

过去十多年,AI的飞速发展主要是工程实践上的进步,AI理论并没有起到指导算法开发的作用,经验设计的神经网络依然是一个黑盒。
而随着ChatGPT的爆火,AI的能力也被不断夸大、炒作,甚至到了威胁、绑架社会的地步,让Transformer架构设计变透明已刻不容缓!

最近,马毅教授团队发布了最新研究成果,设计了一个完全可用数学解释的白盒Transformer模型CRATE,并在真实世界数据集ImageNet-1K上取得了接近ViT的性能。
代码链接:https://github.com/Ma-Lab-Berkeley/CRATE
论文链接:https://arxiv.org/abs/2306.01129
在这篇论文中,研究人员认为,表示学习的目标是压缩和转换数据(例如token集合)的分布,以支持在不相干子空间(incoherent subspace)上的低维高斯分布混合,最终表征的质量可以通过稀疏率降低(sparse rate reduction)的统一目标函数来度量。
从这个角度来看,流行的深度网络模型,如Transformer等可以很自然地被认为是实现迭代方案(realizing iterative schemes)以逐步优化该目标。
特别是,研究结果表明标准Transformer块可以从对该目标的互补部分的交替优化中派生出:多头自注意力运算符可以被视为通过最小化有损编码率来压缩token集合的梯度下降步骤,而随后的多层感知器可以被视为尝试稀疏化token的表示。
这一发现也促进设计了一系列在数学上完全可解释的白盒Transformer类深度网络架构,尽管设计上很简单,但实验结果表明,这些网络确实学会了优化设计目标:压缩和稀疏化了大规模真实世界视觉数据集(如ImageNet)的表示,并实现了接近高度工程化Transformer模型(ViT)的性能。
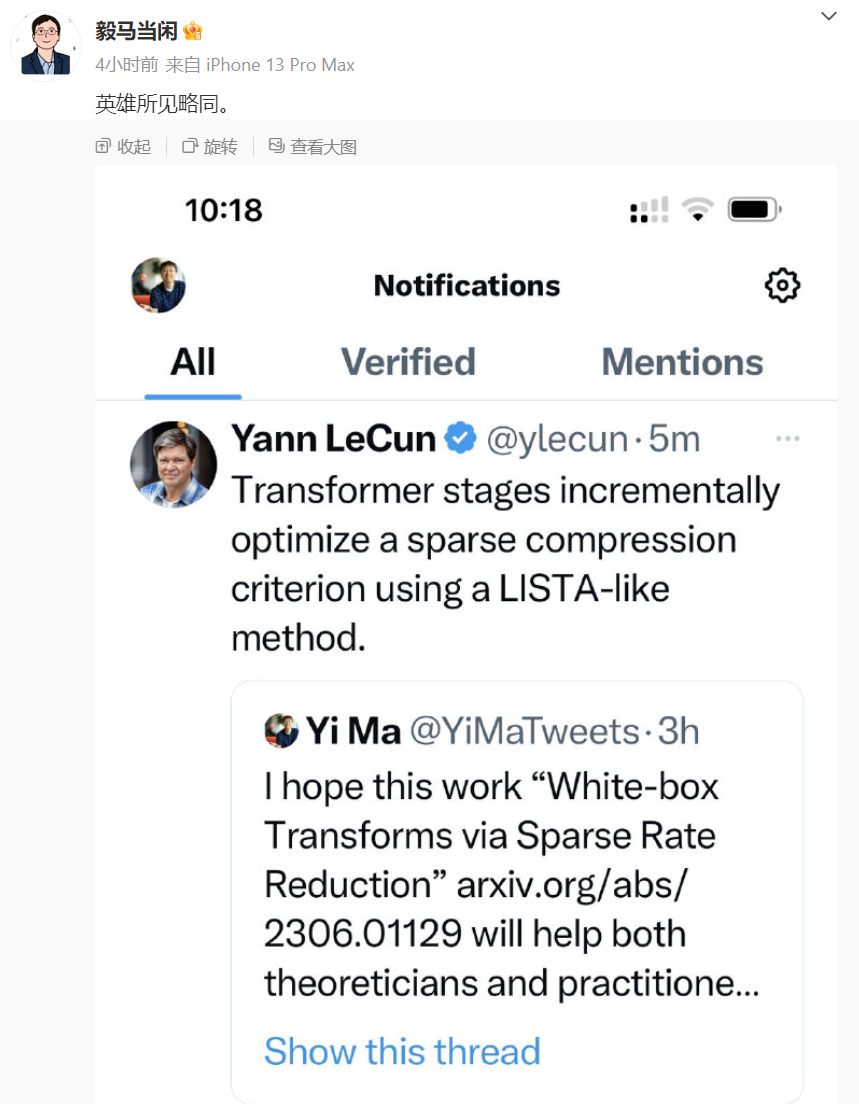
图灵奖得主Yann LeCun对马毅教授的工作也表示赞同,认为Transformer使用LISTA(Learned Iterative Shrinkage and Thresholding Algorithm)类似的方法增量地优化稀疏压缩。
马毅教授于1995年获得清华大学自动化与应用数学双学士学位,并于1997年获加州大学伯克利分校EECS硕士学位,2000年获数学硕士学位与EECS博士学位。

