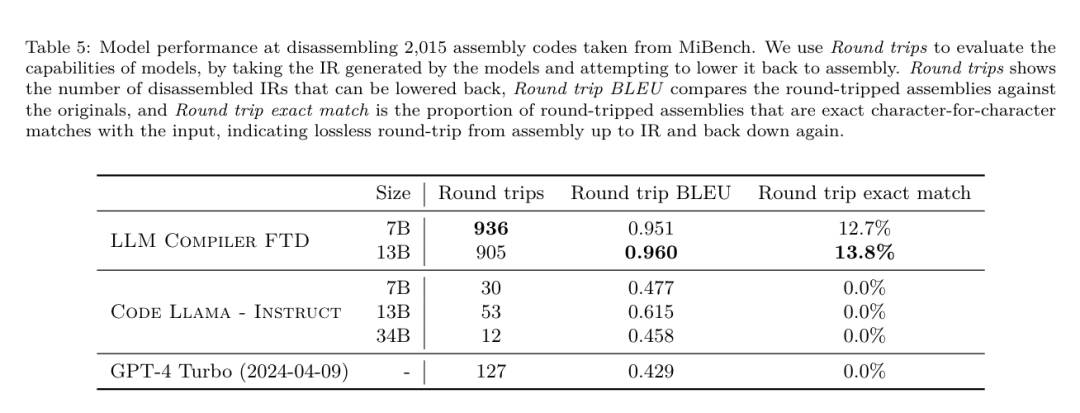
Meta搞了个很牛的LLM Compiler,帮助程序员更高效地写代码。
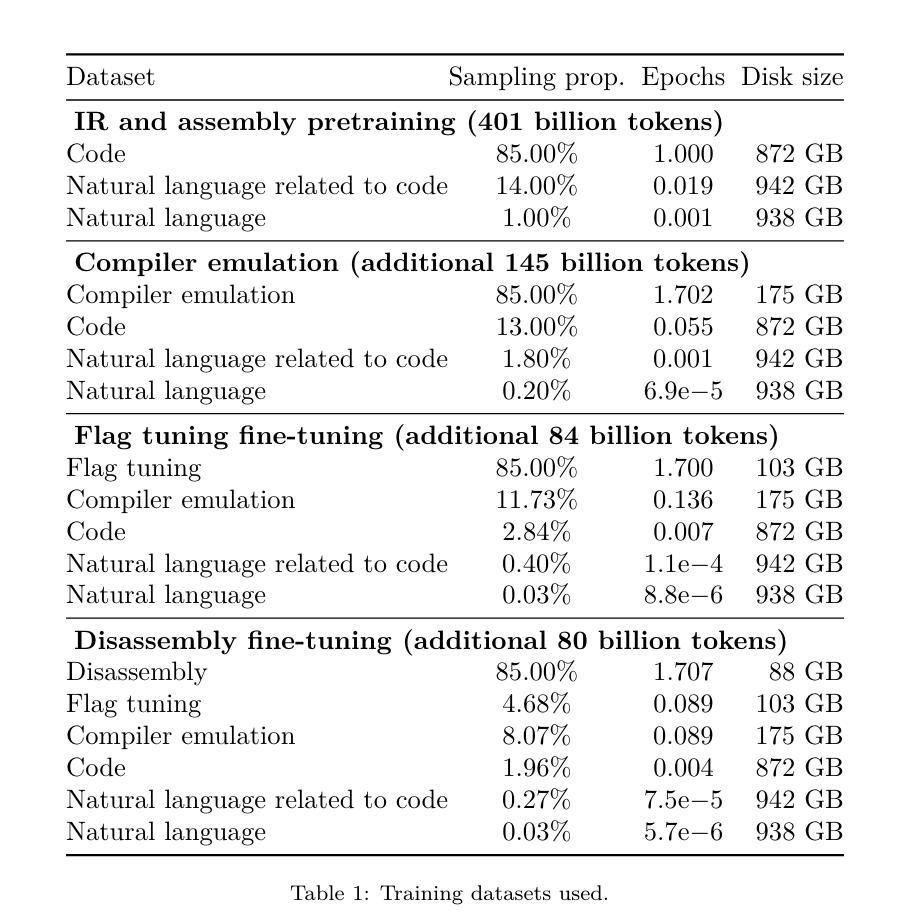
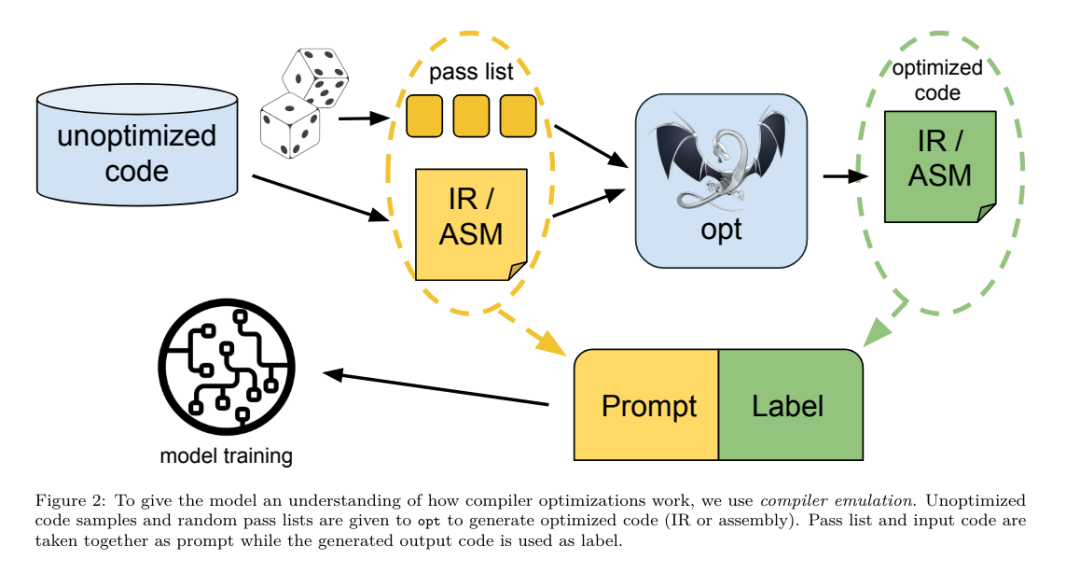
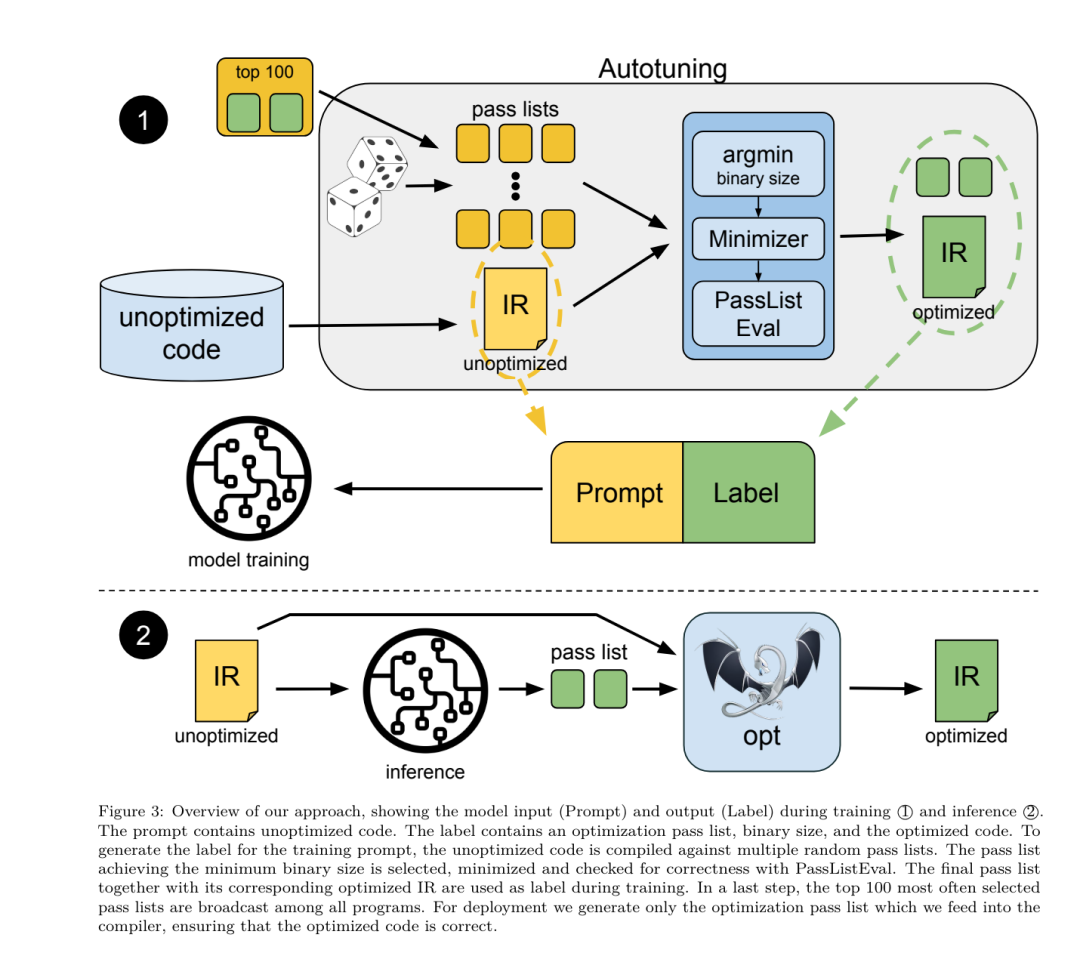
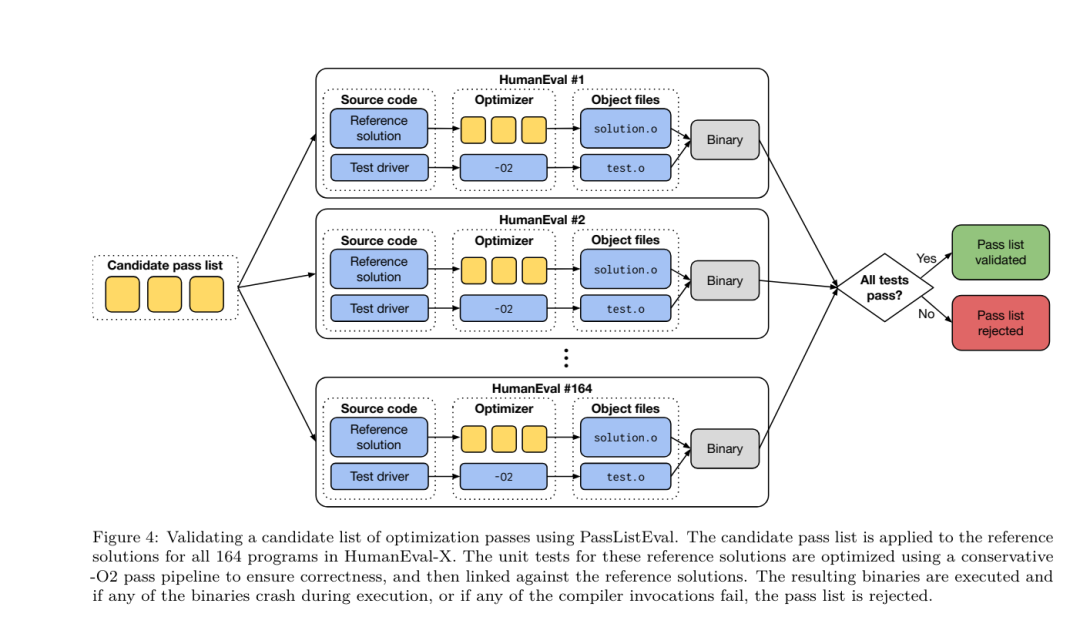
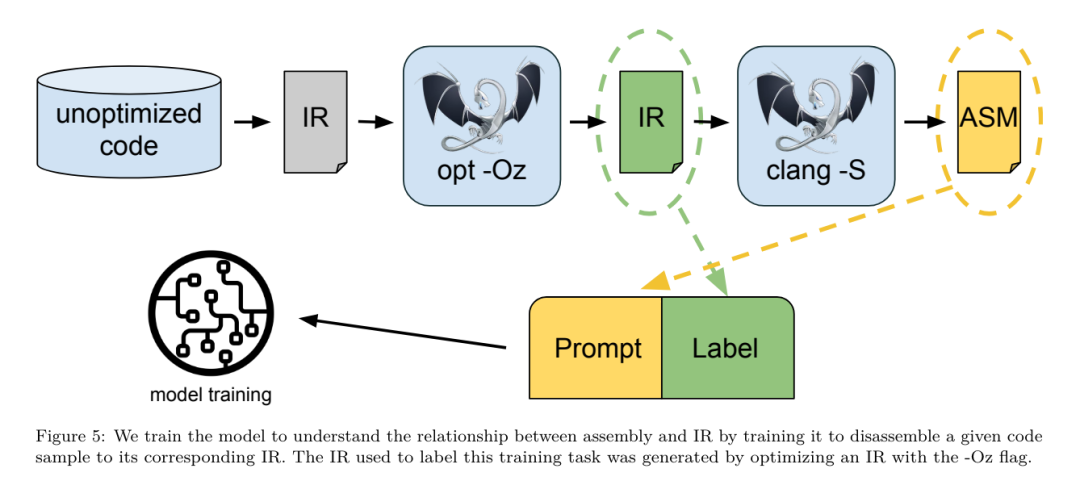
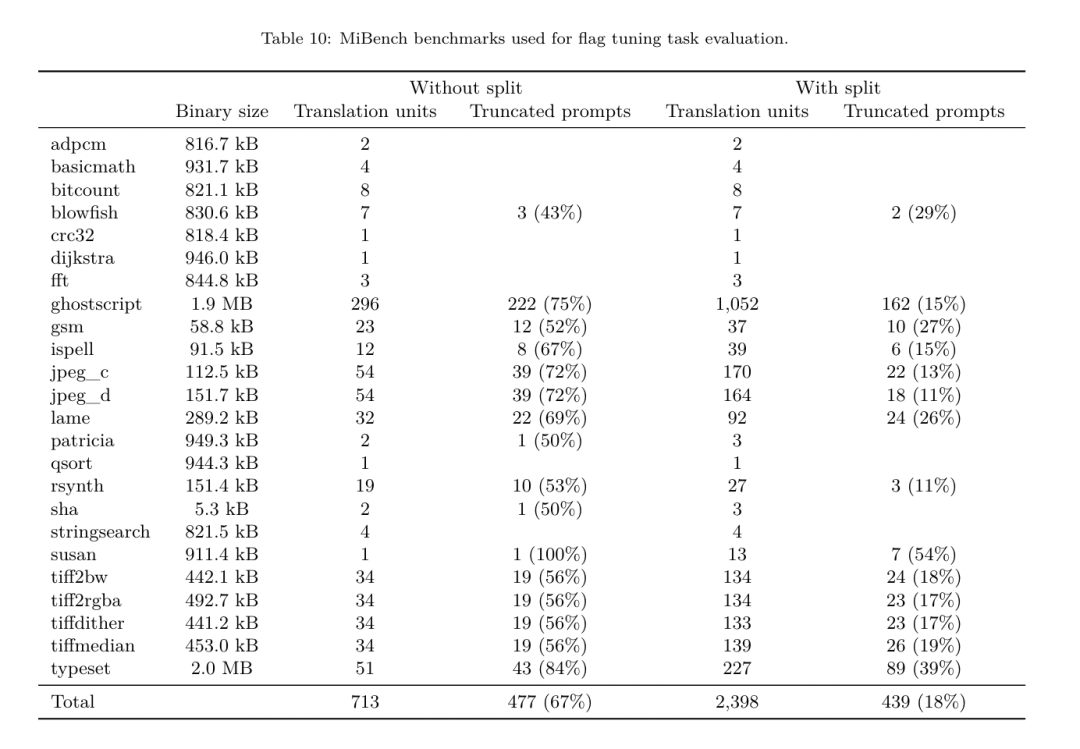
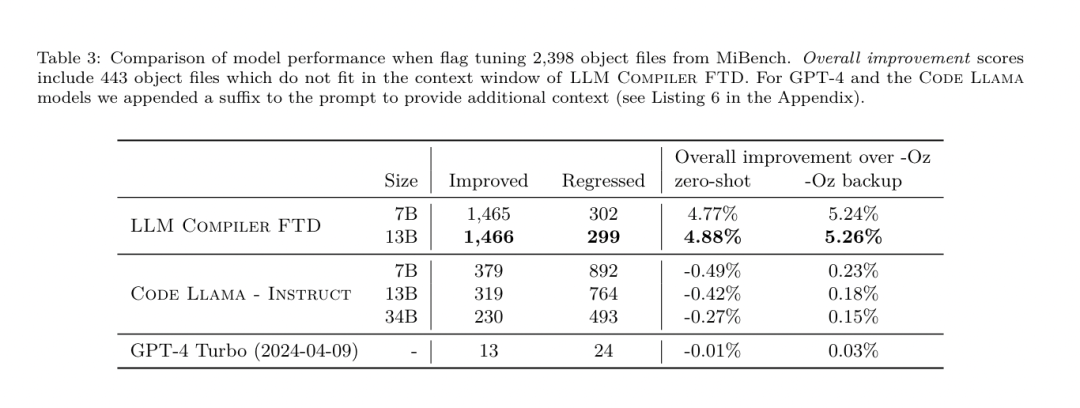
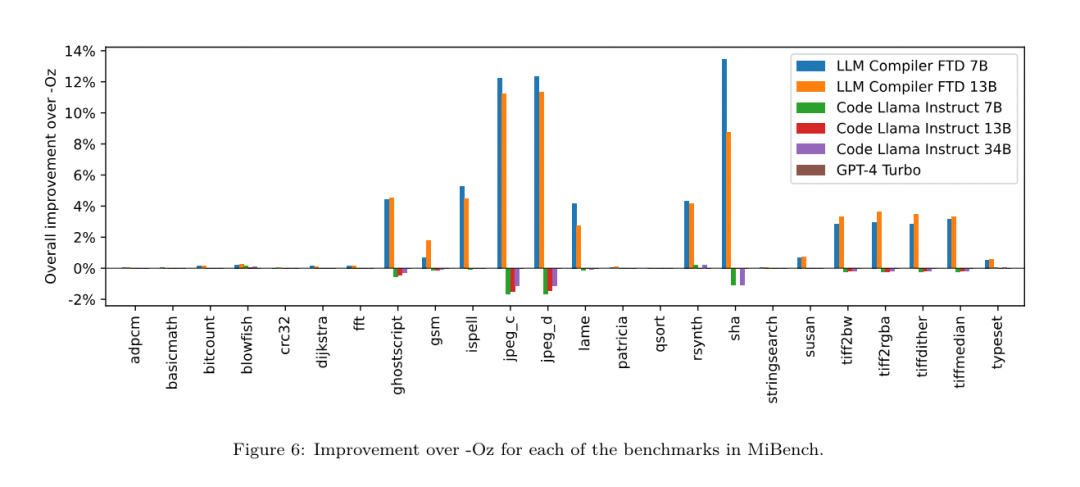
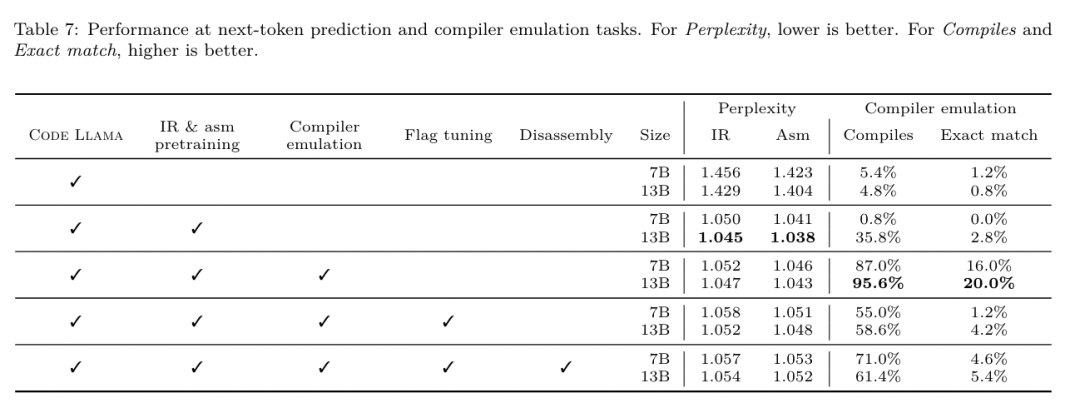
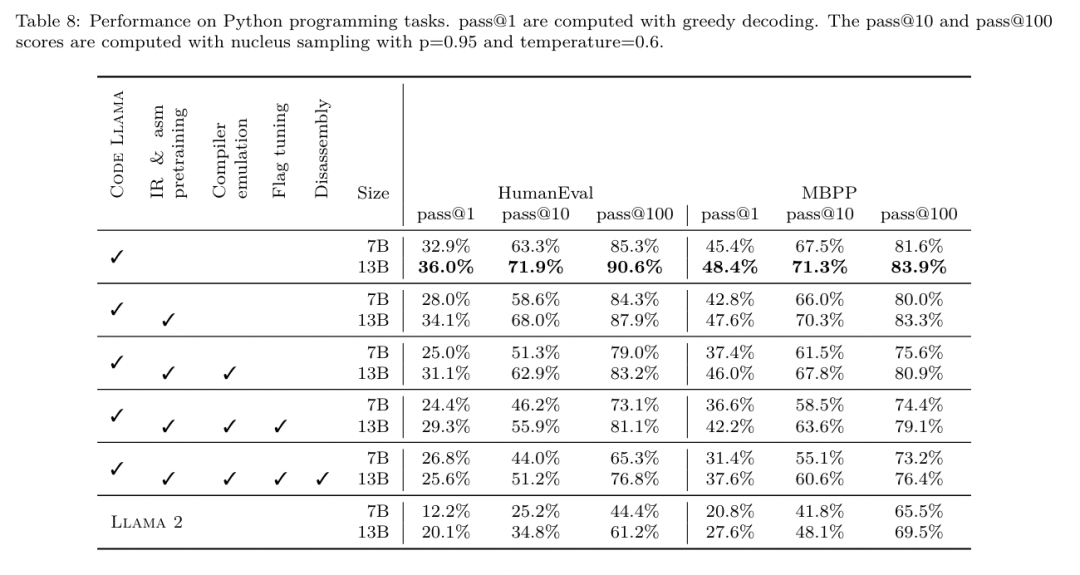
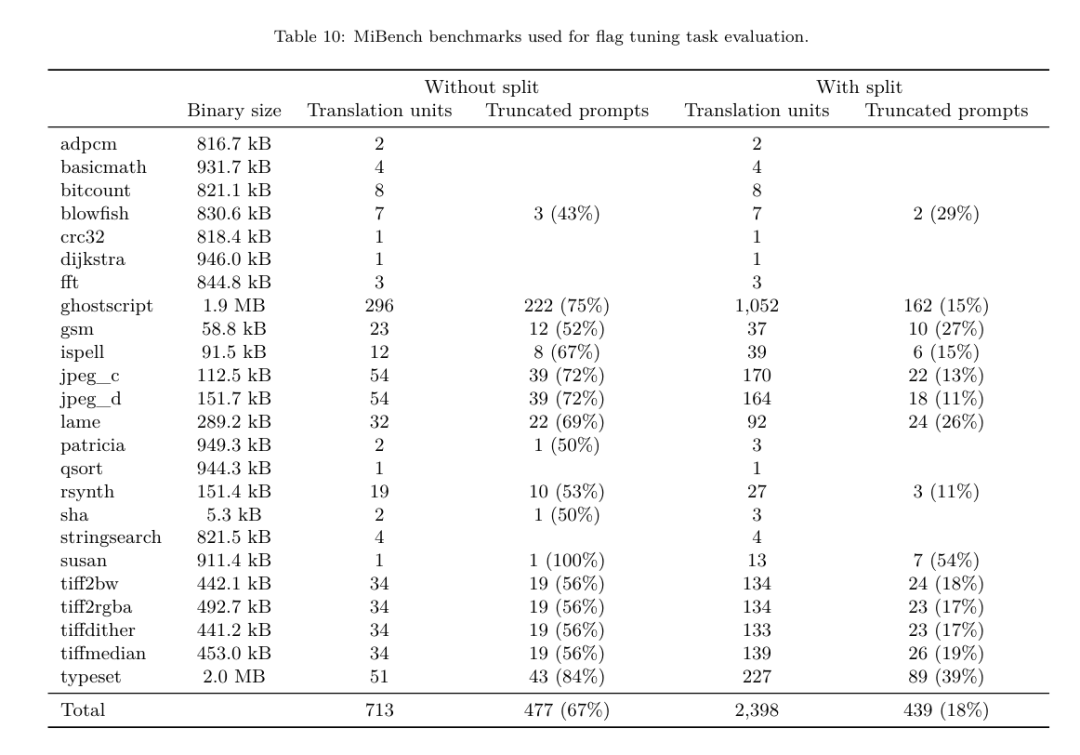
昨天,三大AI 巨头OpenAI、Google、Meta 组团发布自家大模型最新研究成果——OpenAI 推出基于GPT-4 训练的专门找bug 的新模型CriticGPT,谷歌开源9B、27B 版Gemma2,而Meta 则拿出了一项最新的人工智能突破——LLM Compiler。 这是一套强大的开源模型,旨在优化代码并彻底改变编译器设计。这项创新有可能改变开发者处理代码优化的方式,使其更快、更高效、更经济。 据悉,该LLM Compiler 的优化潜力达到了自动调优搜索的77%,这一结果可以显着减少编译时间,并提高各种应用的代码效率,并且在反汇编方面,其往返反汇编的成功率为45%。 有网友表示,这像是代码优化和反汇编的游戏规则改变者。 大语言模型在众多软件工程和编程任务中表现出了卓越的能力,然而它们在代码优化及编译器领域的应用尚未得到充分挖掘。训练这些 LLMs 需要消耗大量的计算资源,包括昂贵的 GPU 时间和庞大的数据集,这往往使得许多研究和项目难以为继。 为了弥补这一空白,Meta 研究团队引入了一种 LLM Compiler,以专门优化代码并彻底改变编译器设计。通过在包含 5460 亿个标记的 LLVM-IR 和汇编代码的庞大语料库上训练模型,他们使模型能够理解编译器中间表示、汇编语言和优化技术。 论文链接:https://ai.meta.com/research/publications/meta-large-language-model-compiler-foundation-models-of-compiler-optimization/研究人员在他们的论文中解释说:「LLM Compiler 增强了对编译器中间表示(IR)、汇编语言和优化技术的理解。」这种增强的理解使模型能够执行以前仅限于人类专家或专业工具的任务。 LLM Compiler 的训练流程如图 1 所示。 LLM Compiler 在代码大小优化方面取得了显著成果。在测试中,模型的优化潜力达到了自动调优搜索的 77%,这一结果可以显着减少编译时间,并提高各种应用的代码效率。 模型在反汇编方面的能力更为出色。 LLM Compiler 在将 x86_64 和 ARM 汇编代码转换回 LLVM-IR 时,往返反汇编的成功率为 45%(其中 14% 完全匹配)。这种能力对于逆向工程任务和旧代码维护可能具有无法估量的价值。 项目的核心贡献者之一Chris Cummins 强调了这项技术的潜在影响:「通过提供两种大小的预训练模型(7 亿和13 亿参数)并通过微调版本展示其有效性, 」他说,「LLM Compiler 为探索LLM 在代码和编译器优化领域未被开发的潜力铺平了道路。」用于训练编程LLMs 的数据通常主要由像Python 这样的高级源语言组成,汇编代码在这些数据集中的比例微乎其微,编译器IR 的比例更小。为了构建一个对这些语言有良好理解的 LLM,研究团队用 Code Llama 的权重初始化 LLM Compiler 模型,然后在一个以编译器为中心的数据集上训练 4010 亿个 token,这个数据集主要由汇编代码和编译器 IR 组成,如表 1 所示。数据集 LLM Compiler 主要在由 LLVM(版本 17.0.6)生成的编译器中间表示和汇编代码上进行训练,这些数据来源于用于训练 Code Llama 的同一数据集,已在表 2 中概述了该数据集。与 Code Llama 一样,我们也从自然语言数据集中获取少量训练批次。 为了理解代码优化的机制,研究团队对 LLM Compiler 模型进行指令微调,以模拟编译器优化,如图 2 所示。其思路是从有限的未优化种子程序集合中,通过对这些程序应用随机生成的编译器优化序列,生成大量示例。然后他们训练模型预测优化生成的代码,还训练模型预测应用优化后的代码大小。任务规范。给定未经优化的 LLVM-IR(由 clang 前端输出),一个优化过程列表,以及一个起始代码大小,生成应用这些优化后的结果代码以及代码大小。这个任务有两种类型:在第一种中,模型预期输出编译器 IR;在第二种中,模型预期输出汇编代码。两种类型的输入 IR、优化过程和代码大小是相同的,提示决定了所需的输出格式。代码大小。他们使用两个指标来衡量代码大小:IR 指令数和二进制大小。二进制大小通过将 IR 或汇编降级为目标文件后,.TEXT 和 .DATA 段大小的总和计算得出。