


在介绍自动并行之前,我们思考一下为什么需要自动并行?一方面现在有着不同的模型结构,另一方面还有各种各样的并行策略,两者之间一般是多对多的映射关系。假设我们能实现一个统一的模型结构满足各种任务需求,那么我们的并行策略是不是在这种统一的模型结构上实现收敛?
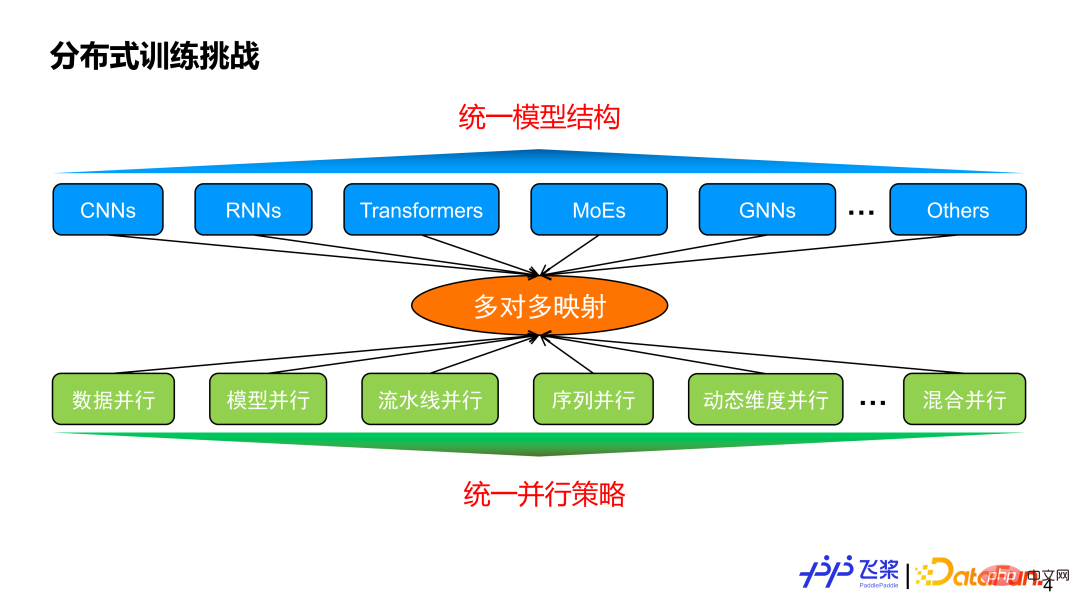
答案是否定的,因为并行策略不仅仅跟模型结构相关,还跟模型的规模以及实际使用的机器资源息息相关。这就体现出自动并行的价值,它的目标是:用户给定一个模型和所使用的机器资源后,能够自动地帮用户选择一个比较好或者最优的并行策略来高效执行。
这里罗列了个人感兴趣的一些工作,不一定完整,想跟大家讨论一下自动并行的现状和历史。大概分了几个维度:第一个维度是自动并行的程度,分为全自动和半自动;第二个维度是并行粒度,分别是针对每个 Layer 来提供并行策略,或者是针对每一个算子或者张量来提供并行策略;第三个是表示能力,这里简化为 SPMD(Single Program Multiple Data)并行和 Pipeline 并行两大类;第四个是特色,这里列出了个人觉得相关工作比较有特色的地方;第五个是支持硬件,主要写出相关工作所支持最大规模的硬件类型和数量。其中,标红部分主要是对飞桨自动并行研发有启发性的点。
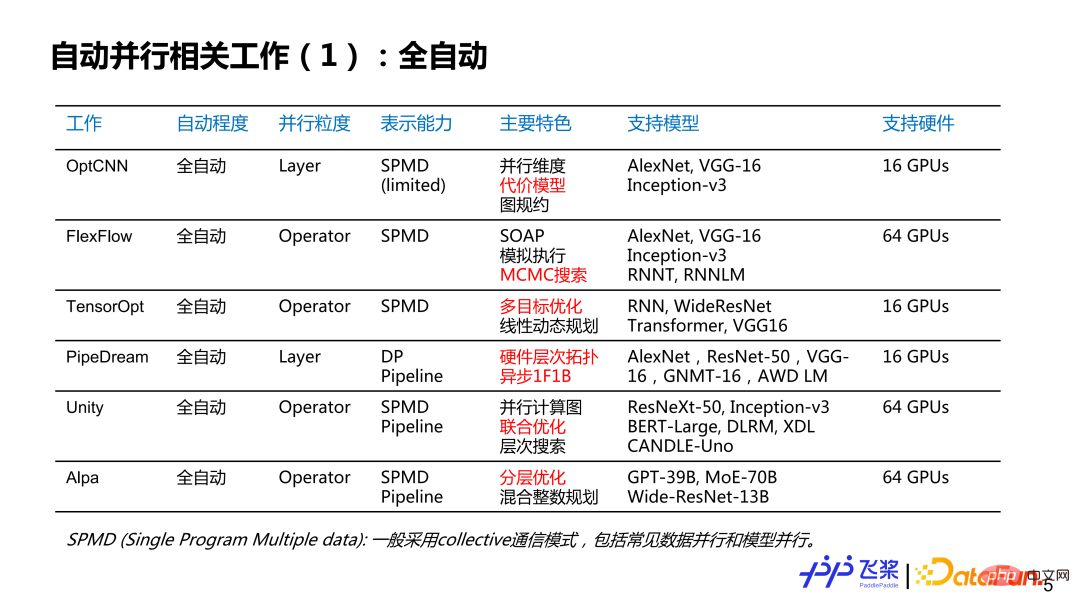
对于全自动并行来说,我们可以看到并行粒度,是由粗粒度到细粒度的发展过程;表示能力是从比较简单的 SPMD 到非常通用的 SPMD 与 Pipeline 的方式;支持的模型是从简单的 CNN 到 RNN 再到比较复杂的 GPT;虽然支持多机多卡,但整体规模不是特别大。
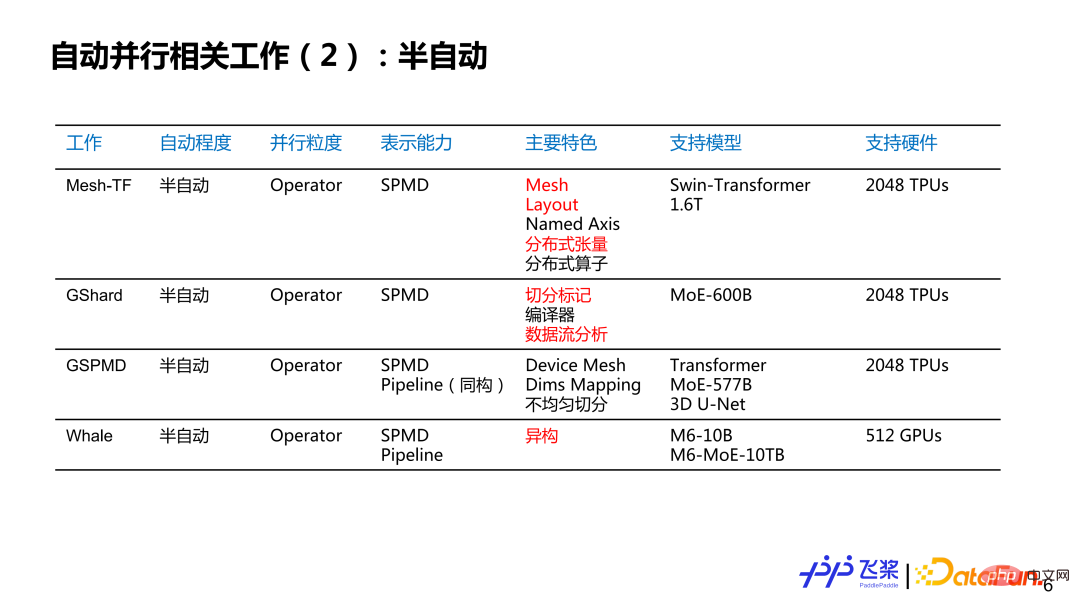
对于半自动并行来说,并行粒度基本上都是以算子为粒度的,而表示能力从简单的 SPMD 到完备的 SPMD 加上 Pipeline 的并行策略,模型支持规模达到千亿和万亿量级,所使用的硬件数量达到千卡量级。
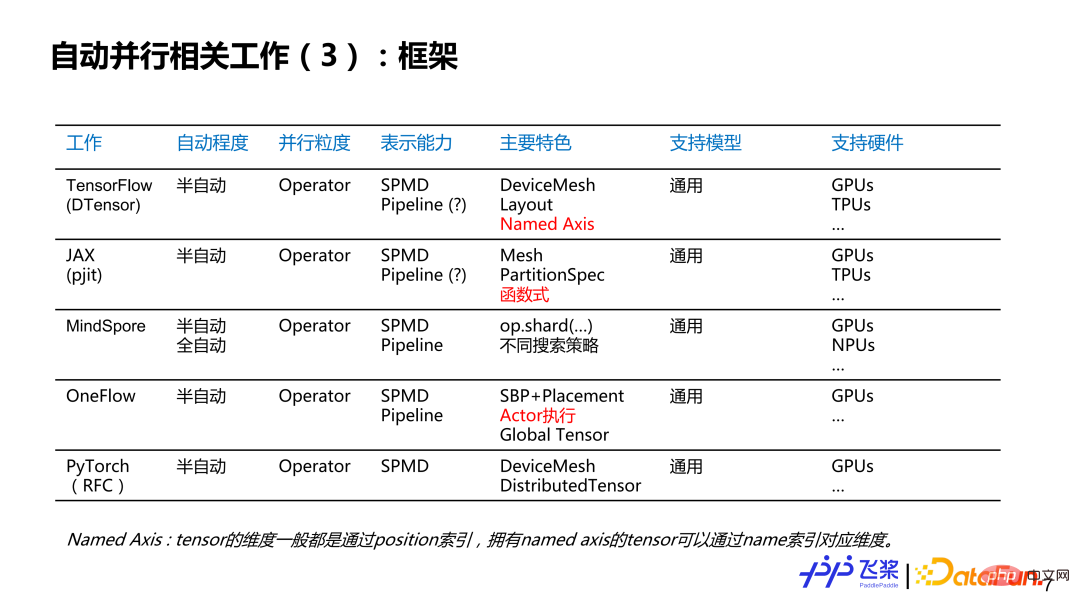
再从框架角度来看,我们可以看到现有的框架基本上已经支持或计划支持半自动这种模式,而并行粒度也发展到算子粒度,表示能力基本上都采用 SPMD 加上 Pipeline 的完备表示,都面向各种各样模型和各种各样硬件。

这里总结一下个人的一些思考:
① 第一点,分布式策略在底层表示上逐渐统一。
② 第二点,半自动会逐渐成为框架的一种分布式编程范式,而全自动会结合特定的场景和经验规则去探索落地。
