

搜索召回作为搜索系统的基础,决定了效果提升的上限。如何在现有的海量召回结果中,继续带来有差异化的增量价值,是我们面临的主要挑战。而多模态预训练与召回的结合,为我们打开了新的视野,带来线上效果的显著提升。
多模态预训练是学术界与工业界研究的重点,通过在大规模数据上进行预训练,得到不同模态之间的语义对应关系,在多种下游任务如视觉问答、视觉推理、图文检索上能够提升效果。 在集团内部,多模态预训练也有一些研究与应用。 在淘宝主搜场景中,用户输入的Query与待召回商品之间存在天然的跨模态检索需求,只是以往对于商品更多地使用标题和统计特征,忽略了图像这样更加直观的信息。 但对于某些有视觉元素的Query(如白色连衣裙、碎花连衣裙),相信大家在搜索结果页都会先被图像所吸引。
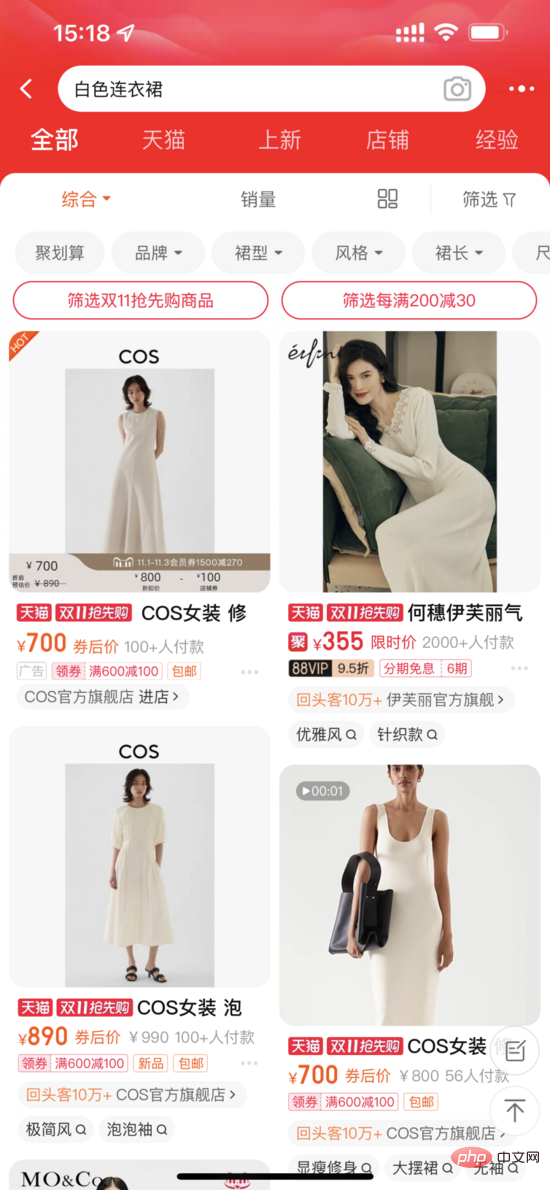

淘宝主搜场景
一方面是图像占据着更显著的位置,另一方面则是图像可能包含着标题所没有的信息,如白色、碎花这样的视觉元素。对于后者,需要区分两种情况:一种是标题中有信息、但由于显示限制无法完全展示,这种情况不影响商品在系统链路里的召回;另一种是标题中没有信息但图像中有,也就是图像相对于文本可以带来增量。后者是我们需要重点关注的对象。
在主搜召回场景中应用多模态技术,有两个主要问题需要解决:
我们的解决思路如下:
多模态预训练模型需要从图像中提取特征,再与文本特征融合。从图像中提取特征的方式主要有三种:使用CV领域训练好的模型提取图像的RoI特征、Grid特征和Patch特征。从模型结构来看,根据图像特征和文本特征融合方式的不同,主要有两类:单流模型或双流模型。在单流模型中,图像特征与文本特征在早期就拼接在一起输入Encoder,而在双流模型中,图像特征和文本特征分别输入到两个独立的Encoder,然后再输入到跨模态Encoder中进行融合。
我们提取图像特征的方式是:将图像划分为Patch序列,使用ResNet提取每个Patch的图像特征。在模型结构上,尝试过单流结构,也就是将Query、标题、图像拼接在一起输入Encoder。经过多组实验,我们发现在这种结构下,很难提取出纯粹的Query向量和Item向量作为下游双塔向量召回任务的输入。如果提取某一向量时,Mask掉不需要的模态,会使得预测与训练不一致。这个问题类似于,在一个交互型的模型里直接提取出双塔模型,根据我们的经验,这种模型的效果不如经过训练的双塔模型。基于此,我们提出了一种新的模型结构。
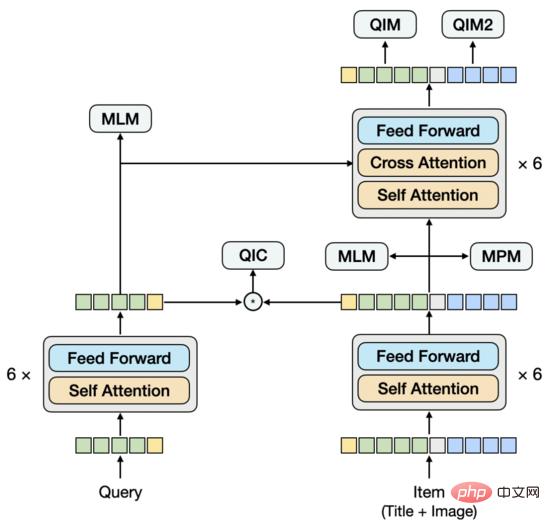
类似双流结构,模型下方由双塔构成,上方通过跨模态Encoder融合双塔。与双流结构不同的是,双塔不是分别由单一模态构成,其中的Item塔中包含了Title和Image图文双模态,Title和Image拼接在一起输入Encoder,这部分类似单流模型。为了建模Query与Title之间存在的语义联系与Gap,我们将Query和Item双塔的Encoder共享,再分别学习语言模型。
