


为什么AI聊天机器人会胡编乱造,我们能完全信任它们的输出吗?为此,我们询问了几位专家,并深入研究了这些AI模型是如何工运行的,以找到答案。
AI聊天机器人(如OpenAI的ChatGPT)依赖于一种称为“大型语言模型”(LLM)的人工智能来生成它们的响应。LLM是一种计算机程序,经过数百万文本源的训练,可以阅读并生成“自然语言”文本语言,就像人类自然地写作或交谈一样。不幸的是,它们也会犯错。
在学术文献中,AI研究人员经常称这些错误为“幻觉”(hallucinations)。随着这个话题成为主流,这个标签也变得越来越具争议,因为一些人认为它将人工智能模型拟人化(暗示它们具有类人的特征),或者在不应该暗示这一点的情况下赋予它们权力(暗示它们可以做出自己的选择)。此外,商业LLM的创造者也可能以幻觉为借口,将错误的输出归咎于AI模型,而不是对输出本身负责。
尽管如此,生成式AI还是一个很新的领域,我们需要从现有的想法中借用隐喻,向更广泛的公众解释这些高度技术性的概念。在这种情况下,我们觉得“虚构”(confabulation)这个词虽然同样不完美,但比“幻觉”这个比喻要好。在人类心理学中,“虚构”指的是某人的记忆中存在一个空白,大脑以一段令人信服的虚构事实来填补他所遗忘的那段经历,而非有意欺骗他人。ChatGPT不像人脑那样运行,但是术语“虚构”可以说是一个更好的隐喻,因为它是以创造性地填补空白的原则(而非有意欺骗)在工作,这一点我们将在下面探讨。
当AI机器人产生虚假信息时,这是一个大问题,这些信息可能会产生误导或诽谤效果。最近,《华盛顿邮报》报道了一名法学教授发现ChatGPT将他列入了性骚扰他人的法律学者名单。但此事是子虚乌有,完全是ChatGPT编造的。同一天,Ars也报道了一名澳大利亚市长发现ChatGPT声称他被判受贿并被捕入狱,而该信息也完全是捏造的。
ChatGPT推出后不久,人们就开始鼓吹搜索引擎的终结。然而,与此同时,ChatGPT的许多虚构案例开始在社交媒体上广为流传。AI机器人发明了不存在的书籍和研究,教授没有写过的出版物,虚假的学术论文,虚假的法律引用,不存在的Linux系统功能,不真实的零售吉祥物,以及没有意义的技术细节。
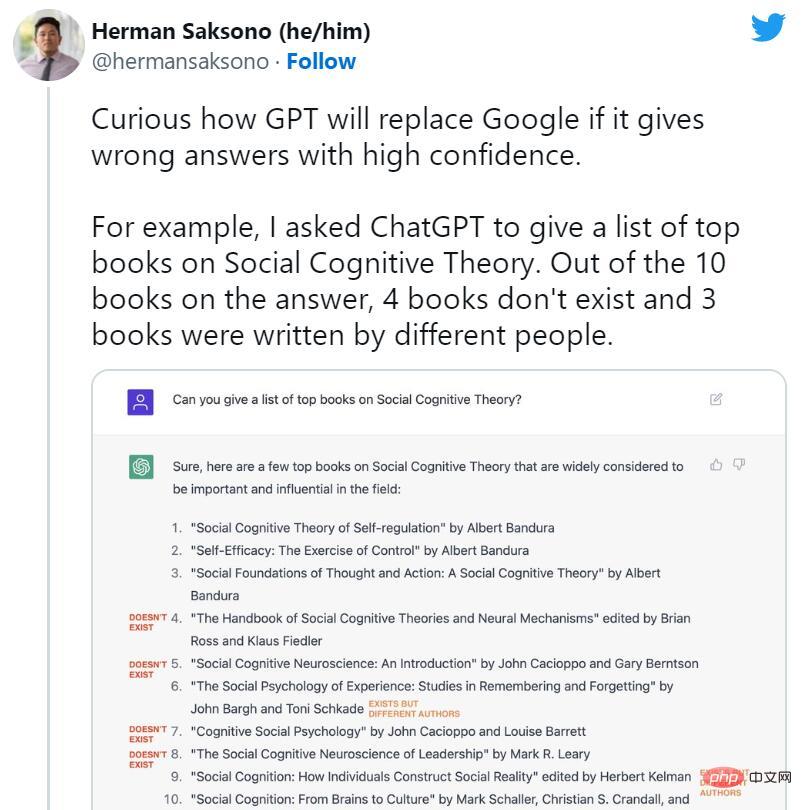
然而,尽管ChatGPT倾向于随意撒些小谎,但它对虚构的抑制正是我们今天谈论它的原因。一些专家指出,ChatGPT在技术上是对普通GPT-3(它的前身模型)的改进,因为它可以拒绝回答一些问题,或者当它的答案可能不准确时让你知道。
大型语言模型专家、Scale AI的提示工程师(prompt engineer)Riley Goodside表示,“ChatGPT成功的一个主要因素是,它成功地抑制了虚构,使许多常见问题都不引人注意。与它的前辈相比,ChatGPT明显不太容易编造东西。”