③ 第三点,实现一个极致端到端性能,需要采用并行策略与优化策略联合调优来实现。
一般完整分布式训练包括 4 个具体的流程。首先是模型切分,无论是手动并行还是自动并行都需要将模型切分为多个可以并行的任务;其次是资源获取,可以通过自己搭建或者从平台申请来准备好我们训练所需要的设备资源;然后是任务放置(或者任务映射),也就是将切分后的任务放置到对应资源上;最后是分布式执行,就是各个设备上的任务并行执行,并通过消息通信来进行同步和交互。
现在一些主流的解决方案存在一些问题:一方面可能只考虑分布式训练中的部分流程,或者只侧重部分流程;第二个就是过于依赖专家的经验规则,比如模型切分和资源分配;最后是在整个训练的过程中,缺乏对任务和资源的感知能力。
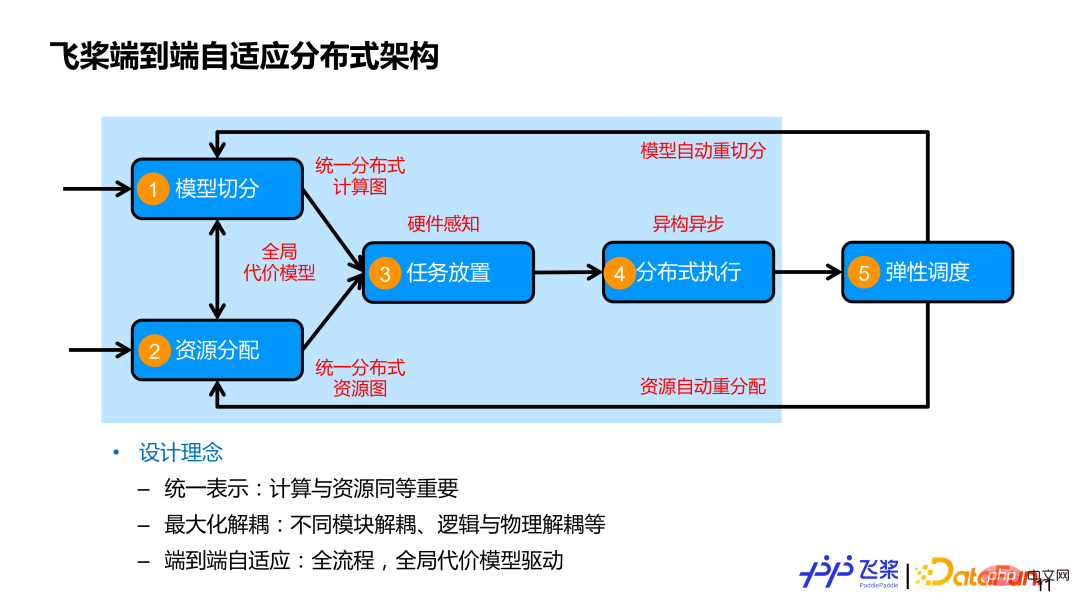
而飞桨所设计的端到端自适应分布式训练架构,在全面考虑 4 个流程基础上,又加入第五个流程,即弹性调度。我们核心设计理念主要包括这 3 点:
第一,计算和资源统一表示,并且计算和资源同等重要。往往大家比较关心怎么切分模型,但是对资源关注度比较少。我们一方面用统一的分布式计算图来表示各种各样的并行策略;另一方面,我们用统一的分布式资源图来建模各种各样的机器资源,既能表示同构的,又能表示异构的资源连接关系,还包括资源本身的计算和存储能力。
第二,最大化解耦,除了模块之间解耦外,我们还将逻辑切分跟物理放置以及分布式执行等进行解耦,这样能够更好地实现不同模型在不同集群资源高效执行。
第三,端到端自适应,涵盖分布式训练所涉及的全面流程,并采用一个全局的代表模型来驱动并行策略或者资源放置的自适应决策,来尽可能代替人工定制化决策。上图浅蓝色框住的部分就是本次报告所介绍的自动并行相关工作。
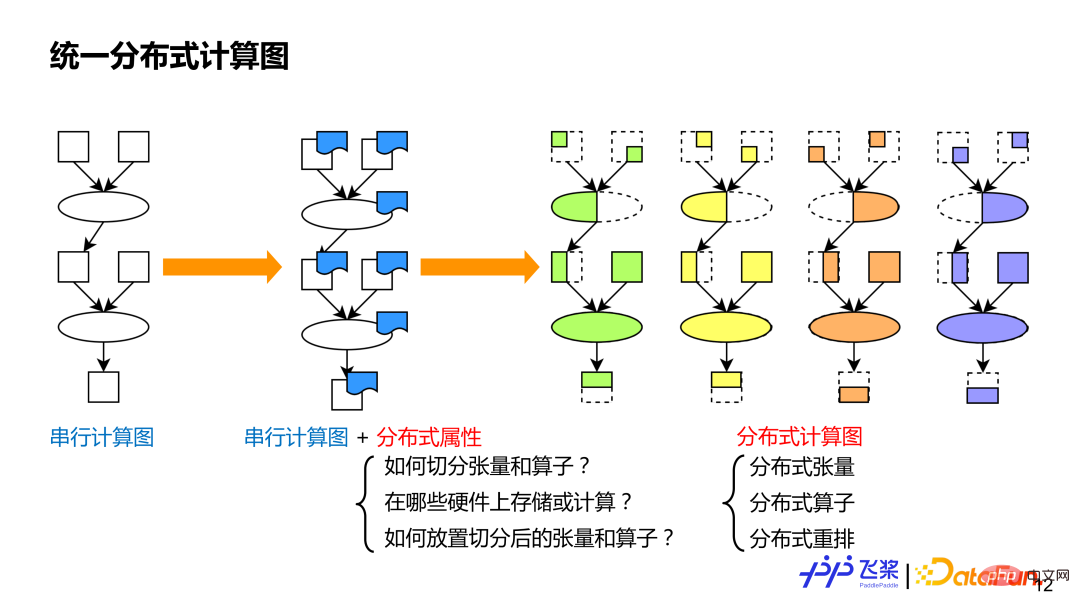
首先是统一的分布式计算图。统一目的是便于我们采用统一方式来表示现有的各种各样的并行策略,这样利于做自动化处理。众所周知,串行计算图能表示各种各样的模型,类似地,我们在串行计算图的基础上,对每个算子和张量加上分布式属性来作为分布式计算图,这种细粒度方式能表示现有并行策略,而且语义会更丰富和通用,还能表示新的并行策略。分布式计算图中的分布式属性主要包括三个方面信息:1)需要表示张量怎么切分或者算子怎么切分;2)需要表示在哪些资源进行分布式计算;3)如何将切分后的张量或算子映射到资源上。对比串行计算图,分布式计算图有 3 个基础组成概念:分布式张量,类似于串行的张量;分布式算子,类似于串行的算子;分布式重排,分布式计算图独有。
