

在这篇文章中,理论计算机科学家、哈佛大学知名教授 Boaz Barak 详细比较了深度学习与经典统计学的差异,认为“如果纯粹从统计学角度认识深度学习,就会忽略其成功的关键因素”。
深度学习(或一般的机器学习)经常被认为是简单的统计学,即它与统计学家研究的基本是相同的概念,但是使用与统计学不同的术语来描述。Rob Tibshirani 曾总结了下面这个有趣的“词汇表”:

表中的某些内容是不是很能引起共鸣?事实上所有从事机器学习的人都清楚,Tibshiriani 发布的这张表中,右侧的许多术语在机器学习中已被广泛使用。
如果纯粹从统计学角度认识深度学习,就会忽略其成功的关键因素。对深度学习更恰当的评价是:它使用统计学术语来描述完全不同的概念。
对深度学习的恰当评价不是它用不同的词来描述旧的统计术语,而是它用这些术语来描述完全不同的过程。
本文会解释为什么深度学习的基础其实不同于统计学,甚至不同于经典的机器学习。本文首先讨论模型拟合数据时的「解释(explanation)」任务和「预测(prediction)」任务之间的差异。接着讨论学习过程的两个场景:1. 使用经验风险最小化拟合统计模型; 2. 向学生传授数学技能。然后,文章又讨论了哪一个场景更接近深度学习的本质。
虽然深度学习的数学和代码与拟合统计模型几乎相同。但在更深层次上,深度学习更像是向学生传授数学技能这种场景。而且应该很少有人敢宣称:我掌握了完整的深度学习理论!其实是否存在这样的理论也是存疑的。相反深度学习的不同方面最好从不同的角度来理解,而仅仅从统计角度无法提供完整的蓝图。
本文对比了深度学习和统计学,这里的统计学特指的是“经典统计学”,因为它被研究得最久,并且在教科书中经久不衰。许多统计学家正在研究深度学习和非经典理论方法,就像 20 世纪物理学家需要扩展经典物理学的框架一样。事实上,模糊计算机科学家和统计学家之间的界限对双方都是有利的。
一直以来,科学家们都是将模型计算结果与实际观测结果进行比较,以验证模型的准确性。埃及天文学家托勒密提出了关于行星运动的巧妙模型。托勒密的模型遵循地心说,但有一系列的本轮(见下图),使其具有极好的预测准确性。相比之下,哥白尼最初的日心说模型比托勒密模型简单,但在预测观察结果方面不太准确。(哥白尼后来添加了自己的本轮,以便能够与托勒密的模型媲美。)
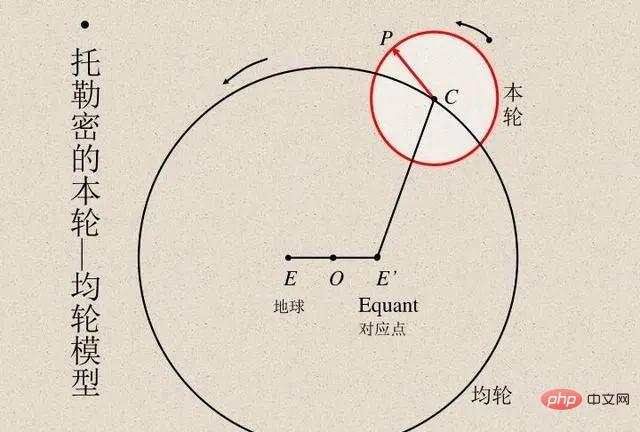