如果用作头脑风暴工具,ChatGPT的逻辑跳跃和虚构可能会导致创造性突破。但当用作事实参考时,ChatGPT可能会造成真正的伤害,而OpenAI也深知这一点。
在该模型发布后不久,OpenAI首席执行官Sam Altman就在推特上写道,“ChatGPT的功能非常有限,但在某些方面足够好,足以造成一种伟大的误导性印象。现在在任何重要的事情上依赖它都是错误的。这是进步的预演;在稳健性和真实性方面,我们还有很多工作要做。”
在后来的一条推文中,他又写道,“它确实知道很多,但危险在于,它在很大一部分时间里是盲目自信的,是错误的。”
这又是怎么一回事?
为了理解像ChatGPT或Bing Chat这样的GPT模型是如何进行“虚构”的,我们必须知道GPT模型是如何运作的。虽然OpenAI还没有发布ChatGPT、Bing Chat甚至GPT-4的技术细节,但我们确实可以在2020年看到介绍GPT-3(它们的前身)的研究论文。
研究人员通过使用一种称为“无监督学习”的过程来构建(训练)大型语言模型,如GPT-3和GPT-4,这意味着他们用于训练模型的数据没有特别的注释或标记。在这个过程中,模型被输入大量的文本(数以百万计的书籍、网站、文章、诗歌、抄写本和其他来源),并反复尝试预测每个单词序列中的下一个单词。如果模型的预测与实际的下一个单词接近,神经网络就会更新其参数,以加强导致该预测的模式。
相反地,如果预测不正确,模型会调整参数以提高性能并再次尝试。这种试错的过程,虽然是一种称为“反向传播”(backpropagation)的技术,但可以让模型从错误中学习,并在训练过程中逐渐改进其预测。
因此,GPT学习数据集中单词和相关概念之间的统计关联。一些人,比如OpenAI首席科学家Ilya Sutskever,认为GPT模型比这更进一步,建立了一种内部现实模型,这样他们就可以更准确地预测下一个最佳令牌(token),但这个想法是有争议的。GPT模型如何在其神经网络中提出下一个令牌的确切细节仍然不确定。

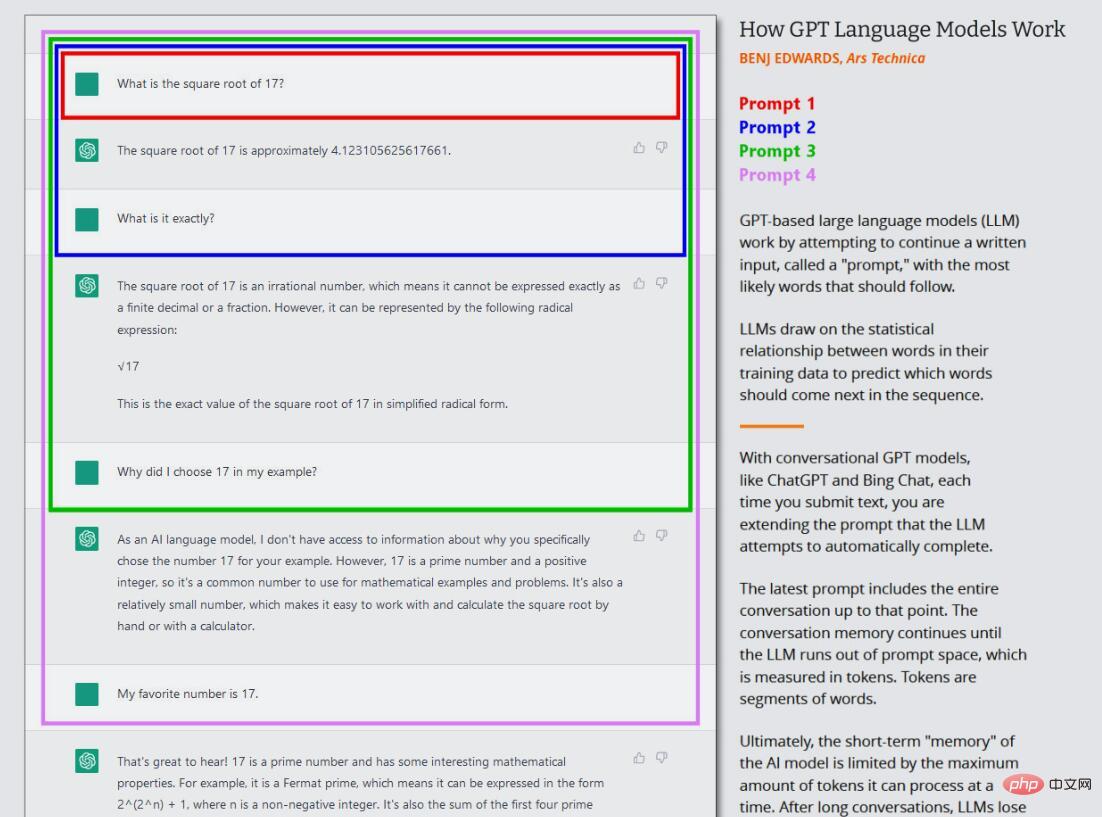
在当前的GPT模型浪潮中,这种核心训练(现在通常称为“预训练”pre-training)只发生一次。在此之后,人们可以在“推断模式”(inference mode)下使用训练好的神经网络,允许用户将输入输进训练好的网络中并得到结果。在推理期间,GPT模型的输入序列总是由人提供的,它被称为“指令/提示”(prompt)。提示符决定了模型的输出,即使稍微改变提示符也会极大地改变模型产生的结果。
例如,如果你提示GPT-3“玛丽有一个……(Mary had a)”,它通常会用“小羊羔”来完成句子。这是因为在GPT-3的训练数据集中可能有成千上万个“玛丽有只小羊羔(Mary had a little lamb)”的例子,这使得它成为一个合理的输出结果。但是如果你在提示符中添加更多上下文,例如“在医院,玛丽有了一个(In the hospital, Mary had a)”,结果将会改变并返回“婴儿”或“一系列检查”之类的单词。
