

互联网上有数十种免费和开源的人工智能文本到图像生成器,专门用于特定类型的图像。因此,我们筛选了一堆,找到了您现在可以尝试的最佳开源人工智能文本到图像生成器。
Craiyon 是最容易访问的开源 AI 图像生成器之一。它基于 DALL-E Mini,虽然您可以克隆 Github 存储库并将模型本地安装在计算机上,但 Craiyon 似乎已经放弃了这种方法,转而采用其网站。
官方 Github 存储库自 2022 年 6 月以来一直没有更新,但最新模型仍然可以在 Craiyon 官方网站上免费获得。也没有 Android 或 iOS 应用程序。
在功能方面,您将看到 AI 图像生成器所期望的所有常用选项。输入提示并获取图像后,您可以使用高档功能来获取更高分辨率的副本。有三种风格可供选择:艺术、照片和绘画。如果您希望模型来决定,您也可以选择“无”选项。
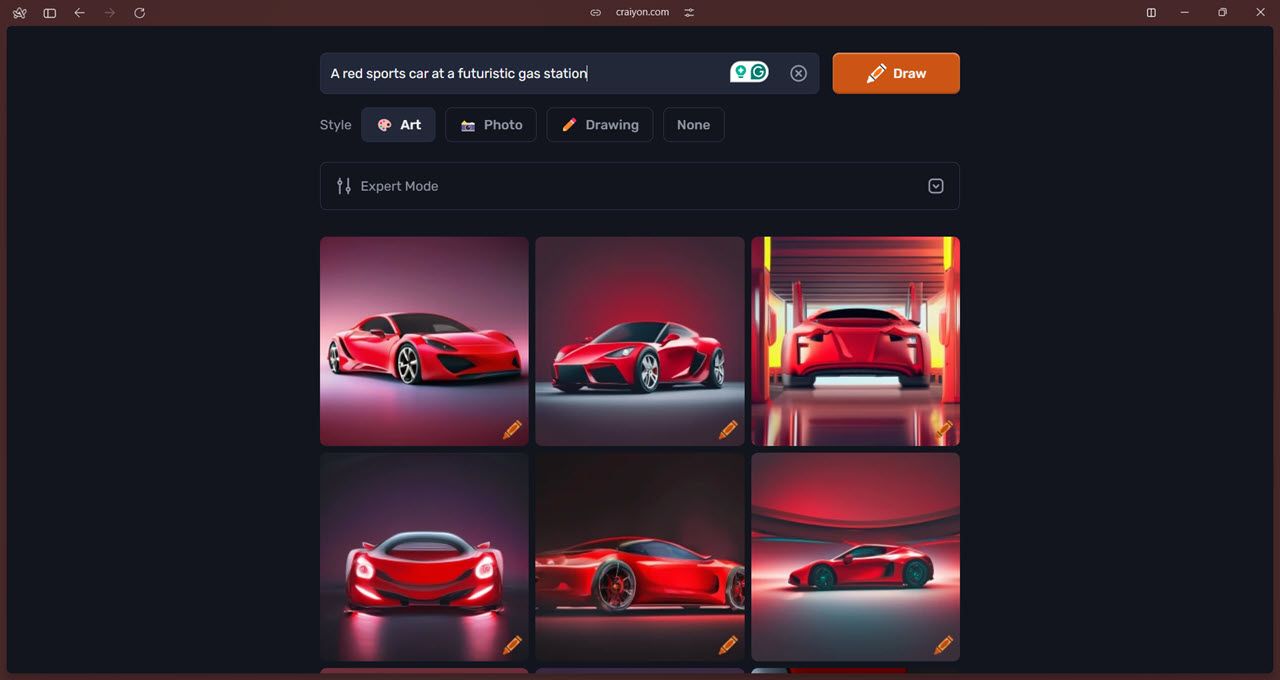
此外,“专家模式”允许您包含否定词,告诉模型避免特定项目。还有一个提示预测功能,它使用 ChatGPT 帮助用户编写尽可能最好、最详细的提示。最后,人工智能驱动的删除背景功能可以帮助您节省从图像中裁剪背景的时间和精力。
这就是 Craiyon 所做的一切。它不是最复杂的人工智能图像生成模型,但如果您不想要详细或真实的东西,它作为基本模型效果很好。
该模型可以免费使用,但免费用户在一分钟内一次只能使用九张免费图像。您可以订阅他们的支持者或专业级别(价格分别为每月 5 美元和 20 美元,按年计费),以获得无广告或水印、更快的生成速度以及将生成的图像保密的选项。自定义订阅层还允许自定义模型、集成、专用支持和专用服务器。
