

近年来,大规模真实世界数据的视觉预训练取得了显着的进展,在基于像素观察的机器人学习中显示出巨大的潜力。然而,这些研究在预训练数据、方法和模型方面存在差异。因此,哪种类型的数据、预训练方法和模型可以更好地辅助机器人操控仍然是一个未决的问题
基于此,ByteDance Research 团队的研究者从预训练数据集、模型架构和训练方法三个基本角度全面研究了视觉预训练策略对机器人操作任务的影响,提供了一些有利于机器人学习的重要实验结果。此外,他们提出了一种名为 Vi-PRoM 的机器人操作视觉预训练方案,它结合了自监督学习和监督学习。 其中前者采用对比学习从大规模未标记的数据中获取潜在模式,而后者旨在学习视觉语义和时序动态变化。在各种仿真环境和真实机器人中进行的大量机器人操作实验证明了该方案的优越性。

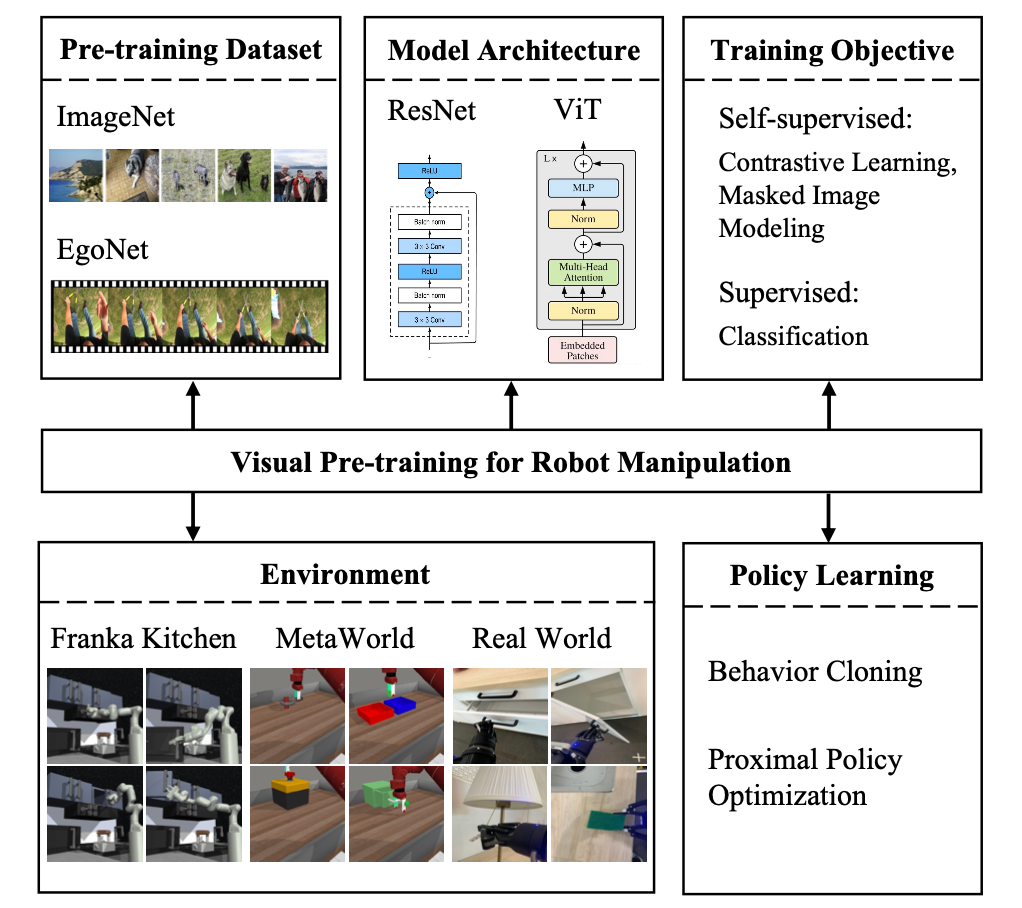
预训练数据
EgoNet比ImageNet更强大。通过对比学习方法在不同的数据集(即ImageNet和EgoNet)上预训练视觉编码器,并观察它们在机器人操作任务中的表现。从下表1中可以看到,在EgoNet上预训练的模型在机器人操作任务上取得了更好的性能。显然,机器人在操作任务方面更倾向于视频中包含的互动知识和时序关系。此外,EgoNet中以自我为中心的自然图像具有更多关于世界的全局背景,这意味着可以学习更丰富的视觉特征
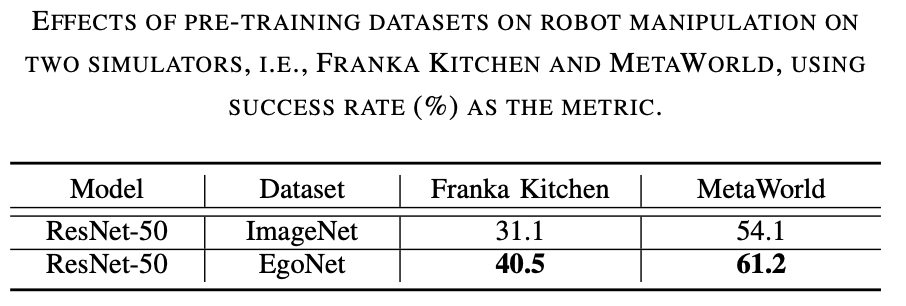
模型结构
ResNet-50 表现更好。从下表 2 中可以看出 ResNet-50 和 ResNet-101 在机器人操作任务上的表现优于 ResNet-34。此外,随着模型从 ResNet-50 增加到 ResNet-101,性能并没有提高。