托勒密和哥白尼的模型都是无与伦比的。如果我们想通过 “黑盒” 进行预测,那么托勒密的地心模型更胜一筹。但如果你想要一个简单的模型,以便可以“观察模型内部”(这是解释恒星运动理论的起点),那么哥白尼的模型是不二选择。后来,开普勒将哥白尼的模型改进为椭圆轨道,并提出了开普勒行星运动三定律,这使得牛顿能够用适用于地球的引力定律来解释行星规律。
因此,重要的是,日心说模型不只是一个提供预测的“黑盒”,而是由几个简单的数学方程给出的,但是方程中的 “运动部分” 极少。多年来,天文学一直是发展统计技术的灵感来源。高斯和勒让德分别独立地在 1800 年左右发明了最小二乘回归,以预测小行星和其他天体的轨道。1847 年,柯西发明了梯度下降法,这也是由天文预测推动的。
在物理学中,有时学者们可以掌握全部细节,从而找到 “正确” 的理论,把预测准确性做到最优,并且对数据做出最好的解释。这些都在奥卡姆剃刀之类的观点范畴内,可以认为是假设简单性、预测能力和解释性都相互和谐一致的。
然而,在许多其它领域,解释和预测这两个目标之间的关系却没有那么和谐。如果只想预测观察结果,通过 “黑盒” 可能是最好的。另一方面,如果想获得解释性的信息,如因果模型、通用原则或重要特征,那么可以理解和解释的模型可能越简单越好。
模型的正确选择与否取决于其用途。例如,考虑一个包含许多个体的遗传表达和表型(例如某些疾病)的数据集,如果目标是预测一个人生病的几率,那么无论它有多复杂或依赖于多少个基因,都要使用适配该任务的最佳预测模型。相反,如果目的是识别一些基因,以便进行进一步研究,那么一个复杂的非常精确的 “黑盒” 的用处是有限的。
统计学家 Leo Breiman 在 2001 年关于统计建模的两种文化的著名文章中阐述了这一点。第一种是“数据建模文化”,侧重于能解释数据的简单生成模型。第二种是“算法建模文化”,对数据的生成方式不可知,侧重于寻找能够预测数据的模型,无论其多么复杂。

论文标题:
Statistical Modeling: The Two Cultures
论文链接:
https://projecteuclid.org/euclid.ss/1009213726
Breiman 认为,统计学过于受第一种文化的支配,这种关注造成两种问题:
Breiman 的论文一出,就引起了一些争议。同为统计学家的 Brad Efron 回应说,虽然他同意一些观点,但他也强调,Breiman 的论点似乎是反对节俭和科学见解,支持花大力气制造复杂的“黑盒”。但在最近的一篇文章中,Efron 摒弃了之前的观点,承认 Breima 更有先见之明,因为“21 世纪统计学的焦点都聚焦在预测算法上,在很大程度上沿着 Breiman 提出的路线演进”。