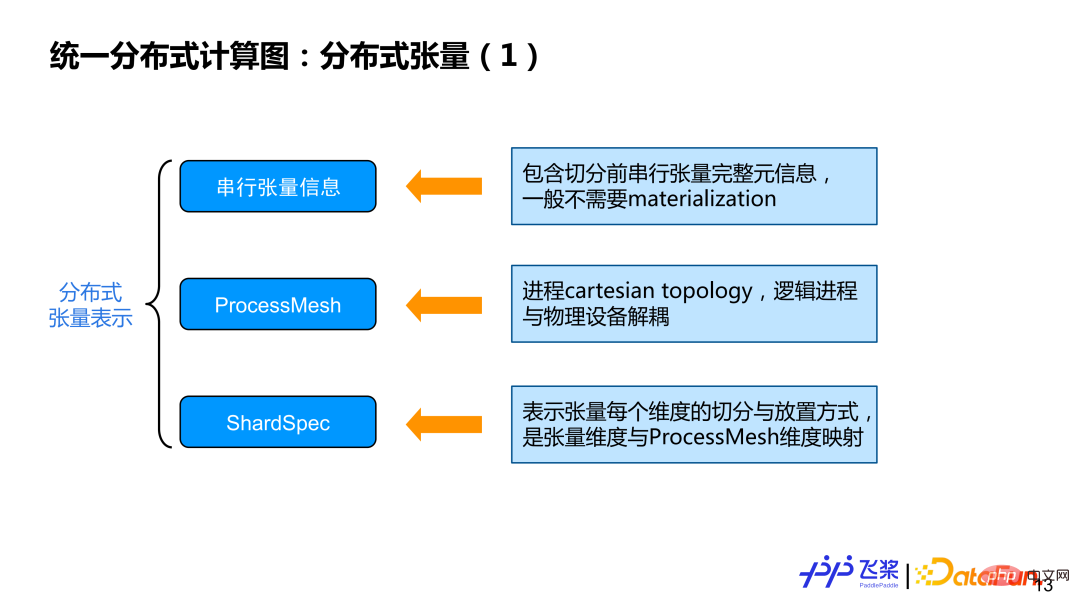
首先,介绍分布式张量所包括的三个方面信息:
① 串行张量信息:主要包含张量 shape、dtype 等一些元信息,一般实际计算不需要对串行张量进行实例化。
② ProcessMesh:进程的 cartesion topology 表示,有别于 DeviceMesh,我们之所以采用 ProcessMesh,主要希望逻辑的进程跟物理设备进行一个解耦,这样便于做更高效任务映射。
③ ShardSpec:用来表示串行张量每个维度用 ProcessMesh 哪个维度进行切分,具体可看下图示例。
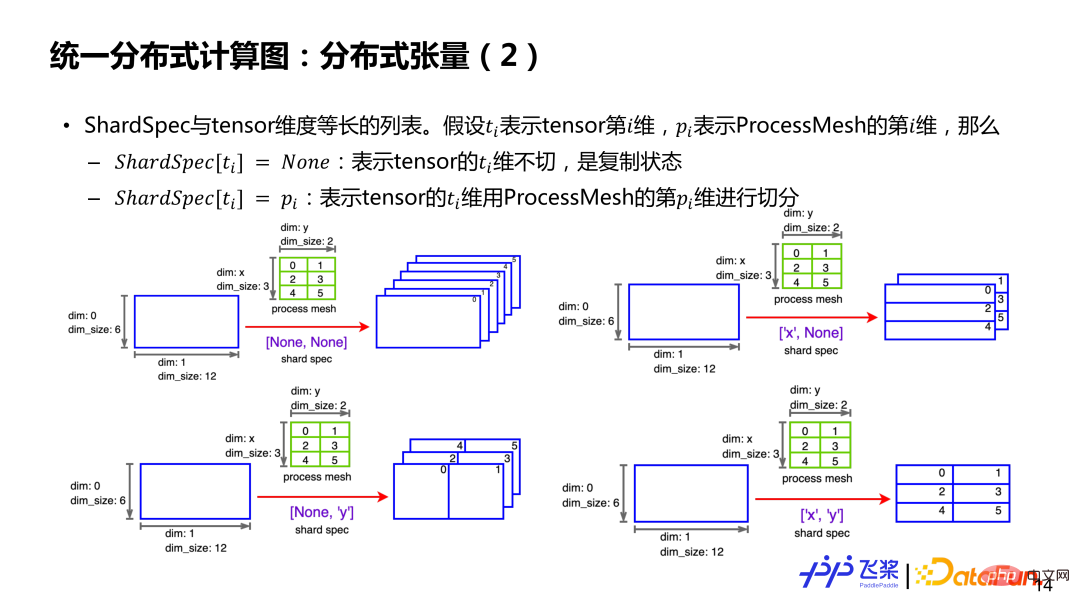
假如有一个二维的 6*12 张量和一个 3*2 的 ProcessMesh(第一维是 x,第二维是 y,元素是进程 ID)。如果 ShardSpec 是 [None,None],就表示张量第 0 维和第 2 维都不切分,每个进程上都有一个全量张量。如果 ShardSpec是 ['x’, ‘y’],表示用 ProcessMesh 的 x 轴去切张量第 0 维,用 ProcessMesh 的 y 轴去切张量第 1 维,这样每个进程都有一个 2*6 大小的 Local 张量。总之,通过 ProcessMesh 和 ShardSpec 以及张量未切分前的串行信息,就能够表示一个张量在相关进程上切分情况。
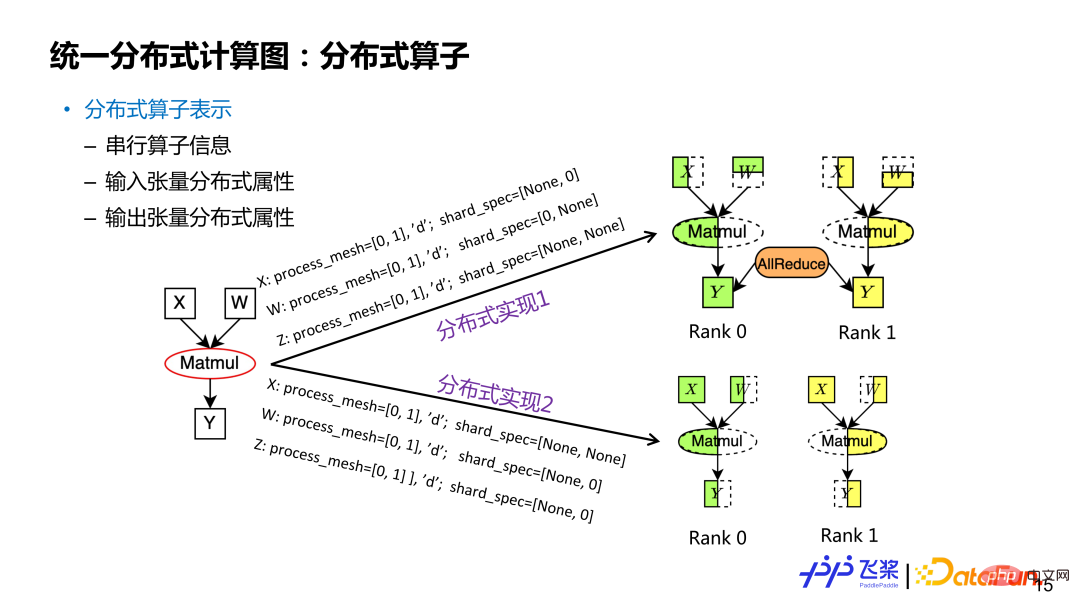
分布式算子表示是基于分布式张量的,包括串行算子信息,输入和输出张量的分布式属性。类似一个分布式张量可能会对应多种切分方式,分布式算子里面的分布式属性不一样,对应着不同切分。以矩形乘 Y=X*W 算子为例,如果输入和输出分布式属性不同,就对应不同的分布式算子实现(分布属性包括 ProcessMesh 和 ShardSpec)。对于分布式算子来说,其输入和输出张量的 ProcessMesh 相同。
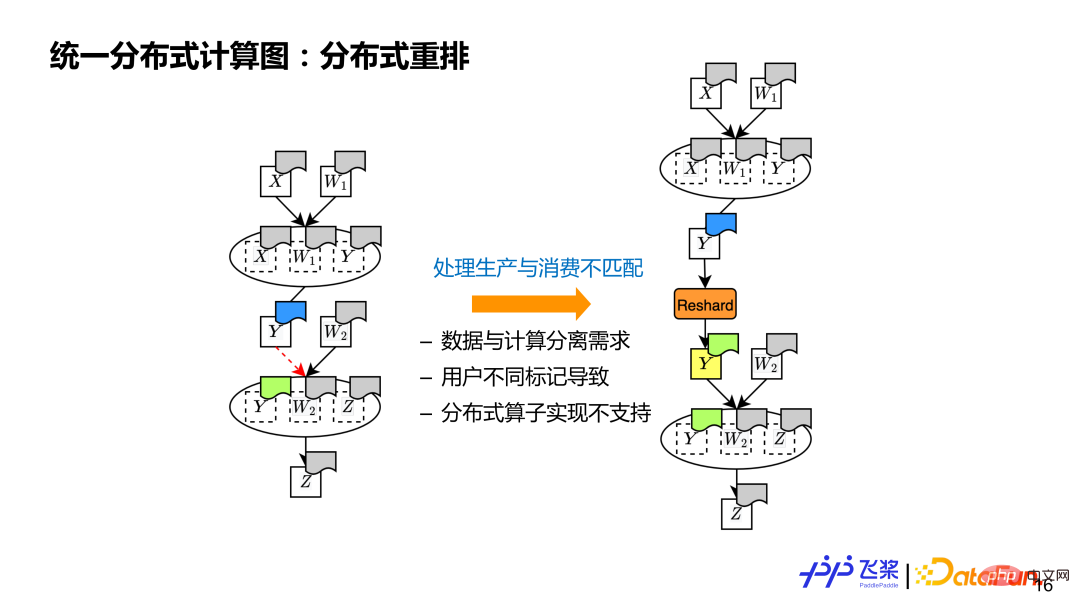
最后一个是分布式重排,这是分布式计算图所必须具有的概念,用来处理源张量和目的张量分布式属性不同的情况。比如有 2 个算子的计算,上一个算子产生 y,跟下一个算子使用 y 分布式属性不同(图中用不同颜色表示),这时我们需要插入额外的一个 Reshard 操作来通过通信进行张量分布式重排,本质就是处理生产和消费不匹配问题。
