引入混合深度,DeepMind 新設計可大幅提升 Transformer 效率。
Transformer 的重要性不需要多言,目前也有很多研究團隊致力於改進這種變革性技術,其中一個重要的改進方向是提升Transformer 的效率,例如讓其具備自適應運算能力,從而可以節省下不必要的計算。 正如不久前Transformer 架構的提出之一、NEAR Protocol 聯合創始人Illiya Polosukhin 在與黃仁勳的對話中說到的那樣:「自適應計算是接下來必須出現的。 我們要關注,在特定問題上具體要花費多少計算資源。各種不同的問題時,會自然分配不同的時間和精力。  語言建模也應如此,為了得到準確的預測結果,並不需要為所有 token 和序列都投入相同的時間或資源。但是,Transformer 模型在一次前向傳播中卻會為每個 token 花費同等的計算量。這不禁讓人哀嘆:大部分計算都浪費了! 理想情況下,如果可以不執行非必要的計算,就可以降低 Transformer 的計算預算。 條件式計算此技術可在需要執行計算時才執行計算,由此可減少總計算量。先前許多研究者已經提出了多種可以評估何時執行計算以及使用多少計算量的演算法。 但是,對於這個頗具挑戰性的問題,普遍使用的解決形式可能無法很好地應對現有的硬體限制,因為它們往往會引入動態計算圖。最有潛力的條件式計算方法反而可能是那些能協調使用當前硬體棧的方法,其會優先使用靜態計算圖和已知的張量大小(基於對硬體的最大利用而選取這個張量大小)。 最近,Google DeepMind 研究了這個問題,他們希望使用更低的運算預算來縮減 Transformer 所使用的運算量。 論文標題:Mixture-of-Depths: Dynamically allocating compute in transformer-based language models
