


近日,來自小紅書搜尋演算法團隊的論文《Generative Dense Retrieval: Memory Can Be a Burden》被自然語言處理領域國際會議EACL 2024 接收為Oral,接受率為11.32%(144/1271)。
他們在論文中提出了一個新穎的資訊檢索範式-生成式密集檢索(Generative Dense Retrieval,GDR)。 此範式能夠很好地解決傳統生成式檢索(Generative Retrieval,GR)在處理大規模資料集時所面臨的挑戰。它是從記憶機制得到的靈感。
在過往的實踐中,GR憑藉其獨特的記憶機制,實現了查詢與文件庫間的深度互動。然而,這種依賴語言模型自回歸編碼的方法,在處理大規模資料時存在明顯的局限性,包括細粒度文檔特徵模糊、文檔庫規模受限、索引更新困難等。
小紅書提出的GDR 採用由粗到細的兩階段檢索思想,首先利用語言模型有限的記憶容量,實現查詢到文檔將的映射,然後透過向量匹配機製完成文件將到文件的精細映射。 GDR 透過引入密集集檢索的向量匹配機制,有效緩解了 GR 的固有弊端。
此外,團隊也設計了「記憶友善的文檔簇標識符建構策略」與「文檔簇自適應的負採樣策略」,分別提升了兩階段的檢索效能。在Natural Questions 資料集的多個設定下,GDR 不僅展現了SOTA 的Recall@k 表現,更在保留深度交互優勢的同時實現了良好的可擴展性,為資訊檢索的未來研究開闢了新的可能性。
