

嘉宾:谭中意
整理:千山
吴恩达曾在多个场合表达过AI已经从以模型为中心的研究范式向以数据为中心的研究范式转变,数据是AI落地最大的挑战。如何保证数据的高质量供给是关键问题,而要解决好这个问题,需要利用MLOps的实践、工具等,帮助AI多快好省的落地。
日前,在51CTO主办的 AISummit 全球人工智能技术大会上,开放原子基金会TOC副主席谭中意带来了主题演讲《从Model-Centric到Data-Centric——MLOps帮助AI多快好省的落地》,和与会者重点分享了MLOps的定义、MLOps能解决什么问题、常见的MLOps项目,以及如何评估一个AI团队MLOps的能力和水平。
现将演讲内容整理如下,希望对诸君有所启发。
当前,AI界有个趋势是——“从Model-Centric到Data-Centric”。具体是什么含义?首先来看一些来自科学界和工业界的分析。
吴恩达曾分享过演讲《MLOps:From Model-centric to Data-centric》,在硅谷引起了极大反响。在演讲中,他认为“AI= Code + Data”(此处Code包括模型和算法),通过提升Data而非Code来提升AI system。
具体来说,采用Model-Centric的方法,即保持数据不变,不断的调整模型算法,比如使用更多网络层,更多超参数调整等;而采用Data-Centric的方法,即保持模型不变,提升数据质量,比如改进数据标签,提高数据标注质量等。
对于同一个AI问题,改进代码还是改进数据,效果完全不同。
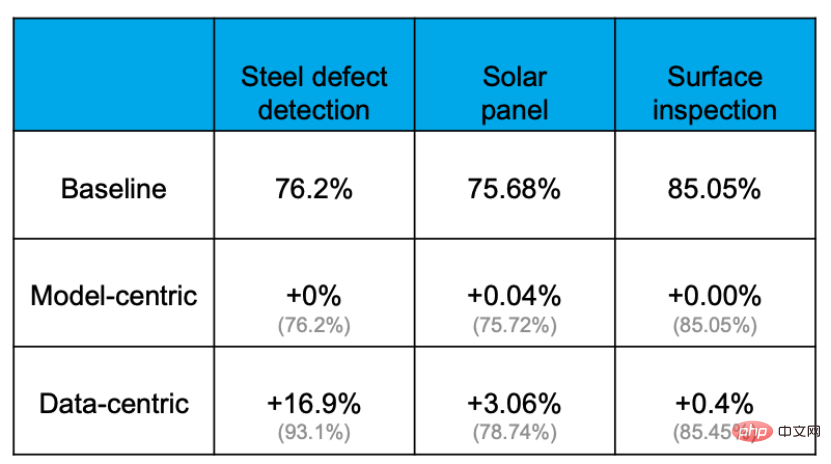
实证显示,通过Data-centricapproach能够有效提升准确率,而通过改进模型、更换模型能提升准确率的程度极为有限。例如,在如下钢板缺陷检测任务当中,baseline准确率为76.2%,各种换模型调参数的操作之后,对准确率几乎没有提升。但是对数据集的优化却将准确率提升了16.9%。其它项目的经验也证明了这点。
之所以会这样,是因为数据比想象中更重要。大家都知道“Data is Food for AI”。在一个真实的AI应用中,大概有80%的时间是处理跟数据相关的内容,其余20%则用来调整算法。这个过程就像烹饪,八成时间用来准备食材,对各种食材进行处理和调整,而真正的烹调可能只有大厨下锅的几分钟。可以说,决定一道菜是否美味的关键,在于食材和食材的处理。
在吴恩达看来,MLOps(即“Machine learning Engineering for Production”)最重要的任务就是在机器学习生命周期的各个阶段,包括数据准备、模型训练、模型上线,还有模型的监控和重新训练等等各个阶段,始终保持高质量的数据供给。
以上是AI科学家对MLOps的认识。接着来看一下AI工程师和业内分析师的一些观点。
首先从业内分析师看来,目前AI项目的失败率是惊人的高。2019年5月Dimensional Research调研发现,78%的AI项目最终没有上线;2019年6月,VentureBeat的报告发现,87%的AI项目没有部署到生成环境中。换句话说,虽然AI科学家、AI工程师做了很多工作,但是最终没有产生业务的价值。
为什么会产生这种结果?2015年在NIPS上发布的论文《Hidden Technical Debt in Machine Learning Systems》中提到,在一个真实上线的AI系统里面,包含了数据采集、验证、资源管理、特征抽取、流程管理、监控等诸多内容。但真正跟机器学习相关的代码,仅仅只占整个AI系统的5%,95%都是跟工程相关的内容,跟数据相关的内容。因此,数据是最重要的,也是最容易出错的。
数据对一个真实的AI系统的挑战主要在于以下几点:
以上列举的都是机器学习里面数据相关的一些挑战。此外,在现实生活中,实时数据会带来更大的挑战。
那么,对于一个企业来说,AI落地如何才能做到规模化?以大企业为例,它可能会有超过1000多个应用场景,同时有1500多个模型在线上跑,这么多模型如何支撑?在技术上怎么能够做到AI“多、快、好、省”的落地?