語言建模也應如此,為了得到準確的預測結果,並不需要為所有 token 和序列都投入相同的時間或資源。但是,Transformer 模型在一次前向傳播中卻會為每個 token 花費同等的計算量。這不禁讓人哀嘆:大部分計算都浪費了! 理想情況下,如果可以不執行非必要的計算,就可以降低 Transformer 的計算預算。 條件式計算此技術可在需要執行計算時才執行計算,由此可減少總計算量。先前許多研究者已經提出了多種可以評估何時執行計算以及使用多少計算量的演算法。 但是,對於這個頗具挑戰性的問題,普遍使用的解決形式可能無法很好地應對現有的硬體限制,因為它們往往會引入動態計算圖。最有潛力的條件式計算方法反而可能是那些能協調使用當前硬體棧的方法,其會優先使用靜態計算圖和已知的張量大小(基於對硬體的最大利用而選取這個張量大小)。 最近,Google DeepMind 研究了這個問題,他們希望使用更低的運算預算來縮減 Transformer 所使用的運算量。 論文標題:Mixture-of-Depths: Dynamically allocating compute in transformer-based language models
- #論文網址:https://arxiv.org/pdf/2404.02258.pdf
他們設想:在每一層中,網路必須學會為每個token 做決策,從而動態地分配可用計算預算。在他們的具體實現中,總計算量由使用者在訓練之前設定並且不再更改,而非網路工作時執行決策的函數。這樣一來,便可以提前預知並利用硬體效率收益(例如記憶體足跡減少量或每次前向傳播的 FLOPs 減少量)。該團隊的實驗顯示:可以在不損害網路整體效能的前提下獲得這些效益。
