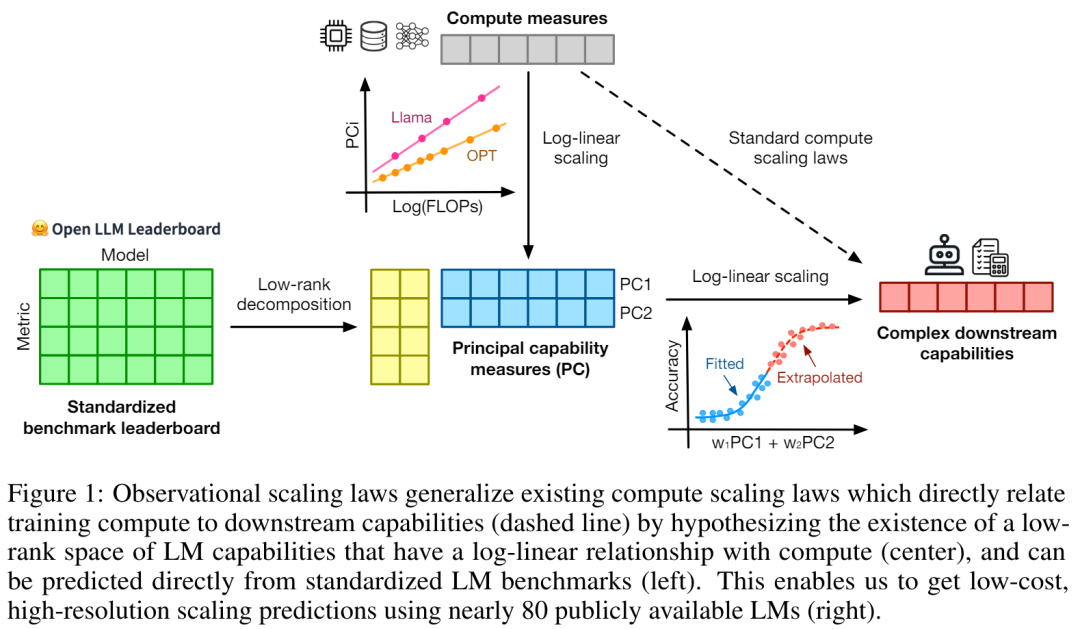
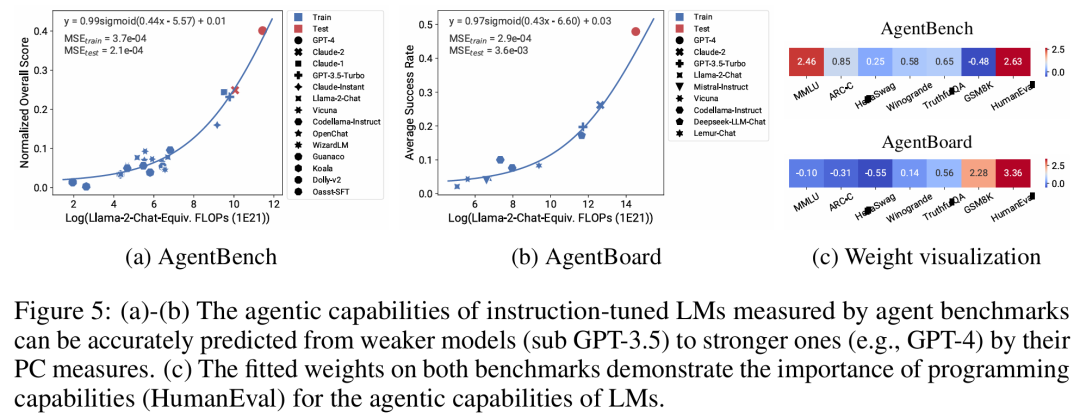
在 AI 领域,扩展定律(Scaling laws)是理解 LM 扩展趋势的强大工具,其为广大研究者提供了一个准则,该定律在理解语言模型的性能如何随规模变化提供了一个重要指导。但不幸的是,扩展分析在许多基准测试和后训练研究中并不常见,因为大多数研究人员没有计算资源来从头开始构建扩展法则,并且开放模型的训练尺度太少,无法进行可靠的扩展预测。来自斯坦福大学、多伦多大学等机构的研究者提出了一种替代观察法:可观察的扩展定律(Observational Scaling Laws),其将语言模型 (LM) 的功能与跨多个模型系列的下游性能联系起来,而不是像标准计算扩展规律那样仅在单个系列内。该方法绕过了模型训练,而是从基于大约 80 个公开可用的模型上建立扩展定律。但这又引出了另一个问题,从多个模型族构建单一扩展定律面临巨大的挑战,原因在于不同模型之间的训练计算效率和能力存在很大差异。尽管如此,该研究表明,这些变化与一个简单的、广义的扩展定律是一致的,在这个定律中,语言模型性能是低维能力空间(low-dimensional capability space)的函数,而整个模型系列仅在将训练计算转换为能力的效率上有所不同。使用上述方法,该研究展示了许多其他类型的扩展研究具有惊人的可预测性,他们发现:一些涌现现象遵循平滑的 sigmoidal 行为,并且可以从小模型中预测;像 GPT-4 这样的智能体性能可以从更简单的非智能体基准中精确预测。此外,该研究还展示了如何预测后训练干预措施(如思维链)对模型的影响。 研究表明,即使仅使用小型 sub-GPT-3 模型进行拟合,可观察的扩展定律也能准确预测复杂现象,例如涌现能力、智能体性能和后训练方法的扩展(例如思维链)。