文本搜尋工具具有重要的研究與應用價值。傳統搜尋範式,如基於字詞匹配度的稀疏檢索(sparse retrieval, SR)和基於語義向量匹配度的密集檢索(dense retrieval, DR),雖然各有千秋,但隨著預訓練語言模型的興起,基於此的生成式檢索範式開始嶄露頭角。 生成式檢索範式的開端主要基於查詢和候選文件之間的語意匹配度。透過將查詢和文件對應到同一語意空間,將候選文件的檢索問題轉換為向量匹配度的密集檢索。這種開創性的檢索範式利用了預訓練語言模型的優勢,為文字搜尋領域帶來了新的機會。 然而,生成式檢索範式仍面臨挑戰。一方面,現有的預訓
在訓練過程中,模型以給定查詢作為上下文,自回歸地產生相關文件的識別碼。這個過程實現了模型對於候選語料庫的記憶。查詢進入模型後與模型參數交互並自回歸解碼,隱式地產生了查詢與候選語料庫的深度交互,而這種深度交互正是 SR 和 DR 所缺少的。因此,當模型能夠準確記憶候選文件時,GR 能夠表現出優異的檢索表現。
儘管GR的記憶機轉並非無懈可擊。我們透過經典DR模型(AR2)與GR模型(NCI)之間的比較實驗,證實了記憶機制至少會帶來三大挑戰:
我們分別計算了NCI 和AR2 在由粗到細解碼文檔標識符的每一位時發生錯誤的機率。對於 AR2,我們透過向量匹配找到給定查詢最相關的文檔對應的標識符,然後統計標識符的首次出錯步數,得到 AR2 對應的分步解碼錯誤率。如表1所示,NCI 在解碼的前半段中表現良好,而後半段錯誤率較高,AR2 與之相反。這說明 NCI 透過整體記憶庫,能較好地完成查找到候選文檔語意空間的粗粒度映射。但由於訓練過程中的選擇特徵是由查找來決定的,因此其細粒度映射難以被準確記憶,故而在細粒度映射時表現不佳。

