

自ChatGPT API开放后,大量的研究都选择利用ChatGPT和GPT-4等大型基础模型(LFM)的输出作为训练数据,然后通过模仿学习来提升小模型的能力。
但由于模仿信号流于表面、训练数据量不够大、缺乏严格的评估标准等问题,小模型的实际性能被高估了。
从效果上来看,小模型更倾向于模仿LFM的输出风格,而非推理过程。

论文链接:https://arxiv.org/pdf/2306.02707.pdf
为了应对这些挑战,微软最近发布了一篇长达51页论文,提出了一个130亿参数的Orca模型,可以学习模仿LFMs的推理过程。
研究人员为大模型设计了丰富的训练信号,使得Orca可以从GPT-4中学习到解释痕迹、逐步的思维过程、复杂的指令等,并由ChatGPT的教师协助指导;并通过采样和选择来挖掘大规模且多样化的模仿数据,可以进一步提升渐进式学习效果。
在实验评估中,Orca超过了其他SOTA指令微调模型,在BigBench Hard(BBH)等复杂的零样本推理基准中实现了比Vicuna-13B翻倍的性能表现,在AGIEval上也实现了42%的性能提升。
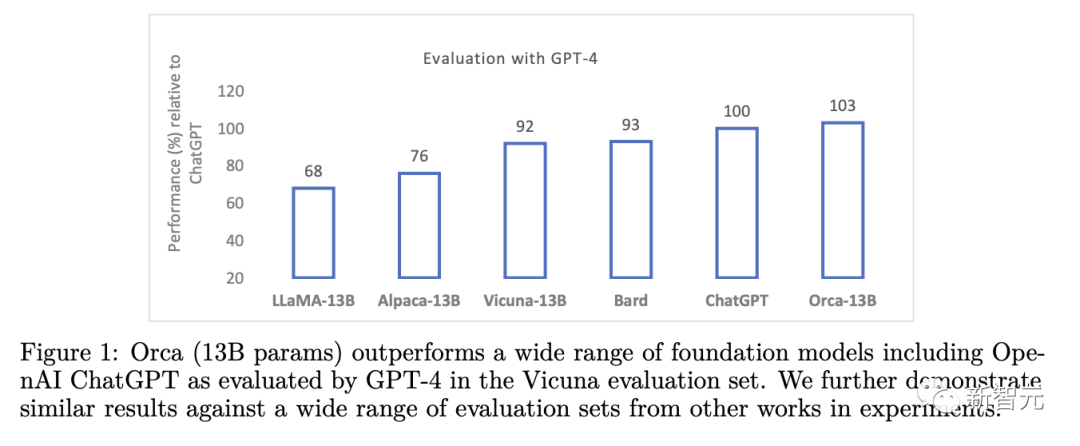
此外,Orca在BBH基准上还实现了与ChatGPT持平的性能,在SAT、LSAT、GRE和GMAT等专业和学术考试中只有4%的性能差距,并且都是在没有思维链的零样本设置下测量的。
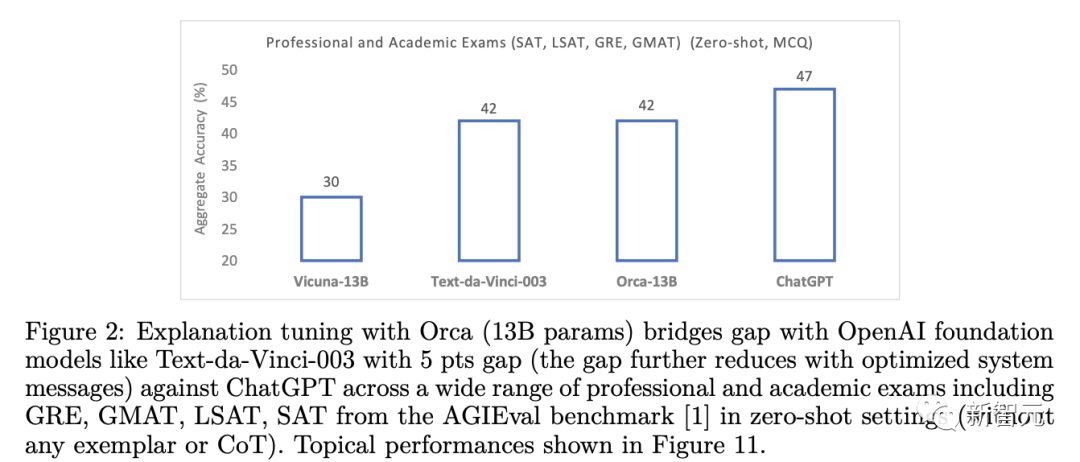
