

Transformer 是时下最强大的 seq2seq 架构。预训练 transformer 通常具有 512(例如 BERT)或 1024 个(例如 BART)token 的个上下文窗口,这对于目前许多文本摘要数据集(XSum、CNN/DM)来说是足够长的。
但 16384 并不是生成所需上下文长度的上限:涉及长篇叙事的任务,如书籍摘要(Krys-´cinski et al.,2021)或叙事问答(Kociskýet al.,2018),通常输入超过 10 万个 token。维基百科文章生成的挑战集(Liu*et al.,2018)包含超过 50 万个 token 的输入。生成式问答中的开放域任务可以从更大的输入中综合信息,例如回答关于维基百科上所有健在作者的文章的聚合属性的问题。图 1 根据常见的上下文窗口长度绘制了几个流行的摘要和问答数据集的大小;最长的输入比 Longformer 的上下文窗口长 34 倍以上。
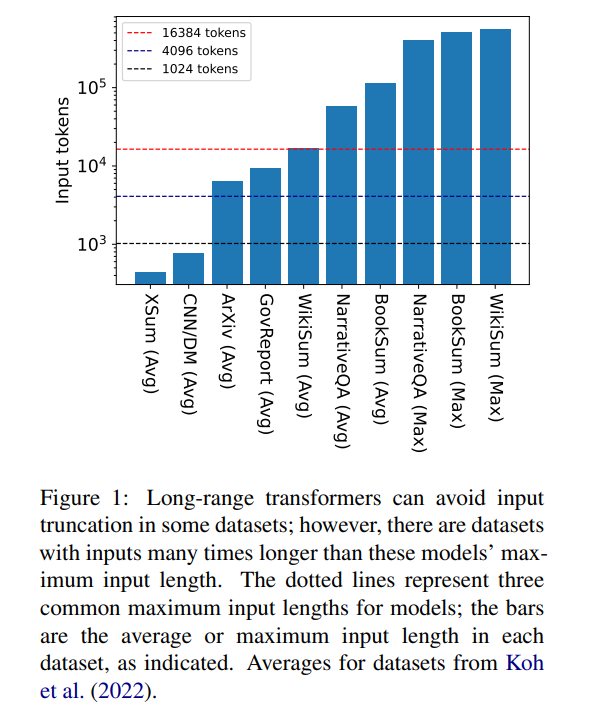
在这些超长输入的情况下,vanilla transformer 无法进行缩放,因为原生注意力机制具有平方级的复杂度。长输入 transformer 虽然比标准 transformer 更高效,但仍需要大量的计算资源,这些资源随着上下文窗口大小的增加而增加。此外,增加上下文窗口需要用新的上下文窗口大小从头开始重新训练模型,计算上和环境上的代价都不小。
在「Unlimiformer: Long-Range Transformers with Unlimited Length Input」一文中,来自卡内基梅隆大学的研究者引入了 Unlimiformer。这是一种基于检索的方法,这种方法增强了预训练的语言模型,以在测试时接受无限长度的输入。

论文链接:https://arxiv.org/pdf/2305.01625v1.pdf