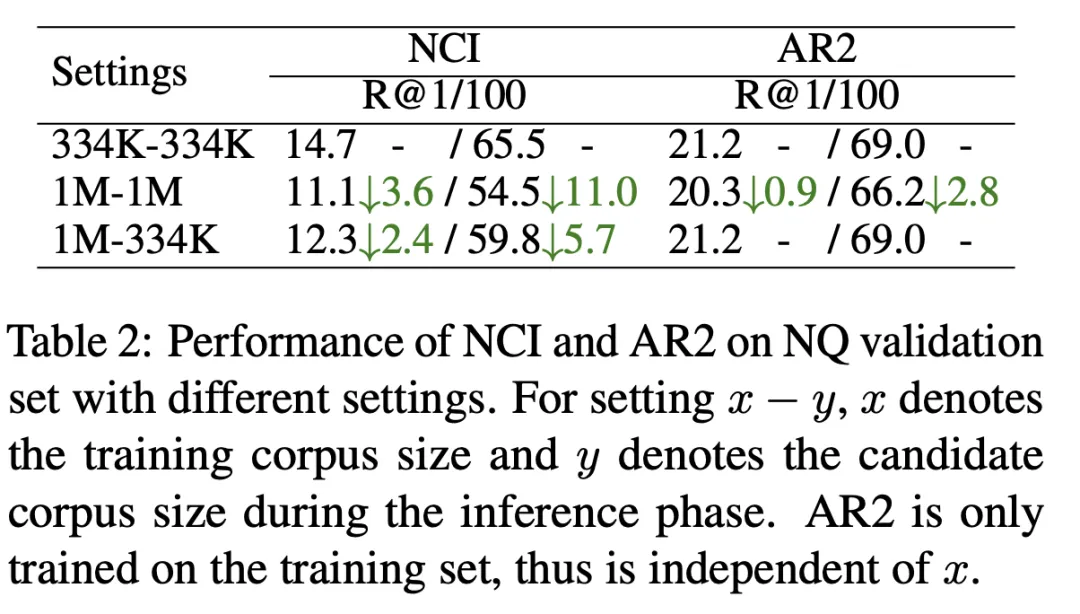
如表 2 所示,我们分别以 334K 的候选文档库大小(第一行)和 1M 的候选文档大小(第二行)训练了 NCI 模型并以 R@k 指标进行测试。结果表明 NCI 在 R@100 上下降了 11 point,对比之下 AR2 只下降了 2.8 point。为了探究候选文档库规模扩大使 NCI 性能显著下降的原因,我们进一步测试了在 1M 文档库上训练的 NCI 模型在以 334K 为候选文档库时的测试结果(第三行)。与第一行相比,NCI 记忆更多文档的负担导致了其召回性能的显著下降,这说明模型有限的记忆容量限制了其记忆大规模的候选文档库。
当新文档需要加入候选库时,需要更新文档标识符,并且需要重新训练模型以重新记忆所有文档。否则,过时的映射关系(查询到文档标识符和文档标识符到文档)将显著降低检索性能。
上述问题阻碍了 GR 在真实场景下的应用。为此,我们在分析后认为 DR 的匹配机制与记忆机制有着互补的关系,因此考虑将其引入 GR,在保留记忆机制的同时抑制其带来的弊端。我们提出了生成式密集检索新范式(Generative Dense Retrieval,GDR):
以查询作为输入,我们利用语言模型记忆候选文档库,并自回归生成 k 个相关文档簇(CID),完成如下映射:
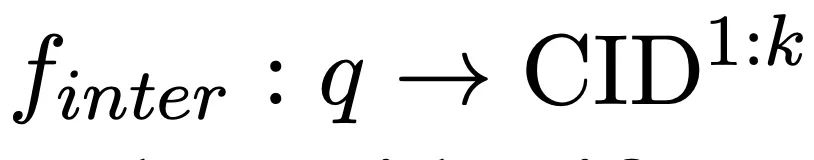
在这一过程中,CID 的生成概率为:
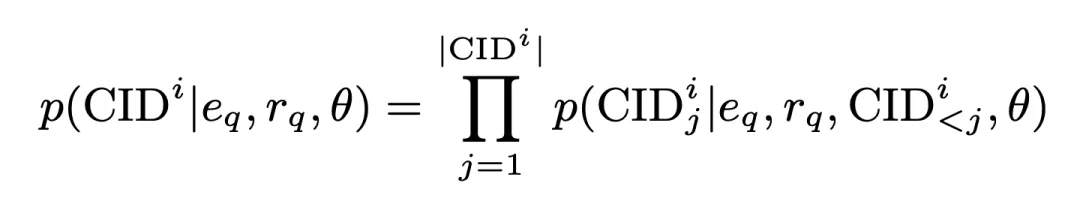
