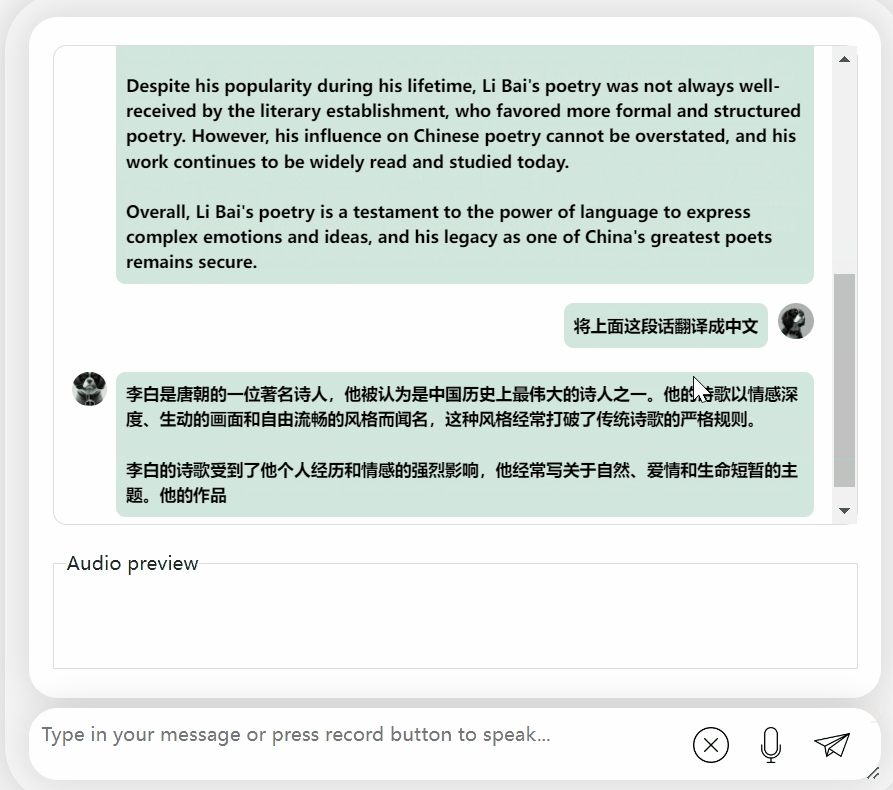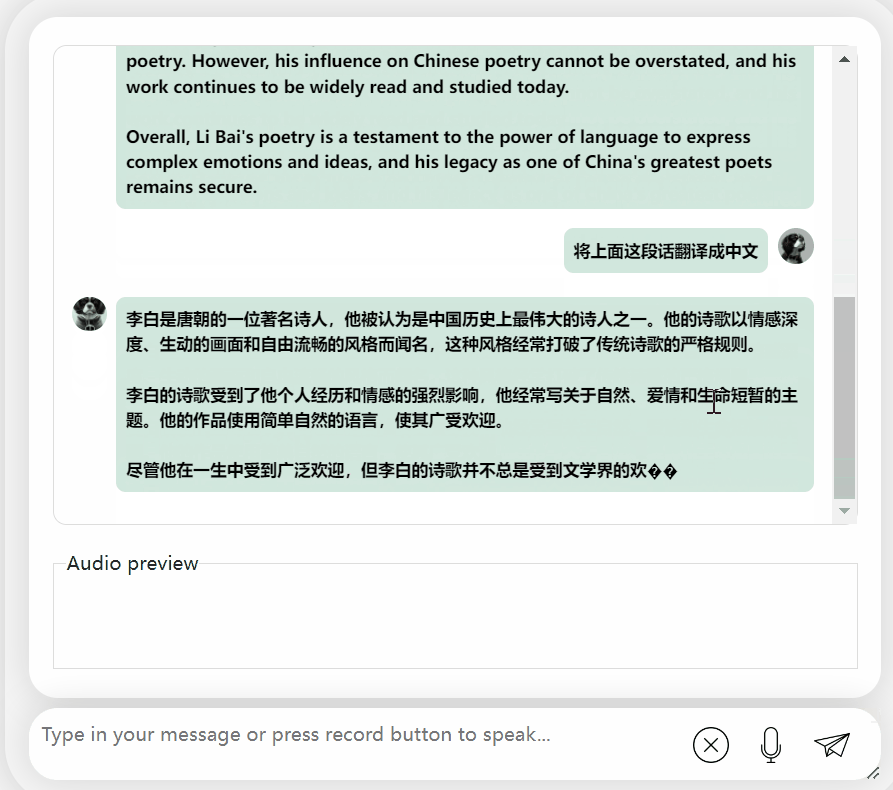
首先,让我们进行一次中英文化碰撞,用英文来评价李白:
 图片
图片
还可以,正确地说出了李白的朝代。如果看不懂英文,让它直接翻译成中文也没问题:
 图片