DeepMind 的這個團隊採用了類似於混合專家(MoE) Transformer 的方法,其中會在整個網路深度上執行動態 token 層面的路由決策。 而與MoE 不同的是,這裡他們的選擇是:要嘛是將計算套用在token(和標準Transformer 一樣),要嘛就是透過一個殘差連接繞過它(保持不變,節省計算)。另一個與 MoE 的不同之處是:這裡是將這個路由機制同時用在 MLP 和多頭注意力上。因此,這也會影響網路處理的鍵值和查詢,因此該路由不僅要決定更新哪些 token,還要決定哪些 token 可供關注。 DeepMind 將此策略命名為Mixture-of-Depths(MoD),以突顯這一事實:各個token 在Transformer 深度上通過不同數量的層或模組。我們這裡將其翻譯成「混合深度」,見圖 1。 MoD 支援使用者權衡考慮效能與速度。一方面,使用者可以使用與常規 Transformer 同等的訓練 FLOPs 來訓練 MoD Transformer,這為最終的對數機率訓練目標帶來多達 1.5% 的提升。另一方面,MoD Transformer 使用更少的計算量就能達到與常規 Transformer 同樣的訓練損失 —— 每一次前向傳播的 FLOPs 可少最多 50%。 這些結果表明,MoD Transformer 可以學習智慧地路由(即跳過不必要的計算)。
- 設定一個靜態的計算預算,該預算低於等價的常規Transformer 所需的計算量;做法是限制序列中可參與模組計算(即自註意力模組和後續的MLP)的token 數量。舉個例子,常規 Transformer 可能允許序列中的所有 token 都參與自註意力計算,但 MoD Transformer 可限定僅使用序列中 50% 的 token。
- 針對每個token,每個模組中都有一個路由演算法給予一個標量權重;該權重表示路由對各個token 的偏好- 是參與模組的計算還是繞過去。