对于预训练来说,设计合适的任务也是比较关键的。我们尝试过常用的Title和Image的图文匹配任务,虽然能达到比较高的匹配度,但对于下游向量召回任务带来的增益很少,这是因为用Query去召回Item时,Item的Title和Image是否匹配不是关键因素。所以,我们在设计任务时,更多地考虑了Query与Item之间的关系。目前,一共采用5种预训练任务。
 其中 表示剩下的文本token
其中 表示剩下的文本token
 其中 表示剩下的图像token
其中 表示剩下的图像token
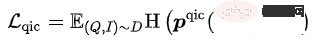 其中
其中  的计算可以采取多种方式:
的计算可以采取多种方式:
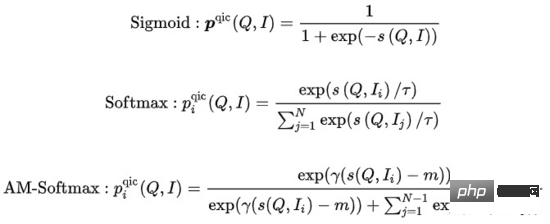
其中 表示相似度计算, 表示温度超参数, 和m分别表示缩放因子和松弛因子
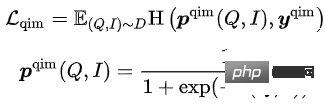
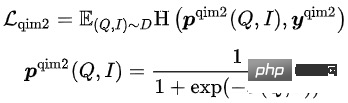
模型的训练目标为,最小化整体Loss:
在这5种预训练任务中,MLM任务和MPM任务位于Item塔的上方,建模Title或Image的部分Token被Mask后,使用跨模态信息相互恢复的能力。Query塔上方有独立的MLM任务,通过共享Query塔和Item塔的Encoder,建模Query与Title之间的语义联系与Gap。QIC任务使用双塔内积的方式,将预训练和下游向量召回任务做一定程度的对齐,并用AM-Softmax拉近Query的表示与Query下点击最多Item的表示之间的距离,推开Query与其他Item的距离。QIM任务位于跨模态Encoder的上方,使用跨模态信息建模Query和Item的匹配。出于计算量的考虑,采用通常NSP任务的正负样本比1:1,为了进一步推开正负样本之间的距离,基于QIC任务的相似度计算结果构造了难负样本。QIM2任务与QIM任务位于同样的位置,显式建模图像相对于文本带来的增量信息。
在大规模信息检索系统中,召回模型位于最底层,需要在海量的候选集中打分。出于性能的考虑,往往采用User和Item双塔计算向量内积的结构。向量召回模型的一个核心问题是:如何构造正负样本以及负样本采样的规模。我们的解决方法是:将用户在一个页面内的点击Item作为正样本,在全量商品池中根据点击分布采样出万级别的负样本,用Sampled Softmax Loss在采样样本中推导出Item在全量商品池中的点击概率。
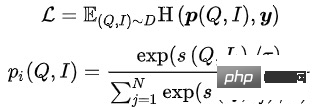
其中 表示相似度计算, 表示温度超参数
遵循常见的FineTune范式,我们尝试过将预训练的向量直接输入到双塔MLP,结合大规模负采样和Sampled Softmax来训练多模态向量召回模型。不过,与通常的小规模下游任务相反,向量召回任务的训练样本量巨大,在数十亿量级。我们观察到MLP的参数量无法支撑模型的训练,很快就会达到自身的收敛状态,但效果并不好。同时,预训练向量在向量召回模型中作为输入而不是参数,无法随着训练的进行得到更新。这样一来,在相对小规模数据上进行的预训练,与大规模数据上的下游任务有一定的冲突。