- 论文地址:https://arxiv.org/pdf/2405.10938
- 论文标题:Observational Scaling Laws and the Predictability of Language Model Performance
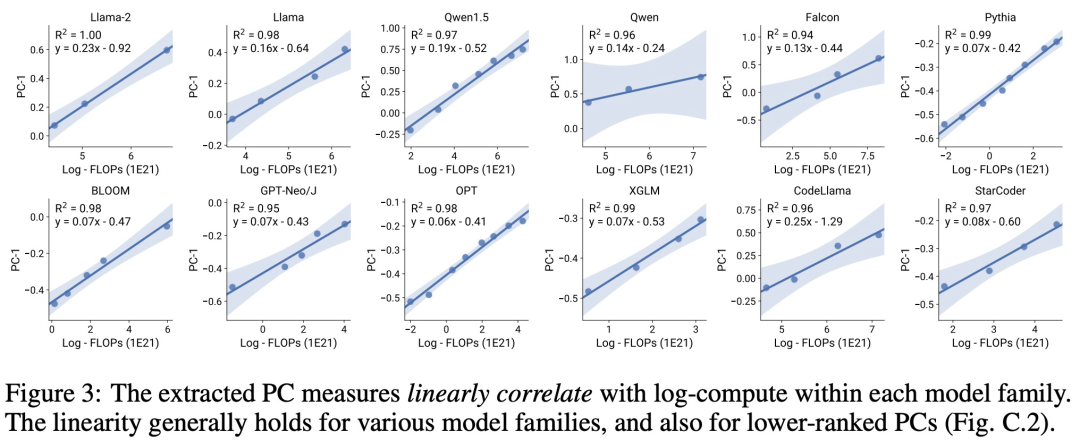
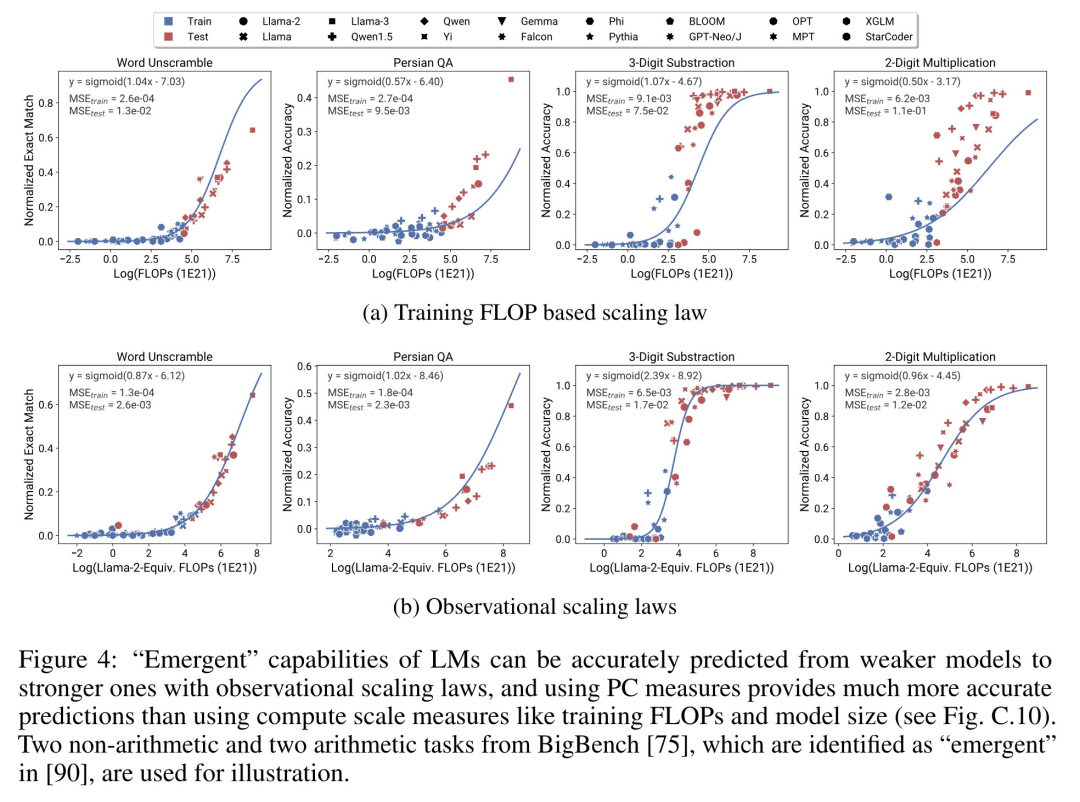
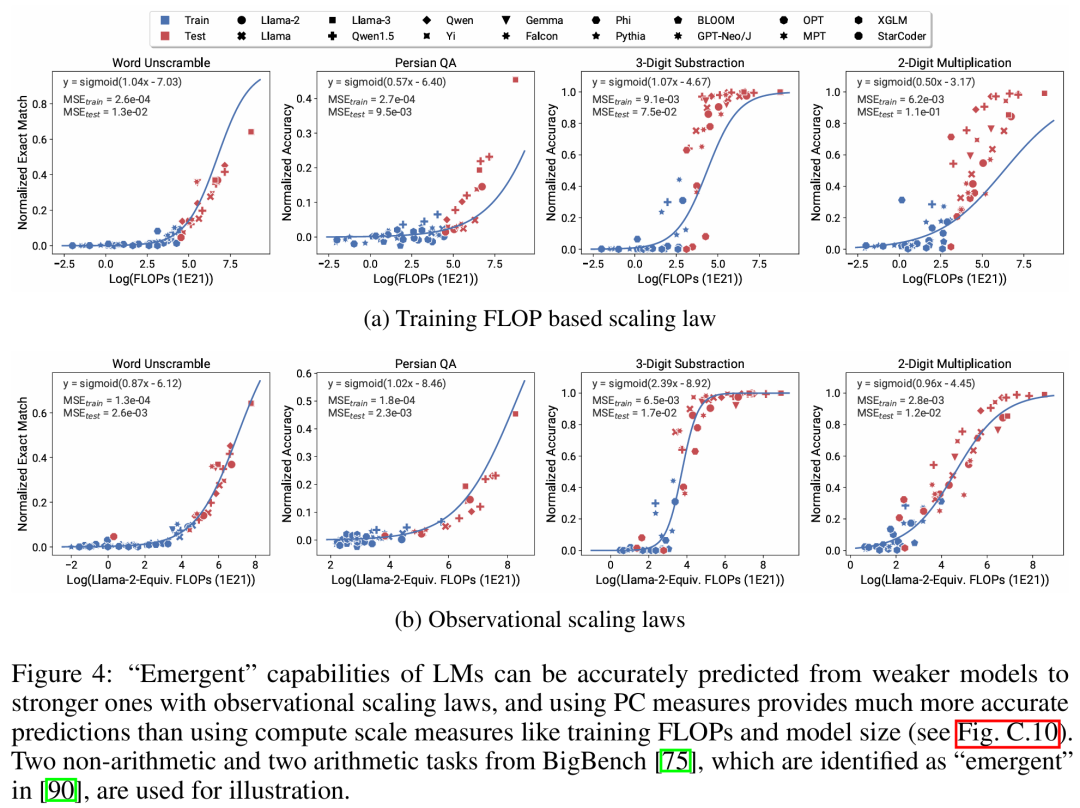
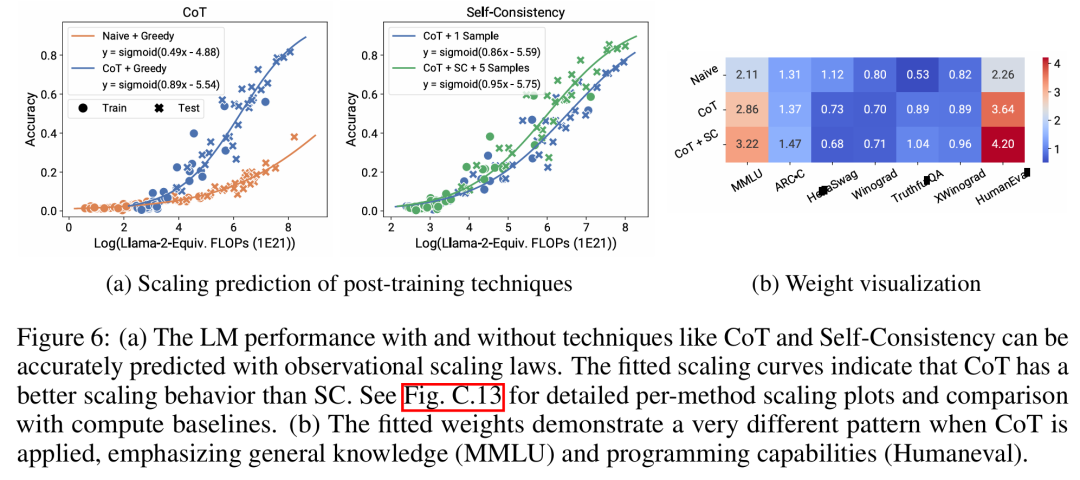
论文作者共有三位,其中 Yangjun Ruan 为华人作者 ,他本科毕业于浙江大学。这篇论文也得到了思维链提出者 Jason Wei 的转发评论,Jason Wei 表示,他非常喜欢这项研究。该研究观察到目前存在数百个开放模型,这些模型拥有不同的规模和能力。不过研究者不能直接使用这些模型来计算扩展定律(因为模型族之间的训练计算效率差异很大),但研究者希望存在一个适用于模型族的更通用的扩展定律。特别是,本文假设 LM 的下游性能是低维能力空间(例如自然语言理解、推理和代码生成)函数,模型族的变化仅仅在于它们将训练计算转换为这些能力的效率。如果这种关系成立,则意味着从低维能力到跨模型族的下游能力存在对数线性关系(这将允许研究者利用现有模型建立扩展定律)(图 1)。该研究使用近 80 个公开可用的 LM 获得了低成本、高分辨率的扩展预测 (右)。