

当前大语言模型 (Large Language Models, LLMs) 如 GPT4 在遵循给定图像的开放式指令方面表现出了出色的多模态能力。然而,这些模型的性能严重依赖于对网络结构、训练数据和训练策略等方案的选择,但这些选择并没有在先前的文献中被广泛讨论。此外,目前也缺乏合适的基准 (benchmarks) 来评估和比较这些模型,限制了多模态 LLMs 的 发展。
 图片
图片
在这篇文章中,作者从定量和定性两个方面对此类模型的训练进行了系统和全面的研究。设置了 20 多种变体,对于网络结构,比较了不同的 LLMs 主干和模型设计;对于训练数据,研究了数据和采样策略的影响;在指令方面,探讨了多样化提示对模型指令跟随能力的影响。对于 benchmarks ,文章首次提出包括图像和视频任务的开放式视觉问答评估集 Open-VQA。
基于实验结论,作者提出了 Lynx,与现有的开源 GPT4-style 模型相比,它在表现出最准确的多模态理解能力的同时,保持了最佳的多模态生成能力。
不同于典型的视觉语言任务,评估 GPT4-style 模型的主要挑战在于平衡文本生成能力和多模态理解准确性两个方面的性能。为了解决这个问题,作者提出了一种包含视频和图像数据的新 benchmark Open-VQA,并对当前的开源模型进行了全面的评价。
具体来说,采用了两种量化评价方案:
为了深入研究多模态 LLMs 的训练策略,作者主要从网络结构(前缀微调 / 交叉注意力)、训练数据(数据选择及组合比例)、指示(单一指示 / 多样化指示)、LLMs 模型(LLaMA [5]/Vicuna [6])、图像像素(420/224)等多个方面设置了二十多种变体,通过实验得出了以下主要结论:
作者提出了 Lynx(猞猁)—— 进行了两阶段训练的 prefix-finetuning 的 GPT4-style 模型。在第一阶段,使用大约 120M 图像 - 文本对来对齐视觉和语言嵌入 (embeddings) ;在第二阶段,使用 20 个图像或视频的多模态任务以及自然语言处理 (NLP) 数据来调整模型的指令遵循能力。
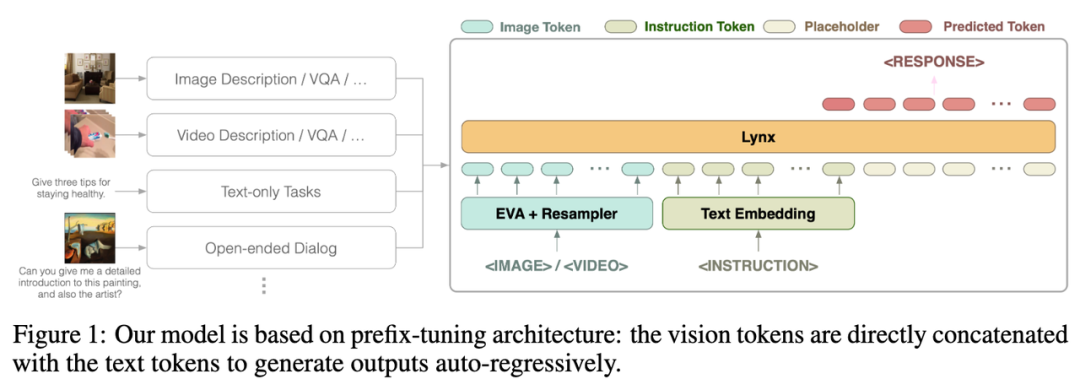 图片
图片
Lynx 模型的整体结构如上图 Figure 1 所示。
视觉输入经过视觉编码器处理后得到视觉令牌 (tokens) $$W_v$$,经过映射后与指令 tokens $$W_l$$ 拼接作为 LLMs 的输入,在本文中将这种结构称为「prefix-finetuning」以区别于如 Flamingo [3] 所使用的 cross-attention 结构。