2018年马毅教授加入加州大学伯克利分校电子工程与计算机科学系,今年1月加入香港大学出任数据科学研究院院长,最近又接任香港大学计算系主任。
主要研究方向为3D计算机视觉、高维数据的低维模型、可扩展性优化和机器学习,最近的研究主题包括大规模3D几何重构和交互以及低维模型与深度网络的关系。
这篇论文的主要目的在于用一个更统一的框架以设计类似Transformer的网络结构,从而实现数学上的可解释性和良好的实际性能。
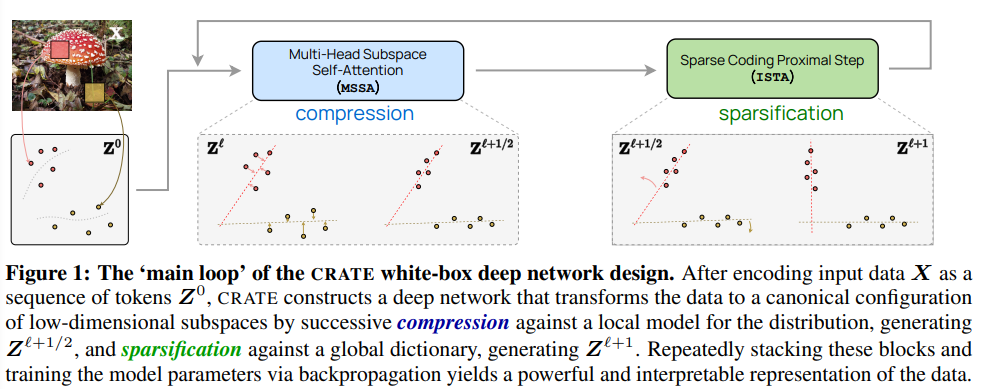
为此,研究人员提出学习一个增量映射(incremental mappings)序列,以获得输入数据(token集合)的最小压缩和最稀疏的表征,优化一个统一的目标函数,即稀疏率降低。

这个框架统一了「Transformer模型和自注意力」、「扩散模型和降噪」、「结构化查找和率降低」(Structure-seeking models and rate reduction)三种看似不同的方法,并表明类似Transformer的深层网络层可以自然地从展开迭代优化(unrolling iterative optimization)方案中导出, 以增量地优化稀疏率降低目标。
映射的目标
Self-Attention via Denoising Tokens Towards Multiple Subspaces
研究人员使用一个理想化的token分布模型表明,如果朝着低维子空间系列迭代去噪,相关的评分函数就会呈现出类似于Transformer中的自注意力操作符的显式形式。
Self-Attention via Compressing Token Sets through Optimizing Rate Reduction
研究人员将多头自注意力层推导为一个展开的梯度下降步,以最小化速率降低的有损编码率部分,从而展现了将自注意力层解释为压缩token表征的另一种解释方法。
MLP via Iterative Shrinkage-Thresholding Algorithms (ISTA) for Sparse Coding
研究人员展示了在Transformer块中紧随多头自注意力层后面的多层感知机可以被解释为(并且可以被替换为)一个层,该层通过构建token表征稀疏编码来逐步优化稀疏率降低目标剩余部分。
结合上述理解,研究人员创建了一个全新的的白盒Transformer架构CRATE(Coding RAte reduction TransformEr),学习目标函数、深度学习架构和最终学习到的表征都完全可以用数学解释,其中每一层执行交替最小化算法(alternating minimization algorithm)的一个步骤,以优化稀疏率降低目标。