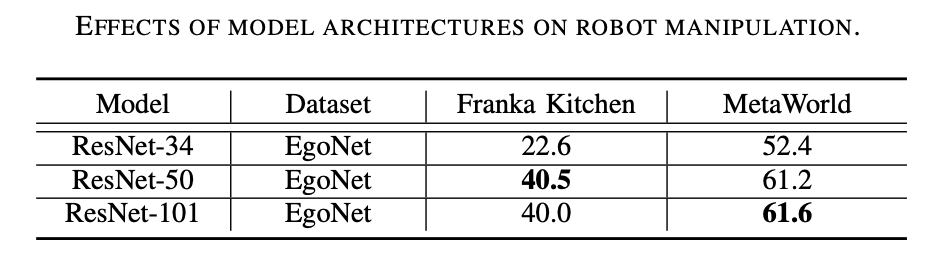
预训练方法
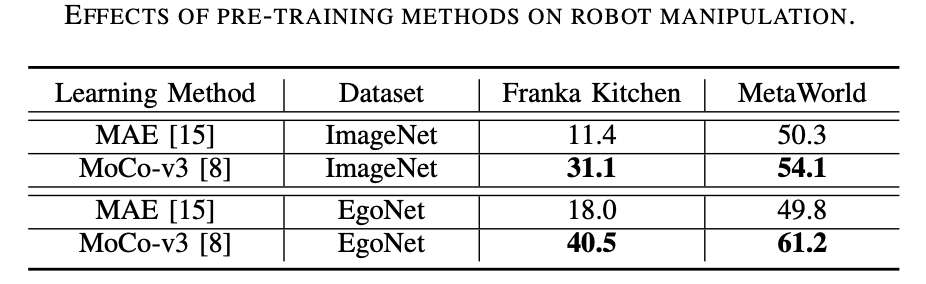
根据原文的意思,需要重写的内容是:“预训练方法首选对比学习。如下表3 所示,MoCo-v3 在ImageNet 和EgoNet 数据集上均优于MAE,这证明了对比学习与掩模图像建模相比更有效。此外,通过对比学习获得的视觉语义对于机器人操作来说比通过掩模图像建模学习的结构信息更重要。” 重写后的内容: 对比学习是首选的预训练方法。从表3中可以看出,MoCo-v3在ImageNet和EgoNet数据集上都优于MAE,这表明对比学习比掩模图像建模更有效。此外,对比学习所获得的视觉语义对于机器人操作来说比掩模图像建模所学习的结构信息更重要
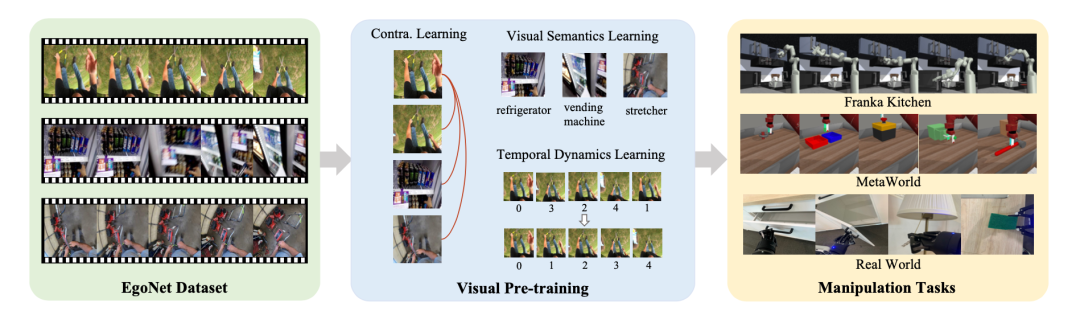
基于上述探索,该研究提出了一种针对机器人操作的视觉预训练方案(Vi-PRoM)。该方案通过在EgoNet数据集上对ResNet-50进行预训练,来提取机器人操作的全面视觉表示。具体而言,首先采用对比学习的方式,通过自我监督从EgoNet数据集中获取人与物体的交互模式。然后,提出了两个额外的学习目标,即视觉语义预测和时序动态预测,以进一步丰富编码器的表示。下图展示了Vi-PRoM的基本流程。值得注意的是,该研究不需要手动标注标签来学习视觉语义和时序动态
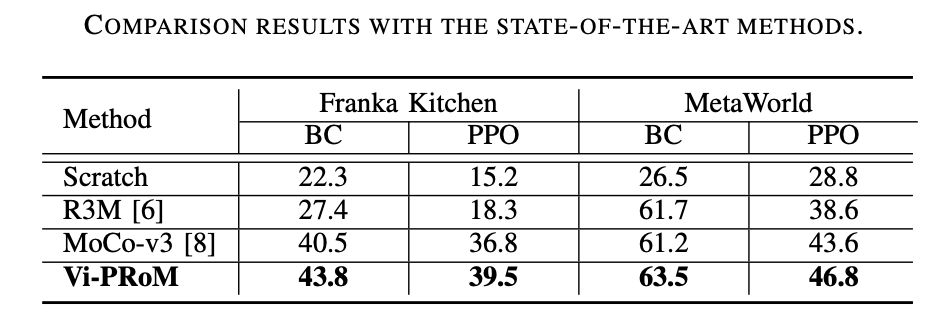
