


多样高质的三维场景生成结果
使用人工智能辅助内容生成(AIGC)在图像生成领域涌现出大量的工作,从早期的变分自编码器(VAE),到生成对抗网络(GAN),再到最近大红大紫的扩散模型(Diffusion Model),模型的生成能力飞速提升。以 Stable Diffusion,Midjourney 等为代表的模型在生成具有高真实感图像方面取得了前所未有的成果。同时,在视频生成领域,最近也涌现出很多优秀的工作,如 Runway 公司的生成模型能够生成充满想象力的视频片段。这些应用极大降低了内容创作门槛,使得每个人都可以轻易地将自己天马行空的想法变为现实。
但是随着承载内容的媒介越来越丰富,人们渐渐不满足于图文、视频这些二维的图形图像内容。随着交互式电子游戏技术的不断发展,特别是虚拟和增强现实等应用的逐步成熟,人们越来越希望能身临其境地从三维视角与场景和物体进行互动,这带来了对三维内容生成的更大诉求。
如何快速地生成高质量且具有精细几何结构和高度真实感外观的三维内容,一直以来是计算机图形学社区研究者们重点探索的问题。通过计算机智能地进行三维内容生成,在实际生产应用中可以辅助游戏、影视制作中重要数字资产的生产,极大地减少了美术制作人员的开发时间,大幅地降低资产获取成本,并缩短整体的制作周期,也为用户带来千人千面的个性化视觉体验提供了技术可能。而对于普通用户来说,快速便捷的三维内容创作工具的出现,结合如桌面级三维打印机等应用,未来将为普通消费者的文娱生活带来更加无限的想象空间。
目前,虽然普通用户可以通过便携式相机等设备轻松地创建图像和视频等二维内容,甚至可以对三维场景进行建模扫描,但总体来说,高质量三维内容的创作往往需要有经验的专业人员使用如 3ds Max、Maya、Blender 等软件手动建模和渲染,但这些有很高的学习成本和陡峭的成长曲线。
其中一大主要原因是,三维内容的表达十分复杂,如几何模型、纹理贴图或者角色骨骼动画等。即使就几何表达而言,就可以有点云、体素和网格等多种形式。三维表达的复杂性极大地限制了后续数据采集和算法设计。
另一方面,三维数据天然具有稀缺性,数据获取的成本高昂,往往需要昂贵的设备和复杂的采集流程,且难以大量收集某种统一格式的三维数据。这使得大多数数据驱动的深度生成模型难有用武之地。
在算法层面,如何将收集到的三维数据送入计算模型,也是难以解决的问题。三维数据处理的算力开销,要比二维数据有着指数级的增长。暴力地将二维生成算法拓展到三维,即使是最先进的并行计算处理器也难以在可接受的时间内进行处理。
上述原因导致了当前三维内容生成的工作大多只局限于某一特定类别或者只能生成较低分辨率的内容,难以应用于真实的生产流程中。
为了解决上述问题,北京大学陈宝权团队联合山东大学和腾讯 AI Lab 的研究人员,提出了首个基于单样例场景无需训练便可生成多样高质量三维场景的方法。该算法具有如下优点:
1,无需大规模的同类训练数据和长时间的训练,仅使用单个样本便可快速生成高质量三维场景;
2,使用了基于神经辐射场的 Plenoxels 作为三维表达,场景具有高真实感外观,能渲染出照片般真实的多视角图片。生成的场景也完美的保留了样本中的所有特征,如水面的反光随视角变化的效果等;
3,支持多种应用制作场景,如三维场景的编辑、尺寸重定向、场景结构类比和更换场景外观等。
研究人员提出了一种多尺度的渐进式生成框架,如下图所示。算法核心思想是将样本场景拆散为多个块,通过引入高斯噪声,然后以类似拼积木的方式将其重新组合成类似的新场景。
作者使用坐标映射场这种和样本异构的表达来表示生成的场景,使得高质量的生成变得可行。为了让算法的优化过程更加鲁棒,该研究还提出了一种基于值和坐标混合的优化方法。同时,为了解决三维计算的大量资源消耗问题,该研究使用了精确到近似的优化策略,使得能在没有任何训练的情况下,在分钟级的时间生成高质量的新场景。更多的技术细节请参考原始论文。
随机场景生成

通过如左侧框内的单个三维样本场景,可以快速地生成具有复杂几何结构和真实外观的新场景。该方法可以处理具有复杂拓扑结构的物体,如仙人掌,拱门和石凳等,生成的场景完美地保留了样本场景的精细几何和高质量外观。当前没有任何基于神经网络的生成模型能做到相似的质量和多样性。
高分辨率大场景生成
该方法能高效地生成极高分辨率的三维内容。如上所示,我们可以通过输入单个左上角分辨率为 512 x 512 x 200 的三维 “千里江山图” 的一部分,生成 1328 x 512 x 200 分辨率的 “万里江山图”,并渲染出 4096 x 1024 分辨率的二维多视角图片。
真实世界无边界场景生成

