

嘉宾 | 窦志成
整理 | 张锋
策划 | 徐杰承
搜索引擎自诞生之初到现在已经有二十多年,其形式和架构一直没有发生很大改变。伴随着互联网技术的持续发展,未来的搜索环境将变得愈加复杂多样,用户获取信息的方式也会发生很多的变化,自然语言、语音、视觉等多种输入形式势必会取代简单的关键词;答案、高阶知识、分析结果、生成内容等多种模态内容输出将取代简单结果列表;在交互方式上也可能会从单轮检索过渡到多轮自然语言交互。
那么在新的搜索的环境下,未来智能搜索技术都将会呈现出哪些特征呢?日前,在51CTO主办的在AISummit全球人工智能技术大会上,中国人民大学高瓴人工智能学院副院长窦志成老师通过主题演讲——《下一代智能搜索技术》,为广大听众分享了新一代智能搜索技术的发展趋势及核心特征,同时就交互式、多模态、可解释搜索、及以大模型为中心的去索引化搜索等技术做出了详尽分析。本文将窦志成老师的演讲内容进行了编辑整理,希望能给大家带来一些新的启发:
我们认为未来的搜索可能会有至少这五个方面的特征:
现在使用的搜索引擎普遍采用的模式是在一个框里面输入一两个词进行搜索。未来的搜索则可能是我们与搜索引擎采用对话的方式进行交互。
在传统的搜索引擎采用的关键词检索方式,我们希望把所有要找的信息核心都通过关键词描述出来,即我们假设单个查询能够完整、准确地表达这个信息的需求。但在表达一个较为复杂的信息时,关键词其实是很难满足需求的。而对话式搜索可以通过多轮交互来充分表达信息需求,比较符合人和人在交流的时层层递进的信息交互方式。
想要到达这种交互式搜索,会给系统或算法带来很大的挑战,需要让搜索引擎从多轮的自然语言交互中准确理解用户的意图,同时也要把理解出的意图与用户想要的信息做好匹配。
相比于传统的关键词搜索,对话式搜索需要更复杂的查询理解(例如需要解决当前查询中的省略,共指等问题),以还原用户的真实搜索意图。最简单的方式是将历史查询全部拼接起来,使用预训练语言模型进行编码。
简单的拼接对话方式虽然简单,但可能会引入噪声,并不是所有的历史查询都对于理解当前查询是有帮助的,所以我们只选出和它有依赖关系的上下文,这样也能解决长度的问题。
基于以上思想,我们提出了对话式稠密检索的模型COTED,其主要包括如下三部分:
1、通过识别对话查询中的依赖关系,来去除对话中的噪声,进而更好地预测用户的意图。