其中
是编码器产生的所有查询嵌入,
是编码器产生的一维查询表征。该概率同时作为簇间匹配分数被存储,参与后续运算。基于此,我们采用标准交叉熵损失训练模型:
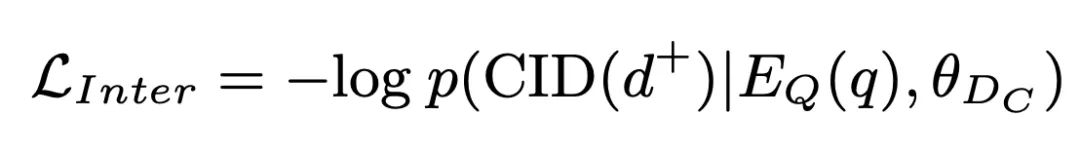
我们进一步从候选文档簇内检索候选文档,完成簇内匹配:
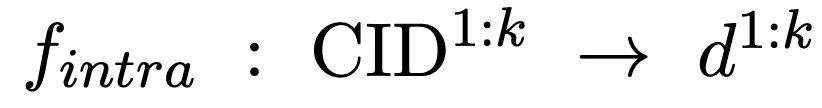
我们引入一个文档编码器提取候选文档的表征,这一过程会离线完成。以此为基础,计算簇内文档与查询间的相似度,作为簇内匹配分数:

在这一过程中,NLL loss 被用来训练模型:
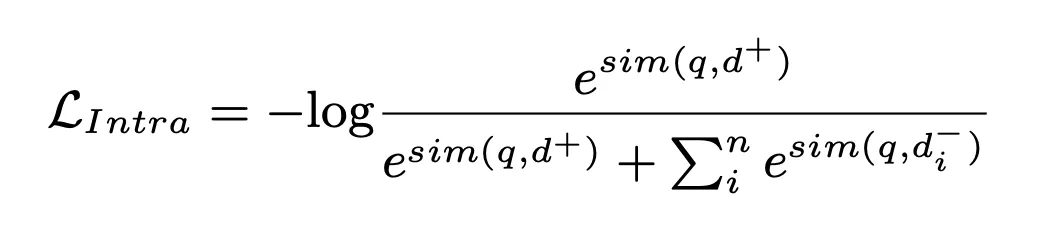
最后,我们计算文档的簇间匹配分数与簇内匹配分数的加权值并进行排序,选出其中的 Top K 作为检索出的相关文档:
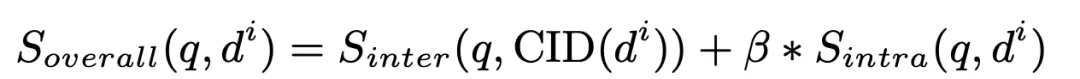
其中 beta 在我们的实验中设定为 1。
為了充分利用模型有限的記憶容量實現查詢與候選文檔庫之間的深度交互,我們提出記憶友善的文檔簇標識符建構策略。此策略首先以模型記憶容量為基準,計算簇內文檔數上限:
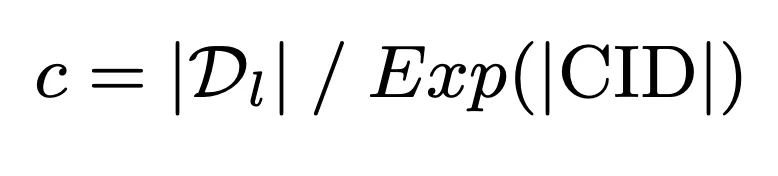
#在此基礎上,進一步透過K-means 演算法構建文檔簇標識符,保障模型的記憶負擔不超過其記憶容量:

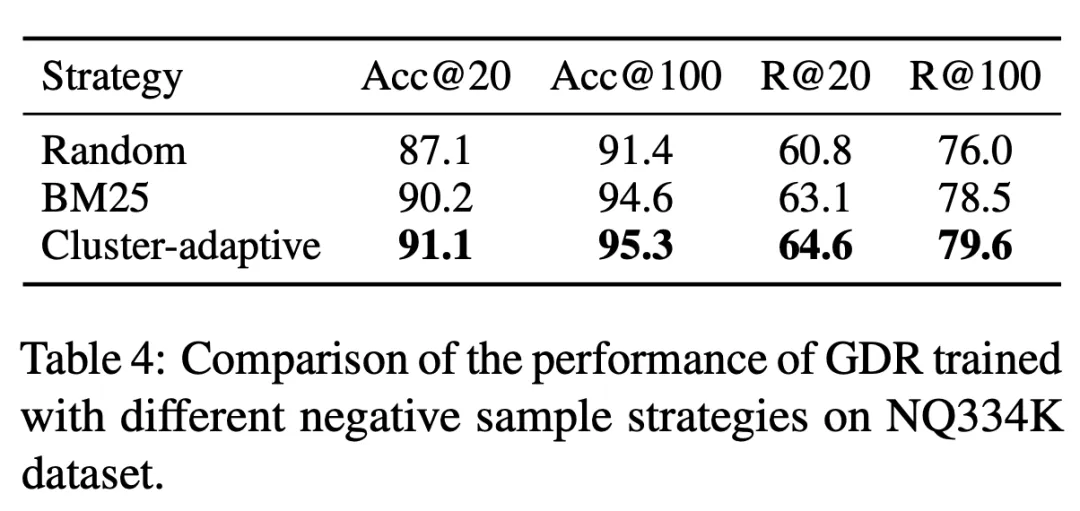