这就是ChatGPT的有趣之处,因为它被设定为与代理(agent)的对话,而不仅仅是一个直接的文本生成工作。在ChatGPT的情况下,输入提示是你与ChatGPT进行的整个对话,从你的第一个问题或陈述开始,包括在模拟对话开始之前提供给ChatGPT的任何具体指示。在此过程中,ChatGPT对它和你所写的所有内容保持短期记忆(称为“上下文窗口”),当它与你“交谈”时,它正试图完成对话的文本生成任务。
此外,ChatGPT不同于普通的GPT-3,因为它也接受了人类编写的对话文本的训练。OpenAI在其最初的ChatGPT发布页面中写道,“我们使用监督微调(supervised fine-tuning)来训练一个初始模型:人类AI训练师提供对话,在对话中,他们会扮演双方——用户和人工智能助手。我们为训练师提供了模型编写的建议,以帮助他们撰写自己的回答。”
ChatGPT还使用一种称为“基于人类反馈强化学习”(RLHF)的技术进行了更大的调整,在这种技术中,人类评分者会根据偏好对ChatGPT的回答进行排序,然后将这些信息反馈到模型中。通过RLHF,OpenAI能够在模型中灌输“避免回答无法准确应答的问题”的目标。这使得ChatGPT能够以比基础模型更少的虚构产生一致的响应。但不准确的信息仍会漏过。
从本质上讲,GPT模型的原始数据集中没有任何东西可以将事实与虚构区分开。
LLM的行为仍然是一个活跃的研究领域。即便是创建这些GPT模型的研究人员仍然在发现这项技术的惊人特性,这些特性在它们最初被开发时没有人预测到。GPT能够做我们现在看到的许多有趣的事情,比如语言翻译、编程和下棋,这一度让研究人员感到惊讶。
所以当我们问为什么ChatGPT会产生虚构时,很难找到一个确切的技术答案。由于神经网络权重有一个“黑匣子”(black box)元素,在给出一个复杂的提示时,很难(甚至不可能)预测它们的准确输出。尽管如此,我们还是知道一些虚构发生的基本原因。
理解ChatGPT虚构能力的关键是理解它作为预测机器的角色。当ChatGPT进行虚构时,它正在寻找数据集中不存在的信息或分析,并用听起来似是而非的词填充空白。ChatGPT特别擅长编造东西,因为它必须处理的数据量非常大,而且它收集单词上下文的能力非常好,这有助于它将错误信息无缝地放置到周围的文本中。
软件开发人员Simon Willison表示,“我认为思考虚构的最好方法是思考大型语言模型的本质:它们唯一知道怎么做的事情是根据统计概率,根据训练集选择下一个最好的单词。”
在2021年的一篇论文中,来自牛津大学和OpenAI的三位研究人员确定了像ChatGPT这样的LLMs可能产生的两种主要类型的谎言。第一个来自其训练数据集中不准确的源材料,例如常见的误解(如,“吃火鸡会让你昏昏欲睡”)。第二种源于对其训练数据集中不存在的特定情况进行推断;这属于前面提到的“幻觉”标签。
