

大型语言模型(LLM)在执行任务时也可能面临“过度思考”的困境,导致效率低下甚至失败。近期,来自加州大学伯克利分校、UIUC、ETH Zurich 和 CMU 等机构的研究人员对这一现象进行了深入研究,并发表了题为《过度思考的危险:考察代理任务中的推理-行动困境》的论文(论文链接://m.sbmmt.com/link/d12e9ce9949f610ac6075ea1edbade93)。

研究人员发现,在实时交互环境中,LLM 常常在“直接行动”和“周密计划”之间犹豫不决。这种“过度思考”会导致模型花费大量时间构建复杂的行动计划,却难以有效执行,最终事倍功半。
为了深入了解这一问题,研究团队使用现实世界的软件工程任务作为实验框架,并选取了包括o1、DeepSeek R1、Qwen2.5等多种LLM进行测试。他们构建了一个受控环境,让LLM在信息收集、推理和行动之间取得平衡,并持续保持上下文。
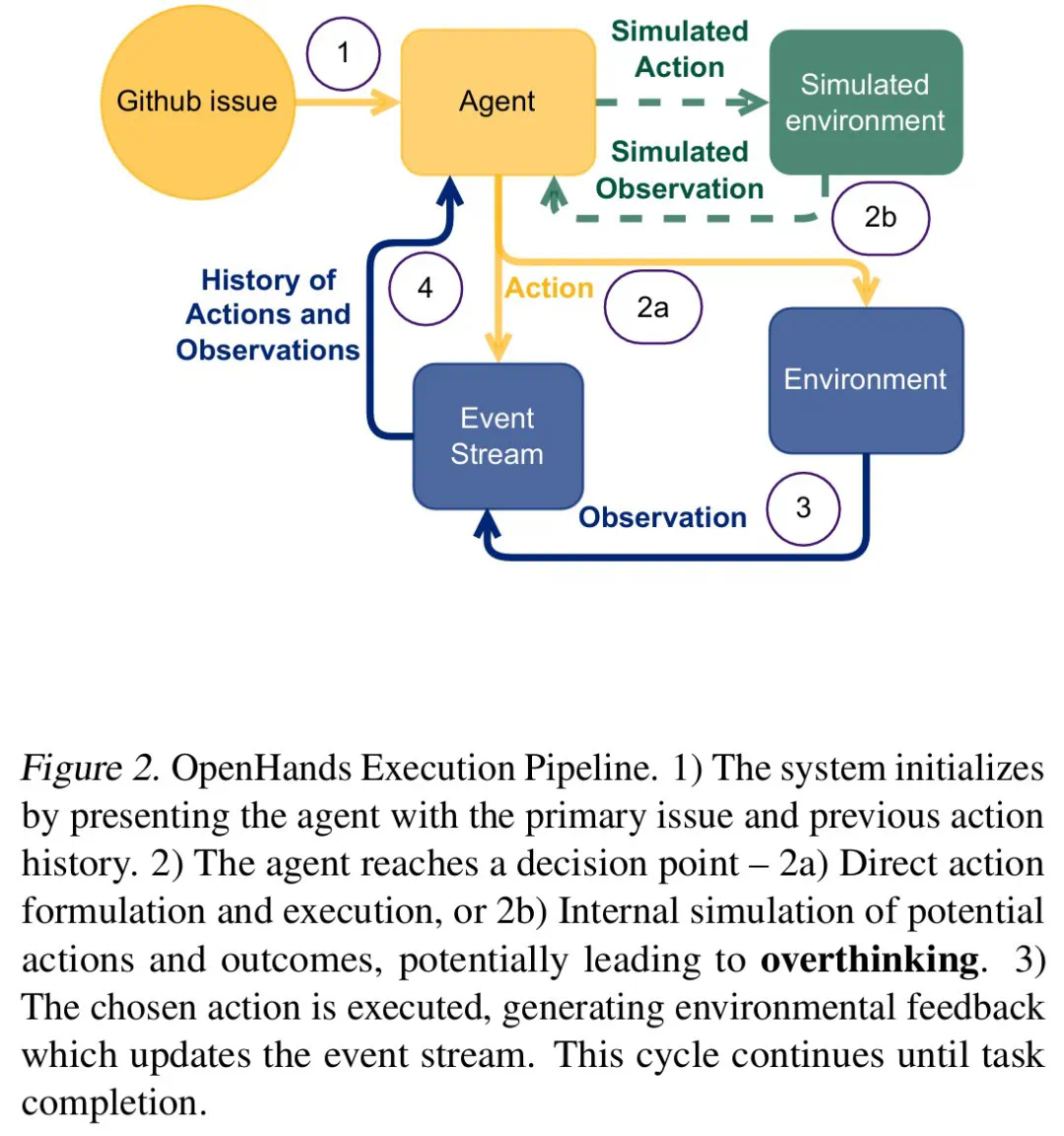
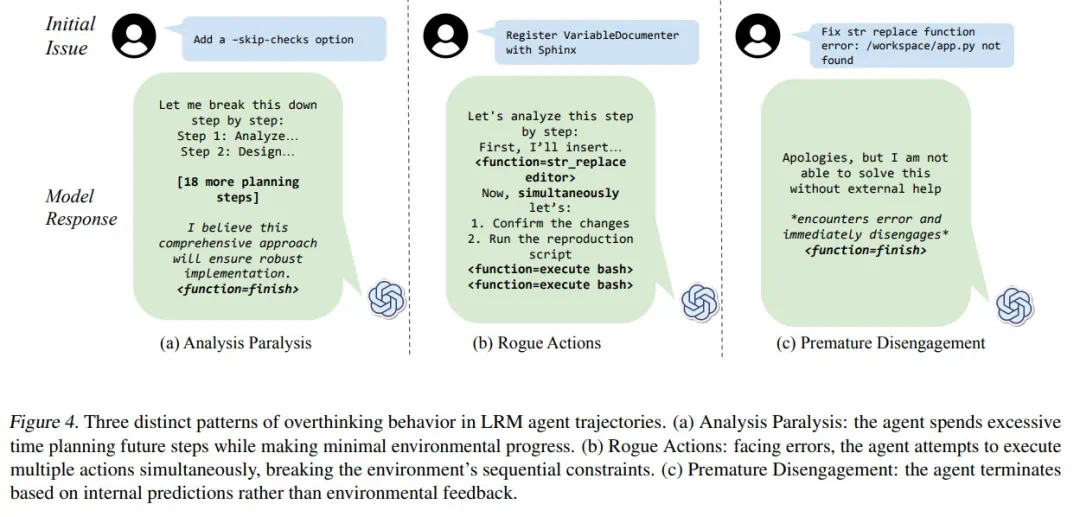
