

在自然語言處理中,有許多資訊其實是重複的。
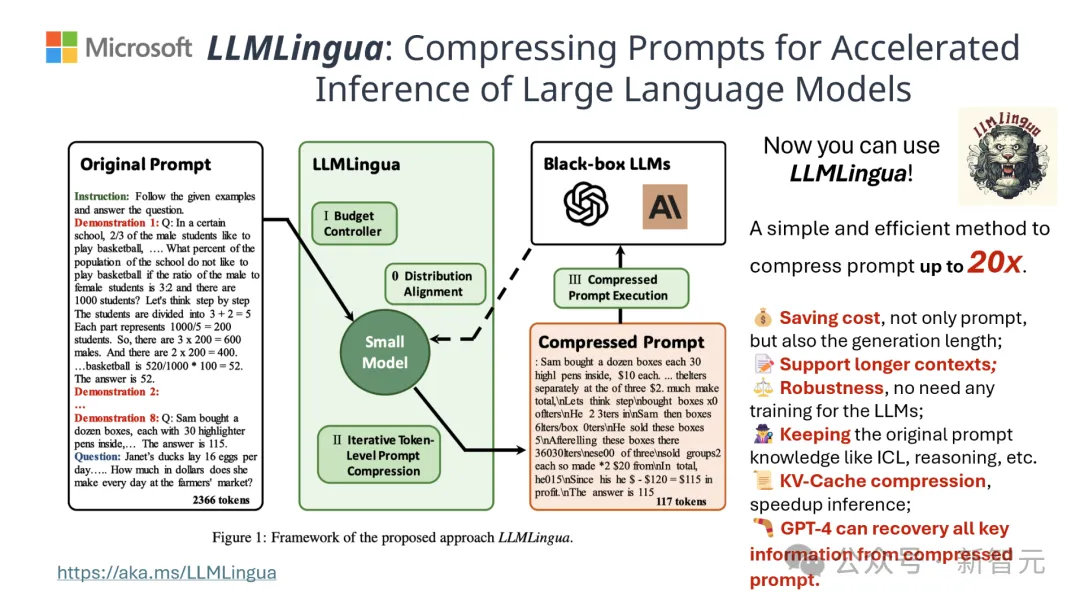
如果能將提示詞有效壓縮,某種程度上也相當於擴大了模型支援上下文的長度。
現有的資訊熵方法是透過刪除某些單字或短語來減少這種冗餘。
然而,基於資訊熵的計算僅涵蓋了文本的單向上下文,可能會忽略壓縮所需的關鍵資訊;而且,資訊熵的計算方式並非完全符合壓縮提示詞的實際目的。
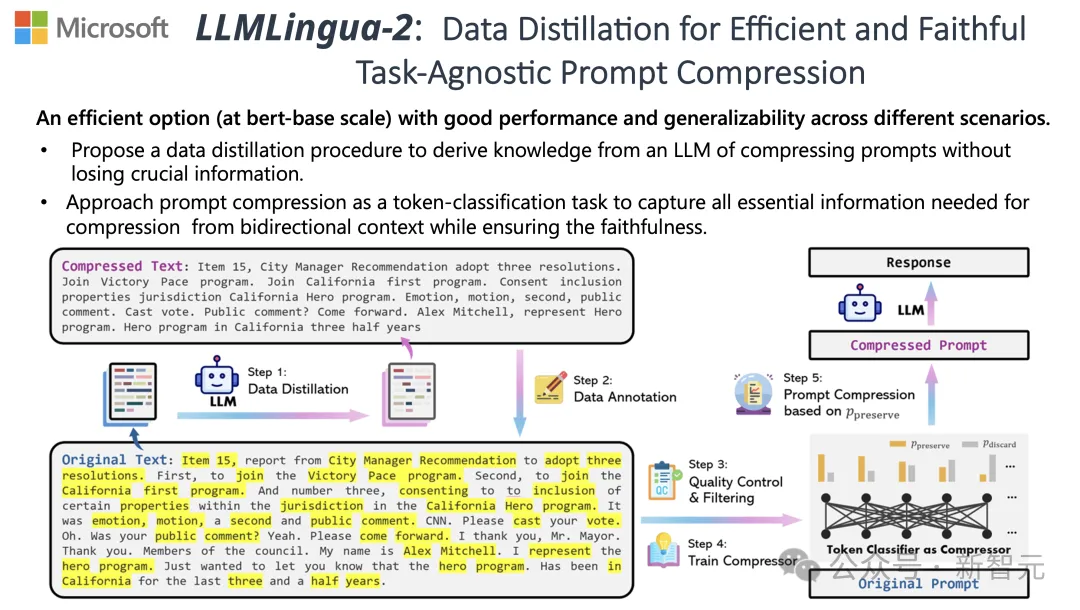
為了迎接這些挑戰,清華大學和微軟的研究人員共同提出了一項全新的資料處理流程,名為LLMLingua-2。其旨在從大型語言模型(LLM)中提取知識,透過壓縮提示詞實現資訊的精煉,同時確保關鍵資訊不會遺失。
專案在GitHub上已經斬獲3.1k星
結果顯示,LLMLingua-2可以將文字長度大幅縮減至最初的20%,有效減少了處理時間和成本。
此外,與先前版本LLMLingua以及其他類似技術相比,LLMLingua 2的處理速度提高了3到6倍。

論文網址:https://arxiv.org/abs/2403.12968
在這個過程中,原始文字首先被輸入模型。
模型會評估每個字的重要性,決定要保留還是刪除,同時也會考慮到字詞之間的關係。
最終,模型會選擇那些評分最高的詞彙組成一個更簡短的提示詞。
團隊在包括MeetingBank、LongBench、ZeroScrolls、GSM8K和BBH在內的多個資料集上測試了LLMLingua-2模型。
儘管這個模型體積不大,但它在基準測試中取得了顯著的性能提升,並且證明了其在不同的大語言模型(從GPT-3.5到Mistral- 7B)和語種(從英語到中文)上具有出色的泛化能力。
系統提示:
#身為傑出的語言學家,你擅長將較長的文段壓縮成簡短的表達方式,方法是去除那些不重要的詞彙,同時盡可能保留訊息。
使用者提示:
