


编辑 | KX
在药物研发领域,准确有效地预测蛋白质与配体的结合亲和力对于药物筛选和优化至关重要。然而,目前的研究没有考虑到分子表面信息在蛋白质-配体相互作用中的重要作用。
基于此,来自厦门大学的研究人员提出了一种新颖的多模态特征提取(MFE)框架,该框架首次结合了蛋白质表面、3D 结构和序列的信息,并使用交叉注意机制进行不同模态之间的特征对齐。
实验结果表明,该方法在预测蛋白质-配体结合亲和力方面取得了最先进的性能。此外,消融研究证明了该框架内蛋白质表面信息和多模态特征对齐的有效性和必要性。
相关研究以「Surface-based multimodal protein–ligand binding affinity prediction」为题,于 6 月 21 日发布在《Bioinformatics》上。

作为药物发现的关键阶段,预测蛋白质-配体结合亲和力,长期以来得到了广泛的研究,这对于高效、准确的药物筛选至关重要。
传统的计算机辅助药物发现工具使用评分函数(SF)粗略估计蛋白质-配体结合亲和力,但准确性较低。分子动力学模拟方法可以提供更准确的结合亲和力估计,但通常成本高昂且耗时。
随着计算技术的发展和大规模生物数据的日益丰富,基于深度学习的方法在蛋白质-配体结合亲和力预测领域显示出巨大的潜力。
然而,目前的研究主要利用基于序列或结构的表示来预测蛋白质-配体的结合亲和力,对蛋白质-配体相互作用至关重要的蛋白质表面信息的研究相对较少。
