

众所周知,在 ChatGPT 的问题上 OpenAI 并不 Open,从 Meta 那里开源的羊驼系列模型也因为数据集等问题「仅限于学术研究类应用」,在人们还在因为寻找绕过限制方法的时候,主打 100% 开源的大模型来了。
4 月 12 日,Databricks 发布了 Dolly 2.0,这是两周前发布的类 ChatGPT 人类交互性(指令遵循)大语言模型(LLM)的又一个新版本。
Databricks 表示,Dolly 2.0 是业内第一个开源、遵循指令的 LLM,它在透明且免费提供的数据集上进行了微调,该数据集也是开源的,可用于商业目的。这意味着 Dolly 2.0 可用于构建商业应用程序,无需支付 API 访问费用或与第三方共享数据。

根据 Databricks 首席执行官 Ali Ghodsi 的说法,虽然已有其他大模型可以用于商业目的,但「它们不会像 Dolly 2.0 那样与你交谈。」而且基于 Dolly 2.0 模型,用户可以修改和改进训练数据,因为它是在开源许可下免费提供的。所以你可以制作你自己的 Dolly 版本。
Databricks 还发布了 Dolly 2.0 在其上进行微调的数据集,称为 databricks-dolly-15k。这是由数千名 Databricks 员工生成的超过 1.5 万条记录的语料库,Databricks 称这是「第一个开源的、人工生成的指令语料库,专门设计用于让大型语言能够展示出 ChatGPT 的神奇交互性。」
在过去的两个月里,业界、学界纷纷追赶 OpenAI 提出了一波遵循指令的类 ChatGPT 大模型,这些版本被许多定义视为开源(或提供某种程度的开放性或有限访问)。其中 Meta 的 LLaMA 最受人关注,它引发了大量进一步改进的模型,如 Alpaca、Koala、Vicuna 以及 Databricks 的 Dolly 1.0。
但另一方面,许多这些「开放」模型都处于「工业限制」之下,因为它们接受了旨在限制商业用途的条款的数据集的训练 —— 例如来自 StanfordAlpaca 项目的 5.2 万个问答数据集,是根据 OpenAI 的 ChatGPT 的输出进行训练的。而 OpenAI 的使用条款包括一条规则,即你不能使用 OpenAI 的服务反过来与其竞争。
Databricks 思考了解决这个问题的方法:新提出的 Dolly 2.0 是一个 120 亿参数的语言模型,它基于开源 EleutherAI pythia 模型系列,专门针对小型开源指令记录语料库进行了微调(databricks-dolly-15k),该数据集由 Databricks 员工生成,许可条款允许出于任何目的使用、修改和扩展,包括学术或商业应用。
到目前为止,在 ChatGPT 的输出上训练的模型一直处于合法的灰色地带。「整个社区一直在小心翼翼地解决这个问题,每个人都在发布这些模型,但没有一个可以用于商业用途,」Ghodsi 表示。「这就是我们非常兴奋的原因。」
「其他人都想做得更大,但我们实际上对更小的东西感兴趣,」Ghodsi 在谈到 Dolly 的微缩规模时说。「其次,我们翻阅了所有的答案,它是高质量的。」