#請將給定的文字壓縮成簡短的表達形式,使得你(GPT-4)能盡可能準確地還原原文。有別於常規的文本壓縮,我需要你遵循以下五個條件:
1. 只移除那些不重要的詞彙。
2. 保持原始詞彙的順序不變。
3. 保持原始詞彙不變。
4. 不使用任何縮寫或表情符號。
5. 不加入任何新的詞彙或符號。
請盡可能地壓縮原文,同時保留盡可能多的資訊。如果你明白了,請對以下文字進行壓縮:{待壓縮文字}
壓縮後的文字是:[...]
結果顯示,在問答、摘要撰寫和邏輯推理等多種語言任務中,LLMLingua-2都顯著優於原有的LLMLingua模型和其他選擇性上下文策略。
值得一提的是,這種壓縮方法對於不同的大語言模型(從GPT-3.5到Mistral-7B)和不同的語言(從英語到中文)同樣有效。
而且,只要兩行程式碼,就可以實現LLMLingua-2的部署。
目前,該模型已經被整合到了廣泛使用的RAG框架LangChain和LlamaIndex當中。
為了克服現有基於資訊熵的文字壓縮方法所面臨的問題,LLMLingua-2採取了一種創新的數據提煉策略。
這項策略透過從GPT-4這樣的大語言模型中抽取精華訊息,實現了在不損失關鍵內容和避免添加錯誤訊息的前提下,對文字進行高效壓縮。
提示設計
#要充分利用GPT-4的文字壓縮潛力,關鍵在於如何設定精確的壓縮指令。
也就是在壓縮文本時,指導GPT-4只移除那些在原始文本中不那麼重要的詞彙,同時避免在過程中引入任何新的詞彙。
這樣做的目的是為了確保壓縮後的文字盡可能地保持原文的真實性和完整性。

標註與篩選
#研究人員利用了從GPT-4等大語言模型中提煉出的知識,發展了一種新穎的資料標註演算法。
這個演算法能夠對原文中的每一個詞彙進行標註,明確指出在壓縮過程中哪些詞彙是必須保留的。
為了保證所建立資料集的高質量,他們也設計了兩種品質監控機制,專門用來識別並排除那些品質不佳的資料樣本。

#壓縮器