机器学习,无论是不是深度学习,都沿着 Breiman 的第二种观点演进,即以预测为重点。这种文化有着悠久的历史。例如,Duda 和 Hart 在 1973 年出版的教科书和 Highleyman 1962 年的论文就写到了下图中的内容,这对于今天的深度学习研究者来说是非常容易理解的:

Duda 和 Hart 的教科书《Pattern classification and scene analysis》和 Highleyman 1962 年的论文《The Design and Analysis of Pattern Recognition Experiments》中的片段。
类似地,下图中的 Highleyman 的手写字符数据集和用于拟合它的架构 Chow(1962)(准确率约为 58%)也会引起很多人的共鸣。

1992 年,Geman、Bienenstock 和 Doursat 写了一篇关于神经网络的悲观文章,认为 “当前的前馈神经网络在很大程度上不足以解决机器感知和机器学习中的难题”。具体来说,他们认为通用神经网络在处理困难任务方面不会成功,而它们成功的唯一途径是通过人工设计的特征。用他们的话说:“重要属性必须是内置的或“硬连接的”…… 而不是以任何统计意义上的方式学习。” 现在看来 Geman 等人完全错了,但更有意思的是了解他们为什么错了。
深度学习确实不同于其它学习方法。虽然深度学习似乎只是预测,就像最近邻或随机森林一样,但它可能有更多的复杂参数。这看起来似乎只是量的差异,而不是质的差异。但在物理学中,一旦尺度变化了几个数量级,通常就需要完全不同的理论,深度学习也是如此。深度学习与经典模型(参数化或非参数化)的基础过程完全不同,虽然它们的数学方程(和 Python 代码)在更高层次上来看是相同的。
为了说明这一点,下面考虑两个不同的场景:拟合统计模型和向学生教授数学。
通过数据去拟合一个统计模型的典型步骤如下:
1. 这里有一些数据 (
( 是
是 的矩阵;
的矩阵; 是
是 维向量,即类别标签。把数据认为是来自某个有结构且包含噪声的模型,就是要去拟合的模型)
维向量,即类别标签。把数据认为是来自某个有结构且包含噪声的模型,就是要去拟合的模型)
2. 使用上面的数据拟合一个模型 ,并用优化算法来最小化经验风险。就是说通过优化算法找到这样的