研究结果表明,让模型从分步解释中学习,无论这些解释是由人类还是更高级的人工智能模型产生的,都是提高模型能力和技能的一个有前景的研究方向。
数据集构造
在训练数据中,每个实例都包括三部分,即系统消息、用户查询和LFM回复。
系统消息(system message)放置在提示中开头的部分,提供给LFM基本的上下文、引导以及其他相关的细节。
系统消息可以用来改变回复的长度、描述AI助手的性格、建立可接受和不可接受的LFM行为,并确定AI模型的回复结构。
研究人员手工制作了16条系统信息来设计LFM不同类型的回复,可以生成创造性的内容以及解决信息查询问题,最重要的是能够根据提示生成解释和逐步推理的答案。

用户查询(user query)定义了希望LFM执行的实际任务。
为了获得大量的、多样化的用户查询,研究人员利用FLAN-v2集合,从中抽取500万个用户查询(FLAN-5M),并收集ChatGPT的回复;然后进一步从500万条指令中抽出100万条指令(FLAN-1M),收集GPT-4的回复。
FLAN-v2集合由五个子集合组成,即CoT、NiV2、T0、Flan 2021和Dialogue,其中每个子集包含多个任务,每个任务都是一个查询的集合。
每个子集合都与多个学术数据集相关,并且每个数据集都有一个或多个任务,主要关注零样本和少样本的查询。
在这项工作中,研究人员只取样训练Orca的零样本查询,并且没有从Dialogue子集中取样,因为这些查询往往缺乏背景,无法从ChatGPT中获得有用的回复。
让ChatGPT扮演Teaching Assistant