我们排除 .BSS 段,因为它不影响磁盘上的大小。优化 pass。在这项工作中,研究团队针对 LLVM 17.0.6,并使用新的过程管理器 (PM, 2021),它将 pass 分类为不同的级别,如模块、函数、循环等,以及转换和分析 pass 。转换 pass 改变给定的输入 IR,而分析 pass 生成影响后续转换的信息。在 opt 的 346 个可能的 pass 参数中,他们选择了 167 个使用。这包括每个默认优化流水线 (例如 module (default)),单独的优化转换 pass (例如 module (constmerge)),但排除了非优化实用程序 pass (例如 module (dot-callgraph)) 和不保留语义的转换 pass (例如 module (internalize))。他们排除了分析 pass,因为它们没有副作用,我们依赖 pass 管理器根据需要注入依赖的分析 pass。对于接受参数的 pass,我们使用默认值 (例如 module (licm))。表 9 包含了所有使用的 pass 列表。我们使用 LLVM 的 opt 工具应用 pass 列表,并使用 clang 将结果 IR 降级为目标文件。清单 1 显示了使用的命令。数据集。研究团队通过对表 2 中总结的未优化程序应用 1 到 50 个随机优化 pass 列表生成编译器模拟数据集。每个 pass 列表的长度是均匀随机选择的。pass 列表是通过从上述 167 个 pass 集合中均匀采样生成的。导致编译器崩溃或在 120 秒后超时的 pass 列表被排除。LLM Compiler FTD :扩展下游编译任务 操作编译器标志对运行时性能和代码大小都有显著影响。研究团队训练 LLM Compiler FTD 模型执行下游任务,即为 LLVM 的 IR 优化工具 opt 选择标志,以生成最小的代码大小。标志调优的机器学习方法以前已经显示出良好的结果,但在不同程序之间的泛化方面存在困难。以前的工作通常需要编译新程序数十或数百次,以尝试不同的配置并找出性能最佳的选项。该研究团队通过预测标志来最小化未见程序的代码大小,在这个任务的零样本版本上训练和评估 LLM Compiler FTD 模型。他们的方法不依赖于所选择的编译器和优化指标,他们打算在未来针对运行时性能。目前,优化代码大小简化了训练数据的收集。任务规范。研究团队向 LLM Compiler FTD 模型呈现一个未优化的 LLVM-IR (由 clang 前端生成),并要求它生成应该应用的 opt 标志列表,这些优化应用前后的二进制大小,以及输出代码,如果无法对输入代码进行改进,则生成一个只包含未优化二进制大小的简短输出消息。他们使用了与编译器模拟任务相同的受限优化 pass 集,并以相同的方式计算二进制大小。图 3 说明了用于生成训练数据的过程以及如何在推理时使用模型。在评估时只需要生成的 pass 列表。他们从模型输出中提取 pass 列表,并使用给定的参数运行 opt。然后,研究人员可以评估模型预测的二进制大小和优化输出代码的准确性,但这些是辅助学习任务,不是使用所必需的。正确性。LLVM 优化器并非无懈可击,以意外或未经测试的顺序运行优化 pass 可能会暴露出微妙的正确性错误,从而降低模型的实用性。为了缓解这种风险,研究团队开发了 PassListEval,这是一个工具,用于帮助自动识别破坏程序语义或导致编译器崩溃的 pass 列表。图 4 显示了该工具的概览。PassListEval 接受候选 pass 列表作为输入,并在一个包含 164 个自测试 C++ 程序的套件上对其进行评估,这些程序取自 HumanEval-X。每个程序都包含一个编程挑战的参考解决方案,例如「检查给定数字向量中是否有两个数字之间的距离小于给定阈值」,以及验证正确性的单元测试套件。他们将候选 pass 列表应用于参考解决方案,然后将它们与测试套件链接以生成二进制文件。执行时,如果任何测试失败,二进制文件将崩溃。如果任何二进制崩溃,或者任何编译器调用失败,我们就拒绝该候选 pass 列表。数据集。该团队在一个源自 450 万个未优化 IR 的标志调优示例数据集上训练了 LLM Compiler FTD 模型,这些 IR 用于预训练。为生成每个程序的最佳 pass 列表示例,他们进行了广泛的迭代编译过程,如图 3 所示。1. 研究团队使用大规模随机搜索为程序生成初始候选最佳 pass 列表。对每个程序,他们独立生成最多 50 个 pass 的随机列表,从之前描述的 167 个可搜索 pass 集合中均匀采样。每次他们评估一个程序的 pass 列表时,都记录生成的二进制大小,然后选择产生最小二进制大小的每个程序 pass 列表。他们运行了 220 亿次独立编译,平均每个程序 4,877 次。2. 随机搜索生成的 pass 列表可能包含冗余 pass,这些 pass 对最终结果没有影响。此外,一些 pass 顺序是可交换的,重新排序不会影响最终结果。由于这些会在训练数据中引入噪声,他们开发了一个最小化过程,并将其应用于每个 pass 列表。最小化包括三个步骤:冗余 pass 消除、冒泡排序和插入搜索。在冗余 pass 消除中,他们通过迭代删除单个 pass 来最小化最佳 pass 列表,看它们是否对二进制大小有贡献,如果没有,就丢弃它们。重复此过程,直到不能再丢弃 pass。然后冒泡排序尝试为 pass 子序列提供统一排序,根据关键字对 pass 进行排序。最后,插入排序通过遍历 pass 列表中的每个 pass 并尝试在其之前插入 167 个搜索 pass 中的每一个来执行局部搜索。