,并用优化算法来最小化经验风险。就是说通过优化算法找到这样的 ,使得
,使得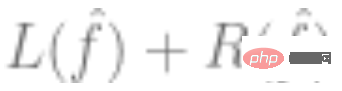 最小,
最小, 代表损失(表明预测值有多接近真实值),
代表损失(表明预测值有多接近真实值), 是可选的正则化项。
是可选的正则化项。
3. 模型的总体损失越小越好,即泛化误差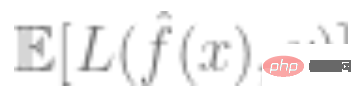 的值相对最小。
的值相对最小。
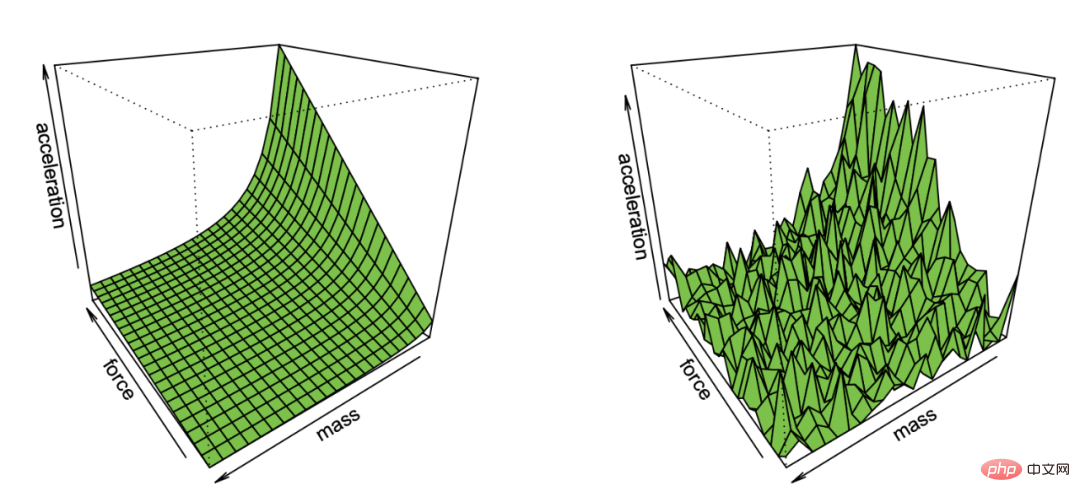
Effron 从包含噪声的观测中恢复牛顿第一定律的展示图
这个非常通用的范例其实包含许多内容,如最小二乘线性回归、最近邻、神经网络训练等等。在经典统计场景中,我们通常会碰到下面的情况:
权衡:假设是经过优化的模型集合(如果函数是非凸的或包含正则化项,精心选择算法和正则化,可得到模型集。的偏差是元素所能达到的最接近真值的近似值。集合越大,偏差越小,并且可能为 0(如果)。
然而,越大,需要缩小其成员范围的样本越多,因此算法输出模型的方差越大。总体泛化误差是偏差和方差的总和。因此,统计学习通常是 Bias-Variance 权衡,正确的模型复杂度是将总体误差降至最低。事实上,Geman 等人证明了其对神经网络的悲观态度,他们认为:Bias-Variance 困境造成的基本限制适用于所有非参数推理模型,包括神经网络。
“多多益善”并不总是成立:在统计学习中,更多的特征或数据并不一定会提高性能。例如,从包含许多不相关特征的数据中学习是很难的。类似地,从混合模型中学习,其中数据来自两个分布中的一个(如和,比独立学习每个分布更难。
收益递减:在很多情况中,将预测噪声降低到水平所需的数据点数量与参数和是有关的,即数据点数量约等于。在这种情况下,需要大约 k 个样本才能启动,但一旦这样做,就面临着回报递减的情况,即如果需要个点才能达到 90% 的准确率,则需要大约额外的个点来将准确率提高到 95%。一般来说,随着资源增加(无论是数据、模型复杂度还是计算),人们希望获得越来越精细的区分,而不是解锁特定的新功能。
对损失、数据的严重依赖性:当将模型拟合到高维数据时,任何小细节都可能会产生很大的差异。L1 或 L2 正则化器等选择很重要,更不用说使用完全不同的数据集。不同数量的高维优化器相互之间也非常不同。