GDR 兩階段的檢索框架決定了在簇內配對過程中簇內的負樣本所佔比例較大。為此,我們在第二階段訓練過程中以文檔簇劃分為基準,明確增強了簇內負樣本的權重,從而獲得更好的簇內匹配效果:
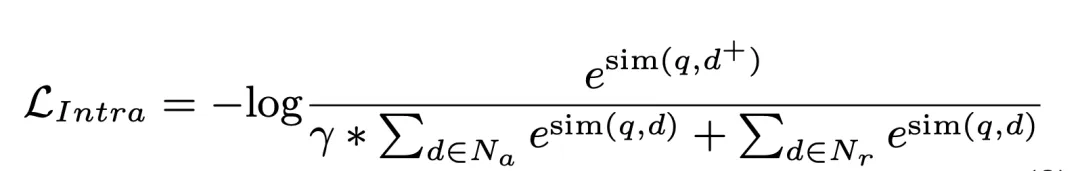
#實驗中所使用的資料集為Natural Questions (NQ),它包含58K 個訓練對(查詢和相關文件)以及6K 個驗證對,伴隨著21M 個候選文檔庫。每個查詢多個相關文檔,這對模型的召回性能提出了更高的要求。為了評估 GDR 在不同規模文件庫上的效能,我們建立了 NQ334K、NQ1M、NQ2M 和 NQ4M 等不同設置,透過向 NQ334K 添加來自完整 21M 語料庫的其餘段落來實現。 GDR 在每個資料集上分別產生 CIDs,以防止更大候選文件庫的語意資訊外洩到較小的語料庫中。我們採用 BM25(Anserini 實現)作為 SR 基線,DPR 和 AR2 作為 DR 基線,NCI 作為 GR 的基線。評估指標包括 R@k 和 Acc@k。
在NQ 資料集上,GDR 在R@k 指標上平均提高了3.0,而在Acc@ k 指標上排名第二。這表明 GDR 透過粗到細的檢索過程,最大化了記憶機制在深度互動和匹配機制在細粒度特徵辨別中的優勢。
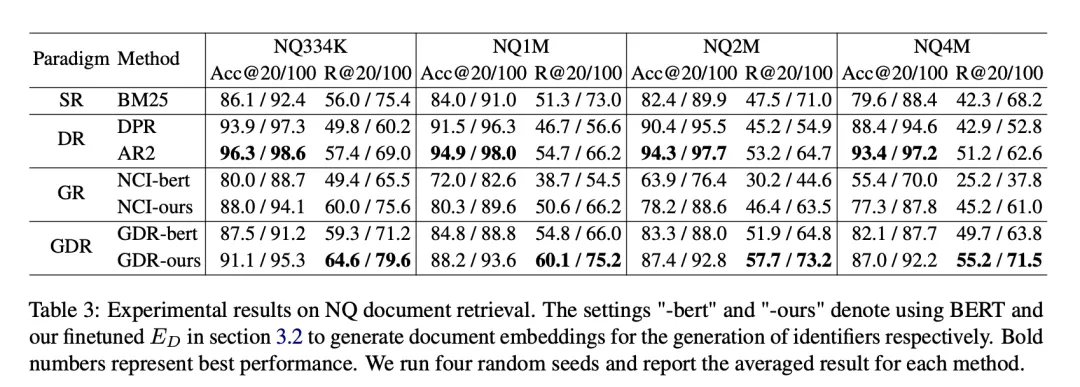
我們注意到當候選語料庫擴展到更大的規模時,SR 和DR 的R@100 下降率保持在4.06% 以下,而GR 在所有三個擴展方向上的下降率超過了15.25%。相較之下,GDR 透過將記憶內容集中在固定體量的語料庫粗粒度特徵上,實現了平均 3.50% 的 R@100 下降率,與 SR 和 DR 相似。