- 在每個模組中,找出最大的前 k 個標量權重,它們對應的 token 會參與到這個模組的計算中。由於必定只有 k 個 token 參與到該模組的計算中,因此其計算圖和張量大小在訓練過程中是靜態的;這些 token 都是路由演算法認定的動態且與上下文有關的 token。
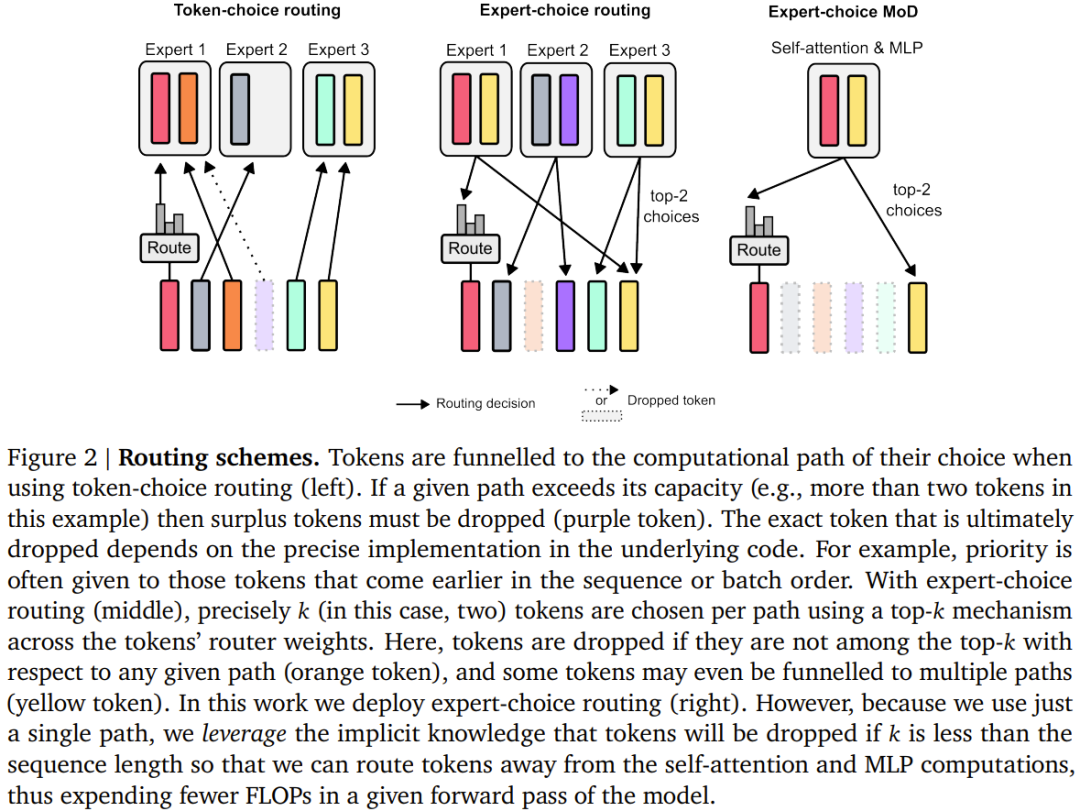
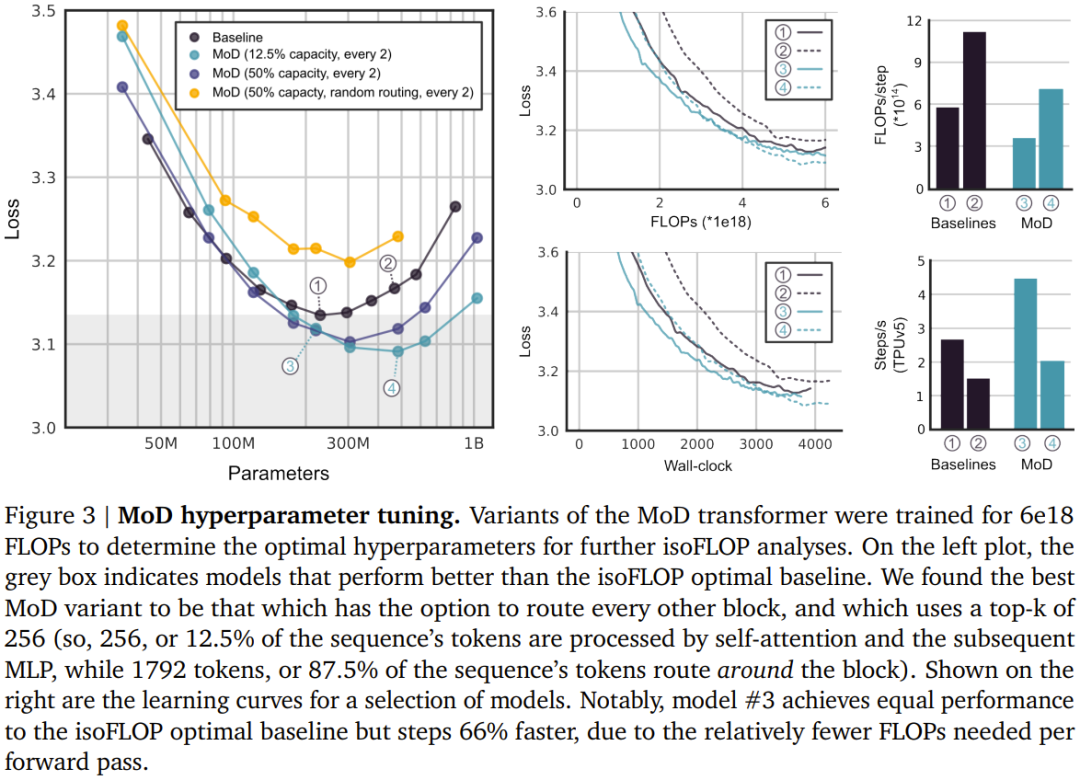
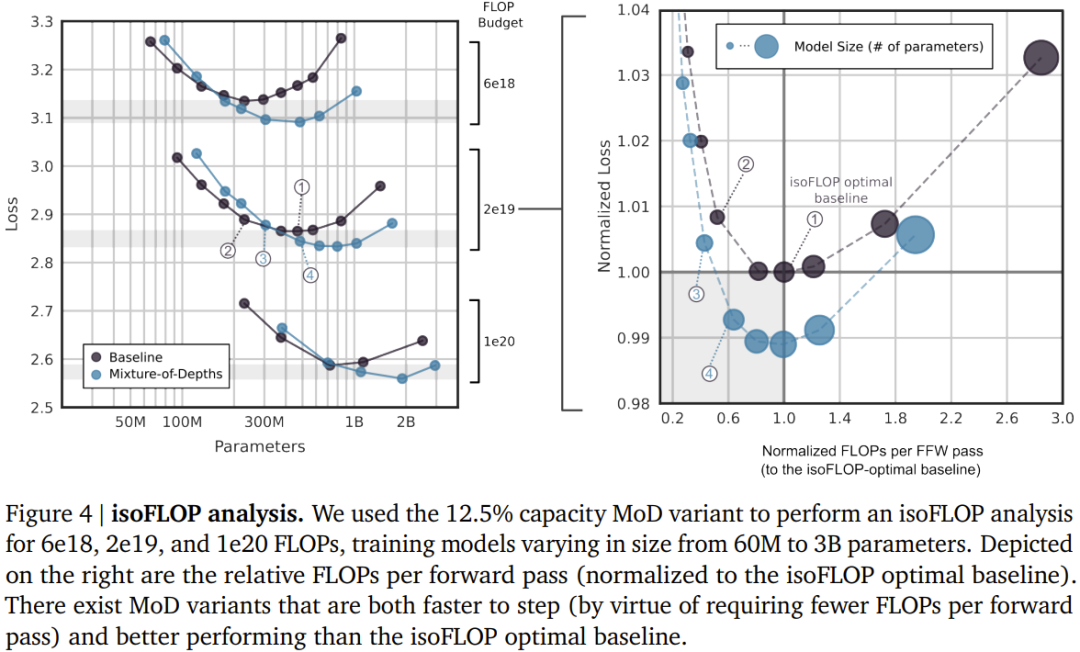
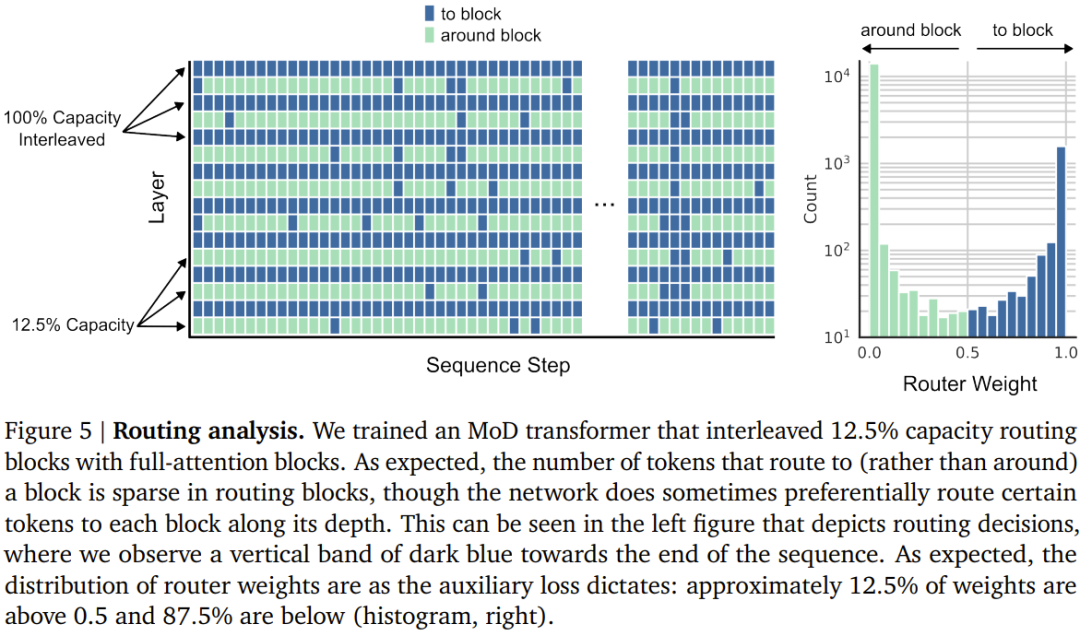
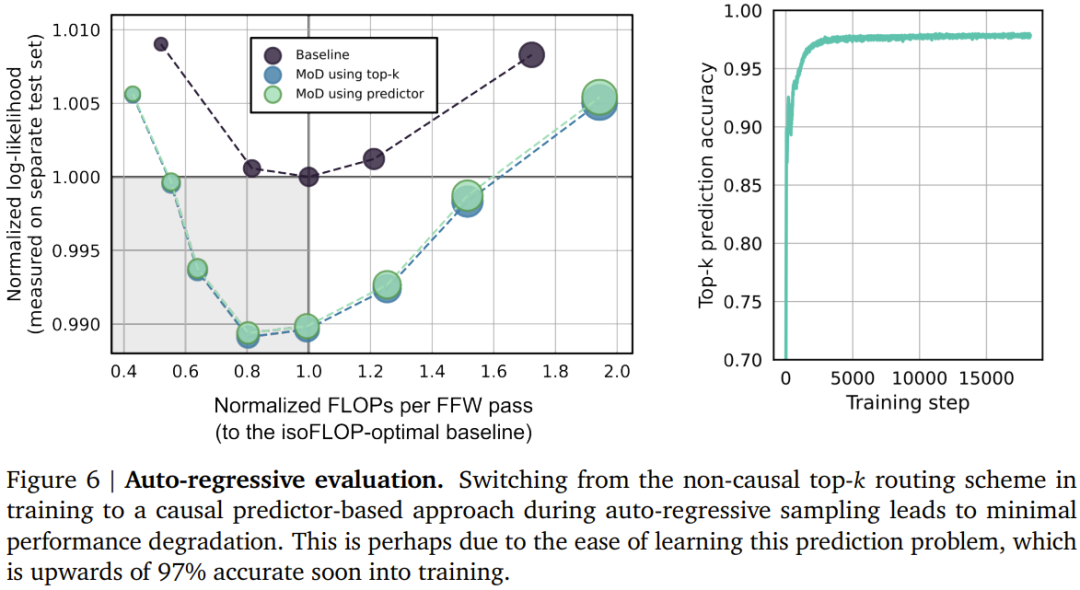
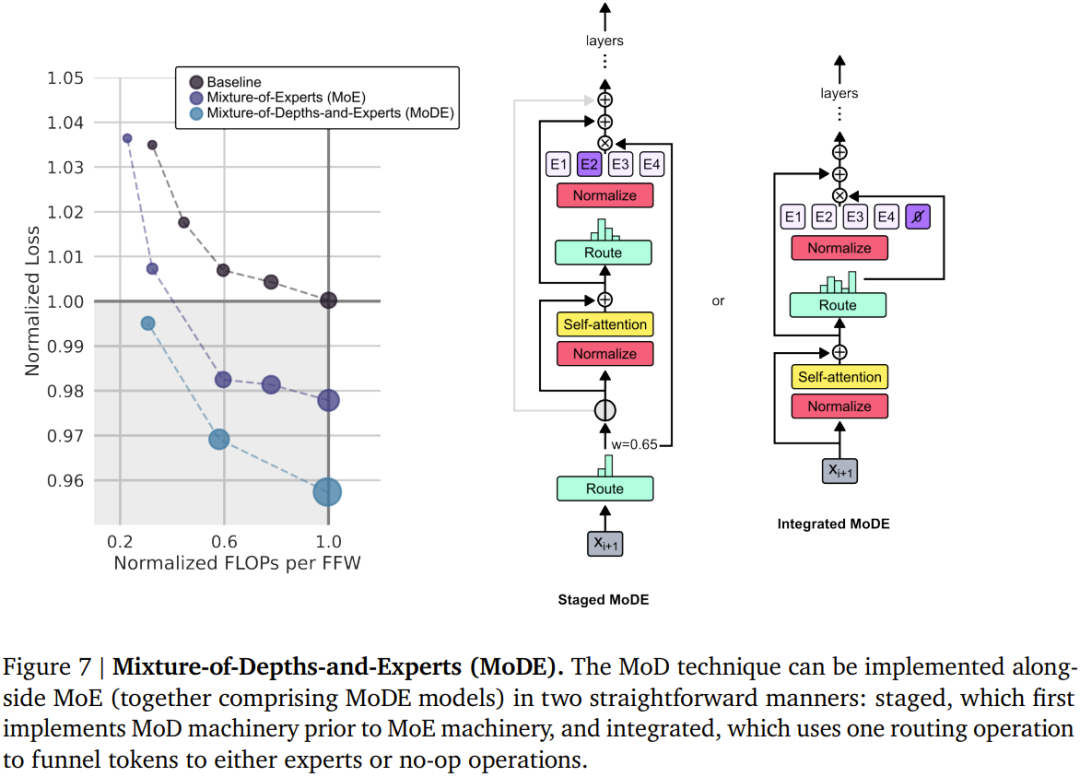
該團隊考慮了兩種學習到的路由方案(見圖2):token 選擇型與專家選擇型。 在 token 選擇型路由方案中,路由演算法會跨運算路徑(例如跨 MoE Transformer 中的專家身分)產生針對每個 token 的機率分佈。然後 token 會被傳送到它們偏好的路徑(即機率最高的路徑),而輔助損失可以確保所有 token 不會收斂到同一路徑。 token 選擇型路由可能會有負載平衡問題,因為無法確保 token 在可能的路徑之間劃分適當。 專家選擇型路由則是將上述方案反過來:不是讓token 選擇它們偏好的路徑,而是讓每條路徑基於token 偏好選擇前k 個token (top-k)。這能確保負載完美平衡,因為每條路徑總是保證 k 個 token。但是,這也可能導致某些 token 被處理或欠處理,因為某些 token 可能是多條路徑的前 k 名,而另一些 token 則可能沒有相應路徑。 DeepMind 的選擇是使用專家選擇型路由,原因有三。 