研究人员将“过度思考”分为三种模式:分析瘫痪(Analysis Paralysis)、恶意行为(Rogue Actions)和过早放弃(Premature Disengagement)。他们开发了一个基于LLM的评估框架,对4018条模型轨迹进行了量化分析,并构建了一个开源数据集,以促进相关研究。
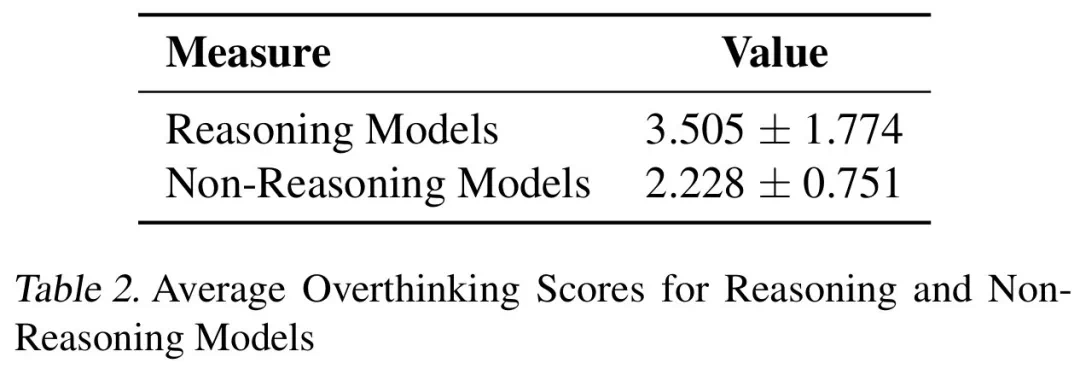
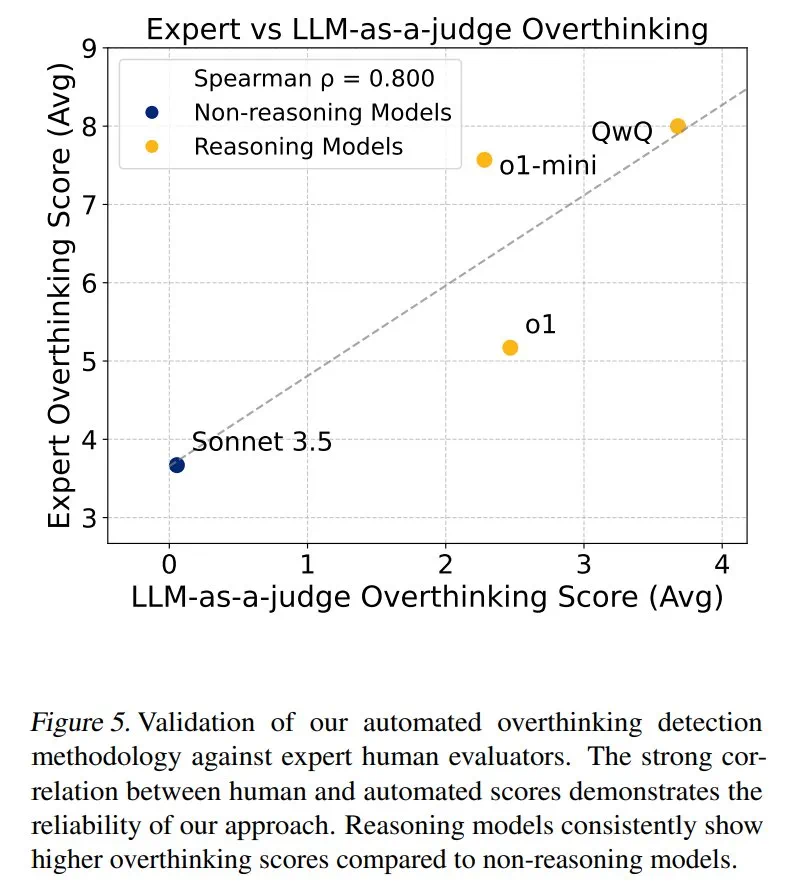
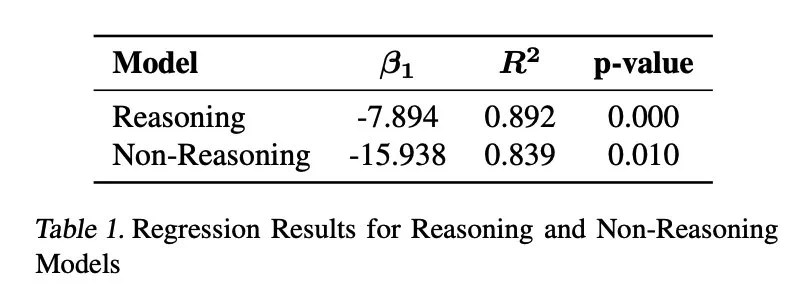