Unlimiformer 可以被注入到任何现有的编码器 - 解码器 transformer 中,能够处理长度不限的输入。给定一个长的输入序列,Unlimiformer 可以在所有输入 token 的隐藏状态上构建一个数据存储。然后,解码器的标准交叉注意力机制能够查询数据存储,并关注前 k 个输入 token。数据存储可以存储在 GPU 或 CPU 内存中,能够次线性查询。
Unlimiformer 可以直接应用于经过训练的模型,并且可以在没有任何进一步训练的情况下改进现有的 checkpoint。Unlimiformer 经过微调后,性能会得到进一步提高。本文证明,Unlimiformer 可以应用于多个基础模型,如 BART(Lewis et al.,2020a)或 PRIMERA(Xiao et al.,2022),且无需添加权重和重新训练。在各种长程 seq2seq 数据集中,Unlimiformer 不仅在这些数据集上比 Longformer(Beltagy et al.,2020b)、SLED(Ivgi et al.,2022)和 Memorizing transformers(Wu et al.,2021)等强长程 Transformer 表现更好,而且本文还发现 Unlimiform 可以应用于 Longformer 编码器模型之上,以进行进一步改进。
由于编码器上下文窗口的大小是固定的,Transformer 的最大输入长度受到限制。然而,在解码过程中,不同的信息可能是相关的;此外,不同的注意力头可能会关注不同类型的信息(Clark et al.,2019)。因此,固定的上下文窗口可能会在注意力不那么关注的 token 上浪费精力。
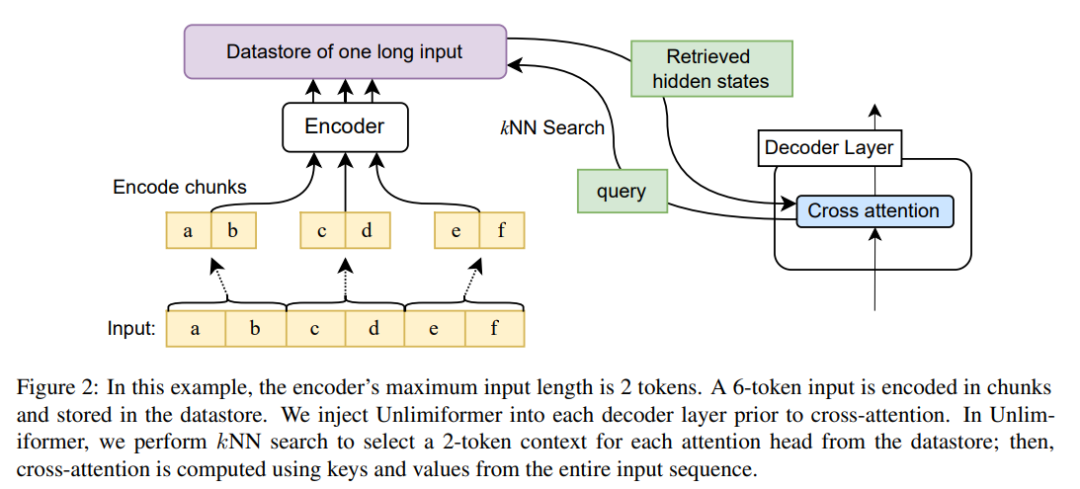
在每个解码步骤中,Unlimiformer 中每个注意力头都会从全部输入中选择一个单独的上下文窗口。通过将 Unlimiformer 查找注入解码器来实现:在进入交叉注意力模块之前,该模型在外部数据存储中执行 k 最近邻 (kNN) 搜索,在每个解码器层中的每个注意力头中选一组 token 来参与。
编码
