

哭死啊,全球狂煉大模型,一網路的資料不夠用,根本不夠用。
訓練模型搞得跟《飢餓遊戲》似的,全球AI研究者,都在苦惱怎麼才能餵飽這群數據大胃王。
尤其在多模態任務中,這問題尤其突出。
一籌莫展之際,來自人大系的初創團隊,用自家的新模型,率先在國內把“模型生成數據自己餵自己”變成了現實。
而且還是理解側和生成側雙管齊下,兩側都能產生高品質、多模態的新數據,對模型本身進行數據反哺。
模型是啥?
中關村論壇上剛剛露面的多模態大模型Awaker 1.0。
團隊是誰?
智子引擎。 由人大高瓴人工智慧學院博士生高一鑷創立,高瓴人工智慧學院盧志武教授擔任顧問。公司成立時還是2021年,就早早打入多模態這條「無人區」賽道。
這不是智子引擎第一次發布模型。
去年3月8日,潛心研發兩年的團隊對外發布了自研的第一個多模態模型,百億級參數的ChatImg序列模型,並基於此推出世界首個公開評測多模態對話應用ChatImg(元乘象)。
後來,ChatImg不斷迭代,新模型Awaker的研發也在並行推進。後者也繼承了前代模型的基礎能力。
相較於前代的ChatImg序列模型,Awaker 1.0採用了MoE模型架構。
要說原因嘛,是想要解決解決多模態多工訓練有嚴重衝突的問題。
採用MoE模型架構,可以更好地學習多模態通用能力以及各個任務所需的獨特能力,從而讓整個Awaker 1.0的能力在多個任務上有進一步提升。
資料勝千言:
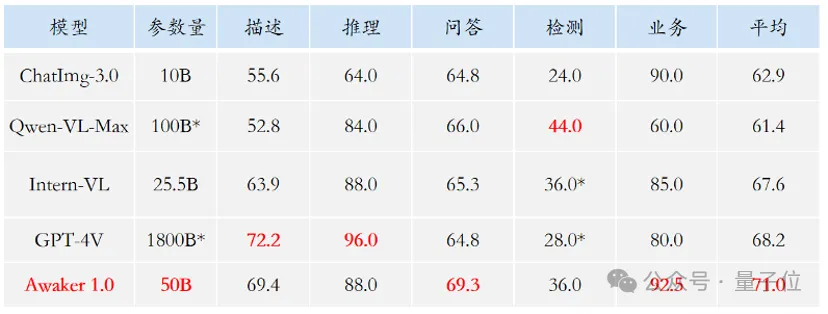
鑑於主流多模態評測名單存在評測資料外洩問題,智子團隊從嚴建置了自有評測集,大部分測試圖片來自個人手機相簿。
表格顯示,團隊讓Awaker 1.0和國內外最先進的3個多模態大模型進行了評測。
多提一嘴,由於GPT-4V和Intern-VL並不直接支援偵測任務,它們的偵測結果是透過要求模型使用語言描述物件方位得到的。
可以看到,在視覺問答和業務應用任務上,Awaker 1.0的基座模型超過了GPT-4V、Qwen-VL-Max和Intern-VL。
在描述、推理和偵測任務上,Awaker 1.0的基座模型達到了次好效果。
最後來看平均分,Awaker 1.0處於幾者中的最高值。
因此,上述結果也印證了多任務多模態模型採用MoE架構的有效性。
資料集評測結果有了,真實效果還需進一步上手體驗。
這裡主要問了它和對比大模型一些關於中文OCR(圖片文字辨識)和計數問題、詳細描述任務等問題。
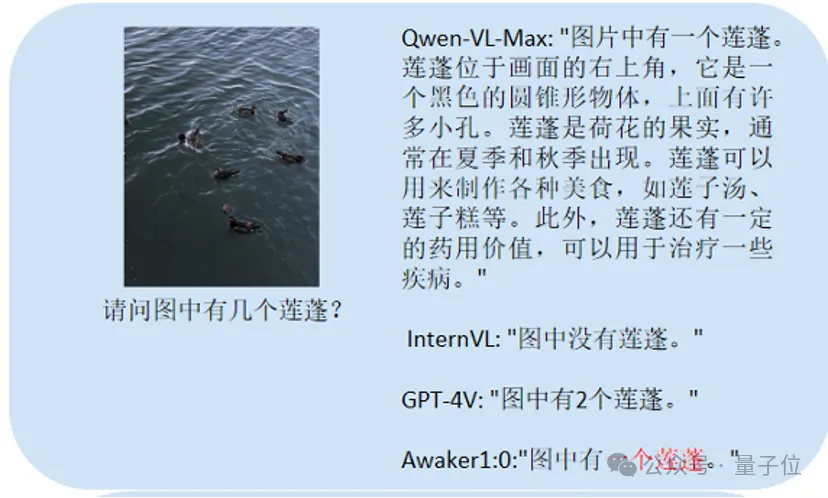
這個主要考計數:
Awaker 1.0能正確地給出答案,而其它三個模型都回答錯誤。
這個主要考中文OCR#:
正確回答的選手是Qwen-VL-Max和Awaker 1.0。

最後這題考圖片內容理解。
GPT-4V和Awaker 1.0不但能夠詳細地描述圖片的內容,而且能夠準確地辨識出圖片中的細節,如圖中所顯示的可口可樂。

不得不提一嘴的是,Awaker 1.0繼承了一些智子團隊先前廣為關注的研究成果。
說的就是你-Awaker 1.0的#產生側邊#。
Awaker 1.0的生成側,是智子引擎自主研發的類Sora視頻生成底座VDT(Video Diffusion Transformer)。
