


培訓大語言模型:從TRPO到GRPO

DeepSeek:深入研究LLMS的加強學習 DeepSeek最近的成功,以較低的成本取得了令人印象深刻的表現,突出了大語言模型(LLM)培訓方法的重要性。本文重點介紹了增強學習(RL)方面,探索TRPO,PPO和更新的GRPO算法。 假設對機器學習,深度學習和LLM的基本熟悉,我們將最大程度地減少複雜數學以使其可訪問。
>> LLM培訓的三個支柱
LLM培訓通常涉及三個關鍵階段:
>
預訓練:- >該模型學會了使用大量數據集從先前的代幣中以序列進行序列預測下一個令牌。
- 監督的微調(SFT):
- 強化學習(RLHF):在本階段,本文的重點,進一步完善了通過直接反饋對更好的人類偏好的反應。 強化學習基礎
代理
與環境 的交互。代理存在於特定的
的交互。代理存在於特定的
中,採取>動作>過渡到新狀態。每個動作都會從環境中產生A獎勵,從而指導代理人的未來行動。 想想一個機器人在迷宮中瀏覽:其位置是國家,運動是行動,到達出口提供了積極的獎勵。 LLMS中的rl:詳細的外觀
在LLM培訓中,組件是:
-
代理:
llm本身。 >
>- >環境:外部因素,例如用戶提示,反饋系統和上下文信息。
- 動作:令牌llm對查詢的響應生成。
- state:當前查詢和生成的令牌(部分響應)。
獎勵:- >通常由對人類通知數據訓練的單獨獎勵模型確定,對分配得分的響應進行排名。更高質量的回應獲得了更高的獎勵。 在特定情況下,例如DeepSeekmath。
策略
確定要採取的行動。 對於LLM,這是對可能令牌的概率分佈,用於採樣接下來的令牌。 RL培訓可以調整策略的參數(型號權重),以偏愛更高的代幣。 該策略通常表示為:
RL的核心是找到最佳策略。 與監督的學習不同,我們使用獎勵來指導政策調整。
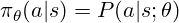 > trpo(信任區域策略優化)
> trpo(信任區域策略優化)
trpo使用優勢函數,類似於監督學習中的損失函數,但從獎勵中得出:

> ppo(近端策略優化) PPO,通過使用剪裁的替代目標來簡化TRPO,隱含地限制了策略更新並提高了計算效率。 PPO目標函數是: grpo(組相對策略優化) >這簡化了過程,非常適合LLMS生成多個響應的能力。 GRPO還包含了KL Divergence術語,將當前策略與參考策略進行了比較。最終的GRPO公式是: 增強學習,尤其是PPO和較新的GRPO,對於現代LLM培訓至關重要。 每種方法都基於RL基本面,提供不同的方法,以平衡穩定性,效率和人類對齊方式。 DeepSeek的成功利用了這些進步以及其他創新。 強化學習有望在促進LLM功能方面發揮越來越重要的作用。 >參考:(參考文獻保持不變,只是重新格式化以獲得更好的可讀性)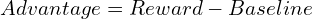
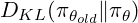

grpo的訓練。對於每個查詢,它都會生成一組響應,並根據其獎勵計算優勢作為z評分:
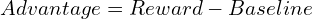

結論
以上是培訓大語言模型:從TRPO到GRPO的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 我嘗試了使用光標AI編碼的Vibe編碼,這太神奇了!
Mar 20, 2025 pm 03:34 PM
我嘗試了使用光標AI編碼的Vibe編碼,這太神奇了!
Mar 20, 2025 pm 03:34 PM
Vibe編碼通過讓我們使用自然語言而不是無盡的代碼行創建應用程序來重塑軟件開發的世界。受Andrej Karpathy等有遠見的人的啟發,這種創新的方法使Dev
 2025年2月的Genai推出前5名:GPT-4.5,Grok-3等!
Mar 22, 2025 am 10:58 AM
2025年2月的Genai推出前5名:GPT-4.5,Grok-3等!
Mar 22, 2025 am 10:58 AM
2025年2月,Generative AI又是一個改變遊戲規則的月份,為我們帶來了一些最令人期待的模型升級和開創性的新功能。從Xai的Grok 3和Anthropic的Claude 3.7十四行詩到Openai的G
 如何使用Yolo V12進行對象檢測?
Mar 22, 2025 am 11:07 AM
如何使用Yolo V12進行對象檢測?
Mar 22, 2025 am 11:07 AM
Yolo(您只看一次)一直是領先的實時對象檢測框架,每次迭代都在以前的版本上改善。最新版本Yolo V12引入了進步,可顯著提高準確性
 最佳AI藝術生成器(免費付款)創意項目
Apr 02, 2025 pm 06:10 PM
最佳AI藝術生成器(免費付款)創意項目
Apr 02, 2025 pm 06:10 PM
本文回顧了AI最高的藝術生成器,討論了他們的功能,對創意項目的適用性和價值。它重點介紹了Midjourney是專業人士的最佳價值,並建議使用Dall-E 2進行高質量的可定製藝術。
 Chatgpt 4 o可用嗎?
Mar 28, 2025 pm 05:29 PM
Chatgpt 4 o可用嗎?
Mar 28, 2025 pm 05:29 PM
Chatgpt 4當前可用並廣泛使用,與諸如ChatGpt 3.5(例如ChatGpt 3.5)相比,在理解上下文和產生連貫的響應方面取得了重大改進。未來的發展可能包括更多個性化的間
 哪個AI比Chatgpt更好?
Mar 18, 2025 pm 06:05 PM
哪個AI比Chatgpt更好?
Mar 18, 2025 pm 06:05 PM
本文討論了AI模型超過Chatgpt,例如Lamda,Llama和Grok,突出了它們在準確性,理解和行業影響方面的優勢。(159個字符)
 如何將Mistral OCR用於下一個抹布模型
Mar 21, 2025 am 11:11 AM
如何將Mistral OCR用於下一個抹布模型
Mar 21, 2025 am 11:11 AM
MISTRAL OCR:通過多模式文檔理解徹底改變檢索效果 檢索增強的生成(RAG)系統具有明顯高級的AI功能,從而可以訪問大量的數據存儲,以獲得更明智的響應
 頂級AI寫作助理來增強您的內容創建
Apr 02, 2025 pm 06:11 PM
頂級AI寫作助理來增強您的內容創建
Apr 02, 2025 pm 06:11 PM
文章討論了Grammarly,Jasper,Copy.ai,Writesonic和Rytr等AI最高的寫作助手,重點介紹了其獨特的內容創建功能。它認為Jasper在SEO優化方面表現出色,而AI工具有助於保持音調的組成
