

語言模型是對文字進行推理的,文字通常是字串形式,但模型的輸入只能是數字,因此需要將文字轉換成數字形式。
Tokenization是自然語言處理的基本任務,根據特定需求能夠把一段連續的文字序列(如句子、段落等)切分為一個字元序列(如單字、片語、字元、標點等多個單元),其中的單元稱為token或詞語。
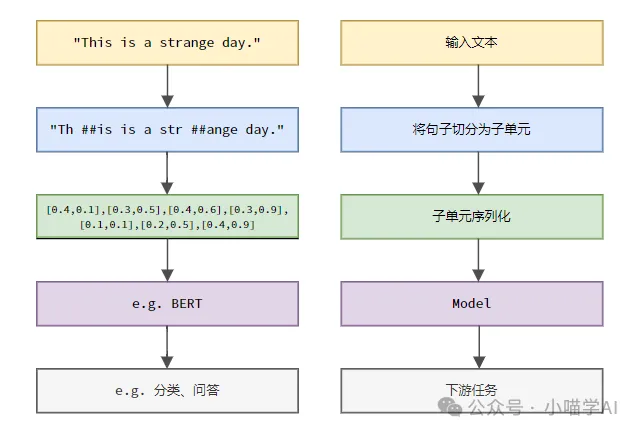
根據下圖所示的具體流程,先將文字句子切分成一個個單元,然後將單元素數值化(映射為向量),再將這些向量輸入到模型進行編碼,最後輸出到下游任務進一步得到最終的結果。
依照文字切分的粒度可以將Tokenization分為詞粒度Tokenization、字元粒度Tokenization、subword粒度Tokenization三類。
詞粒度Tokenization是最直觀的分詞方式,即是指將文本依照詞彙words進行切分。例如:
The quick brown fox jumps over the lazy dog.词粒度Tokenized结果:['The', 'quick', 'brown', 'fox', 'jumps', 'over', 'the', 'lazy', 'dog', '.']
在這個例子中,文字被切分為一個個獨立的單詞,每個單字作為一個token,標點符號'.'也被視為獨立的token 。
中文文本通常會根據照搬字典收錄的標準詞彙彙編或是透過分詞演算法辨識出的片語、成語、專有名詞等進行切分。
我喜欢吃苹果。词粒度Tokenized结果:['我', '喜欢', '吃', '苹果', '。']
這段中文文本被切分成五個詞語:“我”、“喜歡”、“吃”、“蘋果”和句號“。”,每個詞語作為一個token。
字元粒度Tokenization將文字分割成最小的字元單元,即每個字元被視為單獨的token。例如:
Hello, world!字符粒度Tokenized结果:['H', 'e', 'l', 'l', 'o', ',', ' ', 'w', 'o', 'r', 'l', 'd', '!']
字元粒度Tokenization在中文中是將文字依照每個獨立的漢字切分。
我喜欢吃苹果。字符粒度Tokenized结果:['我', '喜', '欢', '吃', '苹', '果', '。']
subword粒度Tokenization介於詞粒度和字元粒度之間,它將文字分割成介於單字和字元之間的子詞(subwords)作為token。常見的subword Tokenization方法包括Byte Pair Encoding (BPE)、WordPiece等。這些方法透過統計文字資料中的子字串頻率,自動產生一種分詞字典,能夠有效應對未登入詞(OOV)問題,同時保持一定的語意完整性。
helloworld
假設經過BPE演算法訓練後,產生的子詞字典包含以下項目:
h, e, l, o, w, r, d, hel, low, wor, orld
子字粒度Tokenized結果:
['hel', 'low', 'orld']
這裡,“helloworld”被切分為三個子詞“hel”,“low”,“orld”,這些都是字典中出現過的高頻子字串組合。這種切分方式既能處理未知詞彙(如「helloworld」並非標準英語單字),也保留了一定的語意訊息(子字組合起來能還原原始單字)。
在中文中,subword粒度Tokenization同樣是將文字分割成介於漢字和字詞之間的子字作為token。例如:
我喜欢吃苹果
假設經過BPE演算法訓練後,產生的子字詞詞典包含以下項目:
我, 喜, 欢, 吃, 苹, 果, 我喜欢, 吃苹果
子詞粒度Tokenized結果:
['我', '喜欢', '吃', '苹果']
在這個例子中,「我喜歡吃蘋果」被切分為四個子詞“我”、“喜歡”、“吃”和“蘋果”,這些子詞均在字典中出現。雖然沒有像英文子詞那樣將漢字進一步組合,但子詞Tokenization方法在生成詞典時已經考慮了高頻詞彙組合,例如“我喜歡”和“吃蘋果”。這種切分方式在處理未知詞彙的同時,也維持了字詞層次的語意訊息。
假設已有建立好的語料庫或詞彙表如下。
vocabulary = {'我': 0,'喜欢': 1,'吃': 2,'苹果': 3,'。': 4}
則可以找出序列中每個token在詞彙表中的索引。
indexed_tokens = [vocabulary[token] for token in token_sequence]print(indexed_tokens)
輸出:[0, 1, 2, 3, 4]。
以上是一文搞懂Tokenization!的詳細內容。更多資訊請關注PHP中文網其他相關文章!


































