

「GPU贫民」即将告别困境!
刚刚,英伟达发布了一款名为TensorRT-LLM的开源软件,可以加速在H100上运行的大型语言模型的推理过程

那么,具体能提升多少倍?
在添加了TensorRT-LLM及其一系列优化功能后(包括In-Flight批处理),模型总吞吐量提升8倍。
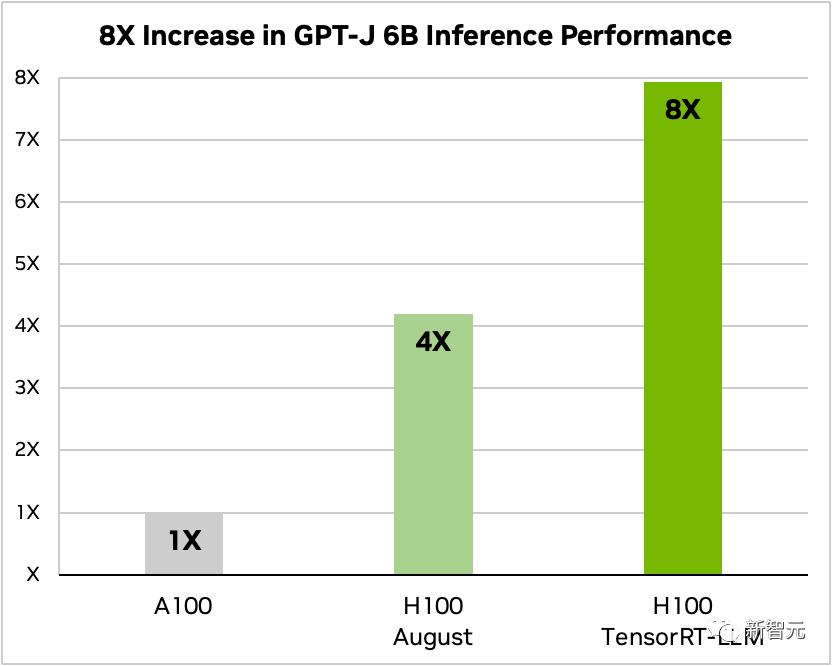
使用和不使用TensorRT-LLM的GPT-J-6B A100与H100的比较
另外,以Llama 2为例,相比独立使用A100,TensorRT-LLM能够将推理性能提升4.6倍
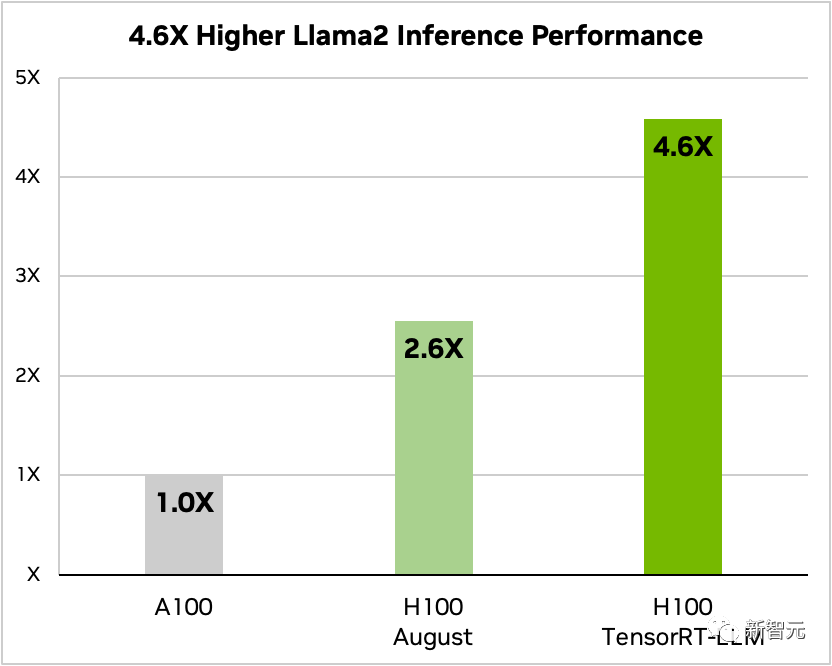
对比Llama 2 70B、A100和H100在使用和不使用TensorRT-LLM的情况下的比较
网友表示,超强H100,再结合上TensorRT-LLM,无疑将彻底改变大型语言模型推理现状!

当前,由于大模型有着巨大的参数规模,使得「部署和推理」难度和成本一直居高不下。
英伟达开发的TensorRT-LLM旨在通过GPU来显著提高LLM的吞吐量,并降低成本

具体而言,TensorRT-LLM将TensorRT的深度学习编译器、FasterTransformer的优化内核、预处理和后处理以及多GPU/多节点通信封装在一个简单的开源Python API中
英伟达对FasterTransformer进行了进一步的增强,使其成为一个产品化的解决方案。
可见,TensorRT-LLM提供了一个易用、开源和模块化的Python应用编程接口。
不需要深入了解C++或CUDA专业知识的码农们,可以部署、运行和调试各种大型语言模型,并且能够获得卓越的性能表现,以及快速定制化的功能