GPT模型是否会做出疯狂的猜测,取决于AI研究人员所说的“温度”(temperature)属性,它通常被描述为“创造力”(creativity)设置。如果创造力被设定得很高,模型就会疯狂猜测;如果它被设置为低,它将根据它的数据集确定地吐出数据。
最近,微软员工Mikhail Parakhin在推特上谈到了Bing Chat的幻觉倾向,以及产生幻觉的原因。他写道,“这就是我之前试图解释的:幻觉=创造力。它试图使用其处理的所有数据产生字符串的最高概率连续。它通常是正确的。有时人们从未制作过这样的连续。”
Parakhin补充道,这些疯狂的创造性跳跃正是LLM有趣的地方。你可以抑制幻觉,但你会发现这样超级无聊。因为它总是回答“我不知道”,或者只反馈搜索结果中的内容(有时也不正确)。现在缺失的是语调:在这些情况下,它不应该表现得那么自信。”
当涉及到微调像ChatGPT这样的语言模型时,平衡创造性和准确性是一个挑战。一方面,提出创造性回应的能力使ChatGPT成为产生新想法或消除作者瓶颈的强大工具。这也使模型听起来更人性化。另一方面,当涉及到产生可靠的信息和避免虚构时,源材料的准确性至关重要。对于语言模型的开发来说,在两者之间找到正确的平衡是一个持续的挑战,但这对于开发一个既有用又值得信赖的工具是至关重要的。
还有压缩的问题。在训练过程中,GPT-3考虑了PB级的信息,但得到的神经网络的大小只是它的一小部分。在一篇被广泛阅读的《纽约客》文章中,作者Ted Chiang称这是一张“模糊的网络JPEG”。这意味着大部分事实训练数据会丢失,但GPT-3通过学习概念之间的关系来弥补了这一点,之后它可以使用这些概念重新制定这些事实的新排列。就像一个有缺陷记忆的人根据预感工作一样,它有时会出错。当然,如果它不知道答案,它会给出最好的猜测。
我们不能忘记提示符在虚构中的作用。在某些方面,ChatGPT是一面镜子:你给它什么,它就给你什么。如果你给它灌输谎言,它就会倾向于同意你的观点,并沿着这些路线“思考”。这就是为什么在改变话题或遇到不想要的回应时,用一个新的提示重新开始是很重要的。ChatGPT是概率性的,这意味着它在本质上是部分随机的。即使使用相同的提示,它输出的内容也可能在会话之间发生变化。
所有这些都得出了一个结论,OpenAI也同意这个结论:ChatGPT目前的设计并不是一个可靠的事实信息来源,也不值得信任。AI公司Hugging Face的研究员兼首席伦理科学家Margaret Mitchell博士认为,“ChatGPT在某些事情上非常有用,比如在缩小写作瓶颈或提出创意想法时。它不是为事实而建的,因此也不会是事实。就是这么简单。”
盲目地相信AI聊天机器人是一个错误,但随着底层技术的改进,这种情况可能会改变。自去年11月发布以来,ChatGPT已经升级了几次,其中一些升级包括准确性的提高,以及拒绝回答它不知道答案的问题的能力。
