

优化器在大语言模型的训练中占据了大量内存资源。
现在有一种新的优化方式,在性能保持不变的情况下将内存消耗降低了一半。
该成果由新加坡国立大学打造,在ACL会议上获得了杰出论文奖,并已经投入了实际应用。
 图片
图片
随着大语言模型不断增加的参数量,训练时的内存消耗问题更为严峻。
研究团队提出了 CAME 优化器,在减少内存消耗的同时,拥有与Adam相同的性能。
 图片
图片
CAME优化器在多个常用的大规模语言模型的预训练上取得了相同甚至超越Adam优化器的训练表现,并对大batch预训练场景显示出更强的鲁棒性。
进一步地,通过CAME优化器训练大语言模型,能够大幅度降低大模型训练的成本。
CAME 优化器基于 Adafactor 优化器改进而来,后者在大规模语言模型的预训练任务中往往带来训练性能的损失。
Adafactor中的非负矩阵分解操作在深度神经网络的训练中不可避免地会产生错误,对这些错误的修正就是性能损失的来源。
而通过对比发现,当起始数值mt和当前数值t相差较小时,mt的置信度更高。
 图片
图片
受这一点启发,团队提出了一种新的优化算法。
下图中的蓝色部分就是CAME相比Adafactor增加的部分。
 图片
图片
CAME 优化器基于模型更新的置信度进行更新量修正,同时对引入的置信度矩阵进行非负矩阵分解操作。
最终,CAME成功以Adafactor的消耗得到了Adam的效果。
团队使用CAME分别训练了BERT、GPT-2和T5模型。
此前常用的Adam(效果更优)和Adafactor(消耗更低)是衡量CAME表现的参照。
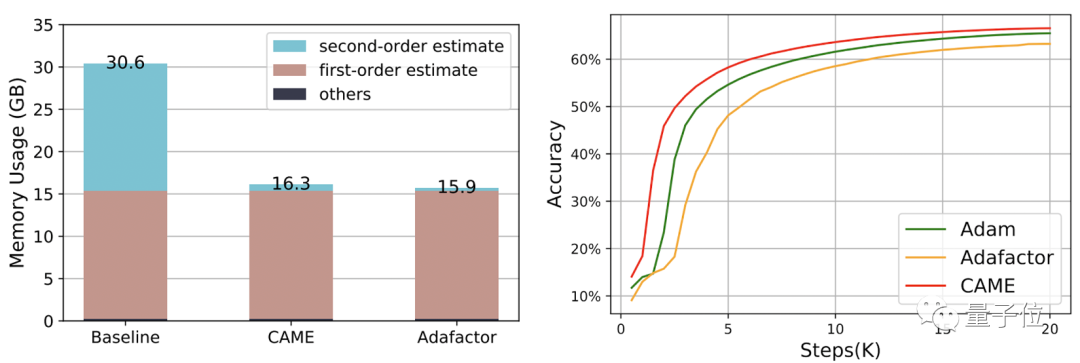
其中,在训练BERT的过程中,CAME仅用一半的步数就达到了和Adafaactor相当的精度。
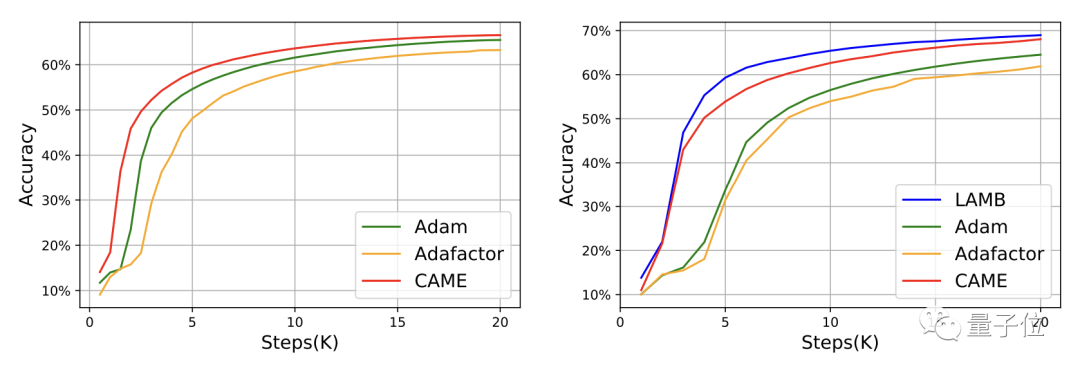 △左侧为8K规模,右侧为32K规模
△左侧为8K规模,右侧为32K规模
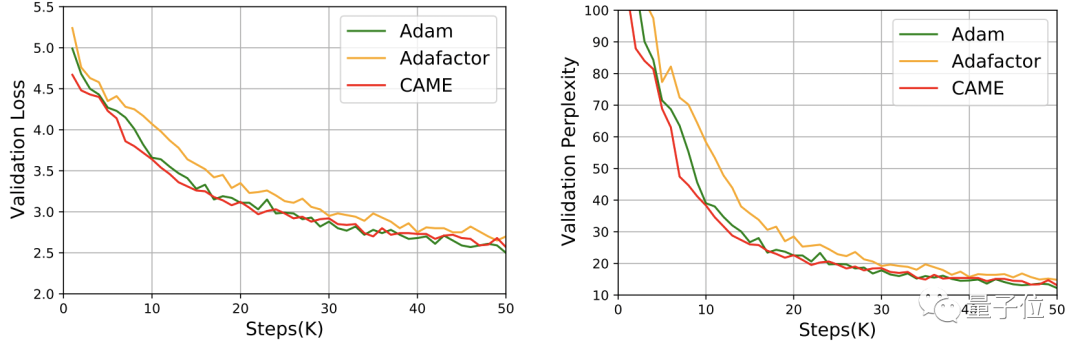
对于GPT-2,从损失和困惑度两个角度看,CAME的表现和Adam十分接近。

在T5模型的训练中,CAME也呈现出了相似的结果。
而对于模型的微调,CAME在精确度上的表现也不输于基准。
资源消耗方面,在使用PyTorch训练4B数据量的BERT时,CAME消耗的内存资源比基准减少了近一半。
新加坡国立大学HPC-AI 实验室是尤洋教授领导的高性能计算与人工智能实验室。
实验室致力于高性能计算、机器学习系统和分布式并行计算的研究和创新,并推动在大规模语言模型等领域的应用。
实验室负责人尤洋是新加坡国立大学计算机系的校长青年教授(Presidential Young Professor)。
尤洋在2021年被选入福布斯30岁以下精英榜(亚洲)并获得IEEE-CS超算杰出新人奖,当前的研究重点是大规模深度学习训练算法的分布式优化。
本文第一作者罗旸是该实验室的在读硕士生,他当前研究重点为大模型训练的稳定性以及高效训练。
论文地址:https://arxiv.org/abs/2307.02047
GitHub 项目页:https://github.com/huawei-noah/Pretrained-Language-Model/tree/master/CAME
以上是大模型训练成本降低近一半!新加坡国立大学最新优化器已投入使用的详细内容。更多信息请关注PHP中文网其他相关文章!





