多:需要围绕关键业务的流程落地多个场景,对大企业来说可能是1000甚至上万的量级。
快:每个场景落地时间要短,迭代速度要快。比如推荐场景中,常常需要做到每天1次全量训练,每15分钟甚至每5分钟做到1次增量训练。
好:每个场景的落地效果都要达到预期,至少要比没有落地前强。
省:每个场景的落地成本比较节省,符合预期。
要真正做到“多、快、好、省”,我们需要MLOps。

在传统的软件开发领域,遇到上线慢、质量不稳定等类似问题,我们用DevOps来解决。DevOps大大提升了软件开发和上线的效率,促进了现代软件的快速迭代和发展。而在面临AI系统的问题时,我们可以借鉴DevOps领域的成熟经验去发展MLOps。所以如图所示,“Machine learning development+Modern software development”就变成了MLOps。
对于MLOps是什么,目前业界并没有标准定义。
上述说法都比较绕口,我个人对此的理解相对简单:MLOps是“Code+Model+Data”的持续集成、持续部署、持续训练和持续监控。
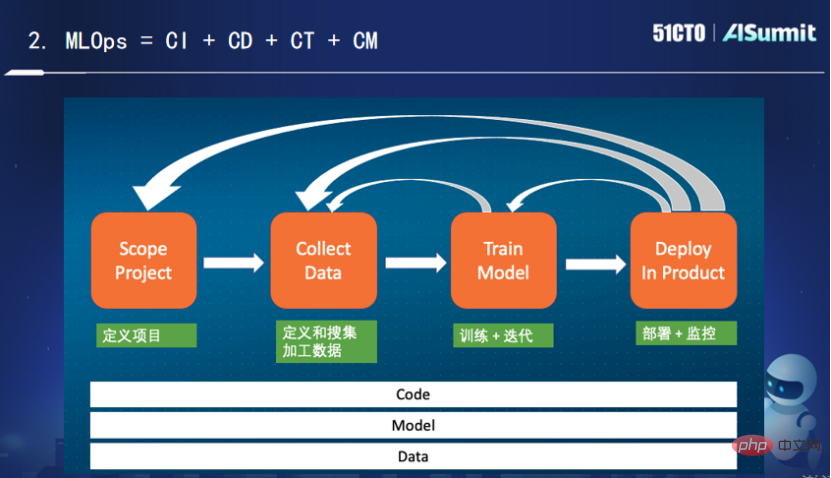
上图展示的是一个典型的机器学习的生命场景。定义项目阶段之后就开始定义和收集加工数据,就要观察对解决当前问题有帮助的数据究竟是哪些?要怎么加工,怎么做特征工程,怎么转换和存储。
收集完数据之后就开始进行模型的训练和迭代,需要不断调整算法,然后不断训练,最后得出一个符合预期的结果。如果对这个结果不满意,就需要返回上层,此时需要获取更多的数据,对数据进行更多的转换,之后再进行训练,循环往复,直到得出比较满意的模型算法出来,然后再开始部署到线上。
在部署和监控环节,如果模型效果不一致,这时候要观察训练和部署出了什么问题。在部署了一段时间后,可能会面临模型衰退的问题,此时就需要重新训练。甚至有时候在部署过程中发现数据有问题,此时就需要返回到数据处理这一层。更有甚者,部署效果远未达到项目预期,也可能需要返回初始原点。
可以看到,整个过程是一个循环迭代的过程。而对于工程实践来说,我们需要不断地持续集成、持续部署、持续训练、持续监控。其中持续训练和持续监控是MLOps所特有的。持续训练的作用在于,即使代码模型没有发生任何改变,也需要针对其数据改变进行持续训练。而持续监控的作用在于,不断监控数据和模型之间的匹配是否发生问题。这里的监控指的不仅是监控线上系统,更要监控系统跟机器学习相关的一些指标,如召回率、准确率等。综合来说,我认为MLOps其实就是代码、模型、数据的持续集成,持续部署,持续训练和持续监控。
当然,MLOps不仅仅只是流程和Pipeline,它还包括更大更多的内容。比如:
(1) 存储平台: 特征和模型的存储和读取
(2) 计算平台:流式、批处理用于特征处理
(3) 消息队列:用于接收实时数据
(4) 调度工具:各种资源(计算/存储)的调度
(5) Feature Store:注册、发现、共享各种特征
(6) Model Store:模型的特征
(7) Evaluation Store:模型的监控/ AB测试
Feature Store、Model store和Evaluation store都是机器学习领域中新兴的应用和平台,因为有时候线上会同时跑多个模型,要实现快速迭代,需要很好的基础设施来保留这些信息,从而让迭代更高效,这些新应用、新平台就应运而生。