如果这样做改善了二进制大小,就保留这个新的 pass 列表。整个最小化管道循环直到达到固定点。最小化后的 pass 列表长度分布如图 9 所示。平均 pass 列表长度为 3.84。3. 他们将之前描述过 PassListEval 应用于候选最佳 pass 列表。通过这种方式,他们确定了1,704,443 个独立pass 列表中的167,971 个(9.85%) 会导致编译时或运行时错4. 他们将100 个最常见的最优pass 列表广播到所有程序,如果发现改进就更新每个程序的最佳pass 列表。之后,唯一最佳 pass 列表的总数从 1,536,472 减少到 581,076。 上述自动调优管道相比 -Oz 产生了 7.1% 的几何平均二进制大小减少。图 10 显示了单个 pass 的频率。对他们来说,这种自动调优作为每个程序优化的黄金标准。虽然发现的二进制大小节省很显着,但这需要 280 亿次额外编译,计算成本超过 21,000 个 CPU 天。对 LLM Compiler FTD 进行指令微调以执行标志调优任务的目标是在不需要运行编译器数千次的情况下达到自动调优器性能的一部分。 将代码从汇编语言提升到更高层次的结构,可以运行额外的优化,例如直接集成到应用程序代码中的库代码,或者将遗留代码移植到新架构。反编译领域在将机器学习技术应用于从二进制可执行文件生成可读和准确的代码方面取得了进展。在本研究中,研究团队展示了 LLM Compiler FTD 如何通过微调进行反汇编,学习汇编代码和编译器 IR 之间的关系。任务是学习 clang -xir - -o - -S 的逆向翻译,如图 5 所示。 往返测试。使用 LLM 进行反汇编会导致正确性问题。提升的代码必须通过等价性检查器进行验证,这并不总是可行的,或者需要手动验证正确性,或经过充分的测试用例以获得信心。然而,可以通过往返测试找到正确性的下限。也就是说,通过将提升的 IR 重新编译成汇编代码,如果汇编代码是相同的,则 IR 是正确的。这为使用 LLM 的结果提供了一条简单途径,并且是衡量反汇编模型效用的一种简单方法。 任务规范。研究团队向模型提供汇编代码,并训练它发出相应的反汇编 IR。这项任务的上下文长度设置为输入汇编代码 8k 个 token 和输出 IR8k 个 token。 数据集。他们从之前任务中使用的数据集中派生出汇编代码和 IR 对。他们的微调数据集包含 470 万个样本,输入 IR 在降低到 x86 汇编之前已经使用 - Oz 进行了优化。 数据通过字节对编码进行标记化,使用与 Code Llama、Llama 和 Llama 2 相同的标记器。他们对所有四个训练阶段使用相同的训练参数。他们使用的大部分训练参数与 Code Llama 基础模型相同,使用 AdamW 优化器,β1 和 β2 的值为 0.9 和 0.95。他们使用余弦调度,预热步骤为 1000 步,并将最终学习率设置为峰值学习率的 1/30。 与 Code Llama 基础模型相比,该团队将单个序列的上下文长度从 4096 增加到 16384,但保持批量大小恒定为 400 万个 token。为了适应更长的上下文,他们将学习率设置为 2e-5,并修改了 RoPE 位置嵌入的参数,其中他们将频率重置为基本值 θ=10^6。这些设置与 Code Llama 基础模型进行的长上下文训练一致。 该研究团队评估 LLM Compiler 模型在标志调优和反汇编任务、编译器模拟、下一个 token 预测以及软件工程任务上的表现。 方法。他们评估 LLM Compiler FTD 在未见程序的优化标志调优任务上的表现,并与 GPT-4 Turbo 和 Code Llama - Instruct 进行比较。他们对每个模型运行推理,从模型输出中提取优化 pass 列表,然后他们使用这个 pass 列表来优化特定程序并记录二进制大小,基线是使用 -Oz 优化时程序的二进制大小。 对于 GPT-4 Turbo 和 Code Llama - Instruct,他们在提示后附加一个后缀,提供额外上下文以进一步描述问题和预期输出格式。所有模型生成的 pass 列表都使用 PassListEval 进行验证,如果验证失败则使用 -Oz 作为替代。为进一步验证模型生成的 pass 列表的正确性,他们链接最终的程序二进制文件,并将其输出与使用保守的 -O2 优化管道优化的基准输出进行差分测试。数据集。研究团队使用从 MiBench 基准套件提取的 2,398 个测试提示进行评估。为生成这些提示,他们取构成 24 个 MiBench 基准的所有 713 个翻译单元,并从每个单元生成未优化的 IR,然后将它们格式化为提示。如果生成的提示超过 15k tokens,他们使用 llvm-extract 将代表该翻译单元的 LLVM 模块分割成更小的模块,每个函数一个,这导致 1,985 个提示适合 15k token 上下文窗口,剩下 443 个翻译单元不适合。在计算性能分数时,他们对 443 个被排除的翻译单元使用 -Oz。表 10 总结了基准。结果。表 3 显示了所有模型在标志调优任务上的零样本性能。只有 LLM Compiler FTD 模型比 -Oz 有所改进,13B 参数模型略优于较小的模型,在 61% 的情况下生成比 -Oz 更小的目标文件。在某些情况下,模型生成的 pass 列表导致比 -Oz 更大的目标文件大小。例如,LLM Compiler FTD 13B 在 12% 的情况下有退化。这些退化可以通过简单地编译程序两次来避免:一次使用模型生成的 pass 列表,一次使用 -Oz,然后选择产生最佳结果的 pass 列表。