

计算机科学和机器学习 (ML) 的许多应用都需要处理跨坐标系的多维数据集,并且单个数据集可能也需要存储 TB 或 PB 的数据。另一方面,使用此类数据集也具有挑战性,因为用户可能会以不规则的间隔和不同的规模读取和写入数据,通常还会执行大量的并行工作。
为了解决上述问题,谷歌开发了一个开源的 C++ 和 Python 软件库 TensorStore,专为存储和操作 n 维数据而设计。谷歌 AI 负责人 Jeff Dean 也在推特上发文表示 TensorStore 现已正式开源。
TensorStore 的主要功能包括:
TensorStore 已被用于解决科学计算中的工程挑战,还被用于创建大型机器学习模型,例如用来管理 PaLM 在分布式训练期间的模型参数(检查点)。
GitHub 地址:https://github.com/google/tensorstore
TensorStore 提供了一个简单的 Python API 用于加载和操作大型数组数据。例如,下面的代码创建了一个 TensorStore 对象,该对象代表一个 56 万亿体素的苍蝇大脑 3D 图像,并允许访问 NumPy 数组中 100x100 的图像 patch 数据:
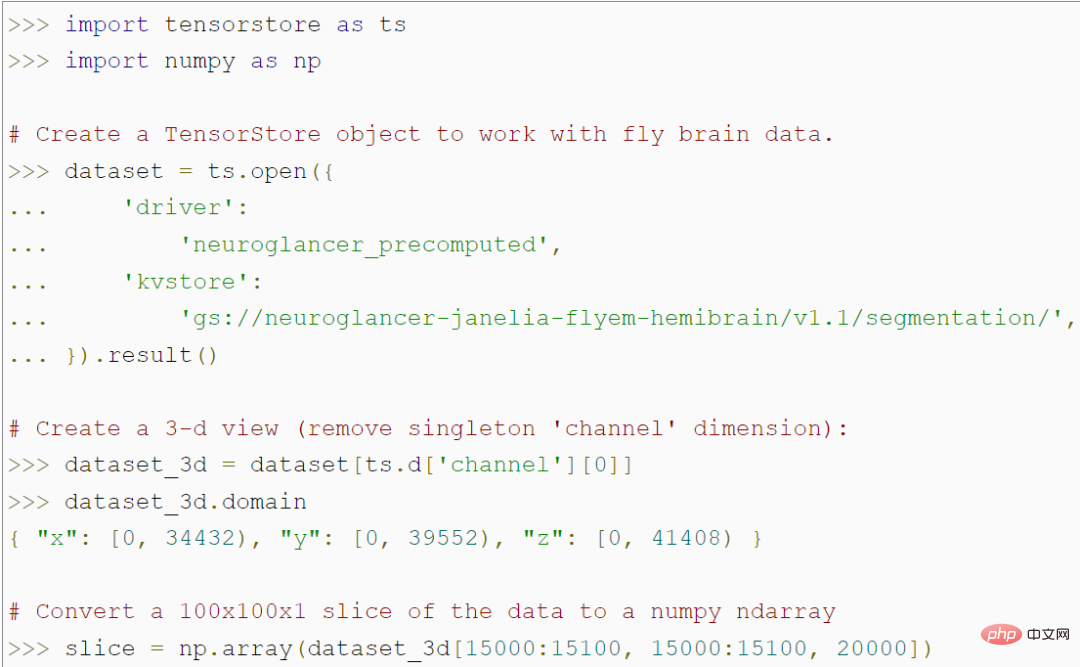
值得注意的是,该程序在访问特定的 100x100 patch 之前,不会访问内存中的实际数据,因此可以加载和操作任意大的基础数据集,而无需将整个数据集存储在内存中。TensorStore 使用与标准 NumPy 基本相同的索引和操作语法。
此外,TensorStore 还为高级索引功能提供广泛支持,包括对齐、虚拟视图等。
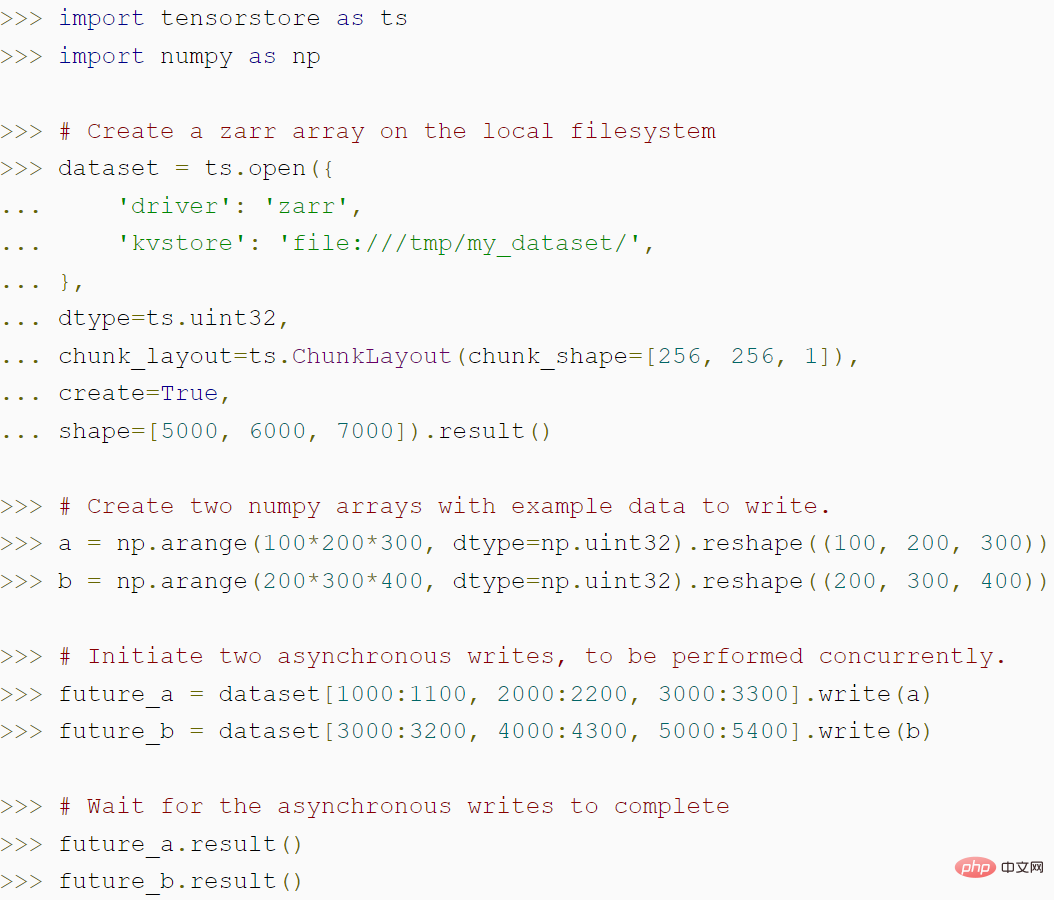
下面的代码演示了如何使用 TensorStore 创建一个 zarr 数组,以及 TensorStore 的异步 API 如何实现更高的吞吐量:
众所周知,分析和处理大型数据集需要大量的计算资源,通常需要分布在多个机器上的 CPU 或加速器内核的并行化来实现。因此,TensorStore 的一个基本目标是实现并行处理,达到既安全又高性能的目的。事实上,在谷歌数据中心内的测试中,他们发现随着 CPU 数量的增加,TensorStore 读写性能几乎呈线性增长:
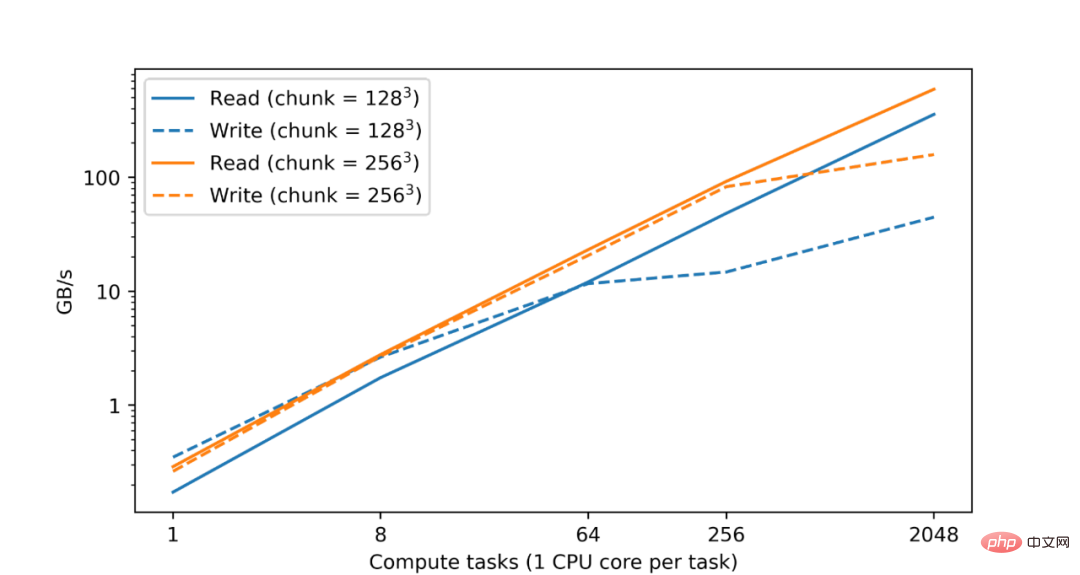
在谷歌云存储 (GCS) 上对 zarr 格式数据集的读写性能,读和写性能与计算任务的数量几乎成线性增长。
TensorStore 还提供了可配置的内存缓存和异步 API,以允许读写操作在程序完成其他工作时在后台继续执行。为了使 TensorStore 的分布式计算与数据处理工作流兼容,谷歌还将 TensorStore 与 Apache Beam 等并行计算库集成。
示例 1 语言模型:最近一段时间,机器学习领域出现了一些 PaLM 等高级语言模型。这些模型包含数千亿个参数,在自然语言理解和生成方面表现出惊人的能力。不过这些模型对计算设施提出了挑战,特别是,训练一个像 PaLM 这样的语言模型需要数千个 TPU 并行工作。
其中有效地读取和写入模型参数是训练过程面临的一个问题:例如训练分布在不同的机器上,但参数又必须定时的保存到 checkpoint 中;又比如单个训练必须仅读取特定参数集,以避免加载整个模型参数集(可能是数百 GB)所需的开销。
TensorStore 可以解决上述问题。它已被用于管理大型(multipod)模型相关的 checkpoint,并已与 T5X 和 Pathways 等框架集成。TensorStore 将 Checkpoint 转换为 zarr 格式存储,并选择块结构以允许每个 TPU 的分区并行独立地读取和写入。