分子表面是蛋白质结构的高级表示,它表现出化学和几何特征模式,可作为蛋白质与其他生物分子相互作用模式的指纹。因此,一些研究开始使用蛋白质表面信息来预测蛋白质-配体结合亲和力。
但现有的方法主要关注单模态数据,忽略了蛋白质的多模态信息。此外,在处理蛋白质的多模态信息时,传统方法通常以直接的方式连接来自不同模态的特征,而不考虑它们之间的异质性,这导致无法有效利用模态之间的互补性。
在此,研究人员提出了一种新颖的多模态特征提取 (MFE) 框架,该框架首次结合了来自蛋白质表面、3D 结构和序列的信息。
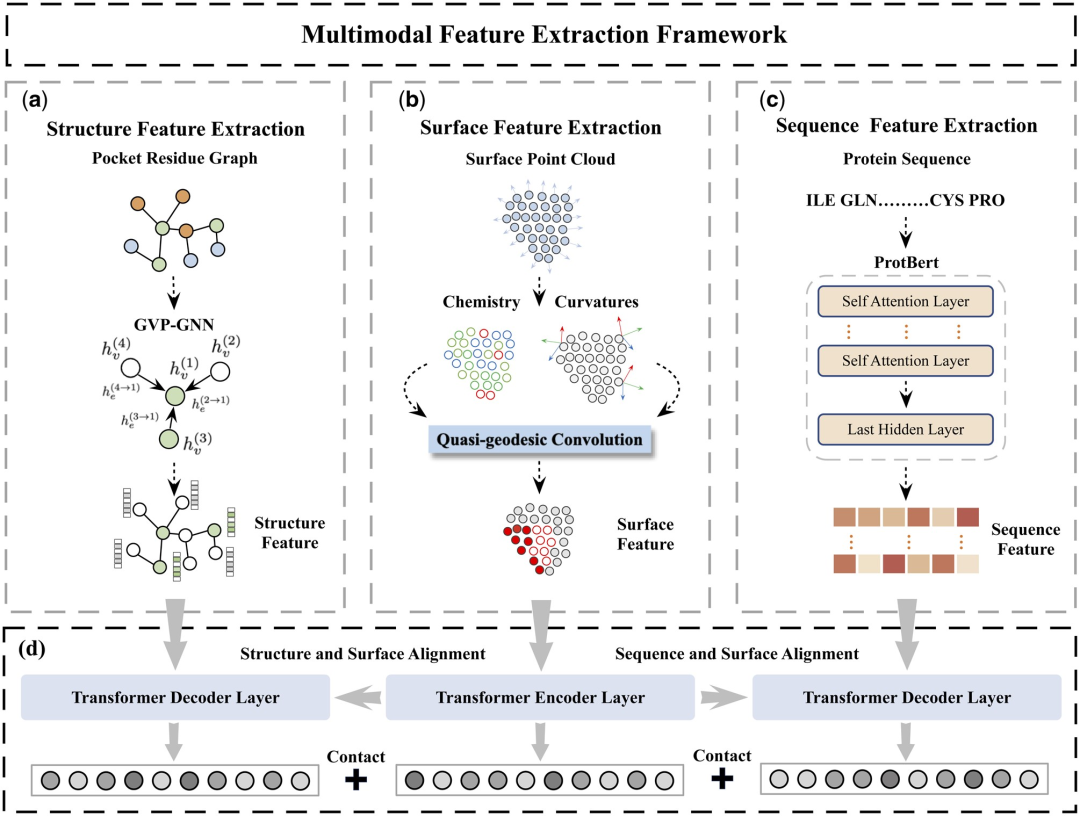
具体来说,研究设计了两个主要组件:蛋白质特征提取模块和多模态特征比对模块。
蛋白质特征提取模块用于从蛋白质表面、结构和序列信息中提取初始嵌入。
在多模态特征比对模块中,使用交叉注意机制实现蛋白质结构、序列嵌入和表面嵌入之间的特征比对,以获得统一且信息丰富的特征嵌入。
与目前最先进的方法相比,所提出的框架在蛋白质-配体结合亲和力预测任务上取得了最佳效果。
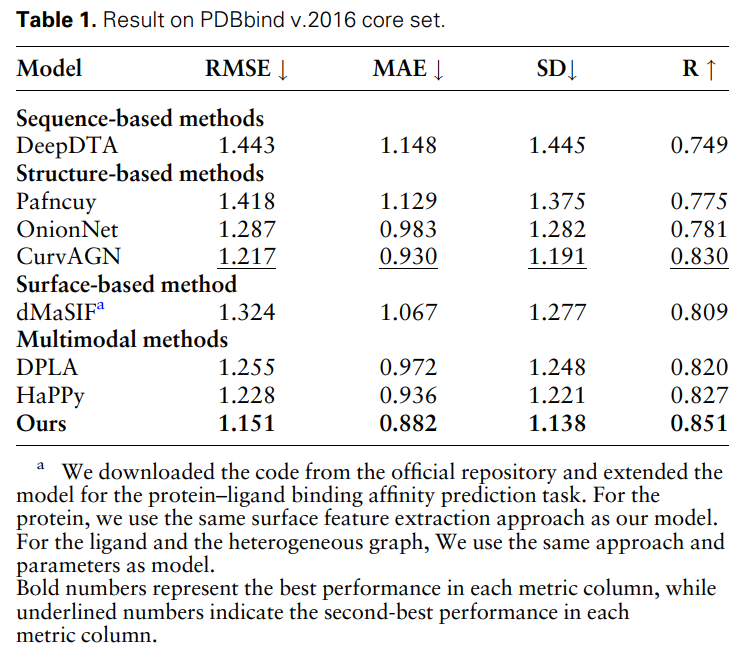
表 1 展示了 MFE 和其他基线模型在蛋白质-配体结合亲和力预测任务上的结果。所有模型都使用相同的训练集和验证集划分方法,并在 PDBbind 核心集(版本 2016)上进行测试。可以发现,与所有基线相比,MFE 方法实现了 SOTA 性能。
