

arXiv论文“JPerceiver: Joint Perception Network for Depth, Pose and Layout Estimation in Driving Scenes“,上传于22年7月,报道关于澳大利亚悉尼大学陶大程教授和北京京东研究院的工作。

深度估计、视觉测程计(VO)和鸟瞰图(BEV)场景布局估计是驾驶场景感知的三个关键任务,这是自主驾驶中运动规划和导航的基础。虽然相互补充,但通常侧重于单独的任务,很少同时处理这三个任务。
一种简单的方法是以顺序或并行的方式独立地完成,但有三种缺点,即1)深度和VO结果受到固有的尺度多义问题的影响;2) BEV布局通常单独估计道路和车辆,而忽略显式叠加-下垫关系;3)虽然深度图是用于推断场景布局的有用几何线索,但实际上直接从前视图图像预测BEV布局,并没有使用任何深度相关信息。
本文提出一种联合感知框架JPerceiver来解决这些问题,从单目视频序列中同时估计尺度-觉察深度、VO以及BEV布局。用跨视图几何变换(cross-view geometric transformation,CGT),根据精心设计的尺度损失,将绝对尺度从道路布局传播到深度和VO。同时,设计一个跨视图和模态转换(cross-view and cross-modal transfer,CCT)模块,用深度线索通过注意机制推理道路和车辆布局。
JPerceiver以端到端的多任务学习方式进行训练,其中CGT尺度损失和CCT模块促进任务间知识迁移,利于每个任务的特征学习。
代码和模型可下载https://github.com/sunnyHelen/JPerceiver.
如图所示,JPerceiver分别由深度、姿态和道路布局三个网络组成,都基于编码器-解码器架构。深度网络旨在预测当前帧It的深度图Dt,其中每个深度值表示3D点与摄像头之间的距离。姿态网络的目标是预测在当前帧It及其相邻帧It+m之间姿态变换Tt→t+m。道路布局网络的目标是估计当前帧的BEV布局Lt,即俯视笛卡尔平面中道路和车辆的语义占用率。这三个网络在训练期间联合优化。