当保存 checkpoint 时,参数以 zarr 格式写入,块网格进一步被划分,以用于在 TPU 上划分参数网格。主机为分配给该主机的 TPU 的每个分区并行写入 zarr 块。使用 TensorStore 的异步 API,即使数据仍被写入持久存储,训练也会继续进行。当从 checkpoint 恢复时,每个主机只读取分配给该主机的分区块。
示例 2 大脑 3D 映射:突触分辨连接组学的目标是在单个突触连接水平上绘制动物和人脑的连线。完成这一目标需要在毫米或更大的视野范围内以极高的分辨率 (纳米级) 对大脑进行成像,由此产生的数据大小达到 PB 级。然而,即使是现在,数据集也面临着存储、处理等方面的问题,即使是单个大脑样本也可能需要数百万 GB 的空间。
谷歌已经使用 TensorStore 来解决与大规模连接组学数据集相关的计算挑战。具体而言,TensorStore 已经开始管理一些连接组学数据集,并将谷歌云存储作为底层对象存储系统。
目前,TensorStore 已被用于人类大脑皮层数据集 H01,原始成像数据为 1.4 PB(约为 500000 * 350000 * 5000 像素)。之后原始数据被细分为 128x128x16 像素的独立块,以「Neuroglancer precomputed」格式存储,TensorStore 可以很容易的对其进行操作。

利用 TensorStore 可以轻松访问和操作底层数据(苍蝇大脑重建)
想要上手一试的小伙伴,可以使用以下方法安装 TensorStore PyPI 包:
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pip</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">install</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">tensorstore</span>
以上是存储和操作n维数据的难题,谷歌用一个开源软件库解决了的详细内容。更多信息请关注PHP中文网其他相关文章!





