数据是相对 “单纯” 的:通常会假设数据是独立于某些分布进行采样的。虽然靠近决策边界的点很难分类,但考虑到高维度上测量集中现象,可以认为大多数点的距离都是相近的。因此在经典的数据分布中,数据点间的距离差异是不大的。然而,混合模型可以显示这种差异,因此,与上述其他问题不同,这种差异在统计中很常见。
在这个场景中,我们假设你想通过一些说明和练习来教学生数学(如计算导数)。这个场景虽然没有正式定义,但有一些定性特征:
学习一项技能,而不是去近似一个统计分布:在这种情况下,学生学习的是一种技能,而不是某个量的估计 / 预测。具体来说,即使将练习映射到解的函数不能被用作解决某些未知任务的“黑盒”,但学生在解决这些问题时形成的思维模式仍然对未知任务是有用的。
多多益善:一般来说,做题越多、题型涉猎越广的学生表现越好。同时做一些微积分题和代数题,不会导致学生的微积分成绩下降,相反可能帮助其微积分成绩提升。
从提升能力到自动化表示:虽然在某些情况下,解决问题的回报也会递减,但学生的学习会经历几个阶段。有一个阶段,解决一些问题有助于理解概念并解锁新的能力。此外,当学生重复某一特定类型的问题时,他们见到同类问题就会形成自动化的解题流程,从之前的能力提升转变为自动化解题。
表现独立于数据和损失:教授数学概念的方法不止一种。使用不同书、教育方法或评分系统学习的学生最终可以学习到相同的内容以及相似的数学能力。
有些问题更困难:在数学练习中,我们经常看到不同学生解决同一问题的方式之间存在着很强的相关性。对于一个问题来说,似乎确实存在一个固有的难度水平,以及一个对学习最有利的自然难度递进。
上面两个场景的比喻中,哪一个用来描述现代深度学习更恰当?具体来说,它成功的原因是什么?统计模型拟合可以很好地使用数学和代码来表达。实际上,规范的 Pytorch 训练循环通过经验风险最小化训练深度网络:

在更深的层次上,这两种场景之间的关系并不清楚。为了更具体,这里以一个特定的学习任务为例。考虑使用 “自监督学习 + 线性探测” 方法训练的分类算法。具体算法训练如下:
1. 假设数据是一个序列,其中 是某个数据点(比如一张图片),是标签。
是某个数据点(比如一张图片),是标签。
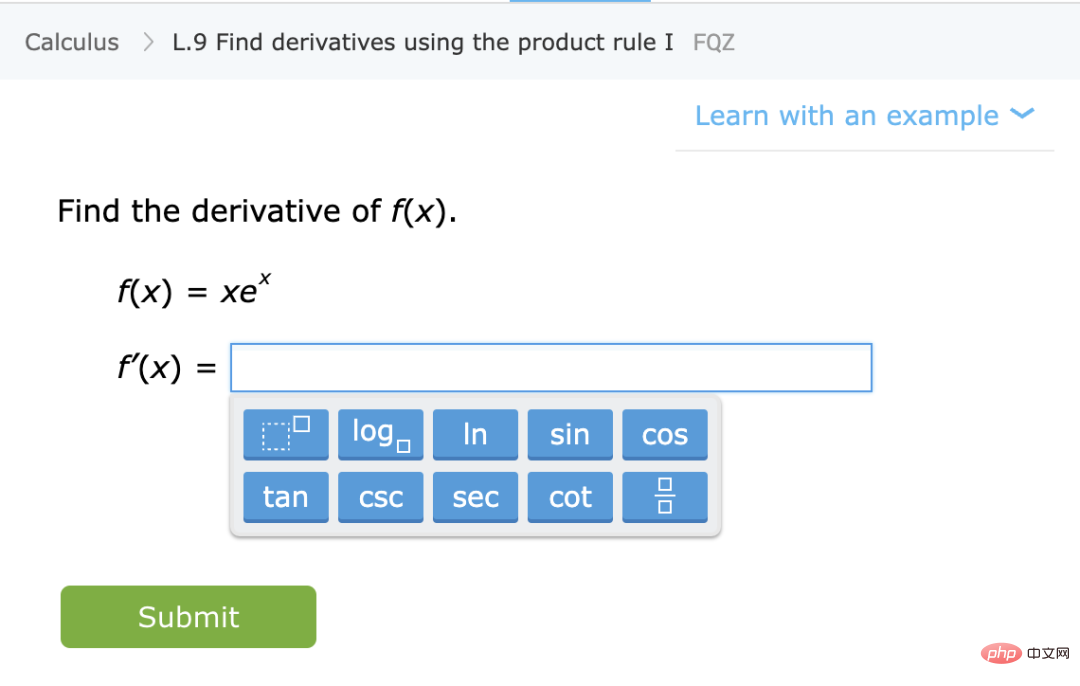
2. 首先得到表示函数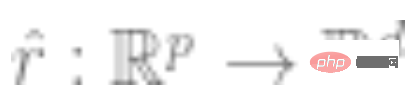 的深度神经网络。通过最小化某种类型的自监督损失函数,仅使用数据点而不使用标签来训练该函数。这种损失函数的例子是重建(用其它输入恢复输入)或对比学习(核心思想是正样本和负样本在特征空间对比,学习样本的特征表示)。