为了将比模型的上下文窗口长度更长的输入序列进行编码,本文按照 Ivgi et al. (2022) 的方法对输入的重叠块进行编码 (Ivgi et al. ,2022),只保留每个 chunk 的输出的中间一半,以确保编码过程前后都有足够的上下文。最后,本文使用 Faiss (Johnson et al., 2019) 等库对数据存储中的编码输入进行索引(Johnson et al.,2019)。
检索增强的交叉注意力机制
在标准的交叉注意力机制中,transformer 的解码器关注编码器的最终隐状态,编码器通常截断输入,并仅对输入序列中的前 k 个 token 进行编码。
本文不是只关注输入的这前 k 个 token,对于每个交叉注意头,都检索更长的输入系列的前 k 个隐状态,并只关注这前 k 个。这样就能从整个输入序列中检索关键字,而不是截断关键字。在计算和 GPU 内存方面,本文的方法也比处理所有输入 token 更便宜,同时通常还能保留 99% 以上的注意力性能。
图 2 显示了本文对 seq2seq transformer 架构的更改。使用编码器对完整输入进行块编码,并将其存储在数据存储中;然后,解码时查询编码的隐状态数据存储。kNN 搜索是非参数的,并且可以被注入到任何预训练的 seq2seq transformer 中,详情如下。
长文档摘要
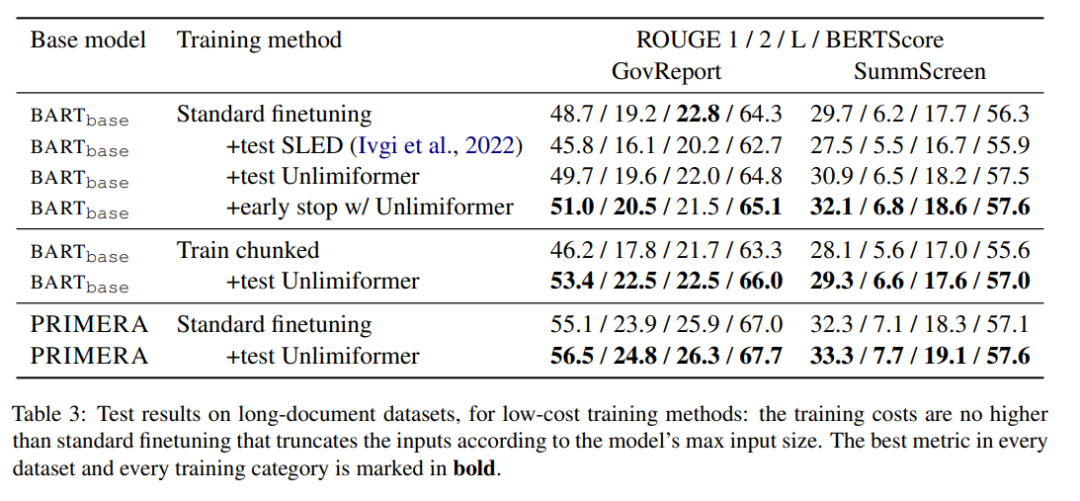
表 3 显示了长文本(4k 及 16k 的 token 输入)摘要数据集中的结果。
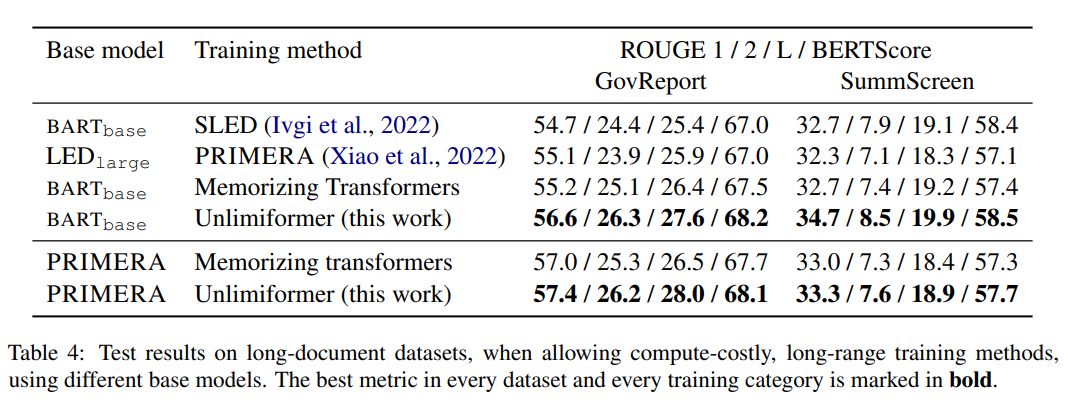
在表 4 的训练方法中,Unlimiformer 能够在各项指标上达到最优。
书籍摘要
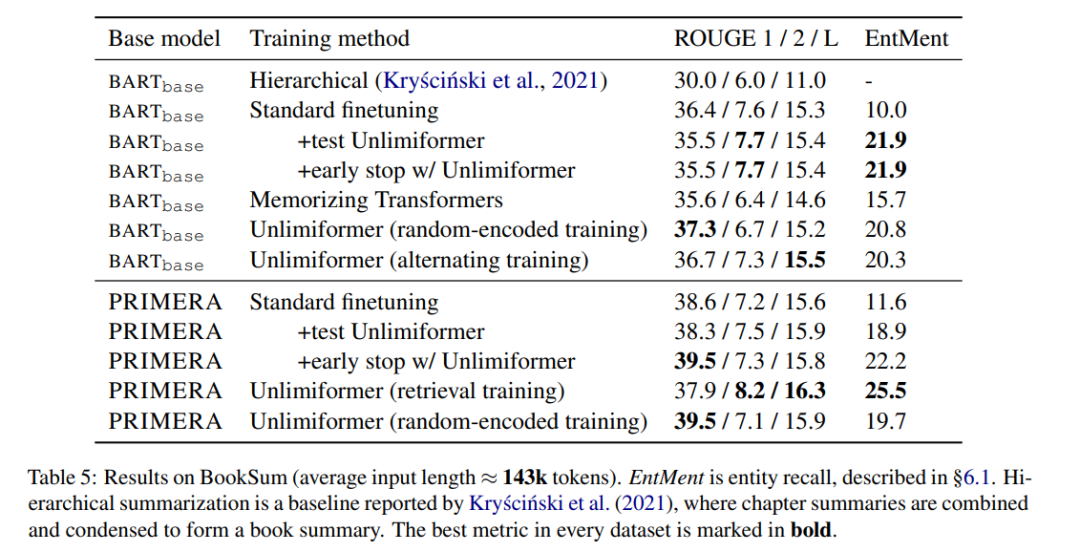
表 5 显示了在书籍摘要上的结果。可以看到,基于 BARTbase 和 PRIMERA,应用 Unlimiformer 都能取得一定的改进效果。
以上是GPT-4的32k输入框还是不够用?Unlimiformer把上下文长度拉到无限长的详细内容。更多信息请关注PHP中文网其他相关文章!





