通过对标准的 LM 基准分析(例如,Open LLM Leaderboard ),研究者发现了一些这样的能力度量, 这些度量在模型家族内部与计算量之间存在扩展定律关系(R^2 > 0.9)(见下图 3),并且在不同模型家族与下游指标上也存在这种关系。本文将这种扩展关系称为可观察的扩展定律。 最后,该研究表明使用可观察的扩展定律成本低且简单,因为有一些系列模型足以复制该研究的许多核心发现。通过这种方法,该研究发现只需评估 10-20 个模型就可以轻松地对基准和后训练干预进行扩展预测。关于 LM 是否在某些计算阈值下具有不连续出现的「涌现」能力,以及这些能力是否可以使用小模型进行预测,一直存在着激烈的争论。可观察的扩展定律表明,其中一些现象遵循平滑的 S 形曲线,并且可以使用小型 sub Llama-2 7B 模型进行准确预测。该研究表明,正如 AgentBench 和 AgentBoard 所测量的,LM 作为智能体的更高级、更复杂的能力可以使用可观察的扩展定律来预测。通过可观察的扩展定律,该研究仅使用较弱的模型(sub GPT-3.5)就能精确预测 GPT-4 的性能,并将编程能力确定为驱动智能体性能的因素。该研究表明,即使将扩展定律拟合到较弱的模型(sub Llama-2 7B)上,扩展定律也可以可靠地预测后训练方法的收益,例如思维链(Chain-of-Thought)、自洽性(Self-Consistency)等等。总的来说,该研究的贡献是提出可观察的扩展定律,利用了计算、简单能力度量和复杂下游指标之间可预测的对数线性关系。研究者通过实验验证了这些扩展定律的有用性。此外,在论文发布后,研究者还预注册了对未来模型的预测,以测试扩展定律是否对当前的模型过拟合。