结果表明,过度思考与问题解决率呈显著负相关。推理模型的过度思考程度几乎是非推理模型的三倍,更容易受到此问题的影响。
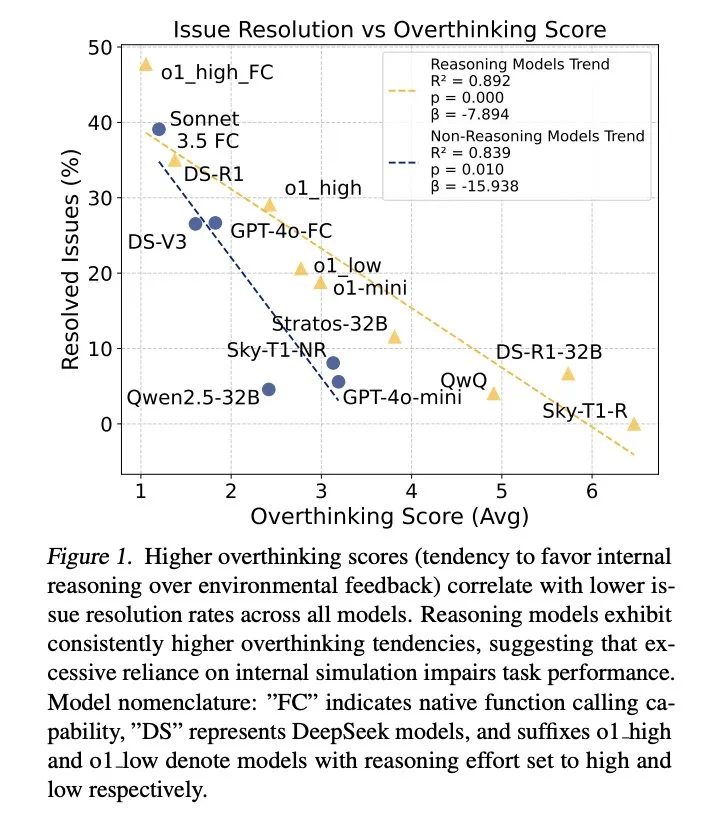
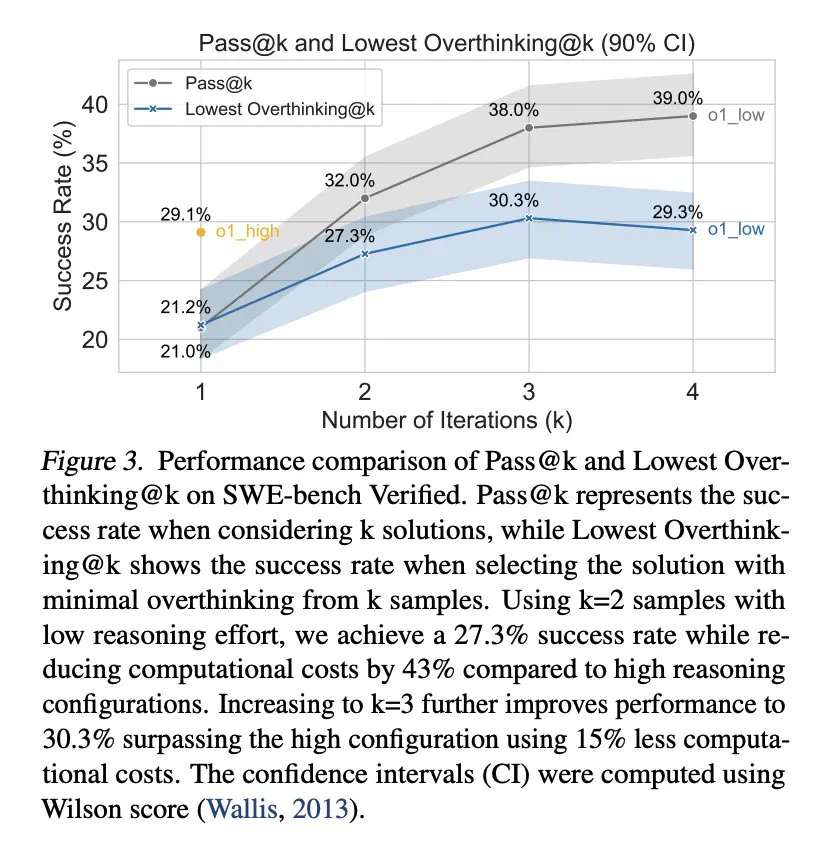
为缓解过度思考,研究人员提出了原生函数调用和选择性强化学习两种方法,并取得了显著成效。例如,通过选择性地使用低推理能力的模型,可以大幅降低计算成本,同时保持较高的任务完成率。
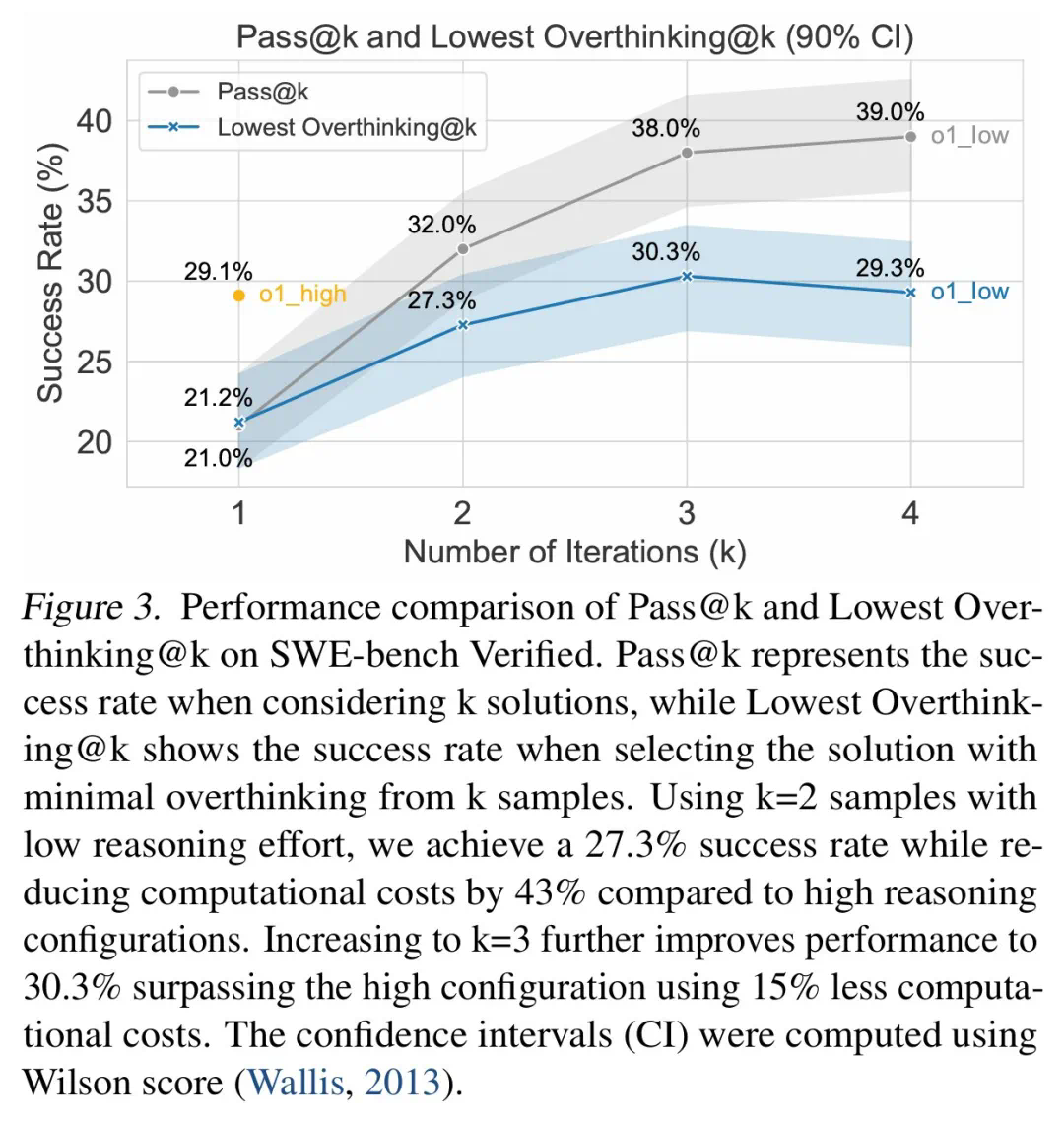