作者在真实的自然场景上也验证了所提出的生成方法。通过采用与 NeRF++ 类似的处理方法,显式的将前景和天空等背景分开后,单独对前景内容进行生成,便可在真实世界的无边界场景中生成新场景。
其他应用场景
场景编辑
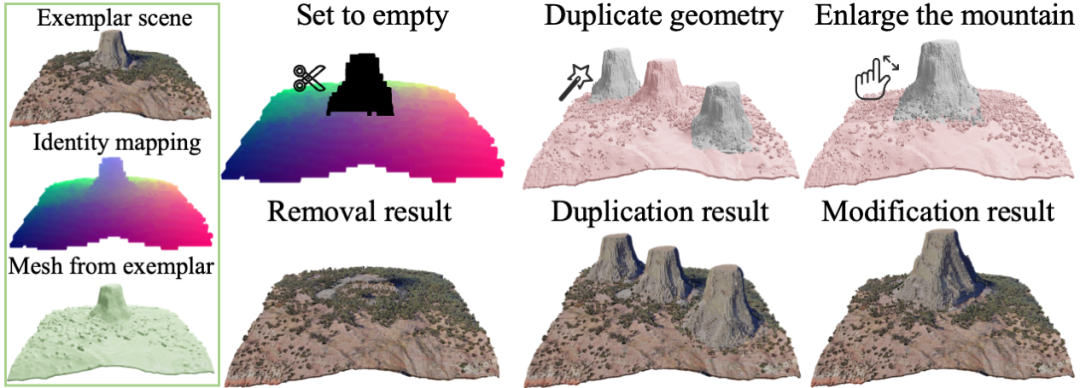
使用相同的生成算法框架,通过加入人为指定限制,可以对三维场景内的物体进行删除,复制和修改等编辑操作。如图中所示,可以移除场景中的山并自动补全孔洞,复制生成三座山峰或者使山变得更大。
尺寸重定向

该方法也可以对三维物体进行拉伸或者压缩的同时,保持其局部的形状。图中绿色框线内为原始的样本场景,将一列三维火车进行拉长的同时保持住窗户的局部尺寸。
结构类比生成

和图像风格迁移类似,给定两个场景 A 和 B,我们可以创建一个拥有 A 的外观和几何特征,但是结构与 B 相似的新场景。如我们可以参考一座雪山将另一座山变为三维雪山。
更换样本场景
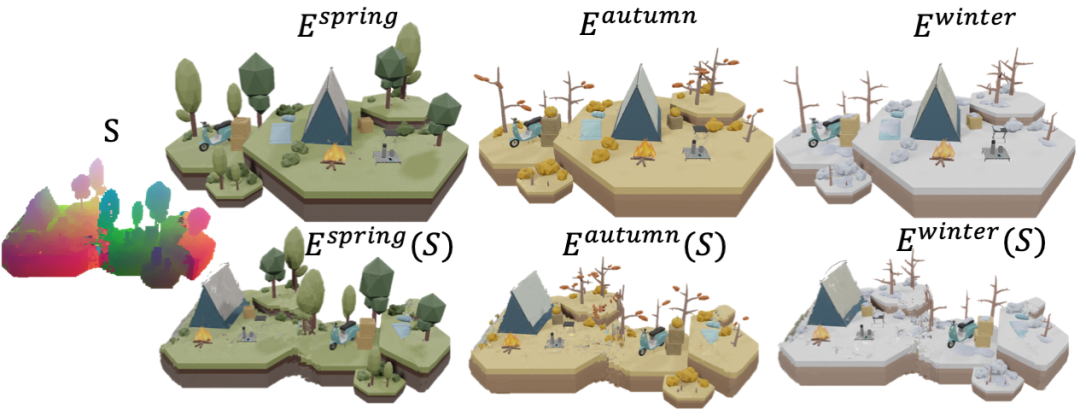
由于该方法对生成场景采用了异构表达,通过简单地修改其映射的样本场景,便可生成更加多样的新场景。如使用同一个生成场景映射场 S,映射不同时间或季节的场景,得到了更加丰富的生成结果。
这项工作面向三维内容生成领域,首次提出了一种基于单样本的三维自然场景生成模型,尝试解决当前三维生成方法中数据需求大、算力开销多、生成质量差等问题。该工作聚焦于更普遍的、语义信息较弱的自然场景,更多的关注生成内容的多样性和质量。算法主要受传统计算机图形学中纹理图像生成相关的技术,结合近期的神经辐射场,能快速地生成高质量三维场景,并展示了多种实际应用。
该工作有较强的通用性,不仅能结合当前的神经表达,也适用于传统的渲染管线几何表达,如多边形网格 (Mesh)。我们在关注大型数据和模型的同时,也应该不时地回顾传统的图形学工具。研究人员相信,不久的未来,在 3D AIGC 领域,传统的图形学工具结合高质量的神经表达以及强力的生成模型,将会碰撞出更绚烂的火花,进一步推进三维内容生成的质量和速度,解放人们的创造力。
这一研究得到了广大网友的讨论:
有网友表示:(这项研究)对于游戏开发来说十分棒,只需要建模单个模型就能生成很多新的版本。
对于上述观点,有人表示完全同意,游戏开发者、个人和小公司可以从这类模型中得到帮助。

以上是三维场景生成:无需任何神经网络训练,从单个样例生成多样结果的详细内容。更多信息请关注PHP中文网其他相关文章!





