的深度神经网络。通过最小化某种类型的自监督损失函数,仅使用数据点而不使用标签来训练该函数。这种损失函数的例子是重建(用其它输入恢复输入)或对比学习(核心思想是正样本和负样本在特征空间对比,学习样本的特征表示)。
3. 使用完整的标记数据拟合线性分类器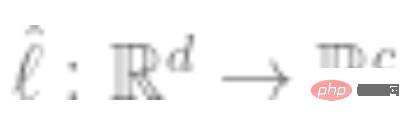 (是类数),以最小化交叉熵损失。我们的最终分类器是:
(是类数),以最小化交叉熵损失。我们的最终分类器是:
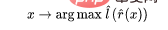
步骤 3 仅适用于线性分类器,因此 “魔术” 发生在步骤 2 中(深度网络的自监督学习)。在自监督学习中有些重要属性:
学习一项技能而不是去近似一个函数:自监督学习不是逼近函数,而是学习可用于各种下游任务的表示(这是自然语言处理的主导范式)。通过线性探测、微调或激励获得下游任务是次要的。
多多益善:在自监督学习中,表示质量随着数据量的增加而提高,不会因为混合了几个来源的数据而变糟。事实上,数据越多样化越好。
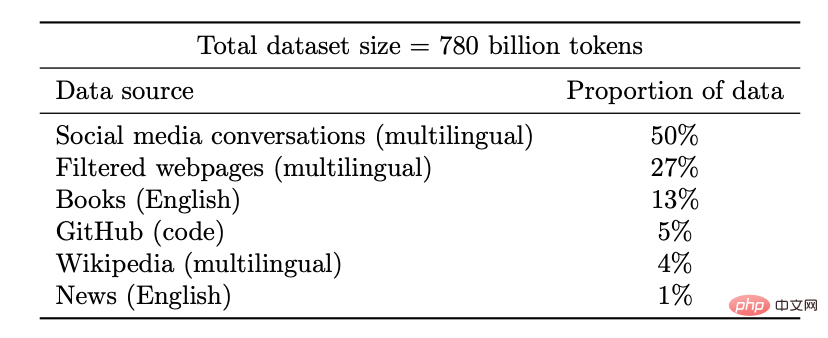
Coogle PaLM 模型的数据集
解锁新能力:随着资源(数据、计算、模型大小)投入的增加,深度学习模型也在不连续地改进。在一些组合环境中也证明了这一点。
随着模型规模的增加,PaLM 在基准测试中显示出不连续的改进,并且解锁令人惊讶的功能,比如解释笑话为什么好笑。
性能几乎与损失或数据无关:存在多个自监督损失,图像研究中其实使用了多种对比和重建损失,语言模型使用单边重建(预测下一个 token)或使用 mask 模型,预测来自左右 token 的 mask 输入。也可以使用稍微不同的数据集。这些可能会影响效率,但只要做出 “合理” 的选择,通常原始资源比使用的特定损失或数据集更能提升预测性能。
有些情况比其他情况更困难:这一点并不特定于自监督学习。数据点似乎有一些固有的 “难度级别”。事实上,不同的学习算法具有不同的“技能水平”,不同的数据 dian 具有不同的” 难度水平“(分类器正确分类点的概率随的技能而单调提升,随难度单调降低)。
“技能与难度(skill vs. difficulty)”范式是对 Recht 等人和 Miller 等人发现的 “accuracy on the line” 现象的最清晰解释。Kaplen、Ghosh、Garg 和 Nakkiran 的论文还展示了数据集中的不同输入如何具有固有的“难度剖面”,对于不同的模型族,该剖面通常是稳健的。