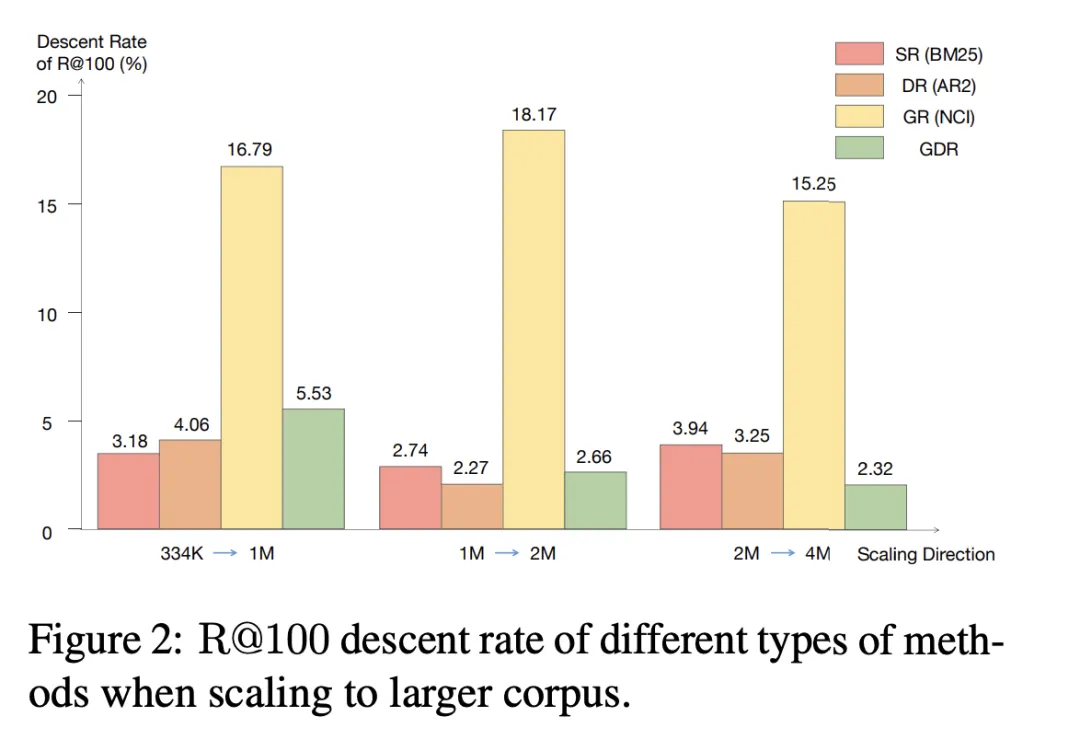
#表3 GDR- bert 與GDR-ours 分別代表了傳統和我們的CID 構建策略下對應的模型表現,實驗證明使用記憶友好的文檔簇標識符構建策略,可以顯著減輕記憶負擔,從而帶來更好的檢索性能。此外,表 4 顯示 GDR 訓練時採用的文檔簇自適應的負採樣策略,透過提供更多的文檔簇內辨別訊號,增強了細粒度匹配能力。
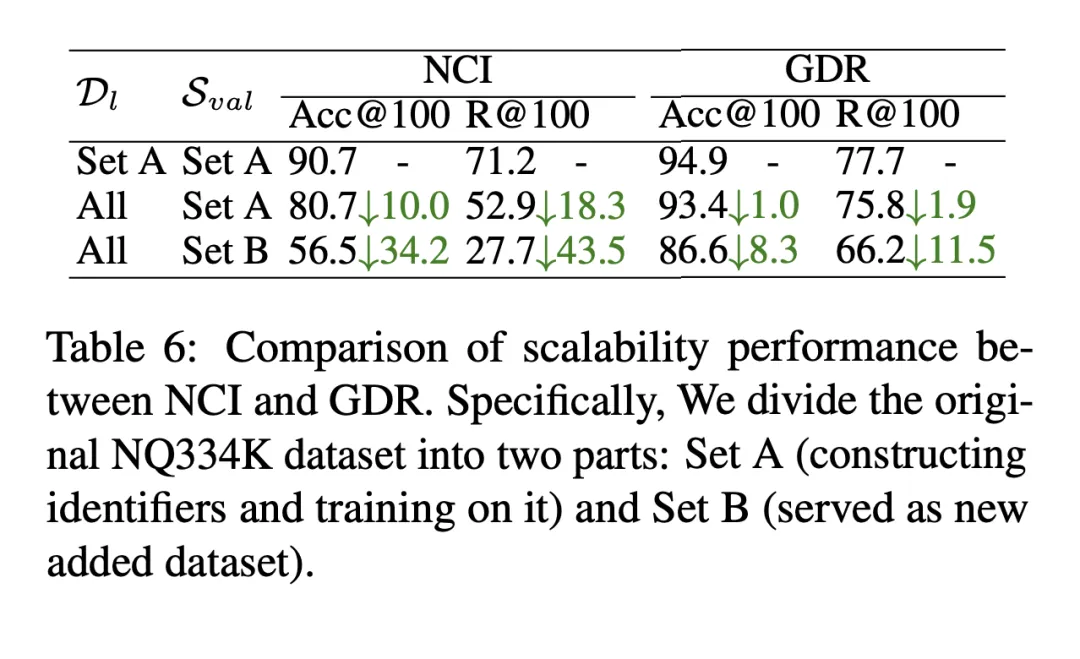
當有新文檔加入候選文檔庫時,GDR 將新文檔加入距離最近的文檔簇聚類中心,並賦予相應標識符,同時透過文檔編碼器提取向量表徵更新向量索引,從而完成對新文檔的快速擴展。如表 6 所示,在新增文件到候選語料庫的設定下,NCI 的 R@100 下降了 18.3 個百分點,而 GDR 的效能僅下降了 1.9 個百分點。這表明 GDR 透過引入匹配機制來緩解記憶機制的難以擴展性,在無需重新訓練模型的情況下保持了良好的回想效果。
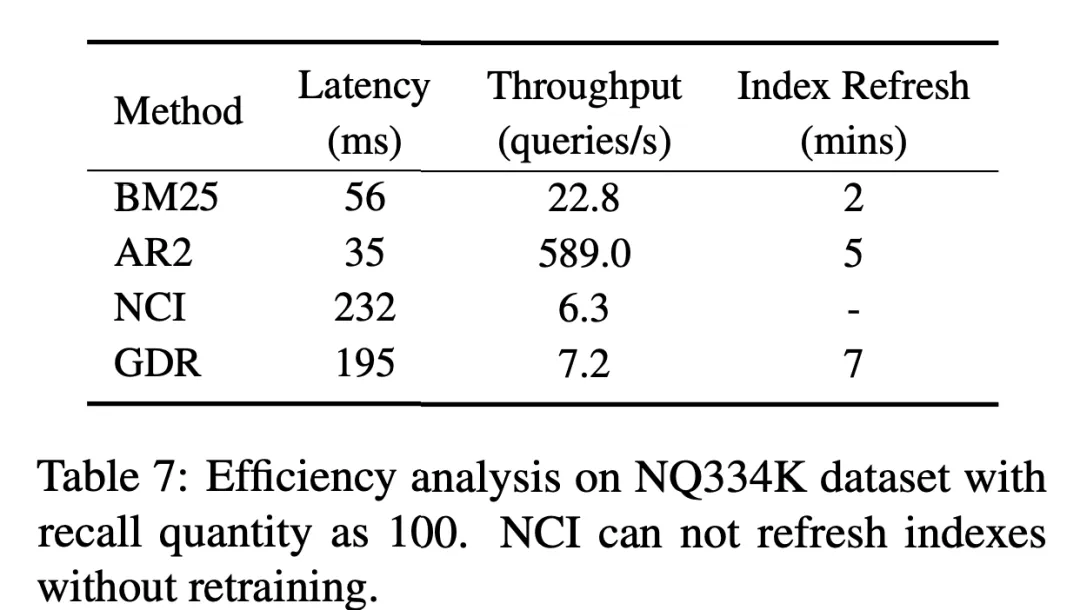
受限于语言模型自回归生成的特点,尽管 GDR 在第二阶段引入了向量匹配机制,相比于 GR 实现了显著的检索效率提升,但相比于 DR 与 SR 仍有较大的提升空间。我们期待未来有更多的研究帮助缓解记忆机制引入检索框架时带来的时延问题。
