

过去十年,学术和商业机器翻译系统(MT)的质量已经得到了大幅度的提升。这些提升很大程度上得益于机器学习的进展和可用的大规模 web 挖掘数据集。同时,深度学习(DL)和 E2E 模型的出现、从 web 挖掘得到的大型并行单语言数据集、回译和自训练等数据增强方法以及大规模多语言建模等带来了能够支持超过 100 种语言的高质量机器翻译系统。
然而,虽然低资源机器翻译出现了巨大进展,但已经构建广泛可用且通用的机器翻译系统的语言被限制在了大约 100 种,显然它们只是当今全世界使用的 7000 多种语言中的一小部分。除了语言数量受限之外,当前机器翻译系统所支持的语言的分布也极大地向欧洲语言倾斜。
我们可以看到,尽管人口众多,但非洲、南亚和东南亚所说的语言以及美洲土著语言相关的服务却较少。比如,谷歌翻译支持弗里西亚语、马耳他语、冰岛语和柯西嘉语,以它们为母语的人口均少于 100 万。相比之下,谷歌翻译没有提供服务的比哈尔方言人口约为 5100 万、奥罗莫语人口约为 2400 万、盖丘亚语人口约为 900 万、提格里尼亚语人口约为 900 万(2022 年)。这些语言被称为「长尾」语言,数据缺乏需要应用一些可以泛化到拥有充足训练数据的语言之外的机器学习技术。
构建这些长尾语言的机器翻译系统在很大程度上受到可用数字化数据集和语言识别(LangID)模型等 NLP 工具缺失的限制。这些对高资源语言来说却是无处不在的。
在近日谷歌一篇论文《Building Machine Translation Systems for the Next Thousand Languages》中,二十几位研究者展示了他们努力构建支持超过 1000 种语言的实用机器翻译系统的成果。

论文地址:https://arxiv.org/pdf/2205.03983.pdf
具体而言,研究者从以下三个研究领域描述了他们的成果。
第一,通过用于语言识别的半监督预训练以及数据驱动的过滤技术,为 1500 + 语言创建了干净、web 挖掘的数据集。
第二,通过用于 100 多种高资源语言的、利用监督并行数据训练的大规模多语言模型以及适用于其他 1000+ 语言的单语言数据集,为服务水平低下的语言创建了切实有效的机器翻译模型。
第三,研究这些语言的评估指标存在哪些局限,并对机器翻译模型的输出进行定性分析,并重点关注这类模型的几种常见的误差模式。
对于致力于为当前研究不足的语言构建机器翻译系统的从业者,研究者希望这项工作可以为他们提供有用的洞见。此外,研究者还希望这项工作可以引领人们聚焦那些弥补数据稀疏设置下大规模多语言模型弱点的研究方向。
在 5 月 12 日的 I/O 大会上,谷歌宣布自家的翻译系统新增了 24 种新的语言,其中包括一些小众的美洲原住民语言,比如前文提到的比哈尔方言、奥罗莫语、盖丘亚语和提格里尼亚语。

这项工作主要分为四大章节展开,这里只对每个章节的内容进行简要介绍。
本章详细介绍了研究者在为 1500 + 语言爬取单语言文本数据集的过程中采用的方法。这些方法重点在于恢复高精度数据(即高比例的干净、语言内文本),因此很大一部分是各种各样的过滤方法。
总的来说,研究者采用的方法包括如下:
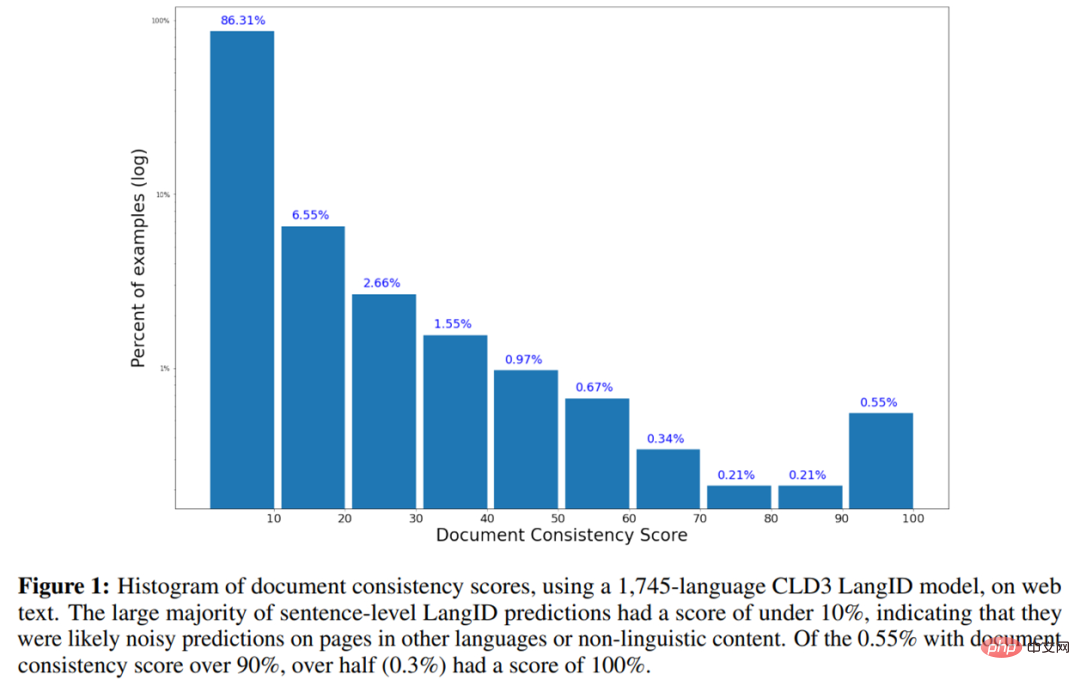
如下为使用 1745-language 的 CLD3 LangID 模型在 web 文本上的文档一致性得分直方图。
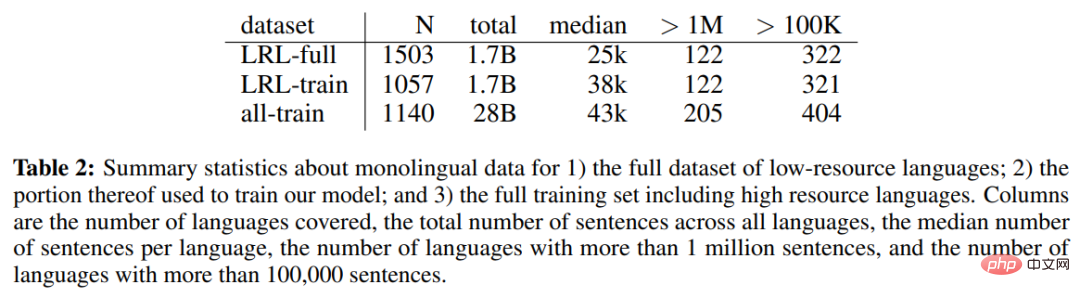
下表 2 为低资源语言(LRL)完整数据集的单语言数据、用于训练模型的部分单语言数据以及包括高资源语言在内的完整训练集的单语言数据统计。
章节目录如下:

对于从 web 挖掘的单语言数据,下一个挑战是从数量有限的单语言训练数据中创建高质量的通用机器翻译模型。为此,研究者采用了这样一种实用方法,即利用所有可用于更高资源语言的并行数据来提升只有单语言数据可用的长尾语言的质量。他们将这一设置称为「零资源」(zero-resource),这是因为长尾语言没有直接的监督。
研究者利用过去几年为机器翻译开发的几种技术来提升长尾语言零资源翻译的质量。这些技术包括从单语言数据中进行自监督学习、大规模多语言监督学习、大规模回译和自训练、高容量模型。他们利用这些工具创建了能够翻译 1000 + 种语言的机器翻译模型,并利用现有覆盖大约 100 种语言的并行语料库和从 web 中构建的 1000-language 的单语言数据集。
具体地,研究者首先通过比较 15 亿和 60 亿参数 Transformers 在零资源翻译上的性能来强调模型容量在高度多语言模型中的重要性(3.2),然后将自监督语言的数量增加到 1000 种,验证了随着来自相似语言中更多单语言数据变得可用,大多数长尾语言的性能也相应提高(3.3)。虽然研究者的 1000-language 模型表现出了合理的性能,但为了了解使用方法的优点和局限性,他们融入了大规模数据增强。
此外,研究者通过自训练和回译对包含大量合成数据的 30 种语言的子集上的生成模型进行微调(3.4)。他们进一步描述了过滤合成数据的实用方法以增强这些微调模型对幻觉(hallucinations)和错误语言翻译的稳健性(3.5)。
研究者还使用序列级蒸馏将这些模型提炼成更小、更易于推理的架构,并强调了教师和学生模型之间的性能差距(3.6)。
章节目录如下:

为了评估自己的机器翻译模型,研究者首先将英文句子翻译成了这些语言,为选择的 38 种长尾语言构建了一个评估集(4.1)。他们强调了 BLEU 在长尾设置中的局限性,并使用 CHRF 评估这些语言(4.2)。
研究者还提出了一个近似的、基于往返(round-trip)翻译的无参考指标,用来了解模型在参考集不可用的语言上的质量,并报告了以该指标衡量的模型的质量(4.3)。他们对模型在 28 种语言的子集上进行人工评估并报告了结果,确认可以按照文中描述的方法构建有用的机器翻译系统(4.4)。
为了了解大规模多语言零资源模型的弱点,研究者在几种语言上进行了定性误差分析。结果发现,模型经常混淆在分布上相似的单词和概念,比如「老虎」变成了「小型鳄鱼」(4.5)。并且在更低资源的设置下(4.6),模型翻译 tokens 的能力在出现频率降低的 tokens 上下降。
研究者还发现,这些模型通常无法准确地翻译短的或者单个单词输入(4.7)。对提炼模型的研究结果表明,所有模型都更有可能放大训练数据中存在的偏见或噪声(4.8)。
章节目录如下:

研究者对上述模型进行了一些额外的实验,表明它们在相似语言之间直接进行翻译通常效果更好,而不使用英语作为支点(5.1),并且它们可以用于不同 scripts 之间的零样本音译(5.2)。
他们描述了一种将终端标点符号附加到任何输入的实用技巧,称为「句号技巧」(period trick),可以用它来提升翻译质量(5.3)。
此外,研究者还证明了这些模型对一些而不是所有语言的非标准 Unicode 字形使用都是稳健的(5.4),并探索了几种 non-Unicode 字体(5.5)。
章节目录如下:

想要了解更多研究细节,请参考原论文。
以上是谷歌为1000+「长尾」语言创建机器翻译系统,已支持部分小众语言的详细内容。更多信息请关注PHP中文网其他相关文章!





