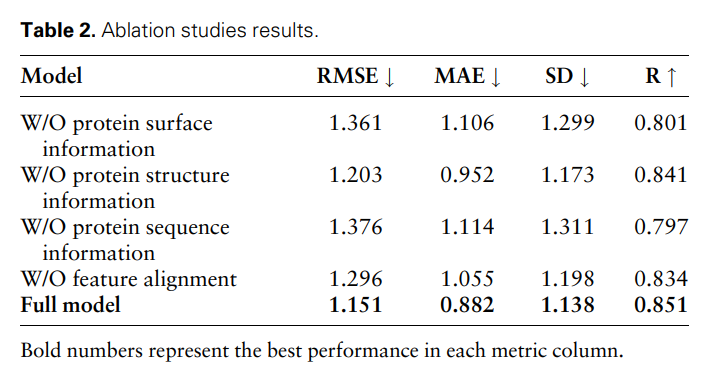
为了进一步证明不同模态特征和特征比对的有效性和必要性,研究人员进行了以下消融研究:W/O 蛋白质表面信息、W/O 蛋白质结构信息、W/O 蛋白质序列信息和无特征比对。结果如表 2 和图 2 所示。
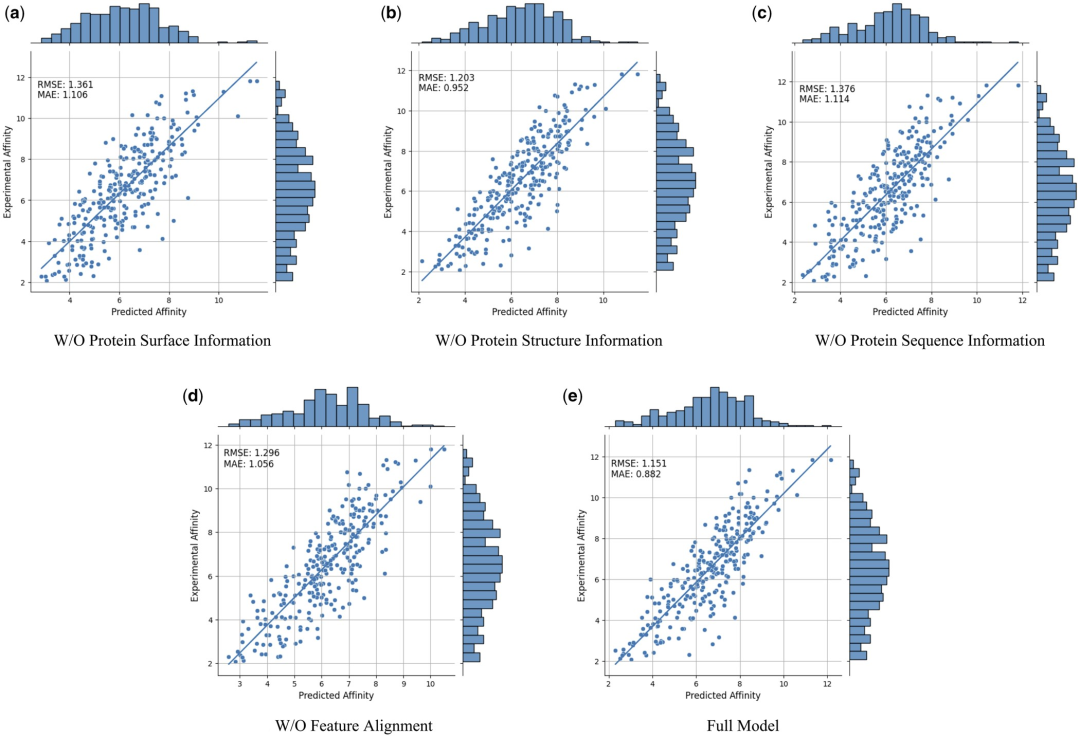
图 2:消融研究结果。(来源:论文)
结果表明,当去除表面信息时,性能会明显下降,这表明表面信息在模型中起着至关重要的作用。同样,排除结构或序列信息都会导致性能下降,而序列信息的消除会导致更明显的下降。这是因为序列信息包含了蛋白质的全局信息,这对于模型对蛋白质的全面理解至关重要。
此外,在没有特征比对的情况下,模型的性能会下降。这强调了特征比对在处理多模态数据中的重要性,因为它有助于减少不同模态特征之间的异质性,从而提高模型有效整合不同模态特征的能力。
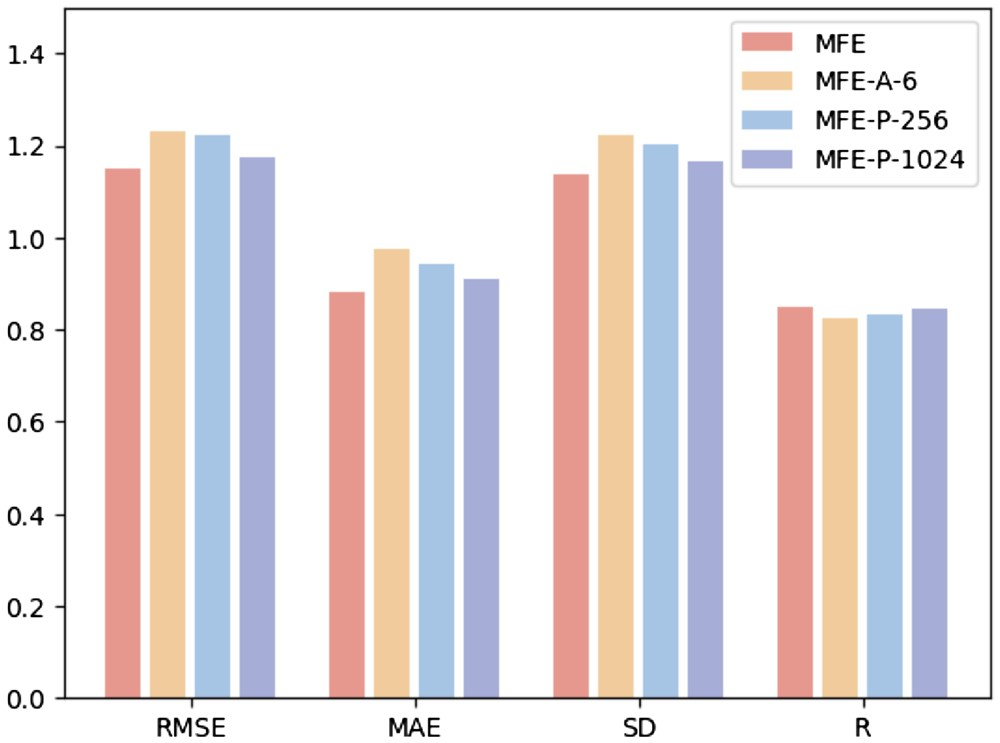
为了研究不同超参数对模型性能的影响,研究人员进行了以下三个实验:(i)MFE-A-6:仅使用 6 种基本原子类型来表示表面的化学特性,包括氢、碳、氮、氧、磷、硫;(ii)MFE-P-256:仅选择最靠近配体中心的 256 个表面点作为蛋白质口袋表面;(iii)MFE-P-1024:选择最靠近配体中心的 1024 个表面点作为蛋白质口袋表面。