VDT的學術論文早於OpenAI Sora的發布(去年5月),並已被頂會ICLR 2024接收。

ディスプレイの独自の革新性は主に 2 点あります。
1 つ目は、技術アーキテクチャに Diffusion Transformer を採用することです。OpenAI が登場する前に、ビデオ生成の分野における Transformer の大きな可能性が示されました。
その利点は、時間の経過に伴う 3 次元オブジェクトの物理ダイナミクスのシミュレーションなど、時間的に一貫したビデオ フレームを生成できる優れた時間依存キャプチャ機能にあります。
2 つ目は、VDT がさまざまなビデオ生成タスクを処理できるようにするための、統合された時空間マスク モデリング メカニズムを提案することです。 単純なトークン空間スプライシングなどの VDT の柔軟な条件付き情報処理方法は、さまざまな長さや形式の情報を効果的に統合します。
同時に、本研究で提案した時空間マスクモデリング機構と組み合わせることで、VDTは一般的なビデオ拡散ツールとなり、モデル構造を変更することなく無条件生成やビデオの後続フレーム予測に適用できます。 、フレーム挿入、画像生成ビデオ、ビデオ画面完成およびその他のビデオ生成タスク。
Sophon エンジン チームは、VDT による単純な物理法則のシミュレーションを研究しただけでなく、
物理プロセスをシミュレートできることも発見したことがわかりました。:
 は、
は、
超リアルなポートレート ビデオ生成タスク # についても詳細な調査を実施しました。 肉眼は顔や人の動的な変化に非常に敏感であるため、このタスクではビデオ生成の品質に対して非常に高い要件が求められます。しかし、Sophon エンジンは、超リアルなポートレート ビデオ生成のための主要なテクノロジーのほとんどを突破しており、Sora に劣らない優れた性能を持っています。
あなたの言うことには根拠がありません。
これは、ポートレートビデオ生成の品質を向上させるために、VDT と制御可能な生成を組み合わせた Sophon エンジンの効果です:
Sophon エンジンは、キャラクター制御可能な生成アルゴリズムの最適化を継続し、積極的に行うと報告されています。商業探査を実施します。
新しいインタラクティブ データの安定したストリームの生成
Awaker 1.0 は、
世界初の自己更新型マルチモーダル大規模モデル。 言い換えれば、Awaker 1.0 は「ライブ」であり、そのパラメータはリアルタイムで継続的に更新できます。これが、Awaker 1.0 を他のすべてのマルチモーダル大規模モデルとは異なるものにしています。 1.0 の更新メカニズムには、次の 3 つの主要なテクノロジが含まれています。 #これら 3 つのテクノロジーにより、Awaker 1.0 は独立して学習し、自動的に反映し、独立して更新できるため、世界を自由に探索し、人間と対話することもできます。
これに基づいて、Awaker 1.0 は、理解する側と生成する側の両方で新しいインタラクティブ データの安定したストリームを生成できます。
どうやってやったのですか?