2、基于对比学习的数据增强(模仿各种噪声情况)和去噪损失函数,有效让模型学会忽略无关的上下文,把它和最终匹配的损失函数联合,做多任务的学习。
3、通过课程学习的方式来降低模型多任务学习的学习难度,最终提升模型性能。
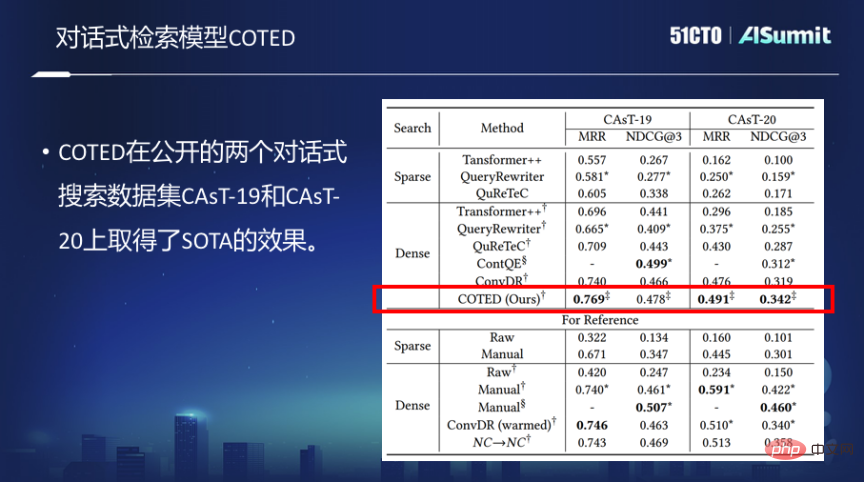
然而,够用于对话式搜索模型训练的数据实际上是非常有限的,在有限的少样本情况下,对话式搜索的模型训练是非常困难的。
如何解决这个问题?出发点就是能否把搜索引擎日志迁移去做对话式搜索引擎的训练。在这个思想上,把大规模的web搜索的日志转换成对话式搜索日志,然后在转换之后的数据上训练对话式搜索的模型。但这种方法也同时伴随着两个很明显的问题:
一是传统的web搜索采用关键词搜索的方式,对话式搜索是自然语言对话的方式,查询形式是不一样的,无法直接迁移使用。二是查询本身就会存在很多噪声,需要对搜索日志里面的用户数据做一些清洗、过滤、转换,才能用在对话式搜索里面。
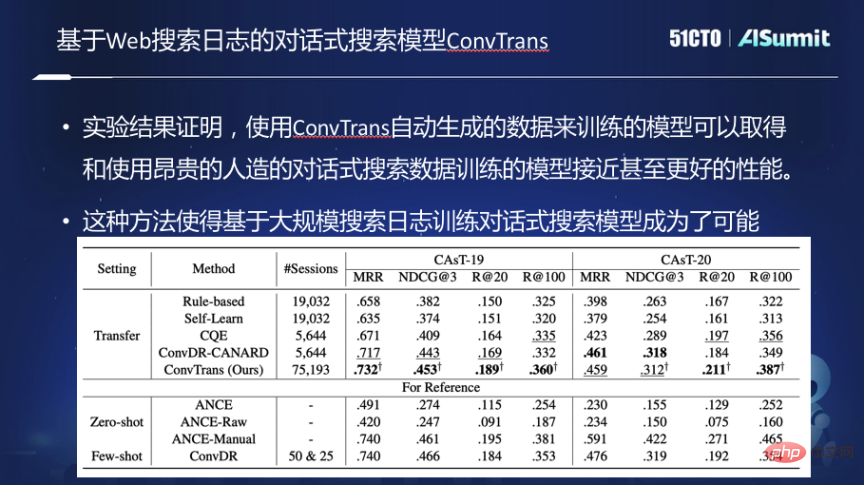
为了解决这些问题,我们做了对话式搜索训练模型ConvTrans,并实现了以下功能。
首先,以图的方式对传统的web搜索引擎中的日志进行了组织,通过查询与查询、查询与文档之间建立联系构建了图。在图的基础上,使用了一个基于T5的两阶段查询改写的模型,将一个关键词的查询改写成一个问题的形式。经过改写之后,图中每个查询都会用自然语言来表达新的查询,再设计一个采样的算法,从图上做随机游走,生成对话的会话,之后基于这个数据来训练对话的模型。
实验显示,用这种自动生成的训练数据来训练的对话式搜索模型,能够和使用昂贵的人造或者人工标注的数据达到同样的效果,且随着自动生成的训练数据规模的增大,性能也会持续提升。这种方法使我们基于大规模搜索日志进行训练对话式搜索模型成为了可能。
对话式搜索模型虽然在搜索上已经走了一大步,但这种对话方式仍然是被动的,搜索引擎一直被动的接受用户的输入,根据输入来返回结果,搜索引擎没有主动地去问用户你到底要找什么。但在人和人的交流过程中,当你被问一个问题的时候,有时候你会主动地来反问一些问题来做澄清。