导致不匹配的原因主要有三个方面:1)支持支持数据和计算分离,所以对张量和使用它的算子有不同的分布式属性;2)支持用户自定义标记分布式属性,用户可能对张量和使用它的算子标记不同的分布式属性;3)分布式算子底层实现有限,如果出现了输入或者输出分布式属性不支持的情况,也需要通过分布式重排。
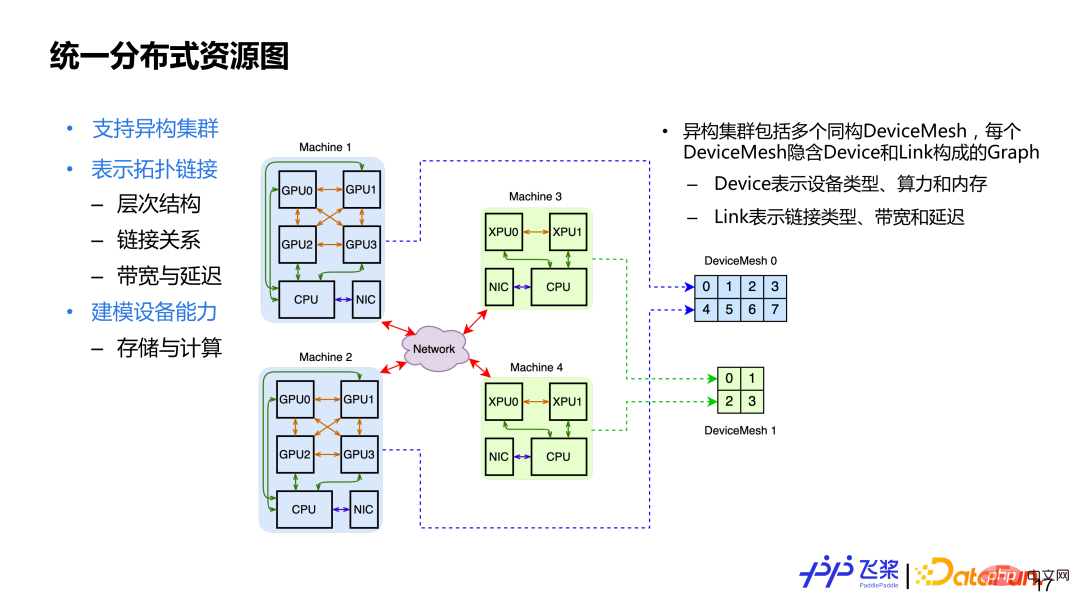
介绍完统一的分布计算图三个基本概念后,再看统一的分布式资源图,主要设计的考量:1)支持异构集群,异构集群就是集群中可能有 CPU、GPU、XPU 资源;2)表示拓扑连接,这里面涵盖了集群的层次结构连接关系,包括对连接能力的量化,比如带宽或者延迟;3)设备本身建模,包括一个设备的存储和计算能力。为了满足上面设计需求,我们用Cluster来表示分布式资源,它包含多个同构 DeviceMesh。每个 DeviceMesh 内会隐含一个由 Device 链接组成的 Graph。
这里举个例子,上图可以看到有 4 台机器,包括 2 个 GPU 机器和 2 个 XPU 机器。对于 2 台 GPU 机器,会用一个同构的 DeviceMesh 表示,而对于 2 台 XPU 机器,会用另一个同构的 DeviceMesh 表示。对于一个固定集群来说,它的 DeviceMesh 是固定不变的,而用户操作的是 ProcessMesh,可以理解是 DeviceMesh 的抽象,用户可以随意 Reshape 和 Slice,最后会统一地将 ProcessMesh 进程映射到 DeviceMesh 设备上。
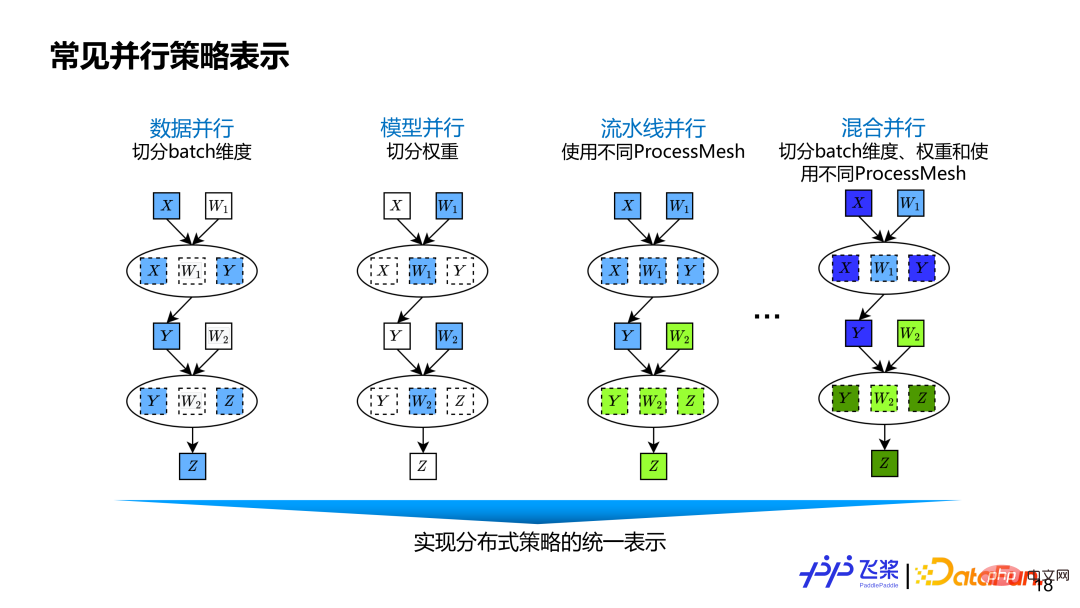
采用前面基于张量和算子细粒度的分布式计算图表示,能涵盖现有并行策略以及未来可能会出现新的并行策略。数据并行就是对数据张量的 Batch 维度进行切分。模型并行对权重相关维度进行切分。流水线并行使用不同 ProcessMesh 来表示,它可以表示为更灵活 Pipeline 并行,比如一个 Pipeline Stage 可以连接多个 Pipeline Stage,而且不同 Stage 使用 ProcessMesh 的 shape 可以不同。其他有些框架的流水线并行是通过 Stage Number 或者 Placement 实现,不够灵活通用。混合并行就是数据并行,张量模型并行和流水线并行三者混合。
前面是飞桨自动并行架构设计和一些抽象概念介绍。基于前面的基础,下面我们通过 2 层 FC 网络例子,来介绍飞桨自动并行内部实现流程。
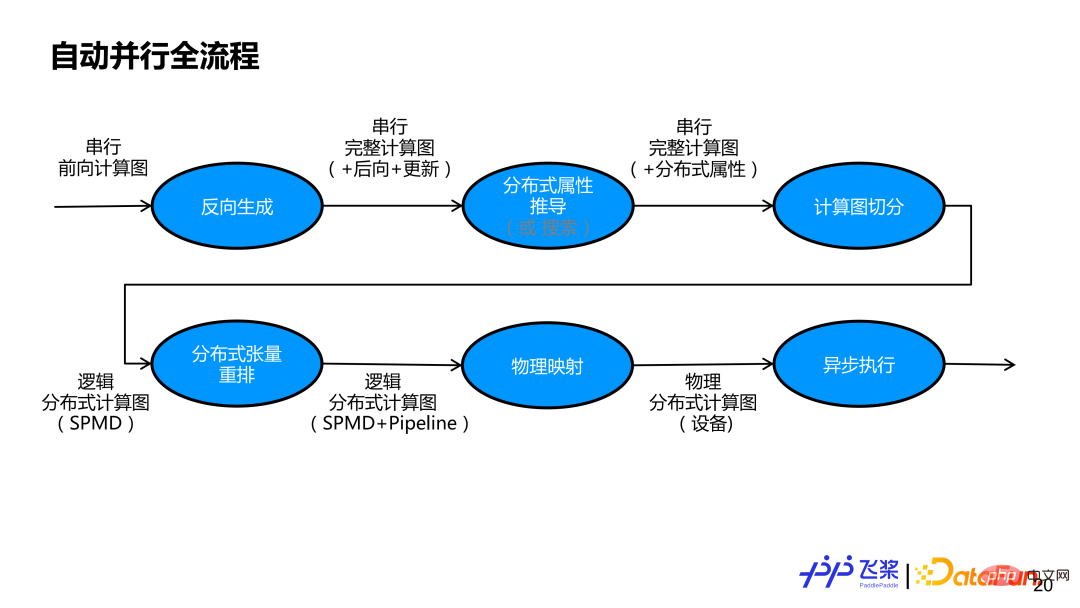