图片
在接下来的练习中,让我们尝试一下中英混合提问,将一个“炸食物”一词加入到中文句子中。模型的输出效果也相当不错:
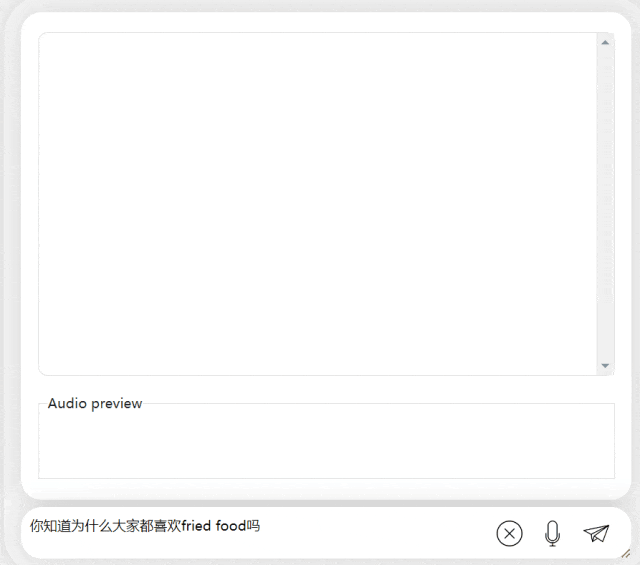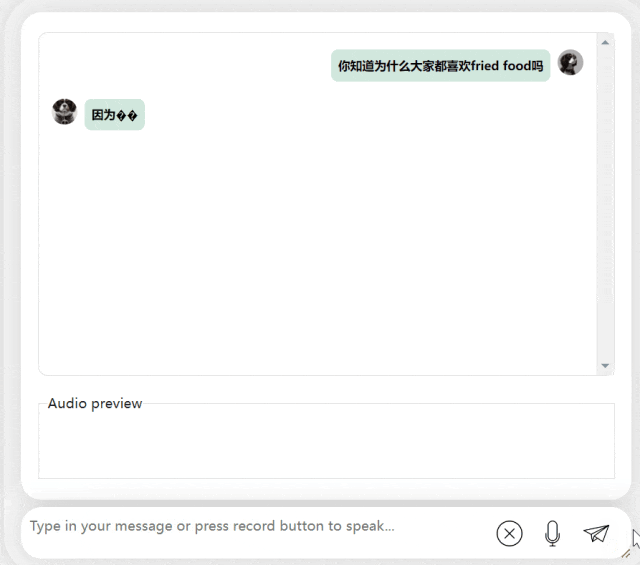