通过消除相对于 -Oz 的退化,这些 -Oz 备份分数将 LLM Compiler FTD 13B 相对于 -Oz 的总体改进提高到 5.26%,并使 Code Llama - Instruct 和 GPT-4 Turbo 相对于 -Oz 有适度的改进。图 6 显示了每个模型在各个基准上的性能细分。 二进制大小准确性。虽然模型生成的二进制大小预测对实际编译没有影响,但研究团队可以评估模型在预测优化前后的二进制大小方面的性能,以了解每个模型对优化的理解程度。图 7 显示了结果。LLM Compiler FTD 的二进制大小预测与实际情况相关性良好,7B 参数模型对未优化和优化的二进制大小分别达到了 0.083 和 0.225 的 MAPE 值。13B 参数模型的 MAPE 值相似,分别为 0.082 和 0.225。Code Llama - Instruct 和 GPT-4 Turbo 的二进制大小预测与实际情况几乎没有相关性。研究人员注意到,LLM Compiler FTD 对优化代码的错误略高于未优化代码。特别是 LLM Compiler FTD 偶尔有高估优化效果的趋势,导致预测的二进制大小低于实际情况。消融研究。表 4 对模型在 500 个提示的小型保留验证集上的性能进行了消融研究,这些提示来自与他们训练数据相同的分布 (但未在训练中使用)。他们在图 1 所示训练管道的每个阶段进行标志调优训练,以比较性能。如图所示,反汇编训练导致性能从平均 5.15% 略微下降到 5.12%(相对于 -Oz 的改进)。他们还展示了用于生成第 2 节所述训练数据的自动调优器的性能。LLM Compiler FTD 达到了自动调优器 77% 的性能。方法。研究团队评估 LLM 生成的代码在将汇编代码反汇编到 LLVM-IR 时的功能正确性。他们评估 LLM Compiler FTD 并与 Code Llama - Instruct 和 GPT-4 Turbo 进行比较,发现需要额外的提示后缀才能从这些模型中提取最佳性能。后缀提供了关于任务和预期输出格式的额外上下文。为评估模型的性能,他们将模型生成的反汇编 IR 往返降级回汇编。这使我们能够通过比较原始汇编与往返结果的 BLEU 分数来评估反汇编的准确性。从汇编到 IR 的无损完美反汇编将有 1.0 的往返 BLEU 分数 (精确匹配)。数据集。他们使用从 MiBench 基准套件提取的 2,015 个测试提示进行评估,取用于上述标志调优评估的 2,398 个翻译单元,生成反汇编提示。然后他们根据最大 8k token 长度过滤提示,允许 8k tokens 用于模型输出,剩下 2,015 个。表 11 总结了基准。LLM Compiler FTD 7B 的往返成功率略高于 LLM Compiler FTD 13B,但 LLM Compiler FTD 13B 具有最高的往返汇编准确性 (往返 BLEU) 和最频繁产生完美反汇编 (往返精确匹配)。Code Llama - Instruct 和 GPT-4 Turbo 在生成语法正确的 LLVM-IR 方面存在困难。图 8 显示了所有模型的往返 BLEU 分数分布。消融研究。表 6 对模型在 500 个提示的小型保留验证集上的性能进行了消融研究,这些提示取自之前使用的 MiBench 数据集。他们在图 1 所示训练管道的每个阶段进行反汇编训练,以比较性能。往返率在通过整个训练数据堆栈时最高,并随每个训练阶段持续下降,尽管往返 BLEU 在每个阶段变化不大。方法。该研究团队在下一个 token 预测和编译器模拟两个基础模型任务上对 LLM Compiler 模型进行消融研究。他们在训练管道的每个阶段进行这种评估,以了解为每个连续任务训练如何影响性能。对于下一个 token 预测,他们在所有优化级别的 LLVM-IR 和汇编代码的小样本上计算困惑度。他们使用两个指标评估编译器模拟:生成的 IR 或汇编代码是否编译,以及生成的 IR 或汇编代码是否与编译器产生的完全匹配。数据集。对于下一个 token 预测,他们使用从与我们训练数据相同分布但未用于训练的小型保留验证数据集。他们使用混合的优化级别,包括未优化代码、用 -Oz 优化的代码和随机生成的 pass 列表。对于编译器模拟,他们使用从 MiBench 生成的 500 个提示进行评估,这些提示使用第 2.2 节描述的方式随机生成的 pass 列表。结果。表 7 显示了 LLM Compiler FTD 在所有训练阶段在两个基础模型训练任务 (下一个 token 预测和编译器模拟) 上的性能。下一个 token 预测性能在 Code Llama 之后急剧上升,后者几乎没有见过 IR 和汇编,并在随后的每个微调阶段略有下降。对于编译器模拟,Code Llama 基础模型和预训练模型表现不佳,因为它们没有在这个任务上训练过。在编译器模拟训练之后直接达到最高性能,其中 LLM Compiler FTD 13B 生成的 95.6% 的 IR 和汇编可以编译,20% 与编译器完全匹配。在进行标志调优和反汇编微调后,性能下降。方法。虽然 LLM Compiler FTD 的目的是为代码优化提供基础模型,但它建立在为软件工程任务训练的基础 Code Llama 模型之上。为评估 LLM Compiler FTD 的额外训练如何影响代码生成的性能,他们使用与 Code Llama 相同的基准套件,评估 LLM 从自然语言提示生成 Python 代码的能力,如「编写一个函数,找出可以从给定的对集合形成的最长链。」数据集。他们使用 HumanEval 和 MBPP 基准,与 Code Llama 相同。