上图是飞桨整个自动并行的流程图。首先我们会基于一个串行前向计算图,进行反向生成,获得包括前向、后向和更新子图的完整计算图。然后,需要明确组网中每个张量和每个算子的分布式属性。既可以采用半自动的推导方式,也可以采用全自动搜索方式。本报告主要讲解半自动推导方式,即基于用户少量标记来推导其他未标记张量和算子的分布式属性。通过分布式属性推导后,串行计算图中每个张量和每个算子都有自己的分布式属性。基于分布式属性,先通过自动切分模块,将串行计算图变成支持 SPMD 并行的逻辑分布式计算图,再通过分布式重排,实现支持 Pipeline 并行的逻辑分布式计算图。生成的逻辑分布式计算图会通过物理映射,变成物理分布式计算图,目前只支持一个进程和一个设备的一一映射。最后,将物理分布式计算图变成一个实际任务依赖图交给异步执行器进行实际执行。
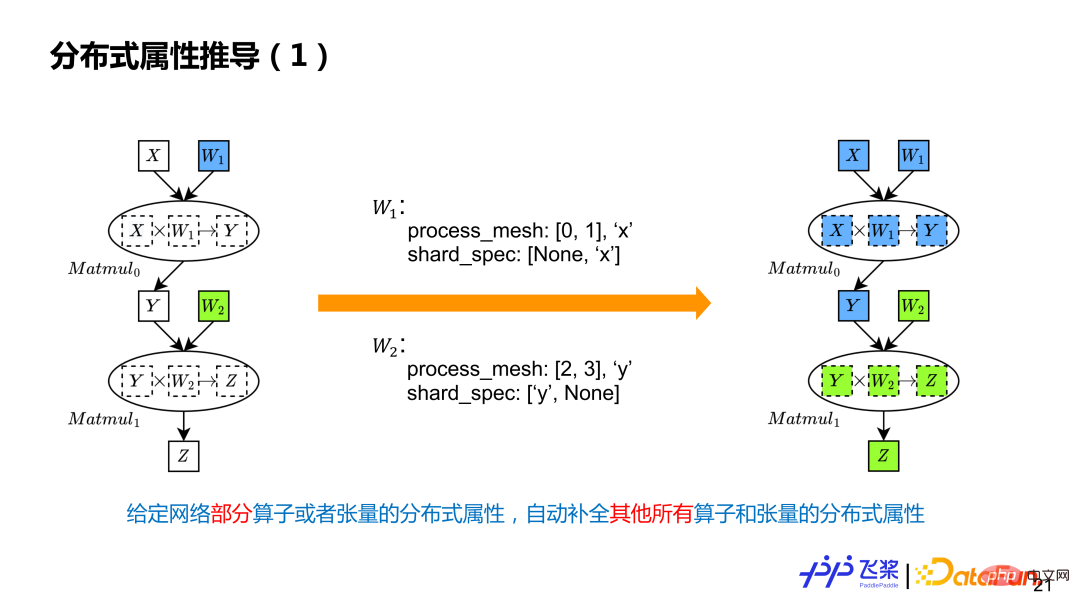
分布式属性推导就是给定计算图中部分张量和算子的分布式属性,自动补全其他所有的张量和算子的分布式属性。例子是两个 Matmul 计算,用户只标记了两个参数分布式属性,表示 W1 在 0,1 进程上进行列切,W2 是在 2,3 进程上进行行切,这里有两个不同 ProcessMesh,用不同的颜色表示。
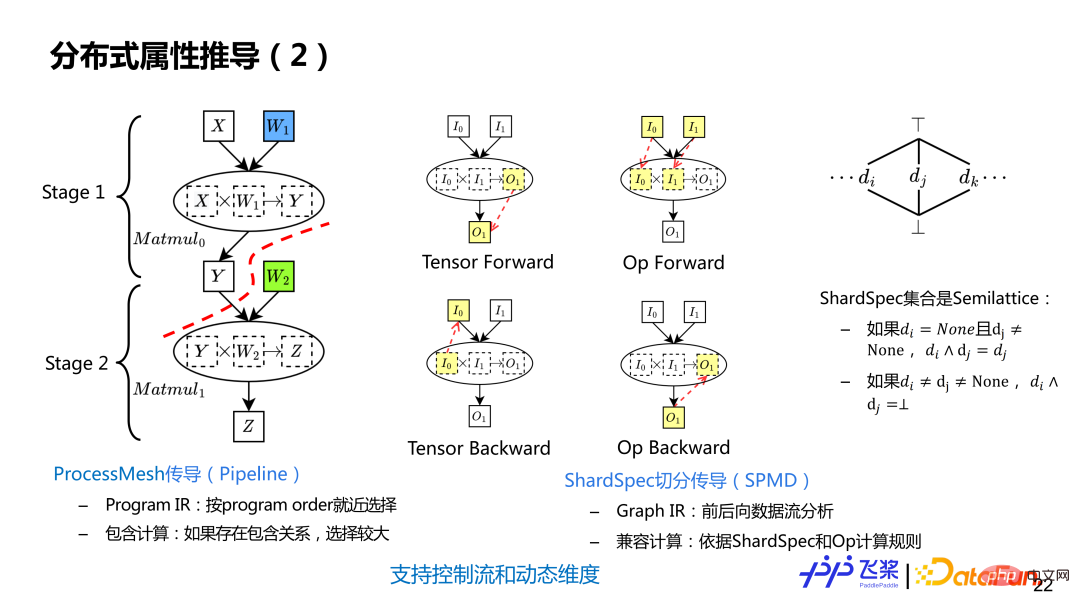
分布式属性推导分为两个步骤:1)先进行 ProcessMesh 传导,实现 Pipeline 切分;2)再进行 ShardSpec 传导,实现一个 Stage 内的 SPMD 切分。ProcessMesh 推导利用了飞桨线性 Program lR, 按静态 Program Order 采用就近选择策略进行推导,支持包含计算,即如果两个 ProcessMesh,一个大一个小,就选较大作为最终 ProcessMesh。而 ShardSpec 推导利用飞桨 SSA Graph IR 进行前向和后向数据流分析进行推导,之所以可以用数据流分析,是因为 ShardSpec 语义,满足数据流分析的 Semilattice 性质。数流分析理论上能保证收敛,通过结合前向和后向分析,能够将计算图任何一个位置标记信息传播到整张计算图,而不是只能单方向传播。
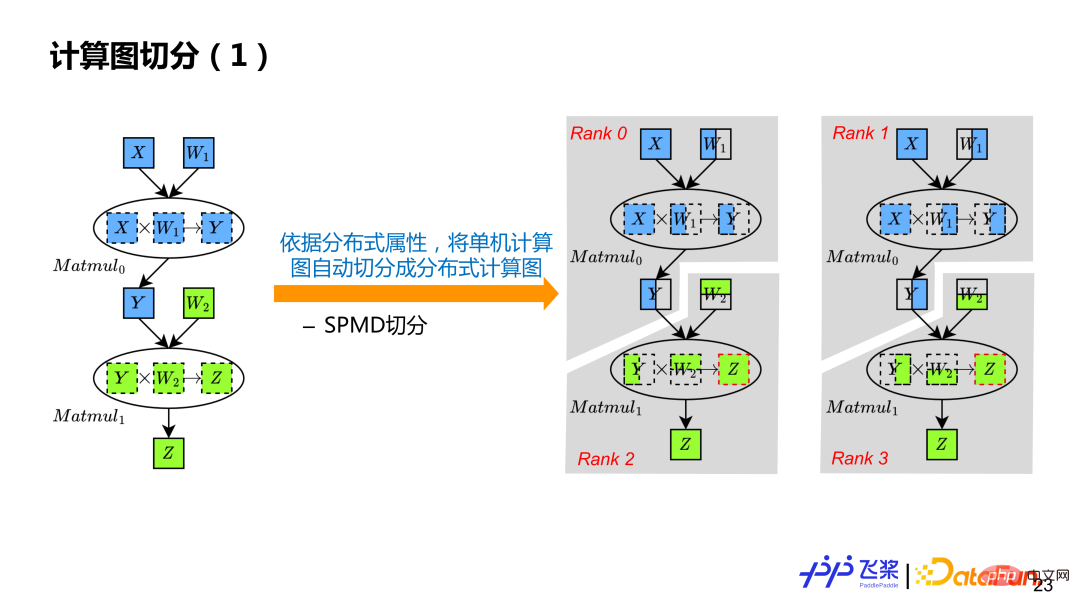
基于分布式属性推导,串行计算图中的每个张量和算子都拥有自己的分布式属性,这样就可以基于分布式属性进行计算图的自动切分。按照例子来说,就是把单机串行计算图,变成 Rank0、Rank1,Rank2、Rank3 四个计算图。
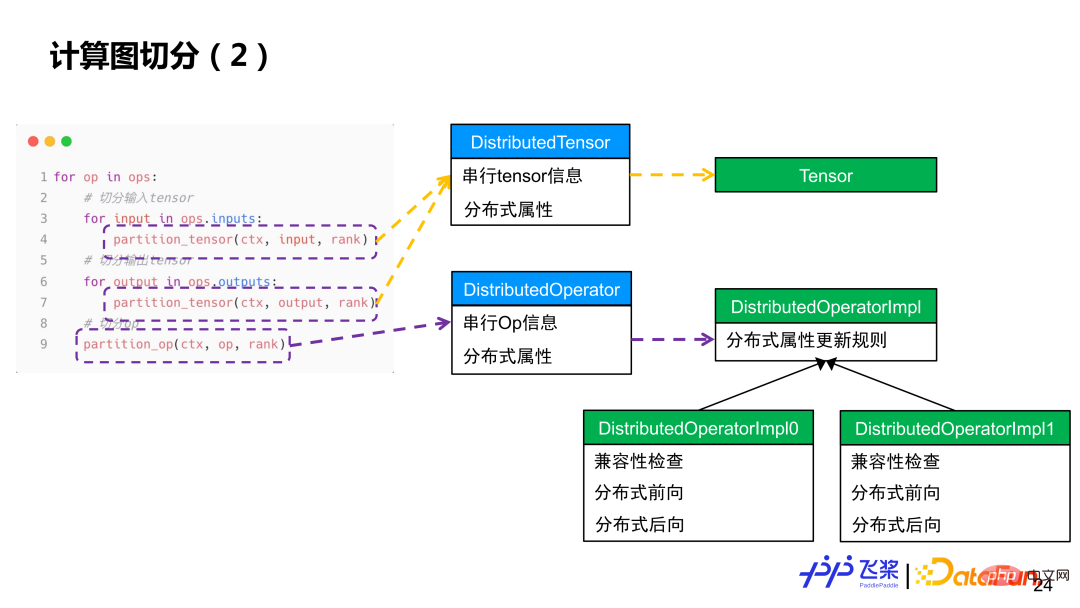
