


AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
该文章的第一作者帅欣成,目前在复旦大学FVL实验室攻读博士学位,本科毕业于上海交通大学。他的主要研究方向包括图像和视频编辑以及多模态学习。



 和 Editing 算法
和 Editing 算法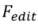 。
。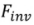 将源图像集合
将源图像集合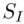 编码到特定的特征或参数空间,得到对应的表征
编码到特定的特征或参数空间,得到对应的表征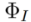 (inversion clue),并用对应的源文本描述
(inversion clue),并用对应的源文本描述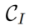 作为源图像的标识符。包括 tuning-based
作为源图像的标识符。包括 tuning-based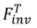 和 forward-based
和 forward-based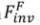 两种类型的 inversion 算法。其可以被形式化为:
两种类型的 inversion 算法。其可以被形式化为: Tuning-based inversion
Tuning-based inversion 通过原有的 diffusion 训练过程将源图像集合植入到扩散模型的生成分布中。形式化过程为:
通过原有的 diffusion 训练过程将源图像集合植入到扩散模型的生成分布中。形式化过程为:

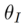 为引入的可学习的参数,且
为引入的可学习的参数,且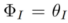 。
。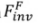 用于在扩散模型的反向过程中(
用于在扩散模型的反向过程中(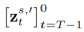 )还原某一条前向路径中的噪声(
)还原某一条前向路径中的噪声(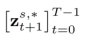 )。形式化过程为:
)。形式化过程为:
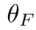 为方法中引入的参数,用于最小化
为方法中引入的参数,用于最小化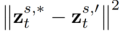 ,其中,
,其中,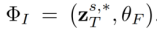 。
。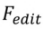 根据
根据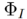 和多模态引导集合
和多模态引导集合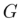 来生成最终的编辑结果
来生成最终的编辑结果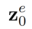 。包含 attention-based
。包含 attention-based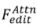 ,blending-based
,blending-based ,score-based
,score-based 以及 optimization-based
以及 optimization-based 的 editing 算法。其可以被形式化为:
的 editing 算法。其可以被形式化为:
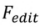 进行了如下操作:
进行了如下操作:
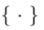 中的操作表示编辑算法对于扩散模型采样过程
中的操作表示编辑算法对于扩散模型采样过程 的干预,用于保证编辑后的图像
的干预,用于保证编辑后的图像 与源图像集合
与源图像集合 的一致性,并反应出
的一致性,并反应出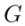 中引导条件所指明的视觉变换。
中引导条件所指明的视觉变换。 。其形式化为:
。其形式化为:
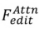 的形式化过程:
的形式化过程:
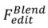 的形式化过程:
的形式化过程:
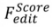 的形式化过程:
的形式化过程:
 的形式化过程:
的形式化过程:



 的算法组合的应用
的算法组合的应用
 的算法组合的应用
的算法组合的应用
 的算法组合的应用
的算法组合的应用
 的算法组合的应用
的算法组合的应用


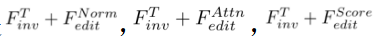
以上是300多篇相关研究,复旦、南洋理工最新多模态图像编辑综述论文的详细内容。更多信息请关注PHP中文网其他相关文章!





