比如必应搜索里面,如果Query是“Headaches”,头疼。它会问你“What do want to know about this medical condition”“你想知道关于这个疾病的什么事”,比如说是它的症状、还是治疗、还是诊断、还是成因或者诱因。因为Headaches本身是非常宽泛的一个Query,在这种情况下,系统希望能够进一步澄清你想找到哪里的信息。
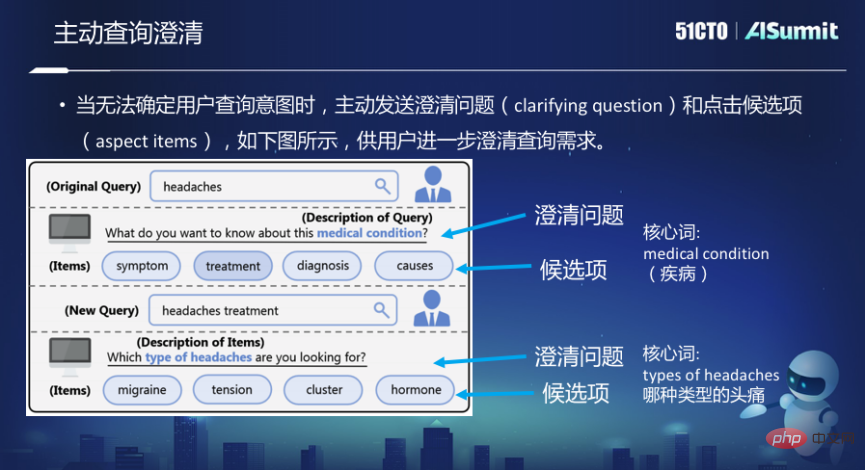
这里面临两个问题,第一是候选项,就是想让用户去澄清到哪个具体的项。第二是澄清问题,搜索引擎主动反过来问用户的这个问题。而核心词是澄清问题里面最至关重要的一部分。
在这方面的探索,第一是通过查询日志和知识库去给定一个查询的时候,能够生成一些澄清的候选项。第二,基于规则可以通过搜索的结果来预测这个澄清问题的一些核心词。同时也标注一些数据,通过有监督的模型来做这种文本标签的分类。第三,进一步在这个标注数据的基础上训练端到端的生成模型。
个性化指的是未来的搜索将以用户为核心。现在的搜索引擎,不管是谁来查,返回都是同样的结果。而这并不能满足用户的特定化信息需求。
现在的个性化搜索采用的模式,首先通过用户历史学习用户熟悉的知识信息,对查询进行个性化实体消歧。其次,通过消歧后的查询实体增强个性化匹配。
此外我们在基于产品品类构建用户的多兴趣模型方面也做了探索,假设用户可能有自己在所有品类上的一些品牌(规格、型号)倾向性,但是这个倾向性不能简单的通过一两个向量来去刻画。应该根据用户购物的历史,构建知识图谱,通过知识图谱针对不同品类学习不同的兴趣,最终做更精准的个性化搜索的结果推送。
也可以用同样的个性化方法去做聊天机器人,核心思想就是通过用户历史对话,学习用户个性化兴趣和语言模式,训练个性化对话模型,可以模仿(代理)用户说话。
现在的搜索引擎在处理多模态信息的时候,其实有相当多的局限性的。未来用户获取的信息可能不仅仅是一些文字、网页,可能还包括图片、视频以及更复杂的结构信息。所以未来的搜索引擎在多模态信息获取上还有很多工作需要做。
现在的搜索引擎在理解或者是做跨模态检索时,即给出一个文本的描述,去找它对应的图片的时候,做得还是有很多缺陷的。类似的搜索如果迁移到手机上,局限性就会更大。
所谓的多模态就是语言、要找的图像、图片、视频等模态,映射到统一的一个空间上,这就意味着可以通过文字去找图片,图片去找文字,图片去找图片等。