简单来说,会遍历每个算子,先对算子输入和输出进行张量切分,然后再对每个算子进行计算切分。张量切分会通过 Distributed Tensor 对象来构造 Local Tensor 对象,而算子切分会通过 Distributed Operator 对象来基于实际输入和输出的分布属性来选择对应分布式实现,类似于单机框架的算子到 Kernel 的分发过程。
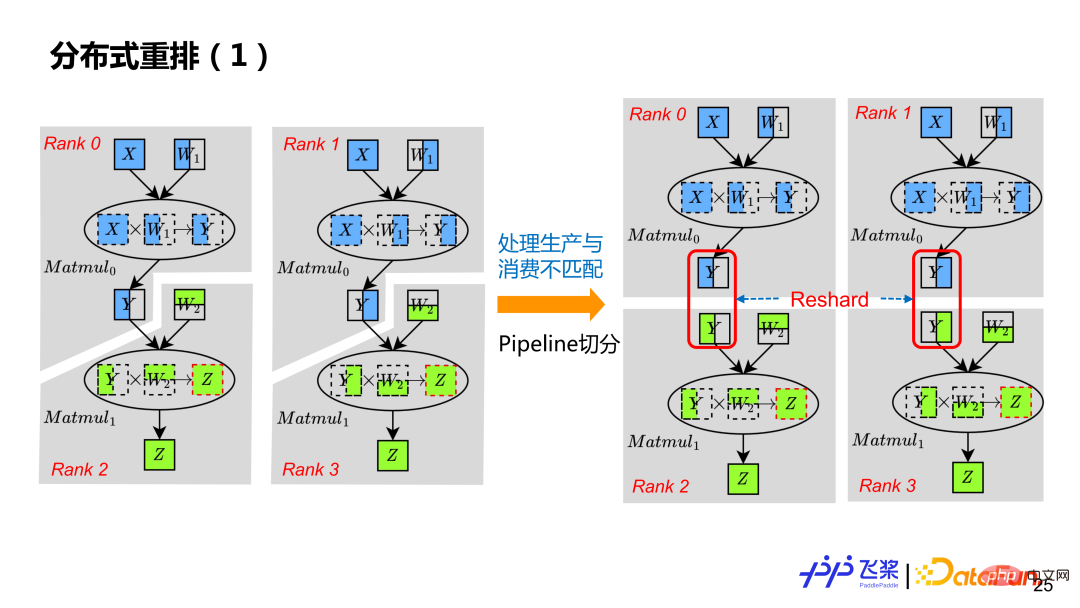
通过前面自动切分,只能获得支持 SPMD 并行的分布式计算图。为了支持 Pipeline 并行,还需要通过分布式重排来处理,这样通过插入一个合适的 Reshard 操作,例子中每个 Rank 拥有自己真正独立计算图。虽然左图 Rank0 的 Y 跟 Rank2 的 Y,切分一样,但是由于他们在不同 ProcessMesh 上,导致了生产消费分布式属性不匹配,所以也需要插入 Reshard。
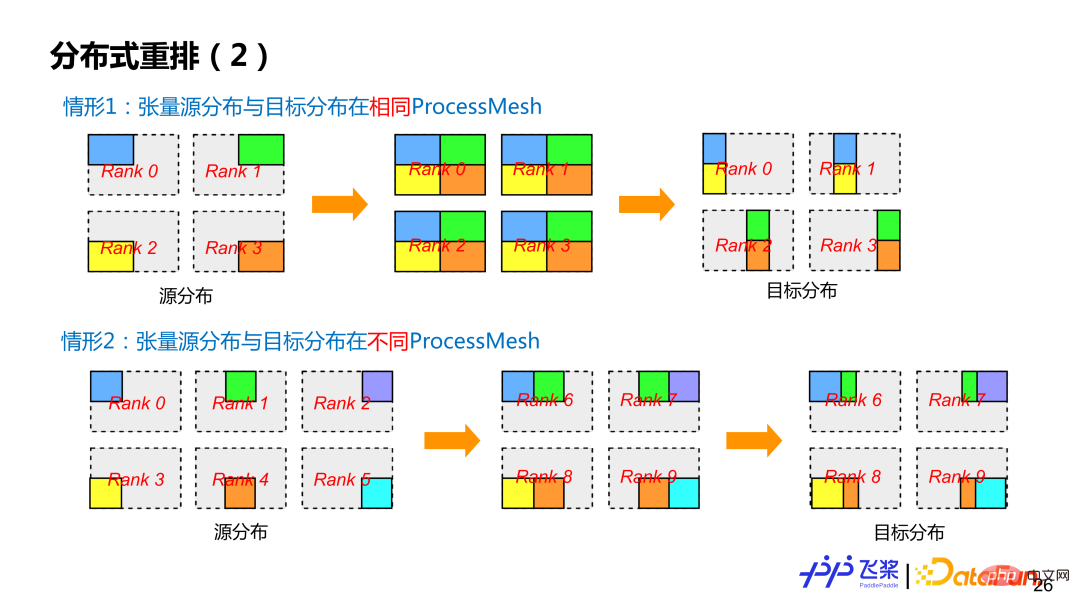
飞桨目前支持两类分布式重排。第一类,是比较常见源张量分布跟目标张量分布都在同一个 ProcessMesh 上,但是源张量分布和目标张量分布所使用切分方式不一样(即 ShardSpec 不一样)。第二类,是源张量分布和目标张量分布在不同的 ProcessMesh 上,而且 ProcessMesh 大小可以不一样,比如图中情形 2 中的 0-5 进程和 6-9 进程。为了尽可能减少通信,飞桨也对 Reshard 操作进行相关优化。
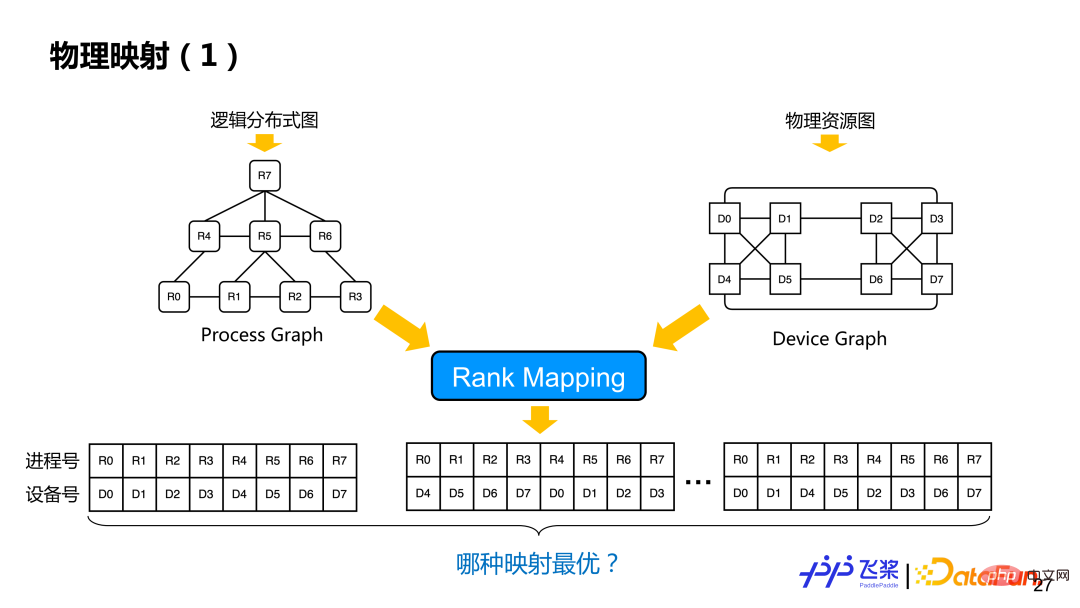
经过分布式重排后,得到一个逻辑上的分布式计算图,这个时候还没有决定进程和具体设备映射。基于逻辑的分布式计算图和前面统一的资源表示图,会进行物理映射操作,也就是 Rank Mapping,就是从多种映射方案(一个进程具体跟哪个设备进行映射)中找到一个最优的映射方案。
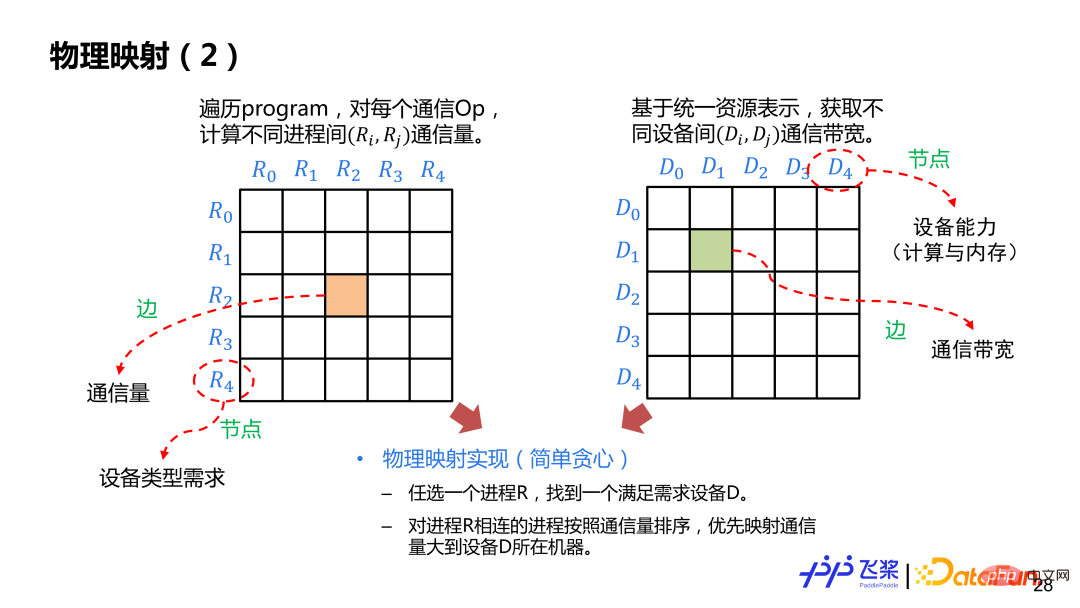
这里介绍一个比较简单基于贪心规则的实现。先构建进程和进程间通信量的邻接表,边表示通信量,节点表示设备需求,再构建设备与设备之间的邻接表,边表示通信带宽,节点表示设备计算和内存。我们会任选一个进程 R 放置到满足需求的设备 D 上,放置后,选择与 R 通信量最大的进程放到 D 所在机器其他设备上,按照这种方式直到完成所有进程映射。在映射过程中,需要判断所选择的设备与进程图所需求的设备类型以及所需要计算量和内存是否匹配。
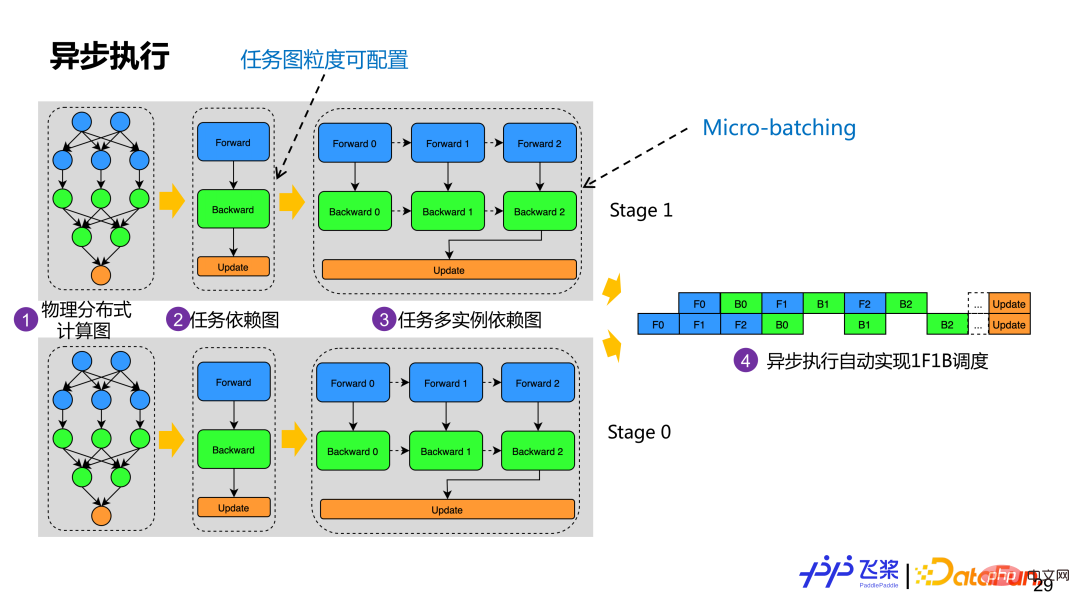