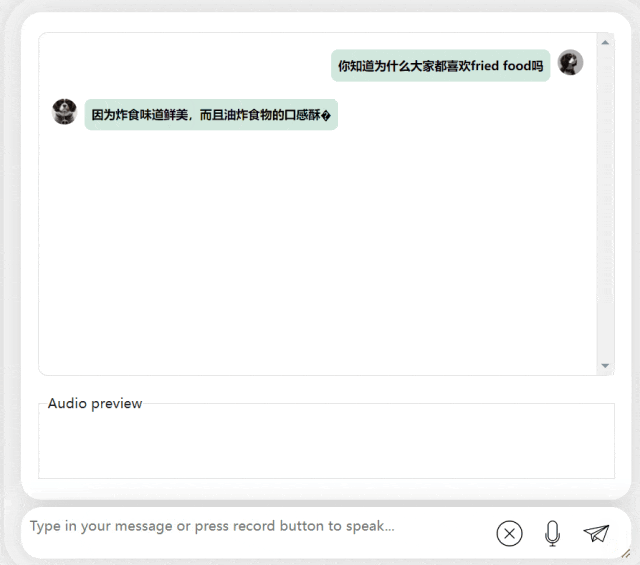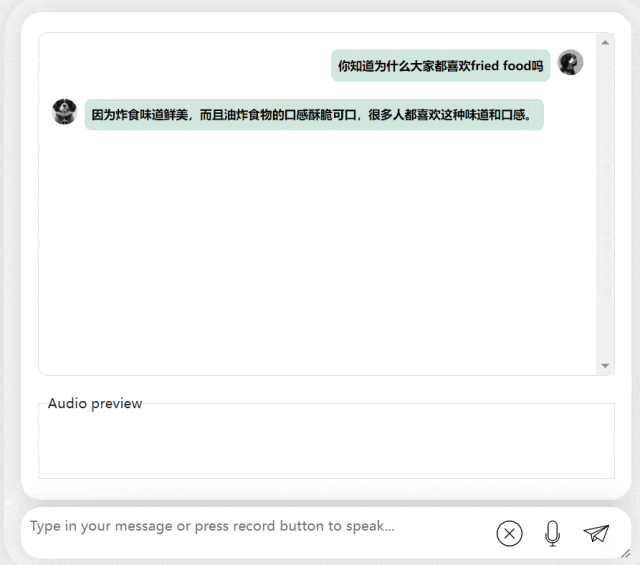 图片
图片
让我们再试探一下模型,让它进行一些评价,看看李白和杜甫哪个更厉害
可以观察到,在经过一段时间的思考后,这个模型给出了非常客观中立的评价,同时也具备了大型模型所必备的基本知识和常识(手动狗头)