Stable Diffusion 可能是最流行的开源文本到图像生成模型之一。它还为其他模型提供动力,包括下面提到的三个图像生成器。它于 2022 年发布,此后已有多次实现。
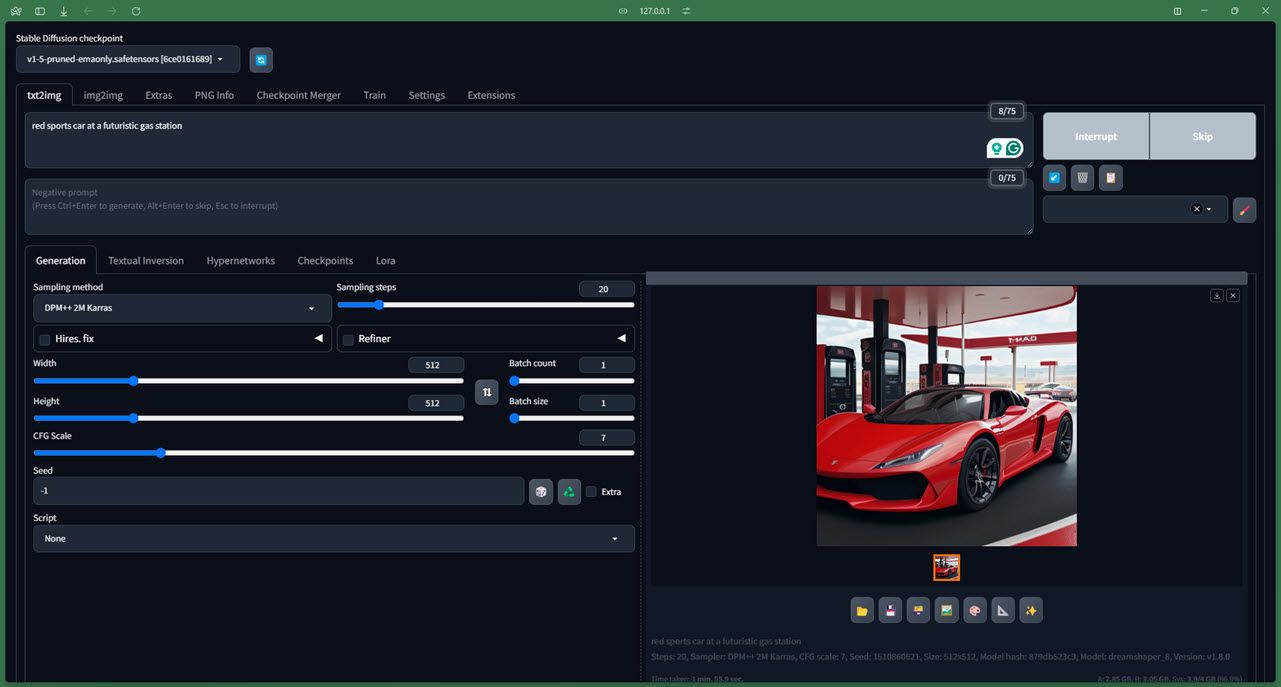
我不会向您介绍该模型如何工作的过多技术细节(您可以查看他们的官方 Github 存储库),但该模型即使对于完全的初学者来说也很容易安装并且运行良好只要您拥有至少 4GB 内存的专用 GPU。您还可以在线访问 Stable Diffusion,如果您想在 Mac 上运行 Stable Diffusion,我们可以为您提供帮助。
有几个检查点(考虑它们的版本)可用于稳定扩散。虽然我们测试了 1.5 版,但 2.1 版也在积极开发中,并且更加精确。

运行模型也相当容易。我们使用 AUTOMATIC1111 Stable Diffusion Web 用户界面对其进行了测试,所有控件和参数都运行良好。由于模型训练所用的 LAION-5B 数据库,它也完全符合 NSFW 标准(请注意,尽管它并不完美)。虽然生成时间本身会根据您的硬件而有所不同,但即使有基本的提示,您也可以期望您的图像是详细且真实的。
DreamShaper 是一种基于稳定扩散的图像生成模型。它的目的是作为 MidJourney 的开源替代品,并专注于生成图像中的真实感,尽管它可以通过一些调整来处理动漫和绘画风格。