生成側では、
Awaker 1.0 は高品質のマルチモーダル コンテンツ生成を実行でき、理解側モデルにより多くのトレーニング データを提供します。
Awaker 1.0 は、理解側と生成側の 2 つのループで、視覚的な理解と視覚的な生成の統合を実際に実現します。 ご存知のように、Sora の登場以降、AGI を達成するには「理解と生成の統一」が達成されなければならないという声がますます増えてきました。
新しい知識の注入を例として、ランスルーの具体的な例を見てみましょう。Awaker 1.0 は、インターネット上のリアルタイムのニュース情報を継続的に学習すると同時に、新しく学習したニュース情報を組み合わせて、さまざまな複雑な質問に答えます。 これは、現在主流の 2 つのメソッド、つまり RAG と従来のロング コンテキスト メソッドとは異なります。Awaker 1.0 は、実際には
独自のモデルのパラメーターに関する新しい知識を「記憶」します#。 ##。
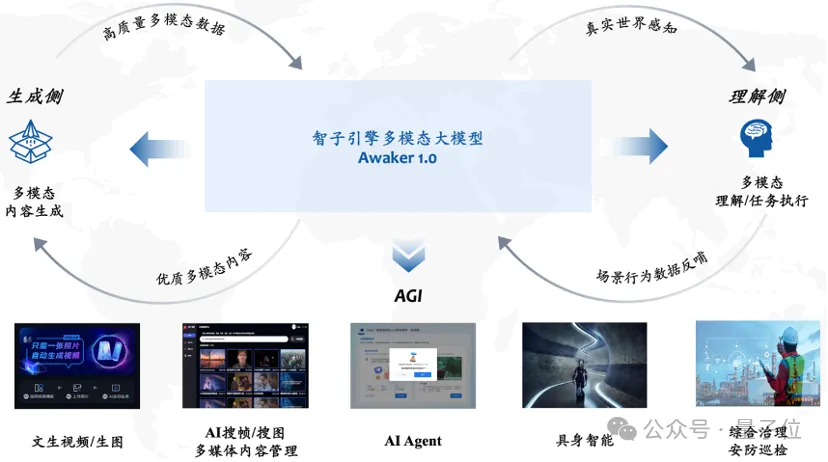 連続 3 日間の自己更新プロセス中に、Awaker 1.0 が毎日その日のニュース情報を学習し、対応する情報を正確に記述できることがわかります。説明。
連続 3 日間の自己更新プロセス中に、Awaker 1.0 が毎日その日のニュース情報を学習し、対応する情報を正確に記述できることがわかります。説明。
そして、Awaker 1.0 は学習を続けていますが、学んだ知識をすぐに忘れることはありません。
たとえば、4 月 16 日に学習した Zhijie S7 に関連する知識は、2 日後も Awaker 1.0 によって記憶または理解されていました。
ですから、データが金のようなこの時代に、「データが足りない」と嘆くのはやめてください。 データのボトルネックに直面しているチームにとって、Awaker 1.0 は実現可能で使用可能な新しいオプションではないでしょうか? そうは言っても、視覚理解と視覚生成が統合されているからこそ、「マルチモーダルな大きなモデルが身体化された知性に適応する」のです。 " "Awaker 1.0 のプライドが明確に明らかになりました。 問題は次のとおりです: Awaker 1.0 のような大規模なマルチモーダル モデルの視覚的理解機能は、身体化された知性の「目」と自然に組み合わせることができます。 そして主流派はまた、「マルチモーダル大規模モデルの身体化インテリジェンス」には、身体化インテリジェンスの適応性と創造性を大幅に向上させる可能性があり、AGI を実現する実現可能な道であると信じています。 理由は2点に過ぎません。 第一に、人々は、身体化されたインテリジェンスが適応可能であること、つまり、エージェントが継続的な学習を通じて変化するアプリケーション環境に適応できることを期待しています。 このようにして、身体化された知能は、既知のマルチモーダル タスクでますます優れたパフォーマンスを発揮できるだけでなく、未知のマルチモーダル タスクにも迅速に適応することができます。 第二に、人々はまた、身体化された知性が真に創造的であることを期待しており、環境の自律的な探索を通じて新しい戦略や解決策を発見し、境界を探索できることを期待しています。 AIの能力について。 しかし、この 2 つの適応は、単純に大規模なマルチモーダル モデルを身体にリンクしたり、身体化された知性の中に脳を直接組み込んだりするほど単純ではありません。 マルチモーダルな大規模モデルを例に挙げると、少なくとも 2 つの明らかな問題が直面しています。 第一に、モデルの反復更新サイクルが長くなります。これには多くの人的投資が必要です;第二に、モデルのトレーニング データモデルはすべて既存のデータから派生したものであるため、モデル は大量の新しい知識を継続的に取得することはできません。 