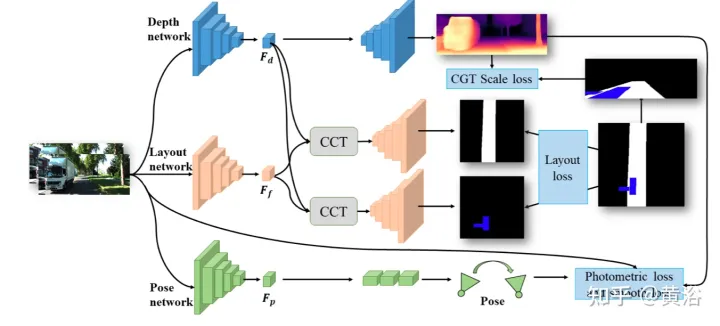
预测深度和姿态的两个网络以自监督方式用光度损失和平滑度损失进行联合优化。此外,还设计CGT尺度损失来解决单目深度和VO估计的尺度多义问题。
为实现尺度-觉察的环境感知,用BEV布局中的尺度信息,提出CGT的尺度损失用于深度估计和VO。由于BEV布局显示了BEV笛卡尔平面中的语义占用,分别覆盖自车前面Z米和左右(Z/2)米的范围。其提供一个自然距离场(natural distance field)z,每个像素相对于自车的度量距离zij,如图所示:
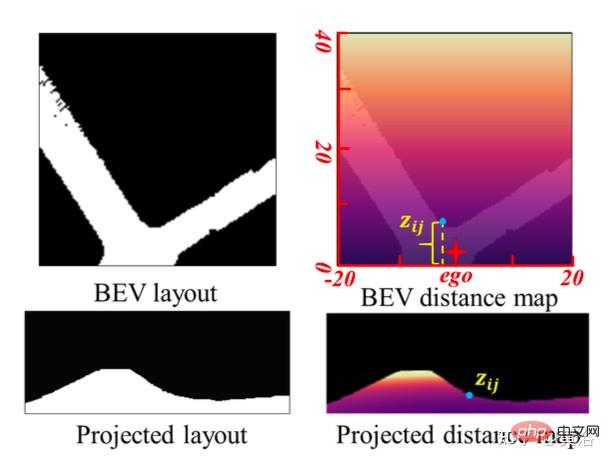
假设BEV平面是地面,其原点刚好在自车坐标系原点下面,基于摄像机外参可以通过单应性变换将BEV平面投影到前向摄像头。因此,BEV距离场z可以投影到前向摄像头中,如上图所示,用它来调节预测深度d,从而导出CGT尺度损失:
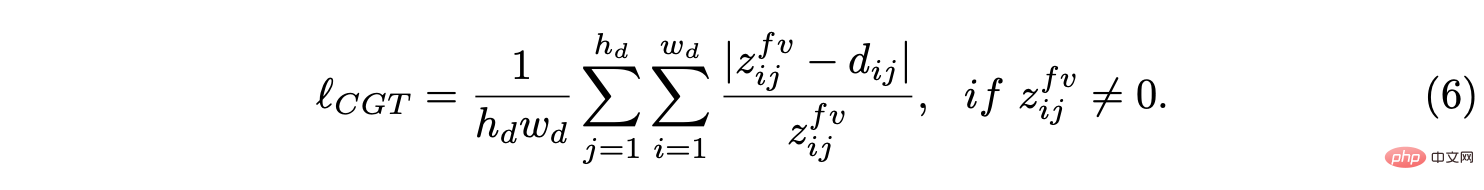
对于道路布局估计,采用了编码器-解码器网络结构。值得注意的是,用一个共享编码器作为特征提取器和不同的解码器来同时学习不同语义类别的BEV布局。此外,设CCT模块,以加强任务之间的特征交互和知识迁移,并为BEV的空间推理提供3-D几何信息。为了正则化道路布局网络,将各种损失项组合在一起,形成混合损失,并实现不同类的平衡优化。
CCT是研究前向视图特征Ff、BEV布局特征Fb、重转换的前向特征Ff′和前向深度特征FD之间的相关性,并相应地细化布局特征,如图所示:分两部分,即跨视图模块和跨模态模块的CCT-CV和CCT-CM。
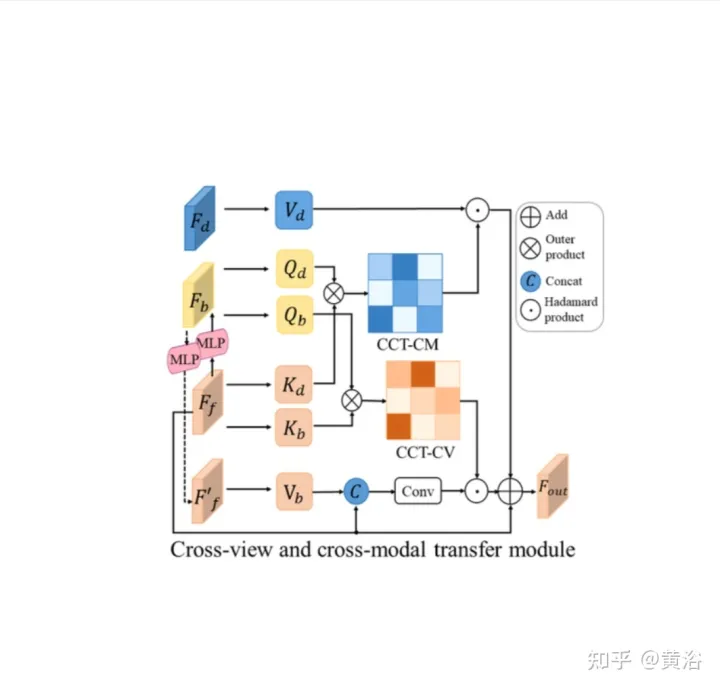