图 3 为三种不同的超参数选择方法在蛋白质-配体结合亲和力预测任务上的结果。
为了深入研究特征对齐对模型性能的影响,研究人员使用主成分分析 (PCA) 对测试集中的蛋白质表面、结构和序列特征进行降维和可视化分析。此方法旨在确定特征对齐是否可以减轻多模态嵌入之间的异质性。
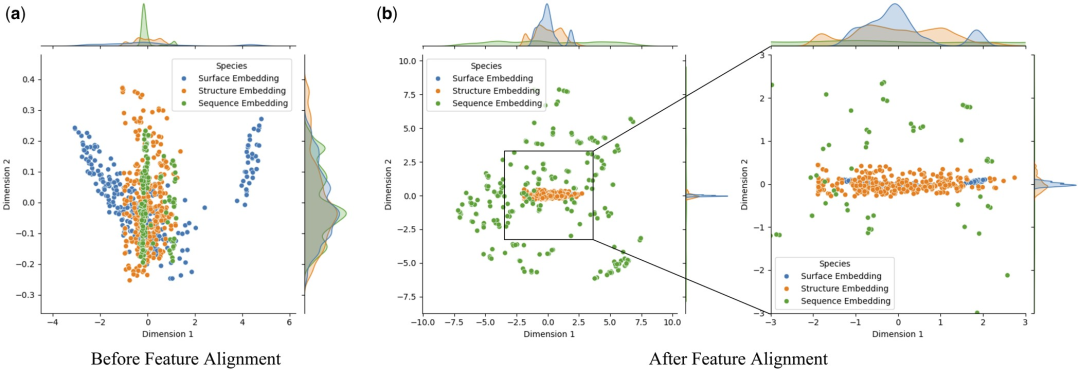
研究发现,特征对齐显著增强了蛋白质表面、结构和序列嵌入之间的一致性。这是由于通过注意力机制优化了 Transformer 中的多模态特征交互,该机制计算了不同特征之间的注意力权重。这增强了模型捕获关键信息的能力,使来自不同模态的数据在特征空间中更紧密地聚集,从而减少了模型识别蛋白质-配体相互作用时的噪音和错误。
最后,研究人员总结道,「总之,通过研究蛋白质的表面,我们可以更深入地了解蛋白质如何与其他生物分子相互作用。在未来的工作中,我们将更彻底地探索蛋白质表面,以揭示它们在生物信息学中的更广泛应用。」
注:封面来自网络
以上是SOTA性能,厦大多模态蛋白质-配体亲和力预测AI方法,首次结合分子表面信息的详细内容。更多信息请关注PHP中文网其他相关文章!


