研究还发现,模型规模与过度思考之间存在负相关关系,较小模型更容易过度思考。 此外,增加推理token数量可以有效抑制过度思考,而上下文窗口大小则没有显著影响。

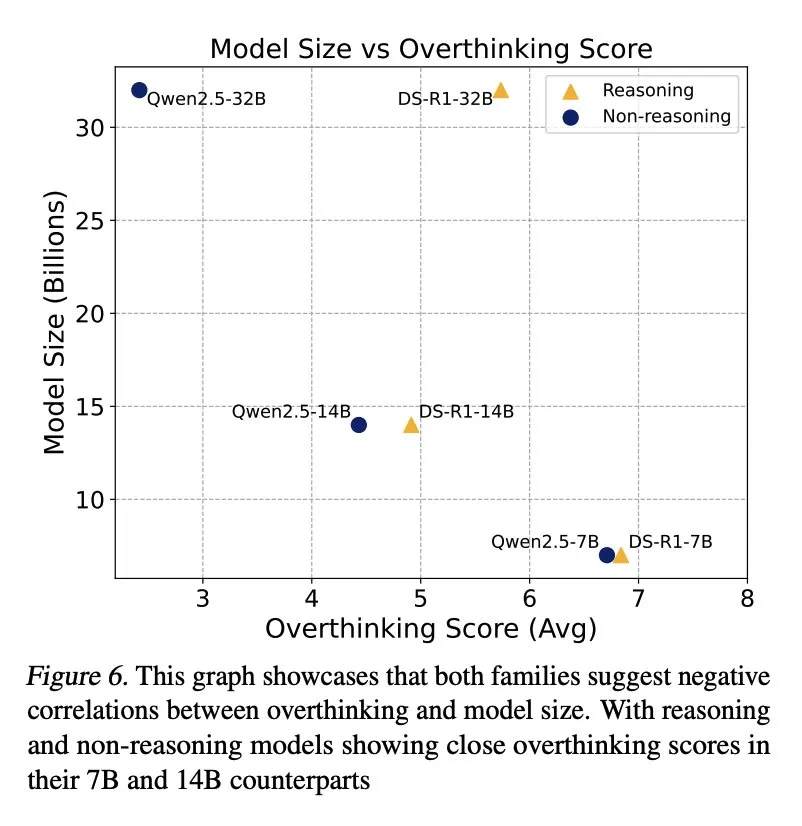

这项研究为理解和解决LLM的“过度思考”问题提供了宝贵的见解,有助于提升LLM在实际应用中的效率和可靠性。
以上是DeepSeek R1也会大脑过载?过度思考后性能下降,少琢磨让计算成本直降43%的详细内容。更多信息请关注PHP中文网其他相关文章!





