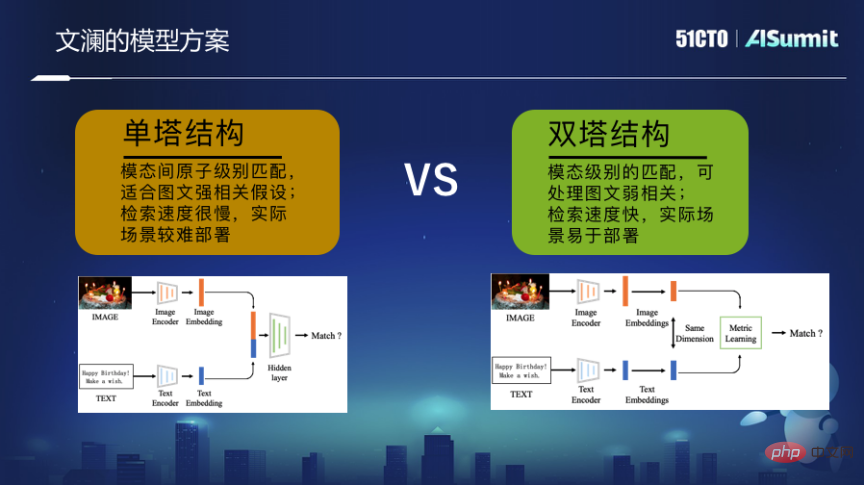
对此,我们做了大规模多模态的预训练模型——文澜。其重点是基于海量的互联网图片和附近文字的弱监督相关性贡献的信息训练出来的。采用双塔模式,最后训练的是一个图片的编码器和文本的编码器,这两个编码器通过端到端匹配的优化学习过程,让最终的表示向量能够映射到统一空间中,而不是把图片的细粒度和文字的细粒度拼接在一起。
这种跨模态的检索能力,其实不只是端到端给用户使用web搜索引擎时提供了更多的空间,同时也可以支撑很多应用,例如创作,不管是社交媒体还是文创类,都可以用它来支撑。
现在的搜索引擎普遍检索的主体还是网页,而未来搜索引擎处理的单元不仅仅是网页,应该是以知识为处理的单位,包括返回的结果也应该是高阶的知识,而不是一个一个页面的列表形式。很多时候用户其实想通过搜索引擎来完成一些复杂的信息需求,故而希望搜索引擎帮助分析结果,而不是让人来一个一个去分析。
基于此想法我们构建了分析引擎,相当于是在搜索引擎的基础上,能提供深度的文本分析,帮助用户高效、快捷地获取高阶知识。帮助用户完成对大规模文档的阅读和理解,并对其中所包含的关键信息和知识进行抽取、挖掘、汇总,最终通过交互式的分析过程,让用户对挖掘到的高阶知识进行浏览和分析,进而为用户提供决策支持。
例如用户希望找雾霾相关的信息,可以直接输入“雾霾”。富知识模式与传统的搜索引擎返回的结果不同,可能返回一个时间轴,告诉用户关于雾霾的信息在时间轴上的分布等情况,还会总结出关于雾霾的子话题有哪些、机构有哪些、人物有哪些。当然它也可以像搜索引擎一样提供详细的结果的列表。
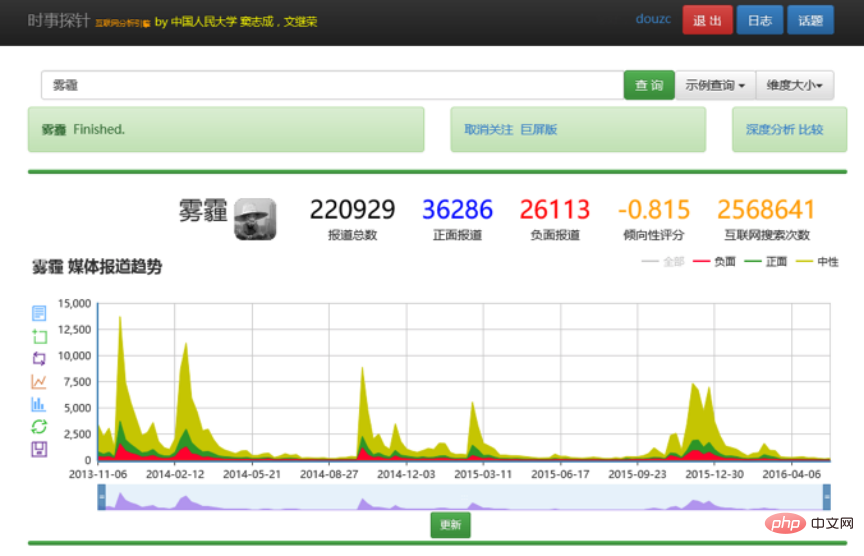
这种可以直接提供分析,而且是交互式分析的能力,能够更好地帮助用户获取复杂信息的能力。提供给用户的东西不再是简单的搜索结果列表。当然这种交互式的多维知识分析,只是一种展示方式,以后还可以做更多的方式,比如我们现在正在做的一件事情就是从检索到生成(有理有据的)内容。
现在的搜索引擎广泛采用以索引为核心的分阶段方式,从大量互联网的网页爬回所需内容后构建Index,也就是倒排的索引或稠密的向量索引。用户的Query来之后,先要做召回,在召回的结果基础上再做精细化排序。