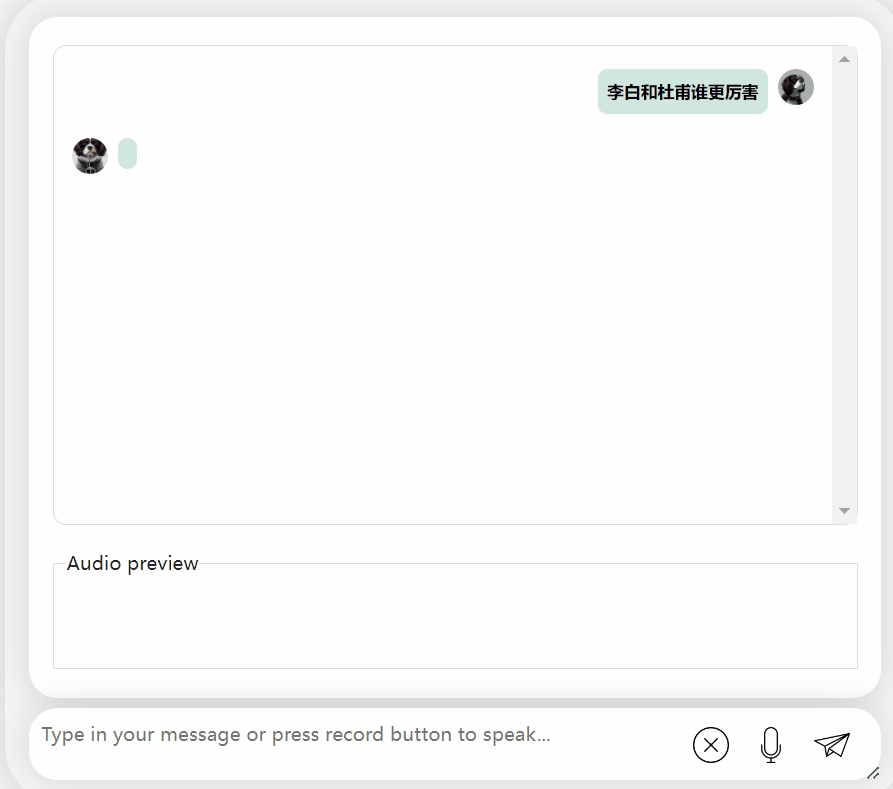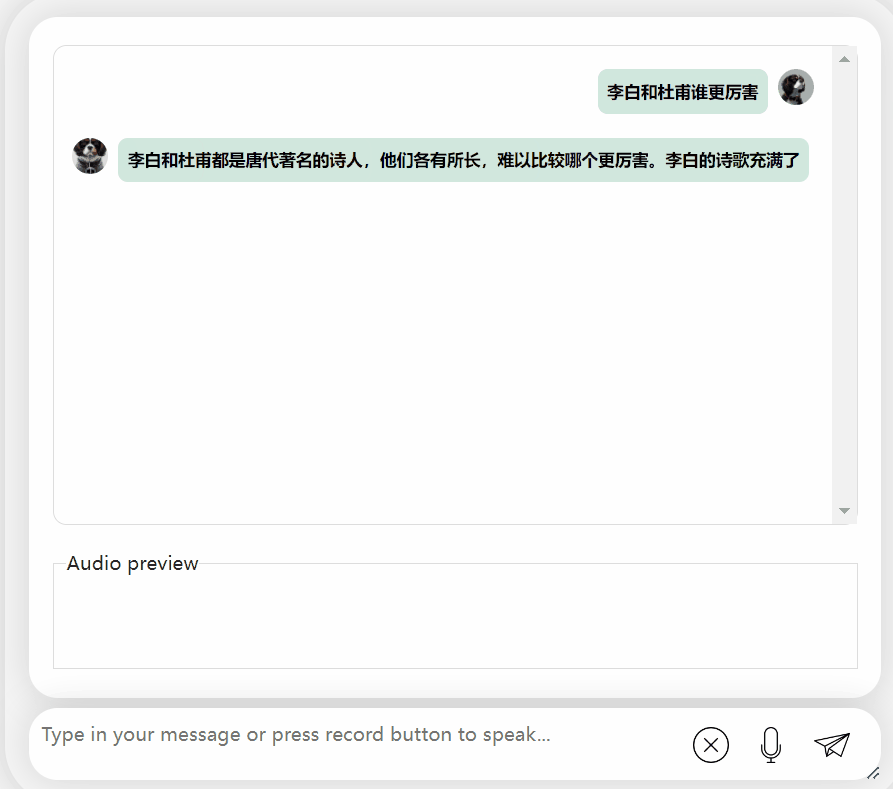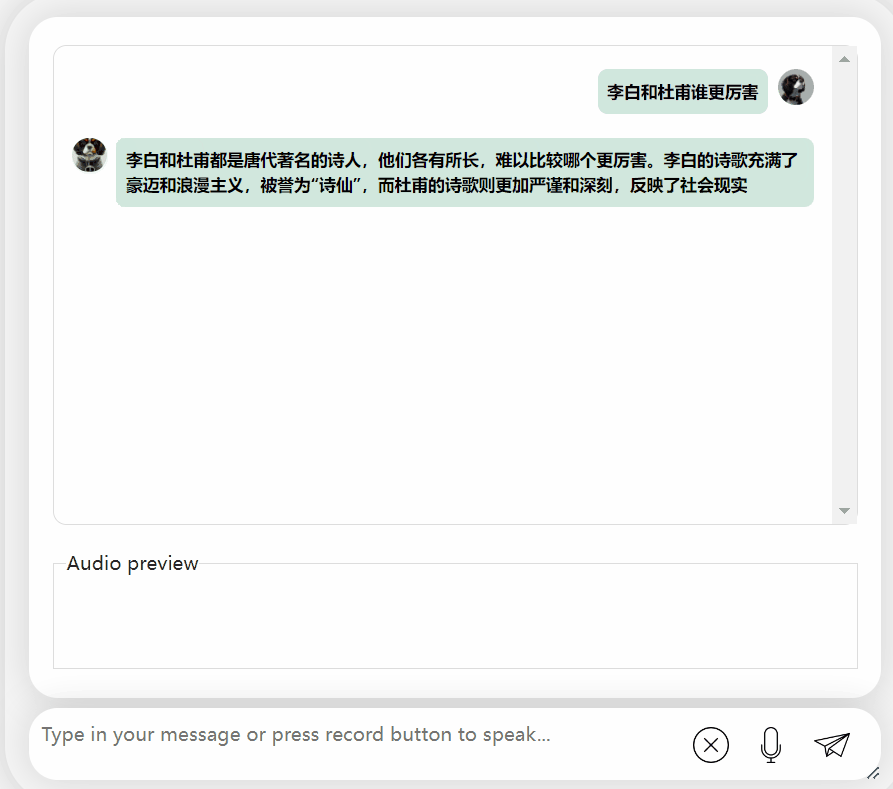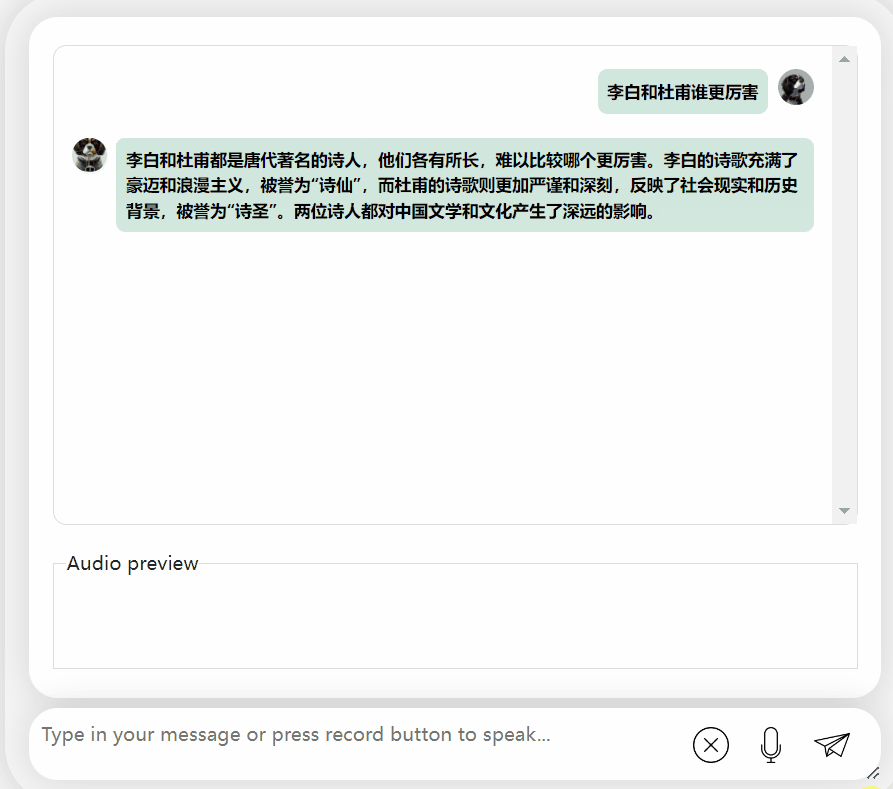 图片