通过物理映射后,我们会根据所获得的物理分布式组网构建实际任务依赖图。图中示例是基于计算图的前向、后向和更新角色来构建任务依赖图,相同角色的算子会组成一个任务。为了支持 Micro-batching 优化,一个任务依赖图会生成多个任务实例依赖图,每个示例虽然计算逻辑一样,但是使用不同内存。目前飞桨会自动地根据计算图角色去构建任务图,但是用户可以根据合适粒度自定义任务构建。每个进程有了任务多实例依赖图后就会基于 Actor 模式进行异步执行,通过消息驱动方式就可以自动地实现 1F1B 执行调度。
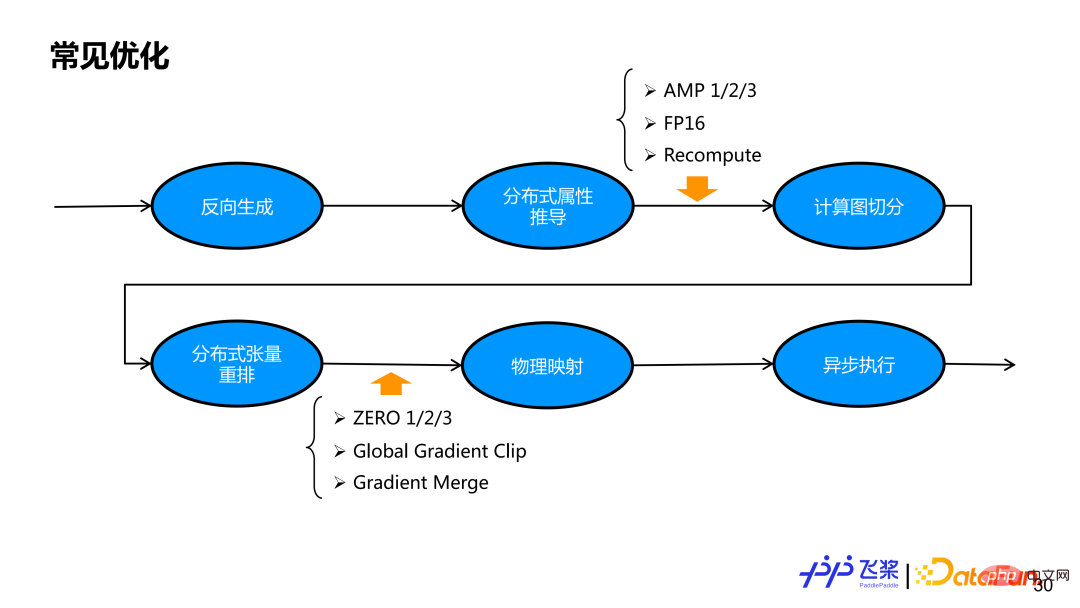
基于上面整个流程,我们已经实现一个功能比较完备的自动并行。但只有并行策略还无法获得一个比较好的端到端性能,所以我们还需要加入相应的优化策略。对飞桨自动并行,我们会在一个自动切分之前和组网切分之后加一些优化策略,这是因为一些优化在串行逻辑上实现比较自然,有一些优化在切分后比较容易实现,通过统一的优化 Pass 管理机制,我们能够保证飞桨自动并行中并行策略与优化策略自由结合。
下面介绍应用实践。
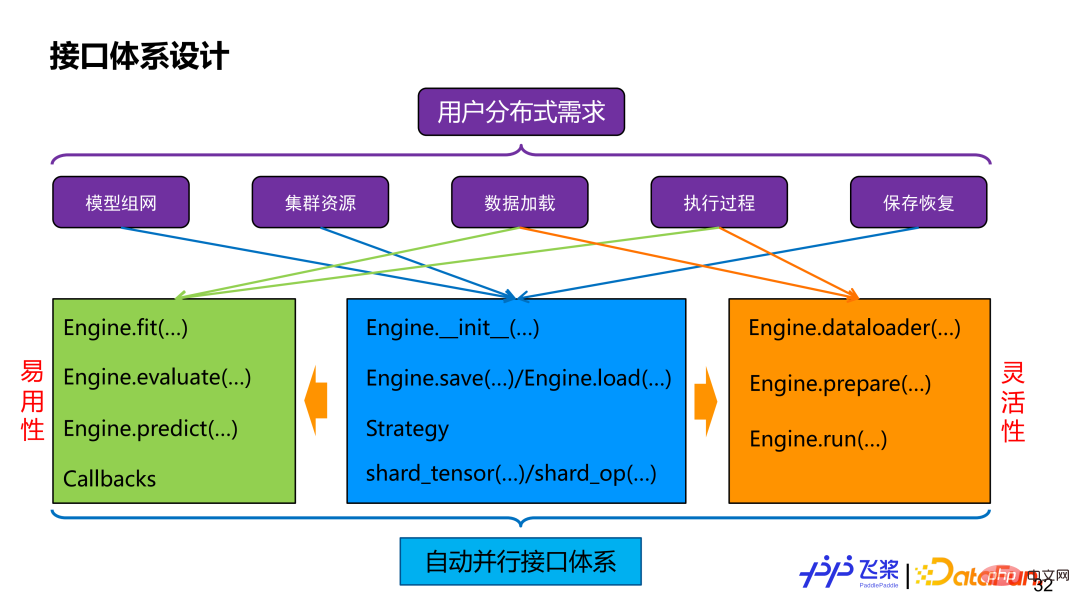
首先是接口,不管如何实现,用户最终还是通过接口来使用我们所提供的自动并行能力。如果对用户分布式需求进行拆解,包括模型组网切分,资源表示,数据分布式加载,分布式执行过程控制和分布式保存和恢复等。为了满足这些需求,我们提供了一个 Engine 类,它同时兼顾易用性和灵活性。易用性方面,它提供了高阶 API,能支持自定义 Callback,分布式过程对用户透明。灵活性方面,它提供了低阶 API,包括分布式 dataloader 构建,自动并行切图和执行等接口,用户可以进行更细粒度控制。两者会共享 shard_tensor、shard_op 以及 save 和 load 等接口。
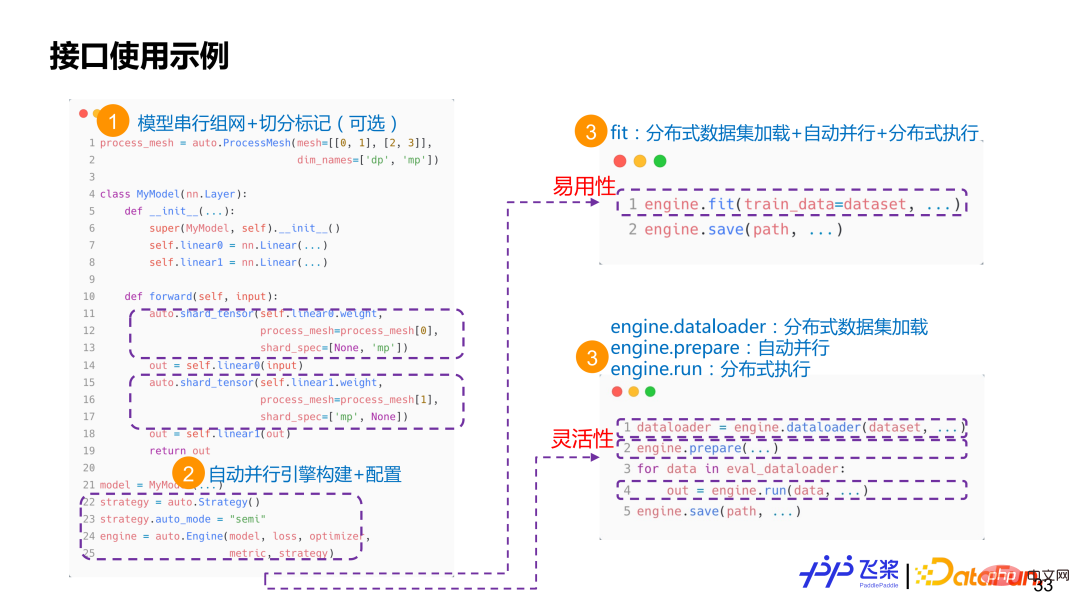
这里有两个标记接口 shard_op 和 shard_tensor。其中,shard_op 既可以标记单个算子,也可以对整个 Module 进行标记,是函数式。上图是一个非常简单的使用示例。首先,使用飞桨已有 API 进行一个串行组网,在其中,我们会使用 shard_tensor 或者 shard_op 进行非侵入式分布式属性标记。然后,构建一个自动并行 Engine,传入模型相关信息和配置。这个时候用户有两个选择,一个选择是直接使用 fit /evaluate/predict 高阶接口,另一种选择是使用 dataloader+prepare+run 接口。如果选择 fit 接口,用户只需要传 Dataset,框架会自动进行分布式数据集加载,自动并行过程编译和分布式训练执行。如果选择 dataloader+prepare+run 接口,用户可以将分布式数据加载、自动并行编译和分布式执行进行解耦,能更好进行单步调试。