首先在FLAN-5M数据上训练Orca(ChatGPT增强),随后在FLAN-1M上进行第二阶段的训练(GPT-4增强)。
将ChatGPT作为中间的教师助手主要有两个原因:
1. 能力差距
虽然GPT-4的参数量没有公开,但130亿参数的Orca肯定比GPT-4要小很多倍,而ChatGPT和Orca之间的能力差距更小,更适合作为中间教师,并且这种方式已经被证明可以提高更小的学生模型在知识蒸馏中的模仿学习性能。
这种方式也可以看作是一种渐进式学习或课程学习,学生首先从较容易的例子中学习,然后再学习较难的例子,假定了较长的回复会比较短的回复更难模仿,可以从更大规模的教师模型中改进推理和逐步解释能力。
2. 成本和时间
从Azure OpenAI API进行大规模数据收集时会受到一些限制,包括每分钟请求的速率限制,防止流量过大;由于服务延迟问题,每分钟可用的token数量有限;提示长度和token补全的金钱成本。

相比之下,ChatGPT API比GPT-4终端更快、更便宜,所以从ChatGPT上收集了比GPT-4多5倍的数据。
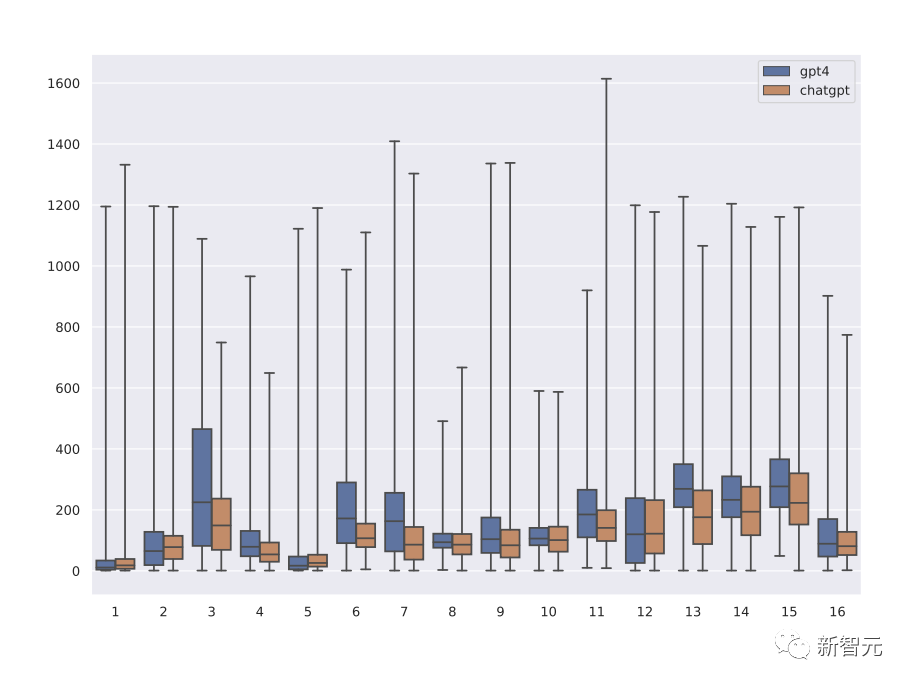
从ChatGPT和GPT-4对应于不同系统消息的回复长度分布中可以观察到,GPT-4的回复平均比ChatGPT长1.5倍,使得Orca能够逐步从教师解释的复杂性中学习,并通过消融实验证明了教师帮助的影响。
训练
在分词阶段,研究人员利用LLaMA的字节对编码(BPE)分词器来处理输入的样本,其中多位数字会被分割成多个单数字,并回落到字节来分解未知的UTF-8字符。