结果。表 8 显示了从 Code Llama 基础模型开始的所有模型训练阶段和模型大小的贪婪解码性能 (pass@1)。它还显示了模型在 pass@10 和 pass@100 上的分数,这些分数是用 p=0.95 和 temperature=0.6 生成的。每个以编译器为中心的训练阶段都导致 Python 编程能力略有退化。在 HumanEval 和 MBPP 上,LLM Compiler 的 pass@1 性能最多下降 18% 和 5%,LLM Compiler FTD 在额外的标志调优和反汇编微调后最多下降 29% 和 22%。所有模型在这两个任务上仍然优于 Llama 2。Meta 研究团队已经展示了 LLM Compiler 在编译器优化任务上表现良好,并且相比先前的工作,对编译器表示和汇编代码的理解有所改进,但仍存在一些局限性。主要限制是输入的有限序列长度 (上下文窗口)。LLM Compiler 支持 16k tokens 的上下文窗口,但程序代码可能远远超过这个长度。例如,当格式化为标志调优提示时,67% 的 MiBench 翻译单元超过了这个上下文窗口,如表 10 所示。为了缓解这一问题,他们将较大的翻译单元拆分为单独的函数,尽管这限制了可以执行的优化范围,而且仍有 18% 的拆分翻译单元对模型来说太大,无法作为输入接受。研究人员正在采用不断增加的上下文窗口,但有限的上下文窗口仍然是 LLM 的一个普遍问题。第二个限制,也是所有 LLM 的共同问题,是模型输出的准确性。建议 LLM Compiler 的用户使用特定于编译器的评估基准来评估他们的模型。鉴于编译器并非无 bug,任何建议的编译器优化都必须经过严格测试。当模型反编译汇编代码时,其准确性应通过往返、人工检查或单元测试来确认。对于某些应用,LLM 生成可以被限制在正则表达式内,或与自动验证相结合以确保正确性。https://x.com/AIatMeta/status/1806361623831171318
为了理解代码优化的机制,研究团队对 LLM Compiler 模型进行指令微调,以模拟编译器优化,如图 2 所示。其思路是从有限的未优化种子程序集合中,通过对这些程序应用随机生成的编译器优化序列,生成大量示例。然后他们训练模型预测优化生成的代码,还训练模型预测应用优化后的代码大小。任务规范。给定未经优化的 LLVM-IR(由 clang 前端输出),一个优化过程列表,以及一个起始代码大小,生成应用这些优化后的结果代码以及代码大小。这个任务有两种类型:在第一种中,模型预期输出编译器 IR;在第二种中,模型预期输出汇编代码。两种类型的输入 IR、优化过程和代码大小是相同的,提示决定了所需的输出格式。代码大小。他们使用两个指标来衡量代码大小:IR 指令数和二进制大小。二进制大小通过将 IR 或汇编降级为目标文件后,.TEXT 和 .DATA 段大小的总和计算得出。我们排除 .BSS 段,因为它不影响磁盘上的大小。优化 pass。在这项工作中,研究团队针对 LLVM 17.0.6,并使用新的过程管理器 (PM, 2021),它将 pass 分类为不同的级别,如模块、函数、循环等,以及转换和分析 pass 。转换 pass 改变给定的输入 IR,而分析 pass 生成影响后续转换的信息。在 opt 的 346 个可能的 pass 参数中,他们选择了 167 个使用。这包括每个默认优化流水线 (例如 module (default)),单独的优化转换 pass (例如 module (constmerge)),但排除了非优化实用程序 pass (例如 module (dot-callgraph)) 和不保留语义的转换 pass (例如 module (internalize))。他们排除了分析 pass,因为它们没有副作用,我们依赖 pass 管理器根据需要注入依赖的分析 pass。对于接受参数的 pass,我们使用默认值 (例如 module (licm))。表 9 包含了所有使用的 pass 列表。我们使用 LLVM 的 opt 工具应用 pass 列表,并使用 clang 将结果 IR 降级为目标文件。清单 1 显示了使用的命令。数据集。研究团队通过对表 2 中总结的未优化程序应用 1 到 50 个随机优化 pass 列表生成编译器模拟数据集。每个 pass 列表的长度是均匀随机选择的。pass 列表是通过从上述 167 个 pass 集合中均匀采样生成的。导致编译器崩溃或在 120 秒后超时的 pass 列表被排除。LLM Compiler FTD :扩展下游编译任务 操作编译器标志对运行时性能和代码大小都有显著影响。研究团队训练 LLM Compiler FTD 模型执行下游任务,即为 LLVM 的 IR 优化工具 opt 选择标志,以生成最小的代码大小。标志调优的机器学习方法以前已经显示出良好的结果,但在不同程序之间的泛化方面存在困难。以前的工作通常需要编译新程序数十或数百次,以尝试不同的配置并找出性能最佳的选项。该研究团队通过预测标志来最小化未见程序的代码大小,在这个任务的零样本版本上训练和评估 LLM Compiler FTD 模型。他们的方法不依赖于所选择的编译器和优化指标,他们打算在未来针对运行时性能。目前,优化代码大小简化了训练数据的收集。任务规范。研究团队向 LLM Compiler FTD 模型呈现一个未优化的 LLVM-IR (由 clang 前端生成),并要求它生成应该应用的 opt 标志列表,这些优化应用前后的二进制大小,以及输出代码,如果无法对输入代码进行改进,则生成一个只包含未优化二进制大小的简短输出消息。