那么OpenAI计划如何让ChatGPT更准确呢?在过去的几个月里,我们多次就这个问题联系OpenAI,但没有得到任何回应。但我们可以从OpenAI发布的文件和有关该公司试图引导ChatGPT与人类员工保持一致的新闻报道中找到线索。
如前所述,ChatGPT如此成功的原因之一是因为使用RLHF进行了广泛的训练。OpenAI解释称,“为了让我们的模型更安全、更有帮助、更一致,我们使用了一种名为‘基于人类反馈强化学习(RLHF)’的现有技术。根据客户向API提交的提示,我们的标签器提供所需模型行为的演示,并对来自模型的几个输出进行排序。然后,我们使用这些数据对GPT-3进行微调。”
OpenAI的Sutskever认为,通过RLHF进行额外的训练可以解决幻觉问题。Sutskever在本月早些时候接受《福布斯》采访时称,“我非常希望,通过简单地改进这个后续RLHF教会它不要产生幻觉。”

他继续道,“我们今天做事的方式是雇人来教我们的神经网络如何反应,教聊天工具如何反应。你只需与它互动,它就会从你的反应中看出,哦,这不是你想要的。你对它的输出不满意。因此,输出不是很好,下次应该做一些不同的事情。我认为这是一个很大的变化,这种方法将能够完全解决幻觉问题。”
其他人并不同意。Meta的首席人工智能科学家Yann LeCun认为,当前使用GPT架构的LLM无法解决幻觉问题。但是有一种新出现的方法,可能会在当前架构下为LLM带来更高的准确性。他解释称,“在LLM中增加真实性的最活跃的研究方法之一是检索增强——向模型提供外部文档作为来源和支持上下文。通过这种技术,研究人员希望教会模型使用谷歌这样的外部搜索引擎,像人类研究人员一样,在答案中引用可靠的来源,减少对模型训练中学习到的不可靠的事实知识的依赖。”
Bing Chat和Google Bard已经通过网络搜索实现了这一点,很快,一个支持浏览器的ChatGPT版本也会实现。此外,ChatGPT插件旨在补充GPT-4的训练数据,它从外部来源检索信息,如网络和专门建造的数据库。这种增强类似于有百科全书的人会比没有百科全书的人更准确地描述事实。
此外,也有可能训练一个像GPT-4这样的模型,让它意识到自己什么时候在瞎编,并做出相应的调整。Mitchell认为,“人们可以做一些更深入的事情,让ChatGPT和类似的东西从一开始就更加真实,包括更复杂的数据管理,以及使用一种类似于PageRank的方法,将训练数据与‘信任’分数联系起来……当它对答复不那么有信心时,还可以对模型进行微调以对冲风险。”
因此,虽然ChatGPT目前因其虚构问题而陷入困境,但也许还有一条出路,随着越来越多的人开始依赖这些工具作为基本助手,相信可靠性的改进应该很快就会到来。
以上是为什么ChatGPT和Bing Chat如此擅长编造故事的详细内容。更多信息请关注PHP中文网其他相关文章!





