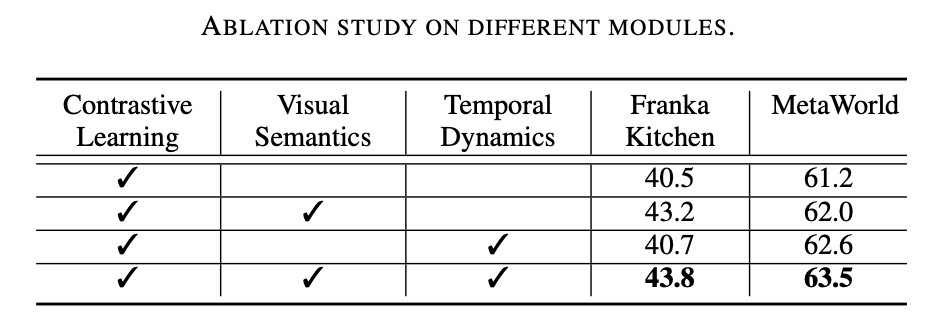
该研究工作在两种仿真环境 (Franka Kitchen 和 MetaWorld) 上进行了广泛的实验。实验结果表明所提出的预训练方案在机器人操作上优于以前最先进的方法。消融实验结果如下表所示,可以证明视觉语义学习和时序动态学习对于机器人操作的重要性。此外,当两个学习目标都不存在时,Vi-PRoM 的成功率会大大下降,证明了视觉语义学习和时序动态学习之间协作的有效性。
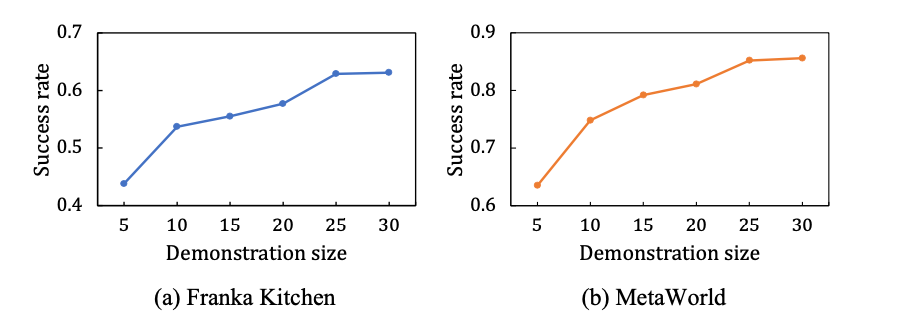
该工作还研究了 Vi-PRoM 的可扩展性。如下左图所示,在 Franka Kitchen 和 MetaWorld 模拟环境中,Vi-PRoM 的成功率随着演示数据规模的增加而稳步提高。在更大规模的专家演示数据集上进行训练后,Vi-PRoM 模型显示了其在机器人操作任务上的可扩展性。

由于 Vi-PRoM 强大的视觉表征能力,真实机器人能够成功地打开抽屉和柜门
Franka Kitchen 上的实验结果可以看出,Vi-PRoM 在五个任务上都比 R3M 具有更高的成功率和更高的动作完成度。
R3M:





Vi-PRoM:





在 MetaWorld 上,由于 Vi-PRoM 的视觉表示学习了良好的语义和动态特征,它可以更好地用于动作预测,因此相比 R3M,Vi-PRoM 需要更少的步骤来完成操作。
R3M:

Vi-PRoM:


以上是改写后的标题:字节推出Vi-PRoM视觉预训练方案,提升机器人操作成功率和效果的详细内容。更多信息请关注PHP中文网其他相关文章!





