图片
当然,不止是电脑,手机也能玩。
我们试着用语音输入“给我推荐一个菜谱吧”:
可以看到模型准确地输出了一个“茄子芝士”的菜谱,就是不知道好不好吃。
不过,我们在尝试的时候也发现,这个模型有时候会出bug。
例如有时候它并不能很好地“听懂人话”。
要求输出中英混合的内容,它会假装看不懂并输出英文:
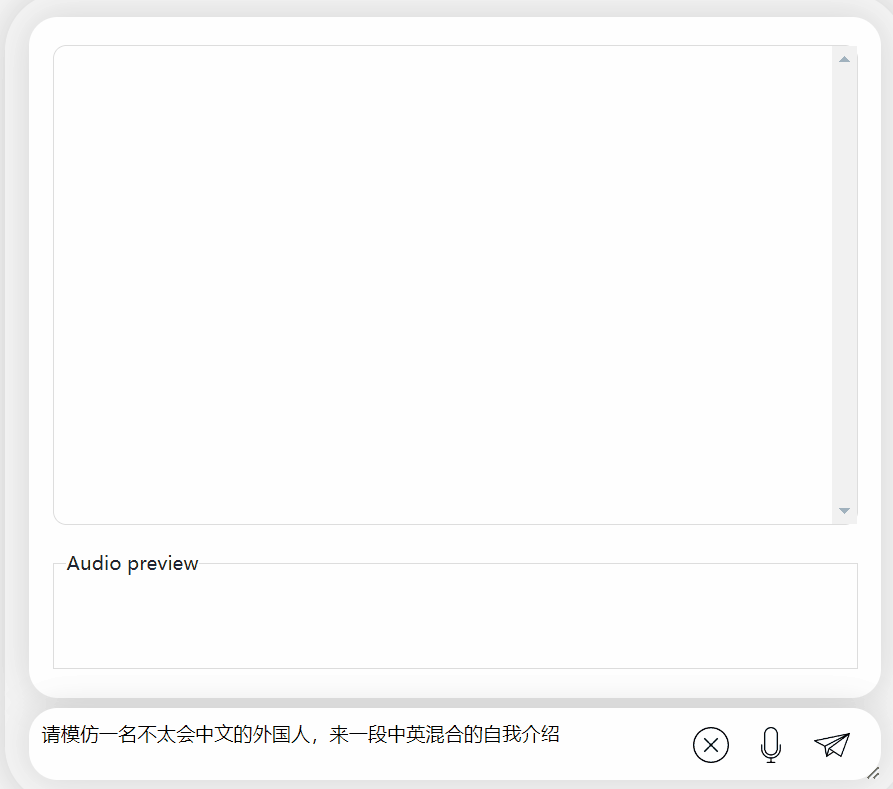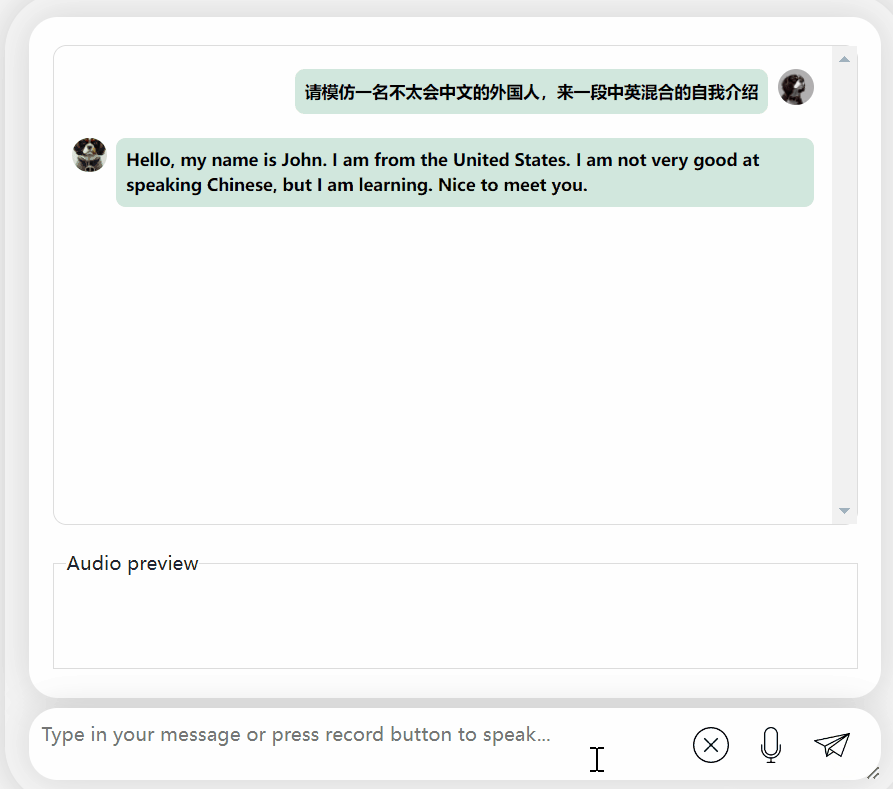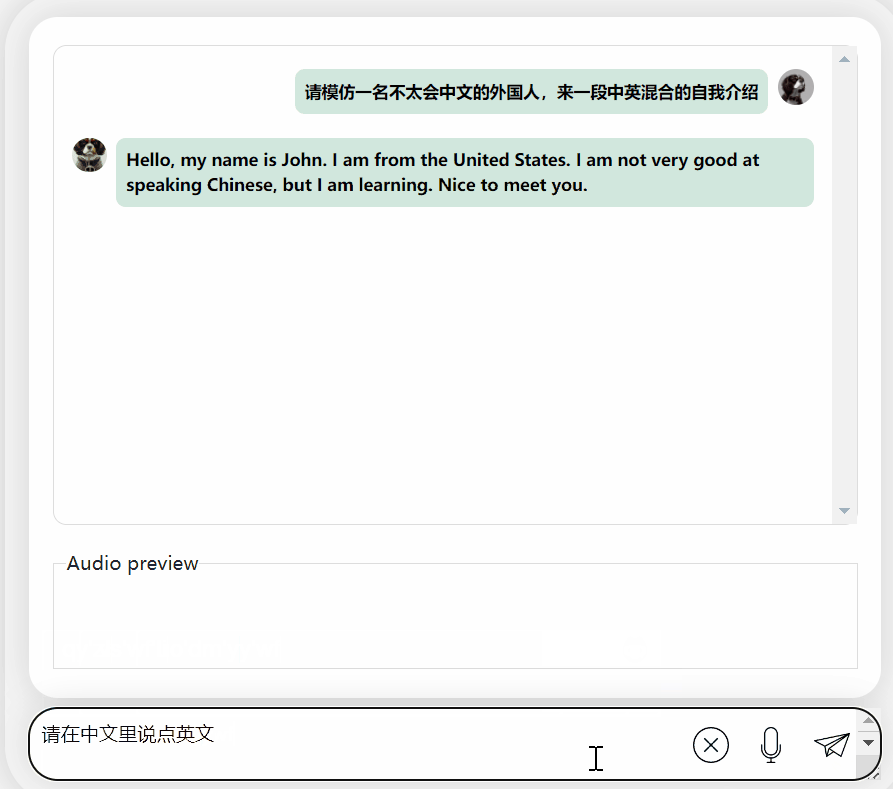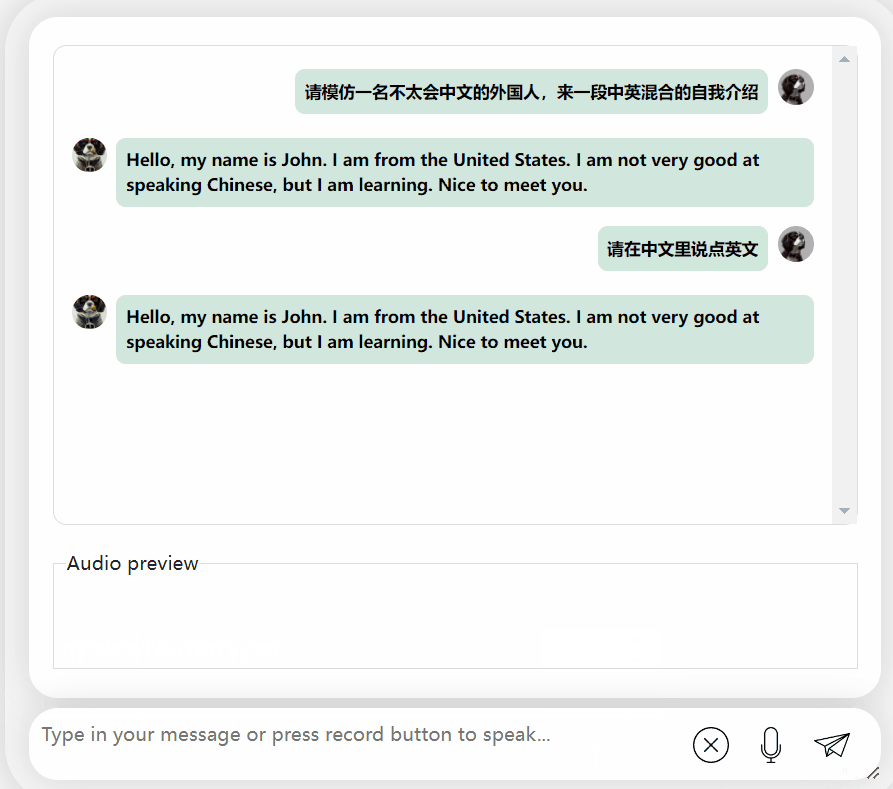 图片
图片
当中英混合询问想听“Taylor Swift的Red”时,模型出现了严重的错误,不断重复输出同一句话,甚至无法停止……
 图片
图片
总体来看,当遇到中英混合的提问或要求时,模型输出能力还是不太行。
不过分开的话,它的中英文表述能力还是不错的。
那么,这样的模型究竟是怎么实现的呢?