第二,由於選取前k 名此操作取決於路由權重的幅度,因此此路由方案允許使用相對路由權重,這有助於確定目前模組計算最需要哪些token;路由演算法可以透過適當地設定權重來盡力確保最關鍵的token 是在前k 名之中—— 這是token 選擇型路由方案無法做到的。在具體的用例中,有一條計算路徑本質上是 null 操作,因此應該避免將重要 token 路由到 null。 第三,由於路由只會經由兩條路徑,因此單次top-k 操作就能有效率地將token 分成兩個互斥的集合(每條計算路徑一個集合),這能應對上述的過處理或欠處理問題。 #儘管專家選擇型路由有很多優點,但它也有一個很明顯的問題:top-k 運算是非因果式的。也就是說,一個給定 token 的路由權重是否在前 k 名取決於其之後的路由權重的值,但在執行自回歸採樣時,我們無法獲得這些權重。 第一種是引入一個簡單的輔助損失;實踐證明,其對語言建模主目標的影響程度為0.2%− 0.3%,但卻能夠讓模型自回歸地採樣。他們使用了一個二元交叉熵損失,其中路由演算法的輸出提供logit,透過選取這些logit 中的top-k,就能提供目標(即,如果一個token 在top-k 中,就為1,否則為0)。第二种方法是引入一个小的辅助 MLP 预测器(就像是又一个路由算法),其输入与路由算法的一样(具有 stop gradient),但其输出是一个预测结果:token 是否在序列的 top-k 中。该方法不会影响语言建模目标,实验表明也不会显著影响该步骤的速度。有了这些新方法,就可以通过选择路由到的 token 来执行自回归采样,也可以根据路由算法的输出绕过一个模块,这无需依赖任何未来 token 的信息。实验结果表明,这是一种相对简单辅助任务,可以很快实现 99% 的准确度。首先,该团队训练了一些 FLOP 预算相对较小(6e18)的模型,以确定最优的超参数(见下图 3)。总体而言,可以看到 MoD Transformer 会将基准 isoFLOP 曲线向右下方拖动。