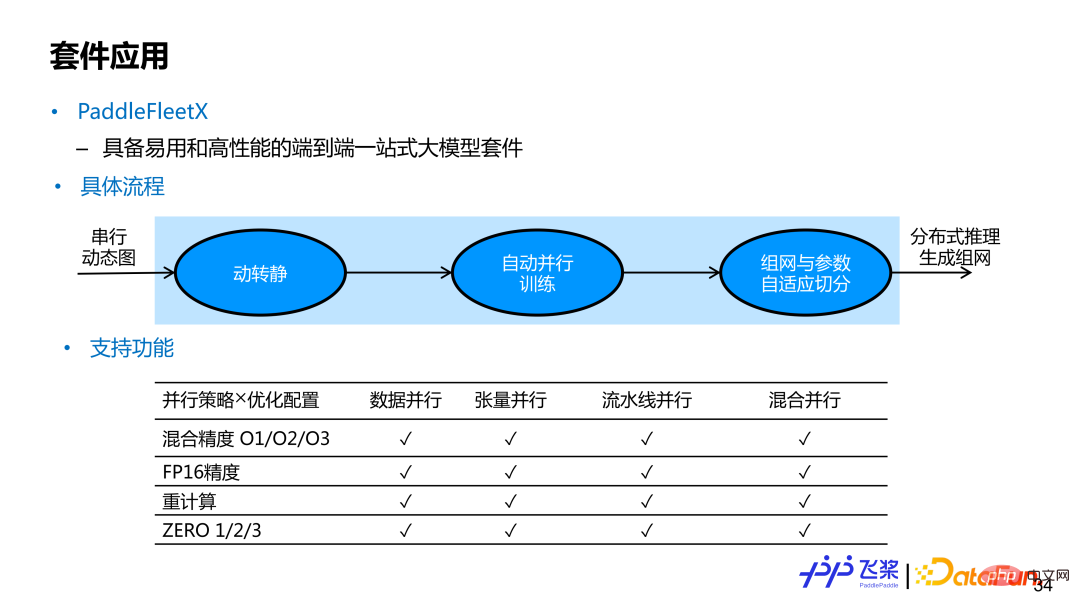
PaddleFleetX 是具备易用性和高性能的一个端到端的一站式大模型套件,支持自动并行功能。用户要想调用飞桨自动并行端到端功能,只需要提供串行动态图模型组网即可。在获得用户动态图串行组网后,内部实现会利用飞桨动转静模块,将动态图单卡组网变成静态图单卡组网,然后通过自动并行编译,最后再进行分布式训练。在推理生成时候,使用的机器资源可能与训练时使用的资源不太一样,内部实现还会进行参数和组网的自适应参数切分。目前 PaddleFleetX 中的自动并行涵盖了大家常用的并行策略和优化策略,并支持两者任意组合,而且对生成任务来说,还支持 While 控制流的自动切分。

飞桨自动并行还有很多工作在开展中,目前的特色可以总结为以下几方面:
首先,统一的分布式计算图,能够支持完备的 SPMD 和 Pipeline 的分布式策略,能够支持存储和计算的分离式表示;
第二,统一的分布式资源图,能够支持异构资源的建模和表示;
第三,支持并行策略和优化策略的有机结合;
第四,提供了比较完备的接口体系;
最后,作为关键组成,支撑飞桨端到端的自适应分布式架构。
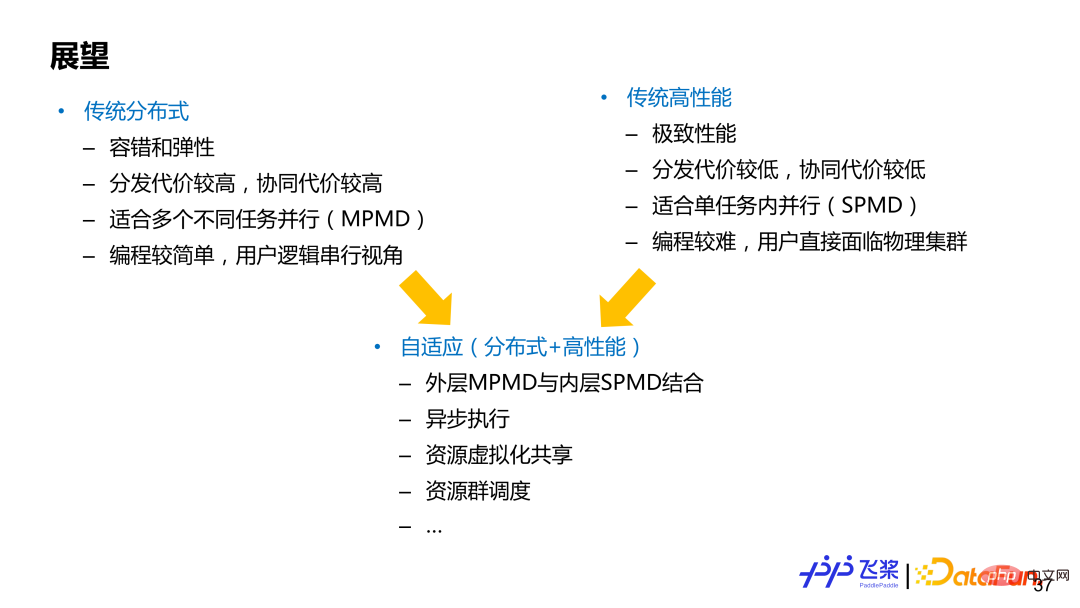
并行一般可以分为两个领域(没有明确分界),一个是传统的分布式计算,一个是传统高性能计算,两者各有优劣。基于传统分布式计算的框架代表是 TensorFlow,它侧重 MPMD(Multiple Program-Multiple Data)并行模式,能够很好支持弹性和容错,分布式计算的用户体验会好一些,编程较简单,用户一般是以一个串行全局视角进行编程;基于传统高性能的计算的框架代表是 PyTorch,更侧重 SPMD(Single Program-Multiple Data)模式,追求极致性能,用户需要直接面临物理集群进行编程,自己负责切分模型和插入合适通信,对用户要求较高。而自动并行或者自适应分布式计算,可以看作两者结合。当然不同架构设计侧重点不一样,需要根据实际需求进行权衡,我们希望飞桨自适应架构能够兼顾两个领域的优势。
以上是飞桨面向异构场景下的自动并行设计与实践的详细内容。更多信息请关注PHP中文网其他相关文章!





