他们使用了与编译器模拟任务相同的受限优化 pass 集,并以相同的方式计算二进制大小。图 3 说明了用于生成训练数据的过程以及如何在推理时使用模型。在评估时只需要生成的 pass 列表。他们从模型输出中提取 pass 列表,并使用给定的参数运行 opt。然后,研究人员可以评估模型预测的二进制大小和优化输出代码的准确性,但这些是辅助学习任务,不是使用所必需的。正确性。LLVM 优化器并非无懈可击,以意外或未经测试的顺序运行优化 pass 可能会暴露出微妙的正确性错误,从而降低模型的实用性。为了缓解这种风险,研究团队开发了 PassListEval,这是一个工具,用于帮助自动识别破坏程序语义或导致编译器崩溃的 pass 列表。图 4 显示了该工具的概览。PassListEval 接受候选 pass 列表作为输入,并在一个包含 164 个自测试 C++ 程序的套件上对其进行评估,这些程序取自 HumanEval-X。每个程序都包含一个编程挑战的参考解决方案,例如「检查给定数字向量中是否有两个数字之间的距离小于给定阈值」,以及验证正确性的单元测试套件。他们将候选 pass 列表应用于参考解决方案,然后将它们与测试套件链接以生成二进制文件。执行时,如果任何测试失败,二进制文件将崩溃。如果任何二进制崩溃,或者任何编译器调用失败,我们就拒绝该候选 pass 列表。数据集。该团队在一个源自 450 万个未优化 IR 的标志调优示例数据集上训练了 LLM Compiler FTD 模型,这些 IR 用于预训练。为生成每个程序的最佳 pass 列表示例,他们进行了广泛的迭代编译过程,如图 3 所示。1. 研究团队使用大规模随机搜索为程序生成初始候选最佳 pass 列表。对每个程序,他们独立生成最多 50 个 pass 的随机列表,从之前描述的 167 个可搜索 pass 集合中均匀采样。每次他们评估一个程序的 pass 列表时,都记录生成的二进制大小,然后选择产生最小二进制大小的每个程序 pass 列表。他们运行了 220 亿次独立编译,平均每个程序 4,877 次。2. 随机搜索生成的 pass 列表可能包含冗余 pass,这些 pass 对最终结果没有影响。此外,一些 pass 顺序是可交换的,重新排序不会影响最终结果。由于这些会在训练数据中引入噪声,他们开发了一个最小化过程,并将其应用于每个 pass 列表。最小化包括三个步骤:冗余 pass 消除、冒泡排序和插入搜索。在冗余 pass 消除中,他们通过迭代删除单个 pass 来最小化最佳 pass 列表,看它们是否对二进制大小有贡献,如果没有,就丢弃它们。重复此过程,直到不能再丢弃 pass。然后冒泡排序尝试为 pass 子序列提供统一排序,根据关键字对 pass 进行排序。最后,插入排序通过遍历 pass 列表中的每个 pass 并尝试在其之前插入 167 个搜索 pass 中的每一个来执行局部搜索。如果这样做改善了二进制大小,就保留这个新的 pass 列表。整个最小化管道循环直到达到固定点。最小化后的 pass 列表长度分布如图 9 所示。平均 pass 列表长度为 3.84。3. 他们将之前描述过 PassListEval 应用于候选最佳 pass 列表。通过这种方式,他们确定了1,704,443 个独立pass 列表中的167,971 个(9.85%) 会导致编译时或运行时错4. 他们将100 个最常见的最优pass 列表广播到所有程序,如果发现改进就更新每个程序的最佳pass 列表。之后,唯一最佳 pass 列表的总数从 1,536,472 减少到 581,076。 上述自动调优管道相比 -Oz 产生了 7.1% 的几何平均二进制大小减少。图 10 显示了单个 pass 的频率。对他们来说,这种自动调优作为每个程序优化的黄金标准。虽然发现的二进制大小节省很显着,但这需要 280 亿次额外编译,计算成本超过 21,000 个 CPU 天。对 LLM Compiler FTD 进行指令微调以执行标志调优任务的目标是在不需要运行编译器数千次的情况下达到自动调优器性能的一部分。 将代码从汇编语言提升到更高层次的结构,可以运行额外的优化,例如直接集成到应用程序代码中的库代码,或者将遗留代码移植到新架构。反编译领域在将机器学习技术应用于从二进制可执行文件生成可读和准确的代码方面取得了进展。在本研究中,研究团队展示了 LLM Compiler FTD 如何通过微调进行反汇编,学习汇编代码和编译器 IR 之间的关系。任务是学习 clang -xir - -o - -S 的逆向翻译,如图 5 所示。 往返测试。使用 LLM 进行反汇编会导致正确性问题。提升的代码必须通过等价性检查器进行验证,这并不总是可行的,或者需要手动验证正确性,或经过充分的测试用例以获得信心。然而,可以通过往返测试找到正确性的下限。也就是说,通过将提升的 IR 重新编译成汇编代码,如果汇编代码是相同的,则 IR 是正确的。这为使用 LLM 的结果提供了一条简单途径,并且是衡量反汇编模型效用的一种简单方法。 任务规范。研究团队向模型提供汇编代码,并训练它发出相应的反汇编 IR。这项任务的上下文长度设置为输入汇编代码 8k 个 token 和输出 IR8k 个 token。 数据集。他们从之前任务中使用的数据集中派生出汇编代码和 IR 对。他们的微调数据集包含 470 万个样本,输入 IR 在降低到 x86 汇编之前已经使用 - Oz 进行了优化。 数据通过字节对编码进行标记化,使用与 Code Llama、Llama 和 Llama 2 相同的标记器。