RAG とコンテキスト ウィンドウの拡張を通じて継続的に出現する新しい知識を注入することも可能ですが、モデルはそれを記憶することができず、修復方法はさらなる問題を引き起こします。 つまり、現在の大規模なマルチモーダル モデルは、創造性はおろか、実際のアプリケーション シナリオにおける高い適応性もなく、業界で実装する際には常にさまざまな困難を引き起こします。 素晴らしい - 先ほど述べたことを思い出してください。Awaker 1.0 は新しい知識を学習できるだけでなく、新しい知識を記憶することもできます。この種の学習は毎日、継続的かつタイムリーに行われます。 #このフレームワーク図からわかるように、Awaker 1.0 はさまざまなスマート デバイスと組み合わせることができ、スマート デバイスを通じて世界を観察し、行動意図を生成し、コマンド制御を自動的に構築できます。インテリジェンス デバイスはさまざまなアクションを実行します。 (狗头) 特に重要なのは、Awaker 1.0# は独立して更新できることです。 ## は、身体化されたインテリジェンスに適応できるだけでなく、より幅広い業界シナリオにも適用でき、より複雑な実践的なタスクを解決できます。 たとえば、Awaker 1.0 はさまざまなスマート デバイスと統合され、クラウド エッジのコラボレーションを実現します。 現時点では、Awaker 1.0 はクラウドに展開された「頭脳」であり、さまざまなタスクを実行するためにさまざまなエッジ スマート デバイスを監視、命令、制御します。 さまざまなタスクを実行するときにエッジ スマート デバイスによって取得されるフィードバックは、継続的に Awaker 1.0 に送信され、トレーニング データを継続的に取得し、継続的に自身を更新できるようになります。 これは単なる机上の話ではありません。Awaker 1.0 とスマート デバイスとのクラウド エッジ コラボレーションの技術的なルートは、スマート グリッド検査やスマート シティなどのアプリケーション シナリオに適用され、以前よりもはるかに高い評価を獲得しています。伝統的な小型モデル。 マルチモーダル大型模型にとって、内なる力の涵養と武術の向上は重要な課題となっていると言えるでしょう。 Sophon エンジン Awaker 1.0 の出現は、マルチモーダル大規模モデルの自己超越への鍵を提供します。 それは、独立した更新メカニズムを通じて、データ不足のボトルネックを打破し、マルチモーダルな大規模モデルの継続的な学習と自己進化の可能性を提供します。クラウドエッジコラボレーションテクノロジーを使用し、身体化されたインテリジェンスなどのインテリジェントデバイスの特定のアプリケーションシナリオを勇敢に探索します。 これは AGI への小さな一歩かもしれませんが、マルチモーダル大規模モデルの自己超越の旅の始まりでもあります。 長くて困難な旅には、Sophon Engine のようなチームがテクノロジーの頂点に継続的に登る必要があります。 身体化された知性の「生きた」脳
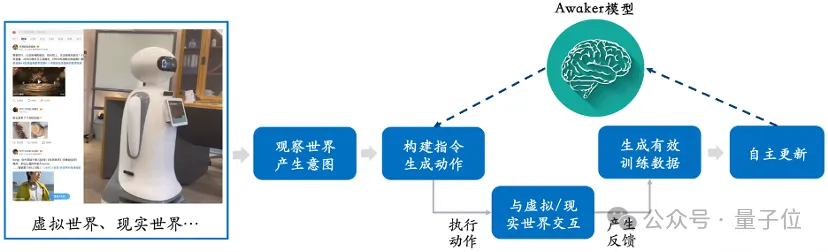
 しかし、その問題は明らかです。新しい知識を継続的に吸収し、新しい変化に適応するにはどうすればよいでしょうか。
しかし、その問題は明らかです。新しい知識を継続的に吸収し、新しい変化に適応するにはどうすればよいでしょうか。
以上是超級智能體生命力覺醒!可自我更新的AI來了,媽媽再也不用擔心資料瓶頸難題的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