关于实现过程和收集数据的相关代码已在 GitHub 上放出:GitHub 地址:https://github.com/ryoungj/ObsScaling下图 4 展示了使用 PC(principal capability)度量的预测结果,以及基于训练 FLOPs 来预测性能的基线结果。可以发现,即使仅仅使用性能不佳的模型,也可以使用本文的 PC 度量来准确预测这些能力。相反,使用训练 FLOPs 会导致测试集上的外推效果和训练集上的拟合效果明显更差,正如更高的 MSE 值所示。这些差异可能是由不同模型系列的训练 FLOPs 导致的。下图 5 展示了使用 PC 度量后,可观察的扩展定律的预测结果。可以发现,在两个智能体基准上,使用 PC 度量的留出模型(GPT-4 或 Claude-2)的性能可以从更弱性能(10% 以上的差距)的模型中准确地预测出。这表明 LMs 的更复杂智能体能力与它们的基础模型能力息息相关,并能够基于后者进行预测。这也说明了随着基干 LMs 持续扩展规模,基于 LM 的智能体能力具有良好的扩展特性。下图 6a 展示了使用可观察的扩展定律,CoT 和 SC(Self-Consistency,自洽性)的扩展预测结果。可以发现,使用 CoT 和 CoT+SC 但不使用(Naive)后训练技术的更强、规模更大模型的性能可以从更弱、更小计算规模(比如模型大小和训练 FLOPs)的模型中准确预测出。值得注意的是,两种技术之间的扩展趋势不同,其中与使用 CoT 的自洽性相比,CoT 表现出更明显的扩展趋势。以上是从80个模型中构建Scaling Law:华人博士生新作,思维链提出者力荐的详细内容。更多信息请关注PHP中文网其他相关文章!