该模型比稳定扩散功能更强大,允许用户对最终输出有更大的自由度,从闪电改进到更宽松的 NSFW 限制。运行模型也很容易,可以在线下载预训练版本以供本地访问,并且可以通过许多网站(包括 Sinkin.ai、RandomSeed 和 Mage.space)(需要基本订阅)来运行模型GPU 加速。
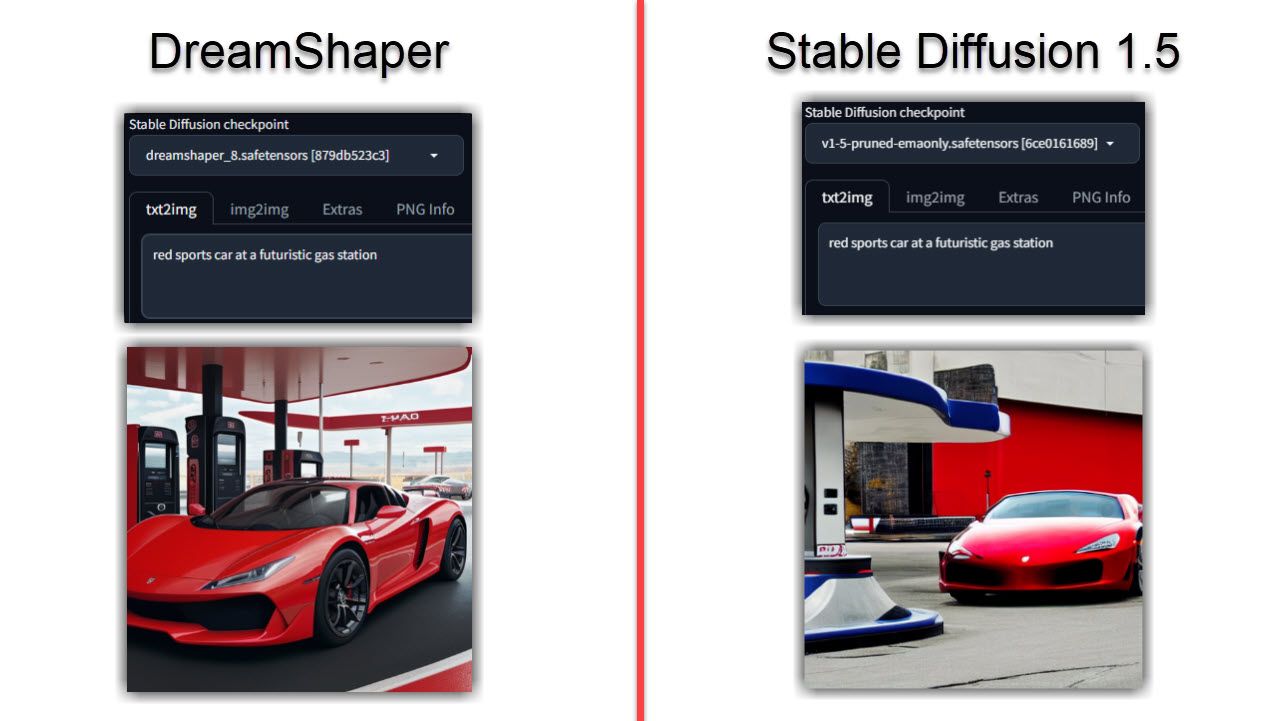
您现在可能已经猜到,与稳定扩散相比,DreamShaper 生成的图像往往看起来更真实。即使您在两个模型上运行相同的提示,DreamShaper 模型也可能会更加真实、详细且光线更好。
对于肖像或人物来说尤其如此,我发现与相同的提示相比,稳定扩散缺乏一些。如果您的图像变得过于真实,可以使用以下四种方法来识别人工智能生成的图像。
您也不需要庞大的 PC 来运行该模型。我的 GTX 1650Ti 配备 4GB VRAM 完美运行该模型。生成时间有点长,但这似乎并不影响实际输出。也就是说,您可能需要具有更多 VRAM 的 GPU 才能运行基于稳定扩散 XL 模型的 DreamShaper XL。
Invoke AI是另一种基于Stable Diffusion的AI图像生成模型,有基于Stable Diffusion XL的XL版本。它还拥有自己的网络和命令行用户界面,这意味着您不必使用稳定扩散网络用户界面之类的东西。
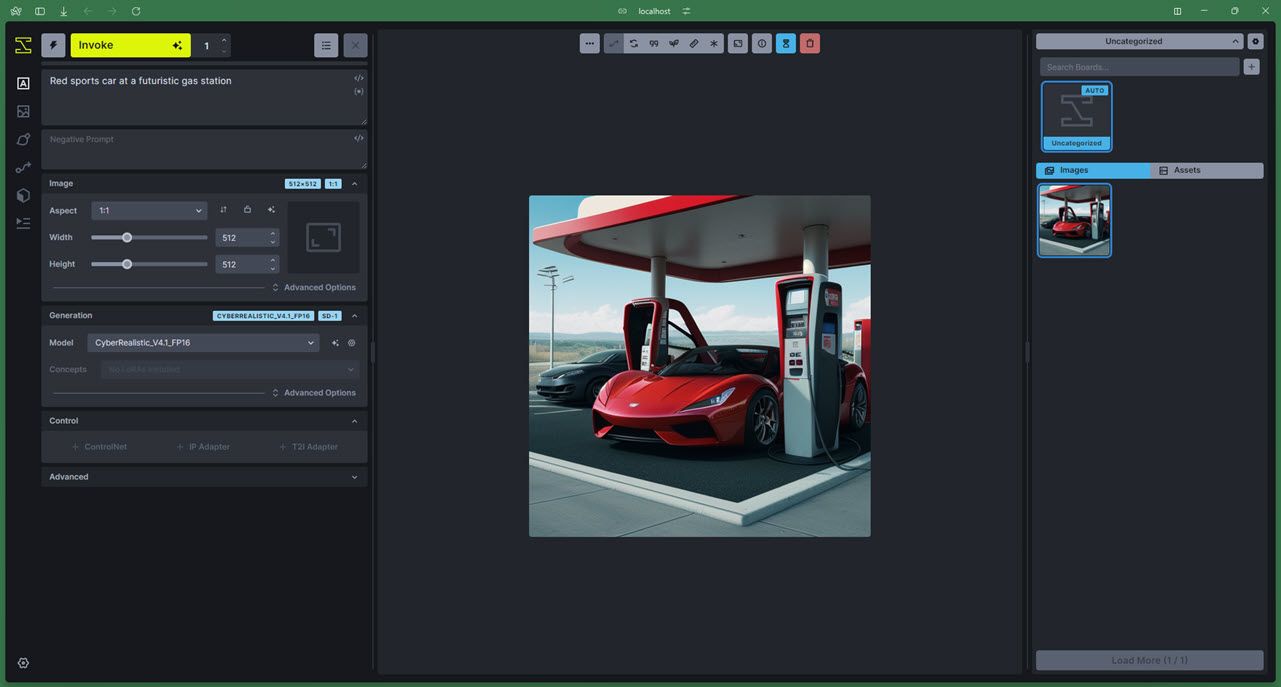
该模型侧重于让用户根据其知识产权通过定制工作流程创建视觉效果。 InvokeAI 是用于训练自定义模型和处理知识产权的最佳开源 AI 图像生成模型之一。