根据英伟达官方博客的报道,TensorRT-LLM采用了四种方法来提升Nvidia GPU上的LLM推理性能
首先,为当前10+大模型,引入TensorRT-LLM,让开发者们能够立即运行。
其次,TensorRT-LLM作为一个开源软件库,允许LLM在多个GPU和多个GPU服务器上同时进行推理。
这些服务器分别通过,英伟达的NVLink和InfiniBand互连连接。
第三点是关于「机内批处理」,这是一项全新的调度技术,它允许不同模型的任务独立于其他任务进入和退出GPU
最后,TensorRT-LLM经过优化,可以利用H100 Transformer Engine来降低模型推理时的内存占用和延迟。
下面我们来详细看一下TensorRT-LLM是如何提升模型性能的
TensorRT-LLM为开源模型生态提供了出色的支持
需要重写的内容是:具有最大规模和最先进的语言模型,例如Meta推出的Llama 2-70B,需要多个GPU协同工作才能实时提供响应
以前,要实现LLM推理的最佳性能,开发人员必须手动重写AI模型,并将其分解成多个片段,然后在GPU之间进行协调执行

TensorRT-LLM使用张量并行技术,将权重矩阵分配到各个设备上,从而简化了这一过程,可以实现大规模高效推理
每个模型可以在通过NVLink连接的多个GPU和多个服务器上并行运行,无需开发人员干预或模型更改。
随着新模型和模型架构的推出,开发人员可以使用TensorRT-LLM中开源的最新NVIDIA AI内核(Kernal)来优化模型
需要进行改写的内容是:支持的内核融合(Kernal Fusion)包括最新的FlashAttention实现,以及用于GPT模型执行的上下文和生成阶段的掩码多头注意力等
此外,TensorRT-LLM还包括了目前流行的许多大语言模型的完全优化、可立即运行的版本。
这些模型包括Meta Llama 2、OpenAI GPT-2和GPT-3、Falcon、Mosaic MPT、BLOOM等十多个。所有这些模型都可以使用简单易用的TensorRT-LLM Python API来调用
这些功能可帮助开发人员更快、更准确地搭建定制化的大语言模型,以满足各行各业的不同需求。
现如今大型语言模型的用途极其广泛。
一个模型可以同时用于多种看起来完全不同的任务——从聊天机器人中的简单问答响应,到文档摘要或长代码块的生成,工作负载是高度动态的,输出大小需要满足不同数量级任务的需求。
任务的多样性可能会导致难以有效地批处理请求和进行高效并行执行,可能会导致某些请求比其他请求更早完成。

为了管理这些动态负载,TensorRT-LLM包含一种称为「In-flight批处理」的优化调度技术。
大语言模型的核心原理在于,整个文本生成过程可以通过模型的多次迭代来实现
通过in flight批处理,TensorRT-LLM运行时会立即从批处理中释放出已完成的序列,而不是等待整个批处理完成后再继续处理下一组请求。
在执行新请求时,上一批还未完成的其他请求仍在处理中。
通过进行机上批处理和进行额外的内核级优化,可以提高GPU的利用率,从而使得H100上LLM的实际请求基准的吞吐量至少增加一倍
TensorRT-LLM还提供了一个名为H100 Transformer Engine的功能,能有效降低大模型推理时的内存消耗和延迟。
因为LLM包含数十亿个模型权重和激活函数,通常用FP16或BF16值进行训练和表示,每个值占用16位内存。
然而,在推理时,大多数模型可以使用量化(Quantization)技术以较低精度有效表示,例如8位甚至4位整数(INT8或 INT4)。
量化(Quantization)是在不牺牲准确性的情况下降低模型权重和激活精度的过程。使用较低的精度意味着每个参数较小,并且模型在GPU内存中占用的空间较小。

这样做可以使用相同的硬件对更大的模型进行推理,同时在执行过程中减少在内存操作上的时间消耗
通过H100 Transformer Engine技术,配合TensorRT-LLM的H100 GPU使户能够轻松地将模型权重转换为新的FP8格式,并能自动编译模型以利用优化后的FP8内核。
而且这个过程不需要任何的代码!H100引入的FP8数据格式使开发人员能够量化他们的模型并从大幅度减少内存消耗,而且不会降低模型的准确性。
与INT8或INT4等其他数据格式相比,FP8量化保留了更高的精度,同时实现了最快的性能,并且实现起来最为方便。 与INT8或INT4等其他数据格式相比,FP8量化保留了更高的精度,同时实现了最快的性能,并且实现起来最为方便
尽管TensorRT-LLM尚未正式发布,但用户现在已经可以提前体验了
申请链接如下:
https://developer.nvidia.com/tensorrt-llm-early-access/join
英伟达也说会将TensorRT-LLM很快集成到NVIDIA NeMo框架中。
这个框架是最近由英伟达推出的AI Enterprise的组成部分,为企业客户提供了一个安全、稳定、可管理性极强的企业级AI软件平台
开发人员和研究人员可以通过英伟达NGC上的NeMo框架或GitHub上的项目来访问TensorRT-LLM
但是需要注意的是,用户必须注册英伟达开发者计划才能申请抢先体验版本。
Reddit上的用户对TensorRT-LLM的发布进行了激烈的讨论
难以想象专门针对LLM对硬件做出优化之后,效果将会有多大的提升。

但也有网友认为,这个东西的意义就是帮助老黄卖更多的H100。
有些网友对此持不同意见,他们认为Tensor RT对于本地部署深度学习的用户也是有帮助的。只要拥有RTX GPU,将来在类似的产品上也有可能受益

从更宏观的角度来看,也许对于LLM而言,会出现一系列专门针对硬件级别的优化措施,甚至可能会出现专门为LLM设计的硬件来提升其性能。这种情况在许多流行的应用中已经出现过,LLM也不会例外
以上是H100推理飙升8倍!英伟达官宣开源TensorRT-LLM,支持10+模型的详细内容。更多信息请关注PHP中文网其他相关文章!





