Ghodsi 表示,他相信 Dolly 2.0 将启动「雪球」效应,让人工智能领域的其他人加入并提出其他替代方案。他解释说,对商业用途的限制是一个需要克服的大障碍:「我们现在很兴奋,因为我们终于找到了一个绕过它的方法。我保证你会看到人们将这 15000 个问题应用于现有的每一个模型,他们会看到这些模型中有多少突然变得有点神奇,你可以与它们互动。」
要下载 Dolly 2.0 模型的权重,只需访问 Databricks Hugging Face 页面,并访问 databricks-labs 的 Dolly repo,下载 databricks-dolly-15k 数据集。
「databricks-dolly-15k」数据集包含 15000 个高质量的人类生成的 prompt / 回复对,由 5000 多名 Databricks 员工在 2023 年 3 月和 4 月期间撰写,专门设计用于指令调优大型语言模型。这些训练记录自然、富有表现力,旨在代表广泛的行为,从头脑风暴、内容生成到信息提取和总结。
根据该数据集的许可条款(Creative Commons Attribution-ShareAlike 3.0 Unported License),任何人都可因任何目的使用、修改或扩展这个数据集,包括商业应用。
目前,这一数据集是首个开源的、由人类生成的指令数据集。
为什么要创建这样一个数据集?团队也在博客中解释了原因。
创建 Dolly 1.0 或任何遵循 LLM 的指令的一个关键步骤是,在指令和回复对的数据集上训练模型。Dolly 1.0 的训练费用为 30 美元,使用的是斯坦福大学 Alpaca 团队用 OpenAI API 创建的数据集。
在 Dolly 1.0 发布之后,就有很多人要求试用,此外还有一部分用户希望在商业上使用这个模型。
但是训练数据集包含 ChatGPT 的输出,正如斯坦福大学团队所指出的,服务条款试图阻止任何人创建一个与 OpenAI 竞争的模型。
此前,所有的知名指令遵循模型(Alpaca、Koala、GPT4All、Vicuna)都受到这种限制:禁止商业使用。为了解决这个难题,Dolly 团队开始寻找方法来创建一个没有商业用途限制的新数据集。
具体而言,团队从 OpenAI 公布的研究论文中得知,最初的 InstructGPT 模型是在一个由 13000 个指令遵循行为演示组成的数据集上训练出来的。受此启发,他们开始研究是否可以在 Databricks 员工的带领下取得类似的结果。
结果发现,生成 13000 个问题和答案比想象中更难。因为每个答案都必须是原创的,不能从 ChatGPT 或网络上的任何地方复制,否则会「污染」数据集。但 Databricks 有超过 5000 名员工,他们对 LLM 非常感兴趣。因此,团队进行了一次众包实验,创造出了比 40 位标注者为 OpenAI 创造的更高质量的数据集。
当然,这项工作耗时耗力,为了激励大家,团队设立置一个竞赛,前 20 名的标注者将获得惊喜大奖。同时,他们也列出了 7 项非常具体的任务:
以下是一些示例:


最开始,团队对于是否能达到 10000 个结果持怀疑态度。但通过每晚的排行榜游戏,一周内就成功地突破了 15000 个结果。
随后,出于对「占用员工生产力」的担心,团队关闭了比赛(这很合理)。
在数据集火速创建完成之后,团队开始考虑商业应用的问题了。
他们想制作一个可在商业上使用的开源模型。尽管 databricks-dolly-15k 比 Alpaca(训练 Dolly 1.0 的数据集)小得多,但基于 EleutherAI pythia-12b 的 Dolly 2.0 模型却表现出高质量的指令遵循行为。
事后看来,这并不令人惊讶。毕竟最近几个月发布的许多指令调优数据集包含合成数据,这些数据往往包含幻觉和事实错误。
另一方面,databricks-dolly-15k 是由专业人士生成的,质量很高,而且包含大多数任务的长篇答案。
以下是 Dolly 2.0 用于总结和内容生成的一些例子:

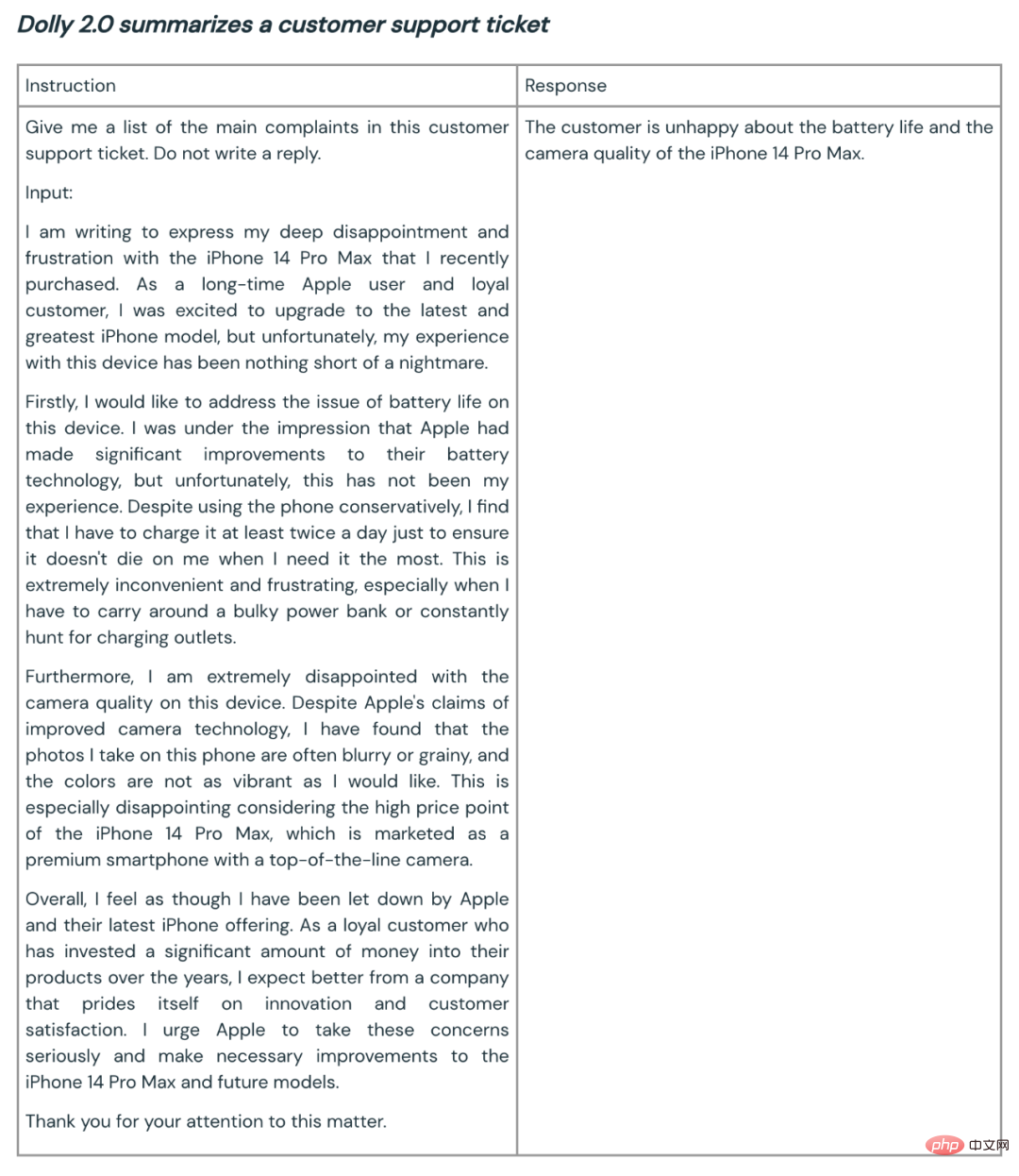

Dolly 团队表示,根据最初的客户反馈,像这样的能力可在整个企业中进行广泛的应用。因为很多企业希望拥有自己的模型,以此为自己的特定领域应用创建更高质量的模型,而不是将自己的敏感数据交给第三方。
Dolly 2 的开源为构建更好的大模型生态开了一个好头。开放源代码的数据集和模型鼓励评论、研究和创新,有助于确保每个人都从人工智能技术的进步中受益。Dolly 团队期望新模型和开源数据集将作为众多后续工作的种子,帮助引导出更强大的语言模型。
以上是世界首款真开源类ChatGPT大模型Dolly 2.0,可随意修改商用的详细内容。更多信息请关注PHP中文网其他相关文章!





