他们对所有四个训练阶段使用相同的训练参数。他们使用的大部分训练参数与 Code Llama 基础模型相同,使用 AdamW 优化器,β1 和 β2 的值为 0.9 和 0.95。他们使用余弦调度,预热步骤为 1000 步,并将最终学习率设置为峰值学习率的 1/30。 与 Code Llama 基础模型相比,该团队将单个序列的上下文长度从 4096 增加到 16384,但保持批量大小恒定为 400 万个 token。为了适应更长的上下文,他们将学习率设置为 2e-5,并修改了 RoPE 位置嵌入的参数,其中他们将频率重置为基本值 θ=10^6。这些设置与 Code Llama 基础模型进行的长上下文训练一致。 该研究团队评估 LLM Compiler 模型在标志调优和反汇编任务、编译器模拟、下一个 token 预测以及软件工程任务上的表现。 方法。他们评估 LLM Compiler FTD 在未见程序的优化标志调优任务上的表现,并与 GPT-4 Turbo 和 Code Llama - Instruct 进行比较。他们对每个模型运行推理,从模型输出中提取优化 pass 列表,然后他们使用这个 pass 列表来优化特定程序并记录二进制大小,基线是使用 -Oz 优化时程序的二进制大小。 对于 GPT-4 Turbo 和 Code Llama - Instruct,他们在提示后附加一个后缀,提供额外上下文以进一步描述问题和预期输出格式。所有模型生成的 pass 列表都使用 PassListEval 进行验证,如果验证失败则使用 -Oz 作为替代。为进一步验证模型生成的 pass 列表的正确性,他们链接最终的程序二进制文件,并将其输出与使用保守的 -O2 优化管道优化的基准输出进行差分测试。数据集。研究团队使用从 MiBench 基准套件提取的 2,398 个测试提示进行评估。为生成这些提示,他们取构成 24 个 MiBench 基准的所有 713 个翻译单元,并从每个单元生成未优化的 IR,然后将它们格式化为提示。如果生成的提示超过 15k tokens,他们使用 llvm-extract 将代表该翻译单元的 LLVM 模块分割成更小的模块,每个函数一个,这导致 1,985 个提示适合 15k token 上下文窗口,剩下 443 个翻译单元不适合。在计算性能分数时,他们对 443 个被排除的翻译单元使用 -Oz。表 10 总结了基准。结果。表 3 显示了所有模型在标志调优任务上的零样本性能。只有 LLM Compiler FTD 模型比 -Oz 有所改进,13B 参数模型略优于较小的模型,在 61% 的情况下生成比 -Oz 更小的目标文件。在某些情况下,模型生成的 pass 列表导致比 -Oz 更大的目标文件大小。例如,LLM Compiler FTD 13B 在 12% 的情况下有退化。这些退化可以通过简单地编译程序两次来避免:一次使用模型生成的 pass 列表,一次使用 -Oz,然后选择产生最佳结果的 pass 列表。通过消除相对于 -Oz 的退化,这些 -Oz 备份分数将 LLM Compiler FTD 13B 相对于 -Oz 的总体改进提高到 5.26%,并使 Code Llama - Instruct 和 GPT-4 Turbo 相对于 -Oz 有适度的改进。图 6 显示了每个模型在各个基准上的性能细分。 二进制大小准确性。虽然模型生成的二进制大小预测对实际编译没有影响,但研究团队可以评估模型在预测优化前后的二进制大小方面的性能,以了解每个模型对优化的理解程度。图 7 显示了结果。LLM Compiler FTD 的二进制大小预测与实际情况相关性良好,7B 参数模型对未优化和优化的二进制大小分别达到了 0.083 和 0.225 的 MAPE 值。13B 参数模型的 MAPE 值相似,分别为 0.082 和 0.225。Code Llama - Instruct 和 GPT-4 Turbo 的二进制大小预测与实际情况几乎没有相关性。研究人员注意到,LLM Compiler FTD 对优化代码的错误略高于未优化代码。特别是 LLM Compiler FTD 偶尔有高估优化效果的趋势,导致预测的二进制大小低于实际情况。消融研究。表 4 对模型在 500 个提示的小型保留验证集上的性能进行了消融研究,这些提示来自与他们训练数据相同的分布 (但未在训练中使用)。他们在图 1 所示训练管道的每个阶段进行标志调优训练,以比较性能。如图所示,反汇编训练导致性能从平均 5.15% 略微下降到 5.12%(相对于 -Oz 的改进)。他们还展示了用于生成第 2 节所述训练数据的自动调优器的性能。LLM Compiler FTD 达到了自动调优器 77% 的性能。方法。研究团队评估 LLM 生成的代码在将汇编代码反汇编到 LLVM-IR 时的功能正确性。他们评估 LLM Compiler FTD 并与 Code Llama - Instruct 和 GPT-4 Turbo 进行比较,发现需要额外的提示后缀才能从这些模型中提取最佳性能。后缀提供了关于任务和预期输出格式的额外上下文。为评估模型的性能,他们将模型生成的反汇编 IR 往返降级回汇编。这使我们能够通过比较原始汇编与往返结果的 BLEU 分数来评估反汇编的准确性。从汇编到 IR 的无损完美反汇编将有 1.0 的往返 BLEU 分数 (精确匹配)。数据集。他们使用从 MiBench 基准套件提取的 2,015 个测试提示进行评估,取用于上述标志调优评估的 2,398 个翻译单元,生成反汇编提示。然后他们根据最大 8k token 长度过滤提示,允许 8k tokens 用于模型输出,剩下 2,015 个。