此外,作者发现,通过在冻结 (frozen) 的 LLMs 某些层后添加适配器 (Adapter) 可以进一步降低训练成本。
作者测评了现有的开源多模态 LLMs 模型在 Open-VQA、Mme [4] 及 OwlEval 人工测评上的表现(结果见后文图表,评估细节见论文)。可以看到 Lynx 模型在 Open-VQA 图像和视频理解任务、OwlEval 人工测评及 Mme Perception 类任务中都取得了最好的表现。其中,InstructBLIP 在多数任务中也实现了高性能,但其回复过于简短,相较而言,在大多数情况下 Lynx 模型在给出正确的答案的基础上提供了简明的理由来支撑回复,这使得它对用户更友好(部分 cases 见后文 Cases 展示部分)。
1. 在 Open-VQA 图像测试集上的指标结果如下图 Table 1 所示:
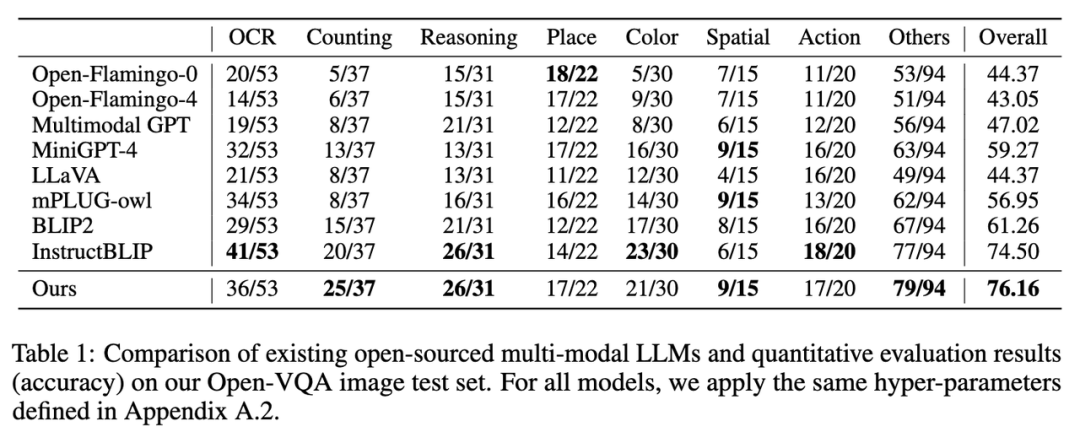 图片
图片
2. 在 Open-VQA 视频测试集上的指标结果如下图 Table 2 所示。
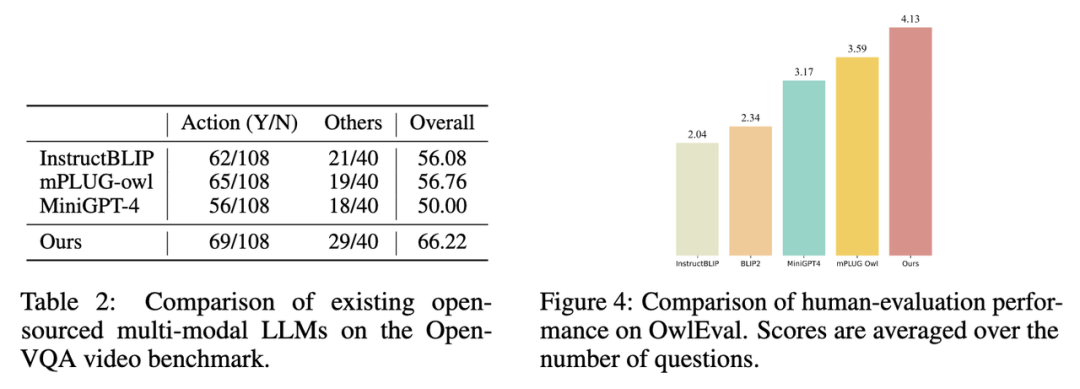 图片
图片
3. 选取 Open-VQA 中得分排名靠前的模型进行 OwlEval 测评集上的人工效果评估,其结果如上图 Figure 4 所示。从人工评价结果可以看出 Lynx 模型具有最佳的语言生成性能。
 图片
图片
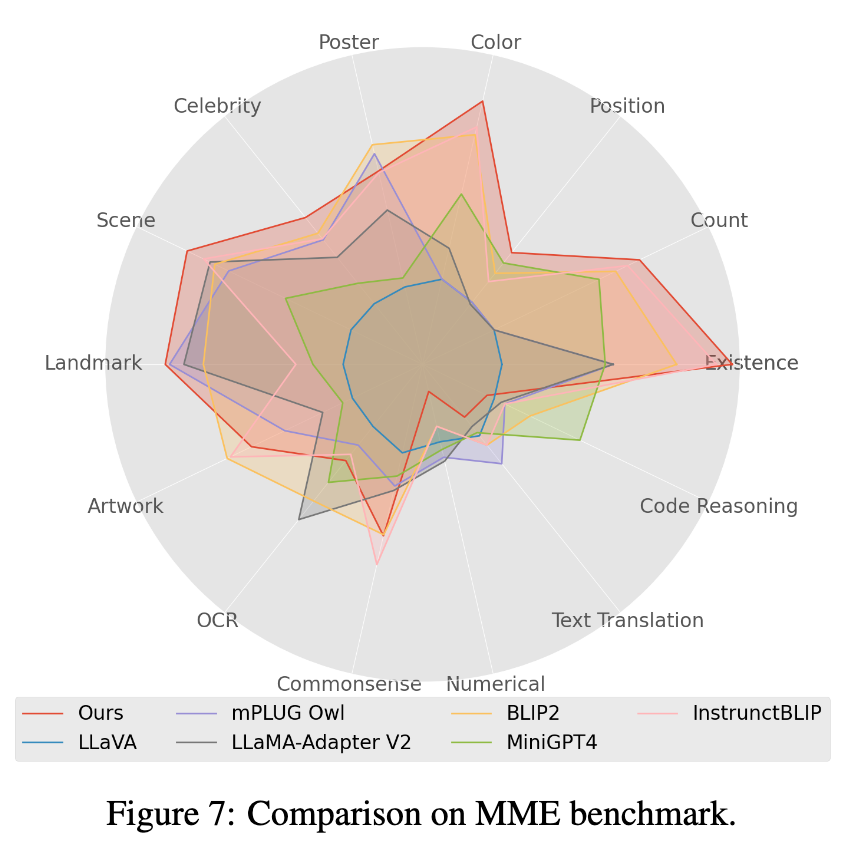
4. 在 Mme benchmark 测试中,Perception 类任务获得最好的表现,其中 14 类子任务中有 7 个表现最优。(详细结果见论文附录)
Open-VQA 图片 cases

OwlEval cases

Open-VQA 视频 case

在本文中,作者通过对二十多种多模态 LLMs 变种的实验,确定了以 prefix-finetuning 为主要结构的 Lynx 模型并给出开放式答案的 Open-VQA 测评方案。实验结果显示 Lynx 模型表现最准确的多模态理解准确度的同时,保持了最佳的多模态生成能力。
以上是字节团队提出猞猁Lynx模型:多模态LLMs理解认知生成类榜单SoTA的详细内容。更多信息请关注PHP中文网其他相关文章!





