解决的思路有几种,一种方法是将预训练模型融合到向量召回模型中,但预训练模型的参数量过大,再加上向量召回模型的样本量,无法在有限的资源约束下,以合理的时间进行常态化训练。另一种方法是在向量召回模型中构造参数矩阵,将预训练向量载入到矩阵中,随着训练的进行更新矩阵的参数。经过调研,这种方式在工程实现上成本比较高。基于此,我们提出了简单可行地建模预训练向量更新的模型结构。
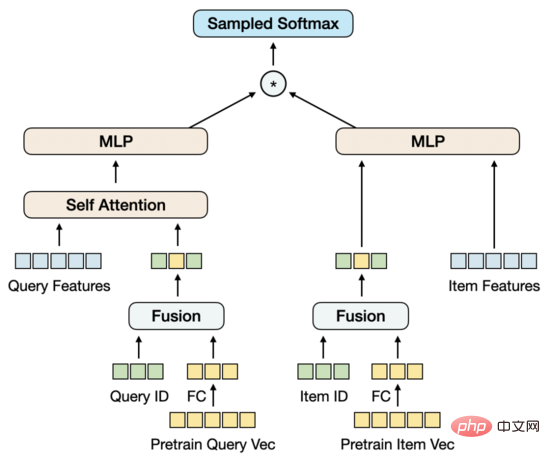
我们先将预训练向量通过FC降维,之所以在这里而不是在预训练中降维,是因为目前的高维向量对于负样本采样来说还在可接受的性能范围内,这种情况下,在向量召回任务中降维是与训练目标更一致的。同时,我们引入Query和Item的ID Embedding矩阵,Embedding维度与降维后的预训练向量的维度保持一致,再将ID与预训练向量融合在一起。这个设计的出发点是:引入足以支撑大规模训练数据的参数量,同时使预训练向量随着训练的进行得到适应性地更新。
在只用ID和预训练向量融合的情况下,模型的效果不仅超过了只用预训练向量的双塔MLP的效果,也超过了包含更多特征的Baseline模型MGDSPR。更进一步,在这个基础上引入更多的特征,可以继续提升效果。
对于预训练模型的效果,通常是用下游任务的指标来评测,而很少用单独的评测指标。但这样一来,预训练模型的迭代成本会比较高,因为每迭代一个版本的模型都需要训练对应的向量召回任务,再评测向量召回任务的指标,整个流程会很长。有没有单独评测预训练模型的有效指标?我们首先尝试了一些论文中的Rank@K,这个指标主要是用来评测图文匹配任务:先用预训练模型在人工构造的候选集中打分,再计算根据分数排序后的Top K结果命中图文匹配正样本的比例。我们直接将Rank@K套用在Query-item匹配任务上,发现结果不符合预期,一个Rank@K更好的预训练模型,在下游的向量召回模型中可能会获得更差的效果,无法指导预训练模型的迭代。基于此,我们将预训练模型的评测与向量召回模型的评测统一起来,采用相同的评测指标及流程,可以相对有效地指导预训练模型的迭代。
Recall@K :评测数据集由训练集的下一天数据构成,先将同一个Query下不同用户的点击、成交结果聚合成 ,再计算模型预测的Top K结果 命中 的比例:
,再计算模型预测的Top K结果 命中 的比例:
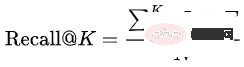
在模型预测Top K结果的过程中,需要从预训练/向量召回模型中提取Query和Item向量,使用近邻检索得到一个Query下的Top K个Item。通过这个流程模拟线上引擎中的向量召回,来保持离线与在线的一致性。对于预训练模型来说,这个指标与Rank@K的区别是:在模型中提取Query和Item向量进行向量内积检索,而不是直接用模态融合后的模型来打分;另外,一个Query下不仅要召回与之匹配的Item,还要召回这个Query下不同用户的点击、成交Item。