也就是说,最优的 MoD Transformer 的损失比最优的基准模型更低,同时参数也更多。这种效应带来了一个幸运的结果:存在一些和最优基准模型表现一样好甚至更好的 MoD 模型(同时步骤速度更快),尽管它们本身在其超参数设置下并不是 isoFLOP 最优的。举个例子,一个 220M 参数量的 MoD 变体(图 3 中的 3 号模型)稍优于 isoFLOP 最优基准模型(参数量也是 220M,图 3 中的 1 号模型),但这个 MoD 变体在训练期间的步骤速度快了 60% 以上。下图 4 给出了总 FLOPs 为 6e18、2e19 和 1e20 时的 isoFLOP 分析。可以看到,当 FLOP 预算更大时,趋势依然继续。下图 5 给出了一个使用交织的路由模块训练的 MoD Transformer 的路由决策。尽管其中存在大量绕过模块的情况,但这个 MoD Transformer 依然能实现优于常规 Transformer 的性能。他们也评估了 MoD 变体的自回归采样表现,结果见下图 6。这些结果表明 MoD Transformer 所带来的计算节省不仅仅局限于训练设置。MoD 技术可以自然地与 MoE 模型整合起来,组成所谓的 MoDE 模型。下图 7 展示了 MoDE 及其带来的提升。MoDE 有两种变体:分阶段 MoDE 和集成式 MoDE。其中分阶段 MoDE 是在自注意力步骤之前进行路由绕过或到达 token 的操作;而集成式 MoDE 则是通过在常规 MLP 专家之间集成「无操作」专家来实现 MoD 路由。前者的优势是允许 token 跳过自注意力步骤,而后者的好处在于其路由机制很简单。该团队注意到,以集成方式实现 MoDE 明显优于直接降低专家的能力、依靠丢弃 token 来实现残差路由的设计。以上是DeepMind升級Transformer,前向通過FLOPs最多可降一半的詳細內容。更多資訊請關注PHP中文網其他相關文章!