下面简要介绍一下Feature Store,即特征平台。作为机器学习领域特有的平台,Feature Store具有很多特性。
第一,需要同时满足模型训练和预测的要求。特征数据存储引擎在不同的场景有着完全不同的应用需求。模型训练时需要扩展性好、存储空间大;实时预测则需要满足高性能、低延迟的要求。
第二,必须解决特征处理在训练时候和预测阶段不一致的问题。在模型训练时,AI科学家一般会使用Python脚本,然后用Spark或者SparkSQL来完成特征的处理。这种训练对延迟不敏感,在应付线上业务时效率较低,因此工程师会用性能较高的语言把特征处理的过程翻译一下。但翻译过程异常繁琐,工程师要反复跟科学家去校对逻辑是否符合预期。只要稍微不符合预期,就会带来线上和线下不一致的问题。
第三,需要解决特征处理中的重用问题,避免浪费,高效共享。在一家企业的AI应用中,经常会出现这一情况:同一个特征被不同的业务部门使用,数据源来自同一份日志文件,中间所做的抽取逻辑也是类似的,但因为是在不同的部门或不同的场景下使用,就不能复用,相当于同一份逻辑被执行了N遍,而且日志文件都是海量的,这对存储资源和计算资源都是巨大的浪费。
综上所述,Feature Store主要用于解决高性能的特征存储和服务、模型训练和模型预测的特征数据一致性、特征复用等问题,数据科学家可以使用Feature Store进行部署和共享。
目前市面上主流的特征平台产品,大致可分为三大类。
成熟度模型是用来衡量一个系统、一套规则的能力目标,在DevOps领域经常用成熟度模型来评估一个公司的DevOps能力。而在MLOps领域也有相应的成熟度模型,不过目前还没有形成规范。这里简要介绍一下Azure的关于MLOps的成熟度模型。
按照机器学习全流程的自动化程度的高低,把MLOps的成熟模型分成了(0,1,2,3,4)个等级,其中0是没有自动化的。(1,2,3)是部分自动化,4是高度自动化.

成熟度为0,即没有MLOps。这一阶段意味着数据准备是手动的,模型训练也是手动的,模训部署也都是手动的。所有的工作全都是手动完成,适合于一些把AI进行创新试点的业务部门来做。
成熟度为1,即有DevOps没有MLOps。其数据准备工作是自动完成的,但模型训练是手动完成的。科学家拿到数据之后进行各种调整和训练再完成。模型的部署也是手动完成的。
成熟度为2,即自动化训练。其模型训练是自动化完成的,简言之,当数据更新完了之后,立马启动类似的pipeline,进行自动化的训练,不过对训练结果的评估和上线还是由人工来完成。
成熟度为3,即自动化部署。模型自动化训练完成之后,对模型的评估和上线是自动完成的,不需要人工干涉。
成熟度为4,即自动化重训和部署。它在不断监控线上的模型,当发现Model DK发生线上模型能力退化的时候,会自动会触发重复训练。整个过程就全部自动化完成了,这就可以称之为成熟度最高的系统。
更多精彩内容见大会官网:点击查看
以上是谭中意:从Model-Centric到Data-Centric MLOps帮助AI多快好省的落地的详细内容。更多信息请关注PHP中文网其他相关文章!





