对于向量召回模型,在Recall@K提高到一定程度后,也需要关注Query和Item之间的相关性。一个相关性差的模型,即使能提高搜索效率,也会面临Bad Case增加导致的用户体验变差和投诉舆情增多。 我们采用与线上相关性模型一致的离线模型,评测Query和Item之间以及Query和Item类目之间的相关性。
我们选取部分类目下1亿量级的商品池,构造了预训练数据集。
我们的Baseline模型是经过优化的FashionBert,加入了QIM和QIM2任务,提取Query和Item向量时采用只对非Padding Token做Mean Pooling的方式。以下实验探索了以双塔方式建模,相对于单塔带来的增益,并通过消融实验给出关键部分的作用。

从这些实验中,我们能得出如下结论:
我们选取10亿量级有点击的页面,构造了向量召回数据集。在每个页面中包含3个点击Item作为正样本,从商品池中根据点击分布采样出1万量级的负样本。在此基础上,进一步扩大训练数据量或负样本采样量,没有观察到效果的明显提升。
我们的Baseline模型是主搜的MGDSPR模型。以下实验探索了将多模态预训练与向量召回结合,相对于Baseline带来的增益,并通过消融实验给出关键部分的作用。
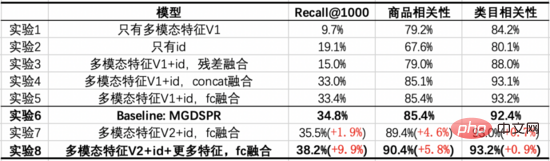
从这些实验中,我们能得出如下结论:
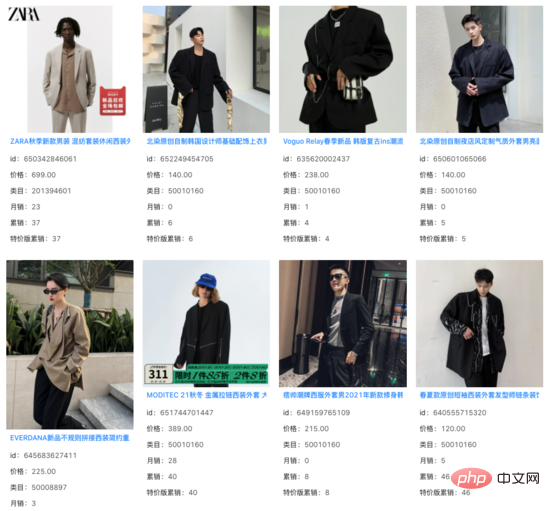
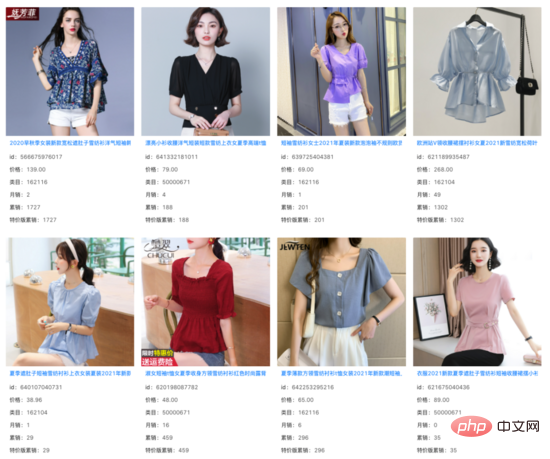
我们在向量召回模型的Top 1000结果中,过滤掉线上系统已经能召回的Item,发现其余增量结果的相关性基本不变。在大量Query下,我们看到这些增量结果捕捉 到了商品Title之外的图像信息,并对Query和Title之间存在的语义Gap起到了一定的作用。
query: 痞帅西装
query: 女掐收腰小衫
针对主搜场景的应用需求,我们提出了文本-图文预训练模型,采用了Query和Item双塔输入跨模态Encoder的结构,其中Item塔是包含图文多模态的单流模型。通过Query-Item和Query-Image匹配任务,以及Query和Item双塔内积方式建模的Query-Item多分类任务,使预训练更接近下游的向量召回任务。同时,在向量召回中建模了预训练向量的更新。在资源有限的情况下,使用相对少量数据的预训练,对使用海量数据的下游任务仍然带来了效果的提升。
在主搜的其他场景中,如商品理解、相关性、排序,也存在应用多模态技术的需求。我们也参与到了这些场景的探索中,相信多模态技术在未来会给越来越多的场景带来增益。
淘宝主搜召回团队:团队负责主搜链路中的召回、粗排环节,目前的主要技术方向为基于全空间样本的多目标个性化向量召回、基于大规模预训练的多模态召回、基于对比学习的相似Query语义改写以及粗排模型等。
以上是多模态技术在淘宝主搜召回场景的探索的详细内容。更多信息请关注PHP中文网其他相关文章!





