从试玩来看,LLaSM主要有两个特点:一个是支持中英输入,另一个是语音文本双输入。
要做到这两点,分别需要在架构和训练数据上做一些调整。
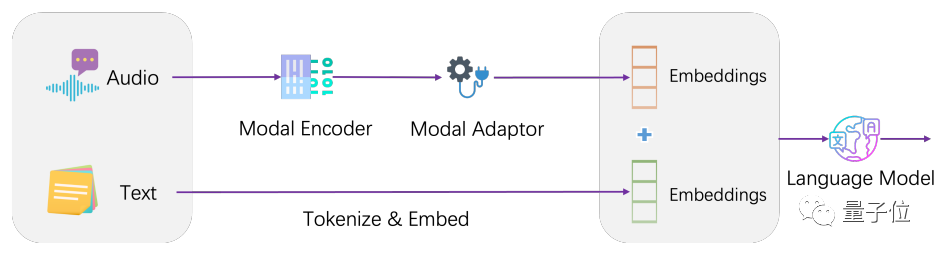
架构上,LLaSM将当前的语音识别模型和大语言模型做了个整合。
LLaSM由三个部分构成,分别包括自动语音识别模型Whisper、模态适配器和大模型LLaMA。
在这个过程中,Whisper负责接收原始语音输入并输出语音特征的向量表示。模态适配器的作用是对齐语音和文本嵌入。而LLaMA则负责理解语音和文本输入的指令,并生成回复
 图片
图片
模型的训练分为两个阶段。第一阶段是训练模态适配器,此时编码器和大模型被冻结,让模型学习语音和文本的对齐。第二阶段是冻结编码器,训练模态适配器和大模型,以提升模型的多模态对话能力
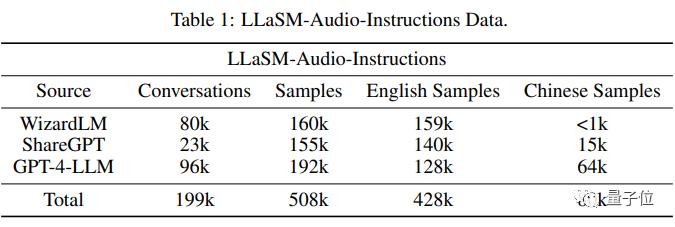
训练数据上,研究人员整理出了一个包含19.9万个对话和50.8万个语音-文本样本的数据集LLaSM-Audio-Instructions。
在50.8万个语音-文本样本中,有8万个是中文语音样本,而42.8万个是英文语音样本
研究人员主要基于WizardLM、ShareGPT和GPT-4-LLM等数据集,通过文本转语音技术,给这些数据集生成语音包,同时过滤掉无效对话。
 图片
图片
这也是目前最大的中英文语音文本指令遵循数据集,不过目前还在整理中,据研究人员表示,整理完后会进行开源。
然而,目前还没有对比该论文与其他语音模型或文本模型的输出效果
这篇论文的作者来自LinkSoul.AI、北京大学和零一万物
共同一作Yu Shu和Siwei Dong均来自LinkSoul.AI,此前曾经在北京智源人工智能研究院工作。
LinkSoul.AI是一家AI初创公司,之前推出过首个开源Llama 2的中文语言大模型。
 图片
图片
作为李开复旗下的大模型公司,零一万物也在这次研究中有所贡献。作者Wenhao Huang的Hugging Face主页显示,他毕业于复旦大学。
 图片
图片
论文地址:
//m.sbmmt.com/link/47c917b09f2bc64b2916c0824c715923
Demo地址:
//m.sbmmt.com/link/bcd0049c35799cdf57d06eaf2eb3cff6
以上是国内推出全新语音对话大模型:李开复领衔,零一万物参与,支持中英双语和多模态,开源并可商用的详细内容。更多信息请关注PHP中文网其他相关文章!





