其官方 Github 存储库列出了两种安装方法:通过 InvokeAI 的安装程序安装或使用 PyPI(如果您熟悉终端和 Python 并且需要对随模型安装的包进行更多控制)。
然而,额外的控制确实带来了一些限制,最明显的是更严格的硬件要求。 InvokeAI 建议使用至少具有 4GB 内存的专用 GPU,建议使用 6 到 8GB 来运行 XL 变体。 VRAM 要求适用于 AMD 和 Nvidia GPU。您还需要至少 12GB 的 RAM 和 12GB 的可用磁盘空间用于模型、其依赖项和 Python。

虽然文档不推荐 Nvidia 的 GTX 10 系列和 16 系列 GPU,因为它们缺乏视频内存,但提供的安装程序确实运行得很好。虽然您的情况可能会有所不同,但如果您使用的是低端 GPU,则需要等待更长的时间才能看到提示转换为图像。最后,如果您使用的是 Windows,则只能使用 Nvidia GPU,因为目前不支持 AMD GPU。
对于图像生成部分,模型更倾向于艺术风格而不是照片写实主义。当然,您可以在数据集上训练模型,并让它生成更接近您想要的图像,即使这涉及逼真的图像,特别是如果您在产品设计、建筑或零售空间工作。然而,需要记住的一件重要事情是,InvokeAI 主要是一个图像生成引擎,这意味着您可能必须使用自己的模型才能获得最佳结果(可以通过 Web 界面中提供的模型管理器轻松找到)作为默认值模型与稳定扩散本身非常相似。
Openjourney 是一个免费的开源 AI 图像生成模型,同样基于稳定扩散。如果您想知道为什么该模型被称为 Openjourney,那是因为它是在 Midjourney 图像上进行训练的,并且可以在生成的图像中模仿其风格。