这个模式有很多弊端,因为要分阶段,如果一个阶段上出了问题,例如在召回阶段没有找到想要的结果,它排序阶段做得再好,也不可能返回很好的结果。
在未来的搜索引擎中,这种结构有可能是会被打破的。全新的想法是使用一个大的模型来取代现在的索引的模式,所有的查询都可以通过模型来满足。这就不再需要使用索引了,而是直接通过这种模型反馈想要的结果。
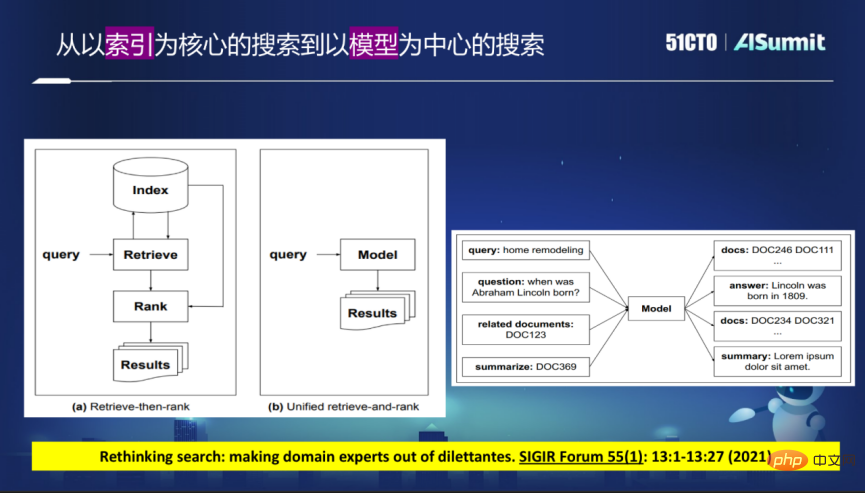
在这个基础上,可以直接提供结果列表,也可以直接提供用户所需的答案,甚至答案还可以是图像,将各模态更好的融合在一起。去掉索引,直接通过模型来反馈结果,就意味着这个模型能够直接return或者直接返回文档的标识符,文档标识符是一定要嵌入到模型中的,构建以模型为中心的搜索。
现在的搜索引擎广泛采用关键词为输入,文档列表为输出的这种简单模式。在满足人们复杂信息获取需求方面,已经存在了一些问题。未来的搜索引擎将会是对话式的、是个性化的、是以用户为中心的、是能够破除千人一面的。同时能够处理多模态的信息,能够处理知识、能够返回知识。在架构上,未来也一定会突破现有的采用倒排索引或者稠密向量索引的这种以索引为核心的模式,逐步过渡到以模型为核心的模式。
窦志成,中国人民大学高瓴人工智能学院副院长,北京智源人工智能研究院“智能信息检索与挖掘”方向项目经理。2008加入微软亚洲研究院,从事互联网搜索的相关工作,培养了丰富的信息检索技术研发经验。2014年开始在中国人民大学任教,主要研究方向为智能信息检索和自然语言处理。曾获国际信息检索大会(SIGIR 2013)最佳论文提名奖,亚洲信息检索大会(AIRS 2012)最佳论文奖,全国信息检索学术会议(CCIR 2018、CCIR 2021)最佳论文奖。担任SIGIR 2019的程序委员会主席(短文),信息检索评测会议NTCIR-16程序委员会主席,中国计算机学会大数据专家委员会副秘书长等职务。近两年主要关注个性化和多样化搜索排序、交互式和对话式搜索模型、面向信息检索的预训练方法、搜索和推荐模型的可解释性、个性化产品搜索等。
以上是未来,我们将如何进行信息搜索?的详细内容。更多信息请关注PHP中文网其他相关文章!





