为了处理可变长度的序列,在LLaMA分词器的词汇表中引入了一个填充词[[PAD]],最终的词汇表包含32001个token
为了优化训练过程并有效利用可用的计算资源,研究人员利用了packing技术,将多个输入实例串联成一个序列后再训练模型。
在packing的过程中,串联序列的总长度不超过max_len=2048 tokens,对输入的样本进行随机打乱后将分成几组,每组串联序列的长度最多为max_len
考虑到训练数据中增强指令的长度分布,每个序列的打包系数为2.7
为了训练Orca,研究人员选择只计算教师模型生成token的损失,也就是说学习生成以系统信息和任务指令为条件的回复,可以确保模型专注于从最相关和最有信息的token中学习,提高了训练过程的整体效率和效果。
最后在20个装有80GB内存的NVIDIA A100 GPU上训练Orca,先在FLAN-5M(ChatGPT增强)上训练4个epoch,花了160个小时;然后在FLAN-1M(GPT-4增强)上继续训练4个epoch
由于流量限制、终端负载以及回复的长度问题,从GPT-3.5-turbo(ChatGPT)和GPT-4的多个终端收集数据分别用了2周和3周的时间。
研究人员主要验证了Orca在推理上的能力。
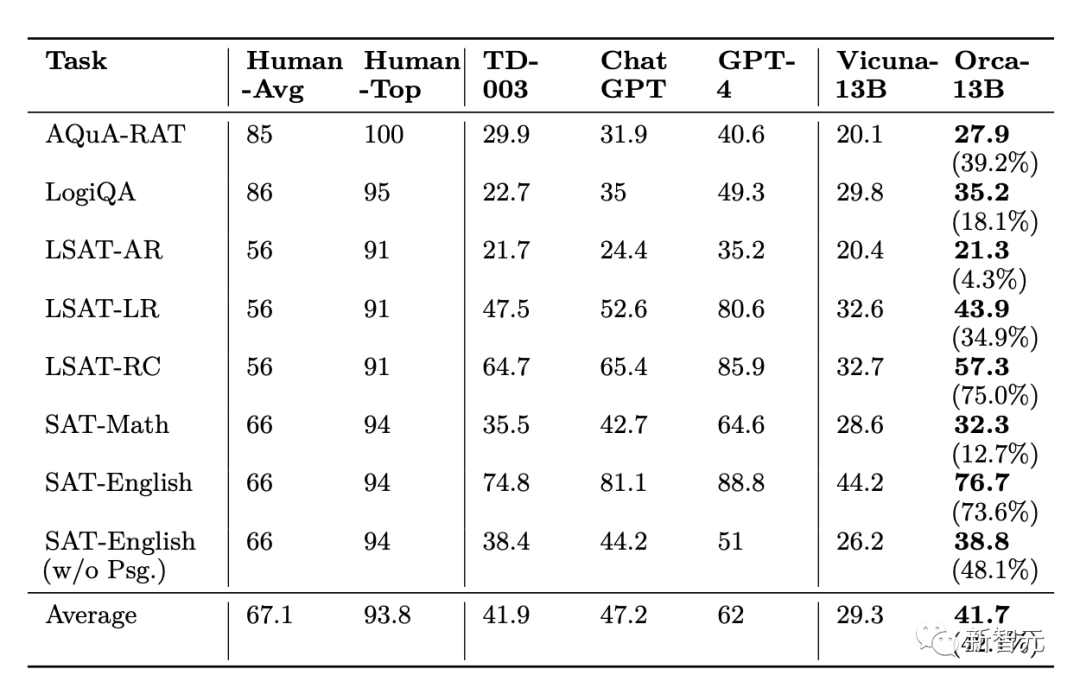
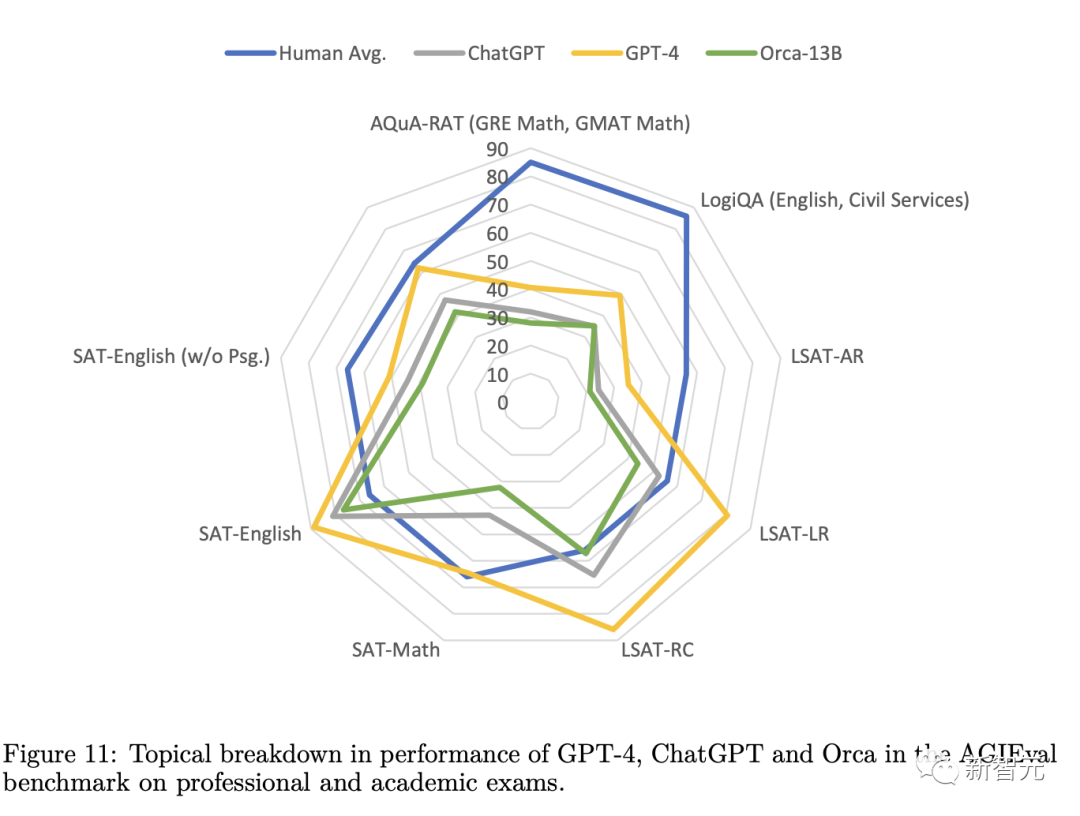
在AGIEval的实验中可以看到,Orca的表现与Text-da-Vinci-003相当,并实现了ChatGPT 88%的性能表现,不过明显落后于GPT-4