表 11 总结了基准。LLM Compiler FTD 7B 的往返成功率略高于 LLM Compiler FTD 13B,但 LLM Compiler FTD 13B 具有最高的往返汇编准确性 (往返 BLEU) 和最频繁产生完美反汇编 (往返精确匹配)。Code Llama - Instruct 和 GPT-4 Turbo 在生成语法正确的 LLVM-IR 方面存在困难。图 8 显示了所有模型的往返 BLEU 分数分布。消融研究。表 6 对模型在 500 个提示的小型保留验证集上的性能进行了消融研究,这些提示取自之前使用的 MiBench 数据集。他们在图 1 所示训练管道的每个阶段进行反汇编训练,以比较性能。往返率在通过整个训练数据堆栈时最高,并随每个训练阶段持续下降,尽管往返 BLEU 在每个阶段变化不大。方法。该研究团队在下一个 token 预测和编译器模拟两个基础模型任务上对 LLM Compiler 模型进行消融研究。他们在训练管道的每个阶段进行这种评估,以了解为每个连续任务训练如何影响性能。对于下一个 token 预测,他们在所有优化级别的 LLVM-IR 和汇编代码的小样本上计算困惑度。他们使用两个指标评估编译器模拟:生成的 IR 或汇编代码是否编译,以及生成的 IR 或汇编代码是否与编译器产生的完全匹配。数据集。对于下一个 token 预测,他们使用从与我们训练数据相同分布但未用于训练的小型保留验证数据集。他们使用混合的优化级别,包括未优化代码、用 -Oz 优化的代码和随机生成的 pass 列表。对于编译器模拟,他们使用从 MiBench 生成的 500 个提示进行评估,这些提示使用第 2.2 节描述的方式随机生成的 pass 列表。结果。表 7 显示了 LLM Compiler FTD 在所有训练阶段在两个基础模型训练任务 (下一个 token 预测和编译器模拟) 上的性能。下一个 token 预测性能在 Code Llama 之后急剧上升,后者几乎没有见过 IR 和汇编,并在随后的每个微调阶段略有下降。对于编译器模拟,Code Llama 基础模型和预训练模型表现不佳,因为它们没有在这个任务上训练过。在编译器模拟训练之后直接达到最高性能,其中 LLM Compiler FTD 13B 生成的 95.6% 的 IR 和汇编可以编译,20% 与编译器完全匹配。在进行标志调优和反汇编微调后,性能下降。方法。虽然 LLM Compiler FTD 的目的是为代码优化提供基础模型,但它建立在为软件工程任务训练的基础 Code Llama 模型之上。为评估 LLM Compiler FTD 的额外训练如何影响代码生成的性能,他们使用与 Code Llama 相同的基准套件,评估 LLM 从自然语言提示生成 Python 代码的能力,如「编写一个函数,找出可以从给定的对集合形成的最长链。」数据集。他们使用 HumanEval 和 MBPP 基准,与 Code Llama 相同。结果。表 8 显示了从 Code Llama 基础模型开始的所有模型训练阶段和模型大小的贪婪解码性能 (pass@1)。它还显示了模型在 pass@10 和 pass@100 上的分数,这些分数是用 p=0.95 和 temperature=0.6 生成的。每个以编译器为中心的训练阶段都导致 Python 编程能力略有退化。在 HumanEval 和 MBPP 上,LLM Compiler 的 pass@1 性能最多下降 18% 和 5%,LLM Compiler FTD 在额外的标志调优和反汇编微调后最多下降 29% 和 22%。所有模型在这两个任务上仍然优于 Llama 2。Meta 研究团队已经展示了 LLM Compiler 在编译器优化任务上表现良好,并且相比先前的工作,对编译器表示和汇编代码的理解有所改进,但仍存在一些局限性。主要限制是输入的有限序列长度 (上下文窗口)。LLM Compiler 支持 16k tokens 的上下文窗口,但程序代码可能远远超过这个长度。例如,当格式化为标志调优提示时,67% 的 MiBench 翻译单元超过了这个上下文窗口,如表 10 所示。为了缓解这一问题,他们将较大的翻译单元拆分为单独的函数,尽管这限制了可以执行的优化范围,而且仍有 18% 的拆分翻译单元对模型来说太大,无法作为输入接受。研究人员正在采用不断增加的上下文窗口,但有限的上下文窗口仍然是 LLM 的一个普遍问题。第二个限制,也是所有 LLM 的共同问题,是模型输出的准确性。建议 LLM Compiler 的用户使用特定于编译器的评估基准来评估他们的模型。鉴于编译器并非无 bug,任何建议的编译器优化都必须经过严格测试。当模型反编译汇编代码时,其准确性应通过往返、人工检查或单元测试来确认。对于某些应用,LLM 生成可以被限制在正则表达式内,或与自动验证相结合以确保正确性。https://x.com/AIatMeta/status/1806361623831171318
https://ai.meta.com/research/publications/meta-large-language-model-compiler-foundation-models-of-compiler-optimization/?utm_source=twitter&utm_medium=organic_social&utm_content=link&utm_campaign=fair以上是开发者狂喜!Meta最新发布的LLM Compiler,实现77%自动调优效率的详细内容。更多信息请关注PHP中文网其他相关文章!