C**IFAR-10 上训练并在 CINIC-10 上测试的分类器的 accuracy on the line 现象。图源:https://millerjohnp-linearfits-app-app-ryiwcq.streamlitapp.com/
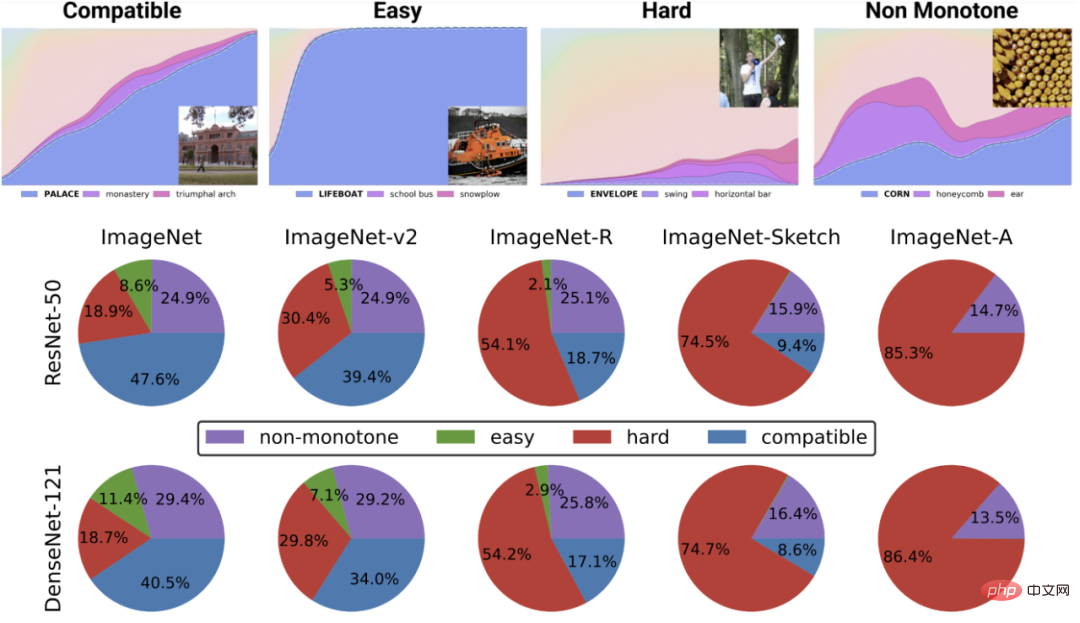
顶部的图描述了最可能类别的不同 softmax 概率,作为某个类别分类器的全局精度的函数,该类别由训练时间索引。底部的饼图显示了不同数据集分解为不同类型的点(注意,这种分解对于不同的神经结构是相似的)。
训练就是教学:现代大模型的训练似乎更像是教学生,而不是让模型拟合数据,当学生不懂或感到疲倦时,就 “休息” 或尝试不同的方法(训练差异)。Meta 的大模型训练日志很有启发性——除了硬件问题外,我们还可以看到干预措施,例如在训练过程中切换不同的优化算法,甚至考虑 “hot swapping” 激活函数(GELU to RELU)。如果将模型训练视为拟合数据,而不是学习表示,则后者没有多大意义。
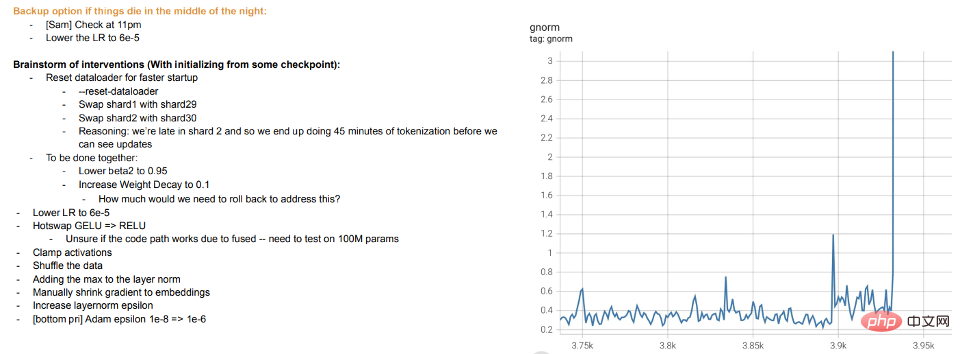
Meta 训练日志摘录
前面讨论了自监督学习,但深度学习的典型例子,仍然是监督学习。毕竟,深度学习的 “ImageNet 时刻” 来自 ImageNet。那么上面所讨论的是否仍然适用于这个设定?
首先,有监督的大规模深度学习的出现在某种程度上是个偶然,这得益于大型高质量标记数据集(即 ImageNet)的可用性。如果你想象力丰富,可以想象另一种历史,即深度学习首先开始通过无监督学习在自然语言处理方面取得突破性进展,然后才转移到视觉和监督学习中。
其次,有证据表明,尽管使用完全不同的损失函数,但监督学习和自监督学习在”内部“的行为其实是相似的。两者通常都能达到相同的性能。具体地,对于每一个,人们可以将通过自监督训练的深度为 d 的模型的前 k 层与监督模型的最后 d-k 层合在一起,而性能损失很小。
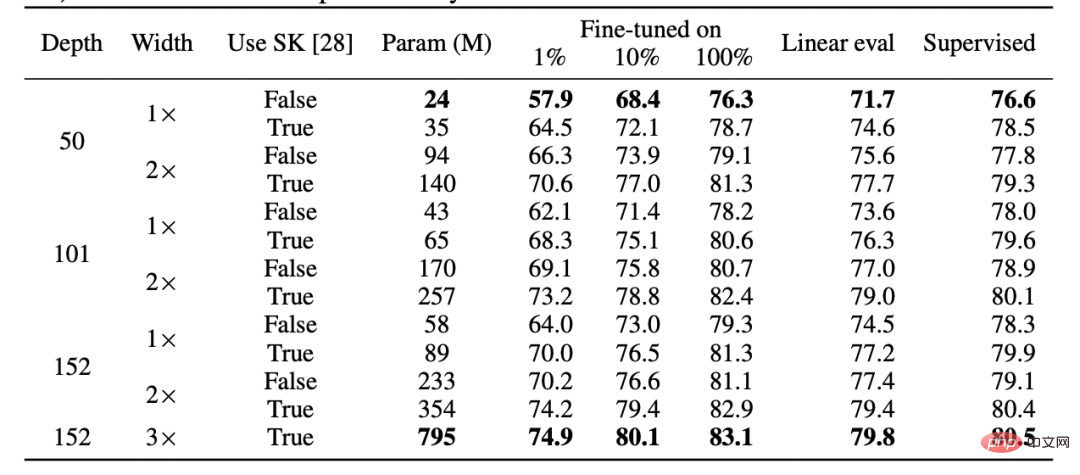
SimCLR v2 论文的表格。请注意监督学习、微调(100%)自监督和自监督 + 线性探测之间在性能上的一般相似性(图源:https://arxiv.org/abs/2006.10029)