对于分析和推理任务,Vicuna的表现明显更差,只保留了62%的ChatGPT质量,表明这种开源语言模型的推理能力很差。
虽然Orca与Text-da-Vinci-003的表现相当,但仍然比ChatGPT低5分,Orca在与数学有关的任务(在SAT、GRE、GMAT中)上与ChatGPT表现出较大的差距。
与Vicuna相比,Orca显示出更强的性能,在每个类别上都超过了Vicuna,平均有42%的相对提高。
GPT-4的性能远远超过了所有其他模型,但在这个基准中仍有很大的提升空间,目前所有模型的性能都明显低于人类的得分。
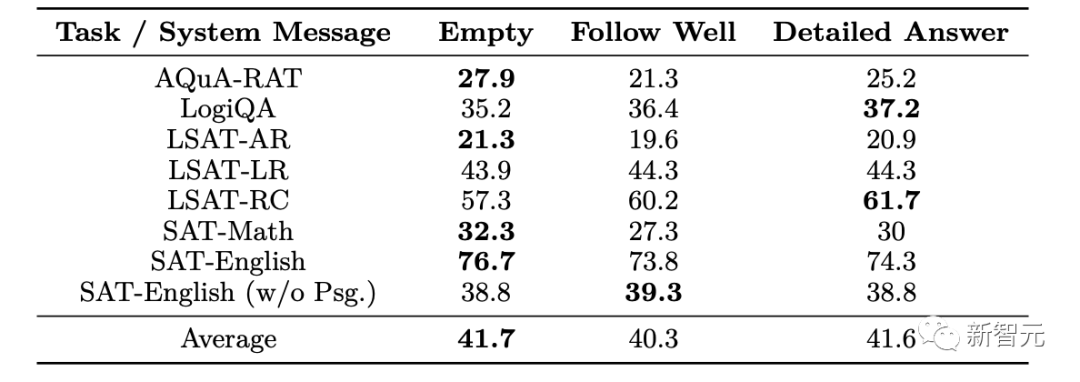
Orca的性能根据系统信息的类型有很大的不同,对于训练的模型来说,空的系统消息往往效果很好。
Orca在不同任务的325个样本中超越了ChatGPT(Orca-beats-ChatGPT例子),其中大部分来自LogiQA(29%),而其他LSAT任务和SAT-英语任务各占不到10%
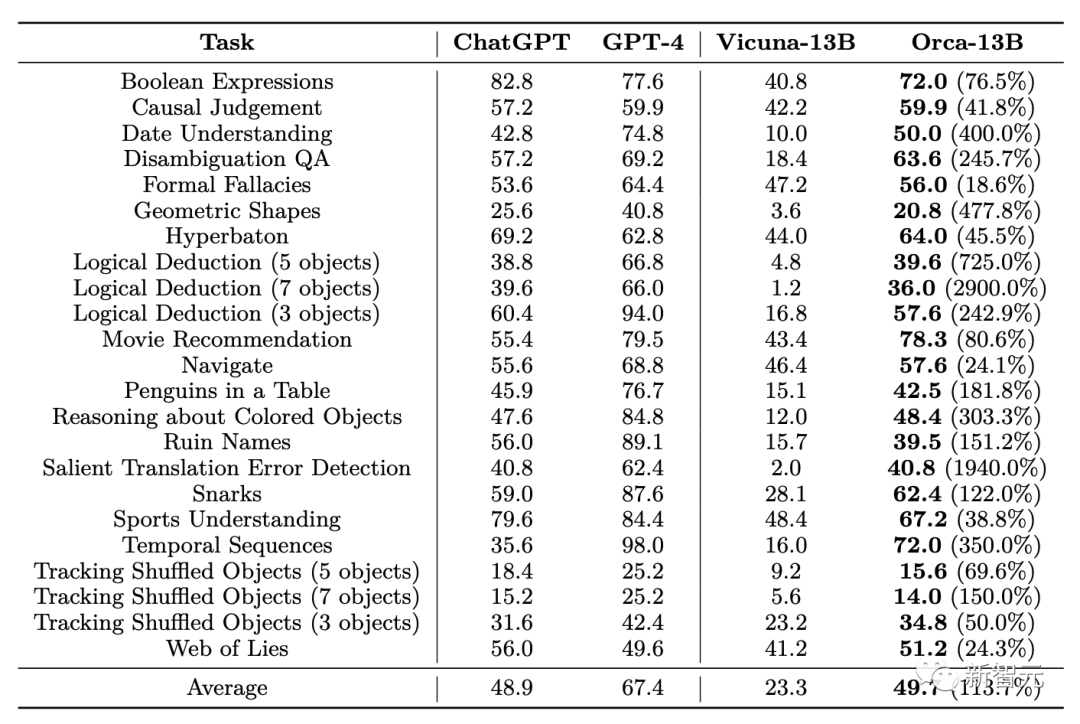
在Big-Bench Hard Results数据集上的推理评估结果显示,Orca在所有任务中的综合表现上略好于ChatGPT,但明显落后于GPT-4;比Vicuna性能高出113%
以上是「模仿学习」只会套话?解释微调+130亿参数Orca:推理能力打平ChatGPT的详细内容。更多信息请关注PHP中文网其他相关文章!





