本项研究中,我们深入探讨了记忆机制在信息检索中的双刃剑效应:一方面这一机制实现了查询与候选文档库的深度交互,弥补了密集检索的不足;另一方面模型有限的记忆容量与更新索引的复杂性,它在面对大规模和动态变化候选文档库时显得捉襟见肘。为了解决这一难题,我们创新性地将记忆机制与向量匹配机制进行层次化结合,实现两者扬长避短、相得益彰的效果。
我们提出了一个全新的文本检索范式,生成式密集检索(GDR)。GDR 该范式对于给定查询进行由粗到细的两阶段检索,先由记忆机制自回归地生成文档簇标识符实现查询到文档簇的映射,再由向量匹配机制计算查询与文档间相似度完成文档簇到文档的映射。
记忆友好的文档簇标识符构建策略保障了模型的记忆负担不超过其记忆容量,增益簇间匹配效果。文档簇自适应的负采样策略增强了区分簇内负样本的训练信号,增益簇内匹配效果。大量实验证明,GDR 在大规模候选文档库上能够取得优异的检索性能,同时能够高效应对文档库更新。
作为一次对传统检索方法进行优势整合的成功尝试,生成式密集检索范式具有召回性能好、可扩展性强、在海量候选文档库场景下表现稳健等优点。随着大语言模型在理解与生成能力上的不断进步,生成式密集检索的性能也将进一步提升,为信息检索开辟更加广阔的天地。
论文地址://m.sbmmt.com/link/9e69fd6d1c5d1cef75ffbe159c1f322e
以上是小紅書從記憶機制解讀資訊檢索,提出新典範取得 EACL Oral的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