可以注意到,CRATE在构建的每个阶段都选择了尽可能最简单的构建方式,只要新构建的部分保持相同的概念角色,就可以直接替换,并获得一个新的白盒架构。
研究人员的实验目标不仅仅是在使用基本设计的情况下与其他精心设计的Transformer竞争,还包括:
1、与通常仅在端到端性能上评估的经验设计的黑盒网络不同,白盒设计的网络可以查看深层架构的内部,并验证学习网络的层是否确实执行其设计目标,即对目标进行增量优化。
2、尽管CRATE架构很简单,但实验结果应当验证该架构的巨大潜力,即可以在大规模真实世界的数据集和任务上取得与高度工程化Transformer模型相匹配的性能。
模型架构
通过变化token维度、头数和层数,研究人员创建了四个不同规模的CRATE模型,表示为CRATE-Tiny,CRATE-Small,CRATE-Base和CRATE-Large
数据集和优化
文中主要考虑ImageNet-1K作为测试平台,使用Lion优化器来训练具有不同模型规模的CRATE模型。
同时还评估了CRATE的迁移学习性能:在ImageNet-1K上训练的模型作为预训练模型,然后在几个常用的下游数据集(CIFAR10/100、Oxford Flowers、Oxford-IIT-Pets)上对CRATE进行微调。
CRATE的层实现设计目标了吗?

随着层索引的增加,可以看到CRATE-Small模型在大多数情况下的压缩和稀疏化项都得到了提升,最后一层稀疏性度量的增加是由于用于分类的额外线性层。
结果表明,CRATE与原始的设计目标非常契合:一旦学习完毕,基本上通过其层逐渐学习对表示进行压缩和稀疏化。

在其他规模的CRATE模型以及中间模型检查点上测量压缩和稀疏化项后可以发现,实验结果依然非常一致,具有更多层的模型往往能更有效地优化目标,验证了之前对每个层角色的理解。
性能对比
通过测量ImageNet-1K上的最高准确率以及在几个广泛使用的下游数据集上的迁移学习性能来研究所提出的网络的经验性能。
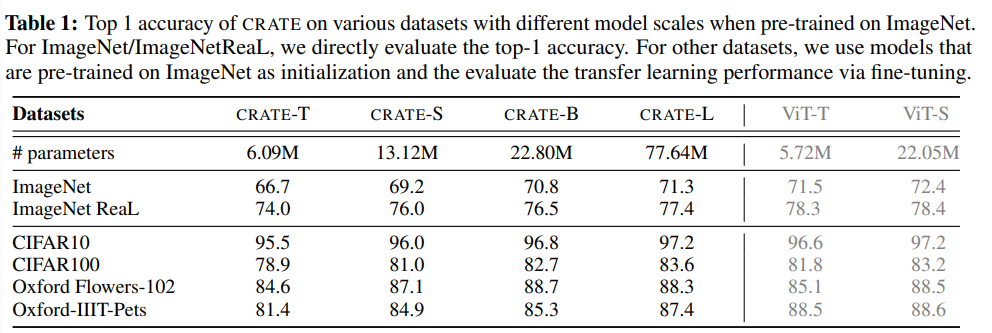
由于设计的架构在注意力块(MSSA)和MLP块(ISTA)中都利用了参数共享,所以CRATE-Base模型(2208万)与ViT-Small(2205万)的参数数量相似。
可以看到,在模型参数数量相似的情况下,文中提出的网络实现了与ViT相似的ImageNet-1K和迁移学习性能,但CRATE的设计更简单,可解释性强。
此外,在相同的训练超参数下,CRATE还可以继续扩展,即通过扩大模型的规模不断提高性能,而在ImageNet-1K上直接扩大ViT的规模并不总是能带来一致的性能改善。
也就是说,CRATE网络尽管简单,但已经可以在大规模的真实世界数据集上学习所需的压缩和稀疏表示,并在各种任务(如分类和迁移学习)上取得与更工程化Transformer网络(如ViT)相当的性能。
以上是LeCun力挺,马毅教授五年集大成之作:完全数学可解释的白盒Transformer,性能不输ViT的详细内容。更多信息请关注PHP中文网其他相关文章!





