在CCT中,Ff和Fd由相应感知分支的编码器提取,而Fb通过一个视图投影MLP将Ff转换为BEV获得,一个循环损失约束的相同MLP将其重新转换为Ff′。
在CCT-CV,交叉注意机制用于发现前向视图和BEV特征之间的几何对应关系,然后指导前向视图信息的细化,并为BEV推理做好准备。为了充分利用前向视图图像特征,将Fb和Ff投影到patches:Qbi和Kbi,分别作为query和 key。
除了利用前向视图特征外,还部署CCT-CM来施加来自Fd的3-D几何信息。由于Fd是从前向视图图像中提取的,因此以Ff为桥来减少跨模态间隙并学习Fd和Fb之间的对应关系是合理的。Fd起Value的作用,由此获得与BEV信息相关有价值的3-D几何信息,并进一步提高道路布局估计的准确性。
在探索同时预测不同布局的联合学习框架过程中,不同语义类别的特征和分布存在很大差异。对于特征,驾驶场景中的道路布局通常需要连接,而不同的车辆目标必须分割。
对于分布,观察到的直线道路场景比转弯场景多,这在真实数据集中是合理的。这种差异和不平衡增加了BEV布局学习的难度,尤其是联合预测不同类别,因为在这种情况下,简单的交叉熵(CE)损失或L1损失会失效。将几种分割损失(包括基于分布的CE损失、基于区域的IoU损失和边界损失)合并为混合损失,预测每个类别的布局。
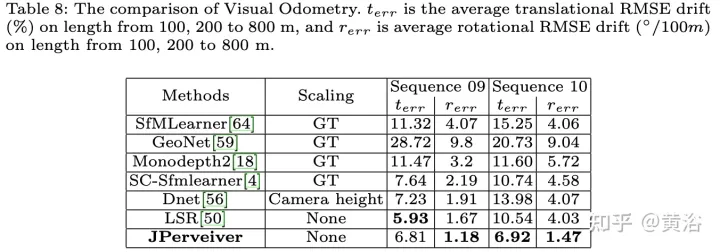
实验结果如下:
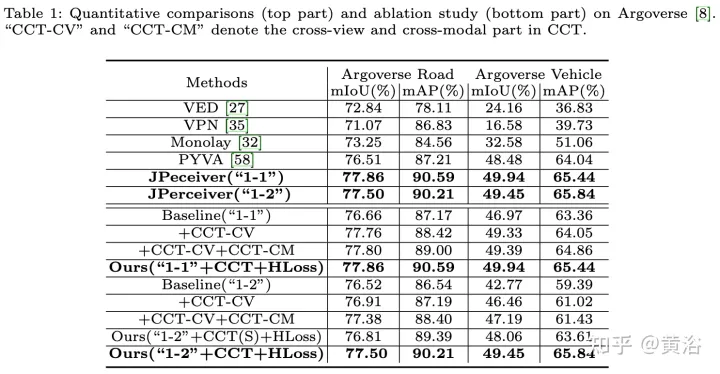
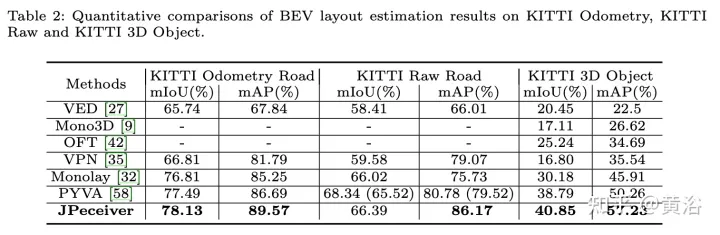
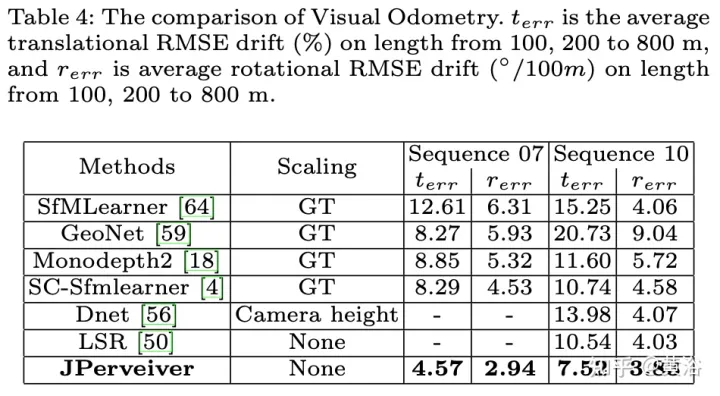
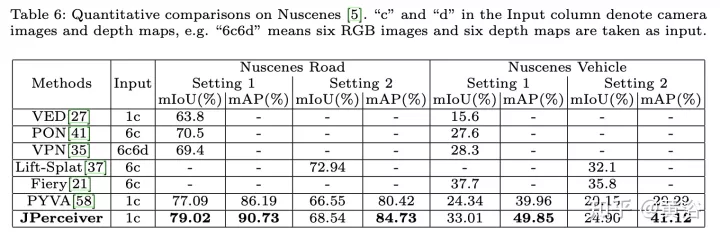
以上是联合驾驶场景中深度、姿态和道路估计的感知网络的详细内容。更多信息请关注PHP中文网其他相关文章!





