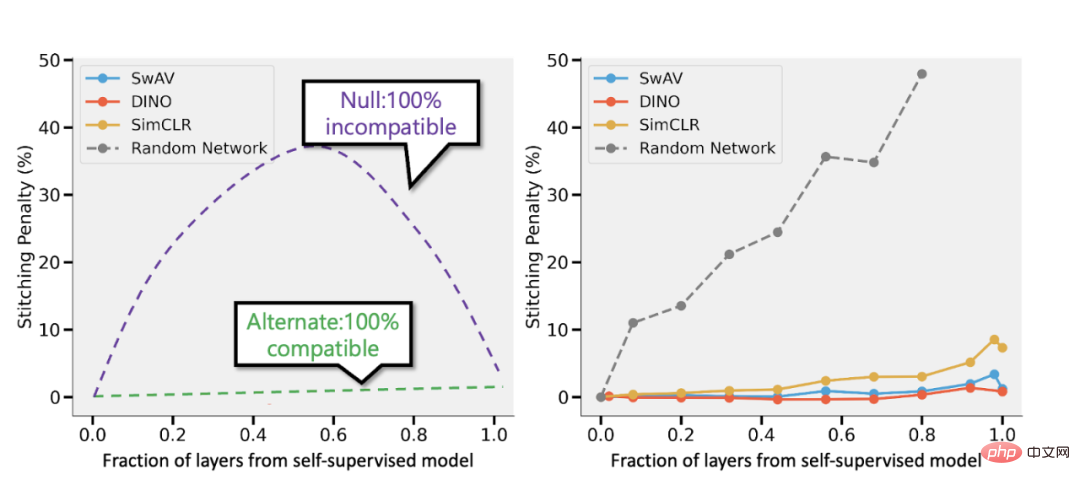
拼接自监督模型和 Bansal 等人的监督模型(https://arxiv.org/abs/2106.07682)。左:如果自监督模型的准确率(比如)比监督模型低 3%,则当层的 p 部分来自自监督模型时,完全兼容的表示将导致拼接惩罚为 p 3%。如果模型完全不兼容,那么我们预计随着合并更多模型,准确率会急剧下降。右:合并不同自监督模型的实际结果。
自监督 + 简单模型的优势在于,它们可以将特征学习或 “深度学习魔法”(由深度表示函数完成)与统计模型拟合(由线性或其他“简单” 分类器在此表示之上完成)分离。
最后,虽然这更像是一种推测,但事实上 “元学习” 似乎往往等同于学习表征(参见:https://arxiv.org/abs/1909.09157,https://arxiv.org/abs/2206.03271),这可以被视为另一个证据,证明这在很大程度上是在进行的,而不管模型优化的目标是什么。
本文跳过了被认为是统计学习模型和深度学习在实践中存在差异的典型例子:缺乏 “Bias-Variance 权衡” 以及过度参数化模型的良好泛化能力。
为什么要跳过?有两个原因:

Nakkiran-Neyshabur-Sadghi“deep bootstrap”论文表明,现代架构在 “过度参数化” 或“欠采样”状态下表现类似(模型在有限数据上训练多个 epoch,直到过度拟合:上图中的 “Real World”),在“欠参数化” 或者 “在线” 状态下也是如此(模型训练单个 epoch,每个样本只看一次:上图中的 “Ideal World”)。图源:https://arxiv.org/abs/2010.08127
统计学习当然在深度学习中发挥着作用。然而,尽管使用了相似的术语和代码,但将深度学习视为简单地拟合一个比经典模型具有更多参数的模型,会忽略很多对其成功至关重要的东西。教学生数学的比喻也不是完美的。
与生物进化一样,尽管深度学习包含许多复用的规则(如经验损失的梯度下降),但它会产生高度复杂的结果。似乎在不同的时间,网络的不同组件会学习不同的东西,包括表示学习、预测拟合、隐式正则化和纯噪声等。研究人员仍在寻找合适的视角提出有关深度学习的问题,更不用说回答这些问题。
以上是学习=拟合?深度学习和经典统计学是一回事吗?的详细内容。更多信息请关注PHP中文网其他相关文章!





