Openjourney 背后的公司 PromptHero 允许您与其他模型一起测试该模型,包括稳定扩散(版本 1.5 和 2)、DreamShaper 和 Realistic Vision。注册时,您将获得 25 个免费积分(每生成一张图像就获得一个积分),之后您必须订阅他们的 Pro 订阅套餐,每月费用为 9 美元,每月可以使用 300 个积分以及其他独家功能。

但是,如果您想在本地免费运行它,您可以从 HuggingFace 下载模型文件并使用 Stable Diffusion Web UI 运行它。 Openjourney 也是 HuggingFace 上下载量第二高的 AI 图像生成模型,仅次于 Stable Diffusion。
Openjourney 并未在其网站上列出本地运行模型的任何具体硬件要求,但您可以预期与 Stable Diffusion 类似的硬件要求。这意味着计算机上需要具有 4GB VRAM、16GB RAM 和大约 12 到 15GB 可用空间的专用 GPU 来保存模型及其依赖项。

除非另有说明,否则 Openjourney 生成的图像往往会在写实主义和艺术之间取得平衡。如果您正在寻找一款全能型号,并且喜欢 Midjourney 的外观和感觉,而无需付费订阅,那么 Openjourney 是最好的选择之一。
以上是5 个最佳开源 AI 图像生成器的详细内容。更多信息请关注PHP中文网其他相关文章!





