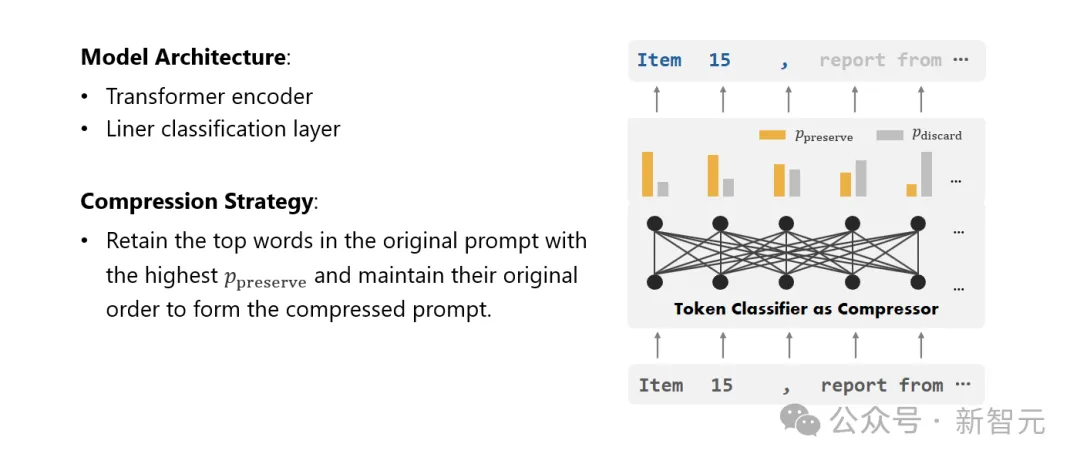
#最後,研究人員將文字壓縮的問題轉換為了一個對每個詞彙(Token)進行分類的任務,並採用了強大的Transformer作為特徵提取器。
這個工具能夠理解文本的前後關係,從而精確地抓取對於文字壓縮至關重要的資訊。
透過在精心建構的資料集上進行訓練,研究人員的模型能夠根據每個詞彙的重要性,計算出一個機率值來決定這個詞彙是應該被保留在在最終的壓縮文本中,還是應該被捨棄。
#研究人員在一系列任務上測試了LLMLingua-2的效能,這些任務包括上下文學習、文字摘要、對話生成、多文件和單文檔問答、代碼生成以及合成任務,既包括了域內的資料集也包括了域外的資料集。
測試結果顯示,研究人員的方法在保持高效能的同時,減少了最小的效能損失,並且在任務不特定的文字壓縮方法中表現突出。
- 域內測試(MeetingBank)
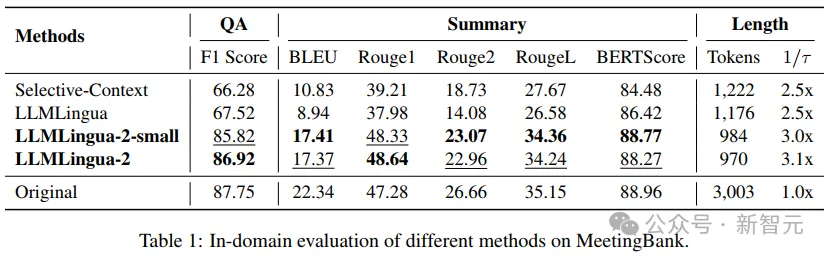
#研究者將LLMLingua-2在MeetingBank測試集上的表現與其他強大的基線方法進行了比較。
儘管他們的模型規模遠小於基線中使用的LLaMa-2-7B,但在問答和文本摘要任務上,研究人員的方法不僅大幅提升了性能,而且與原始文字提示的表現相差無幾。
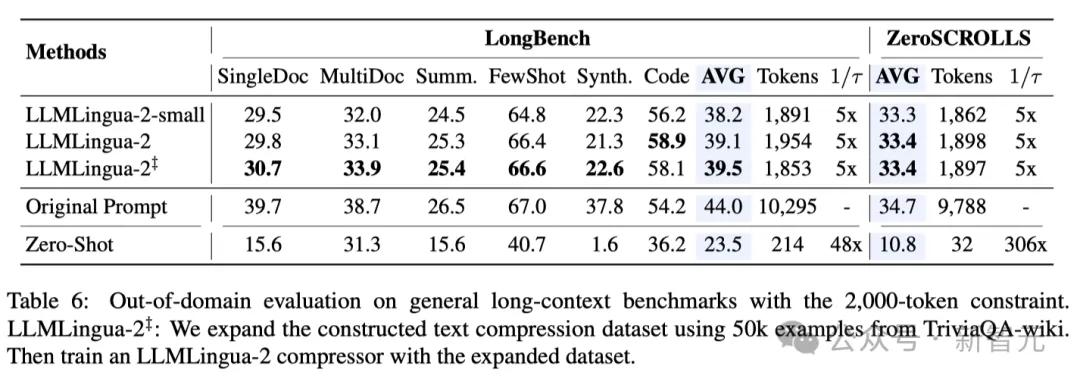
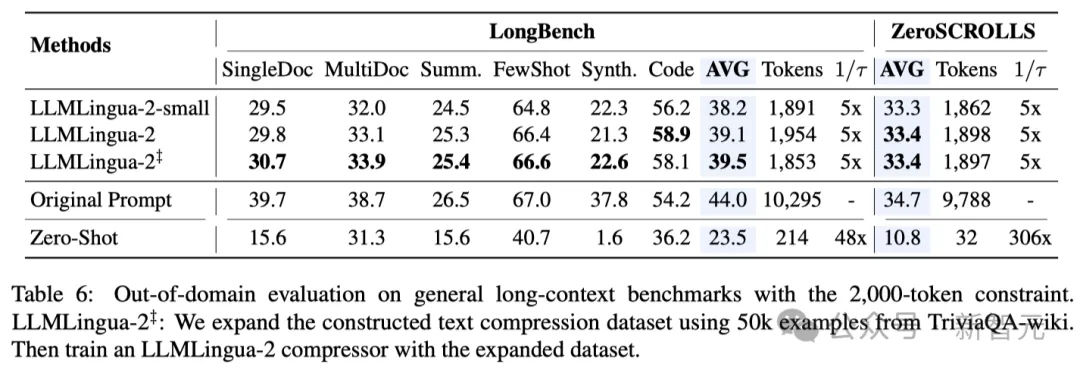
- 域外測試(LongBench、GSM8K和BBH)
考慮到研究人員的模型僅在MeetingBank的會議記錄資料上進行了訓練,研究人員進一步探索了其在長文本、邏輯推理和上下文學習等不同場景下的泛化能力。
值得一提的是,儘管LLMLingua-2只在一個資料集上訓練,但在域外的測試中,它的表現不僅與當前最先進的任務不特定壓縮方法相媲美,甚至在某些情況下還有過之而無不及。
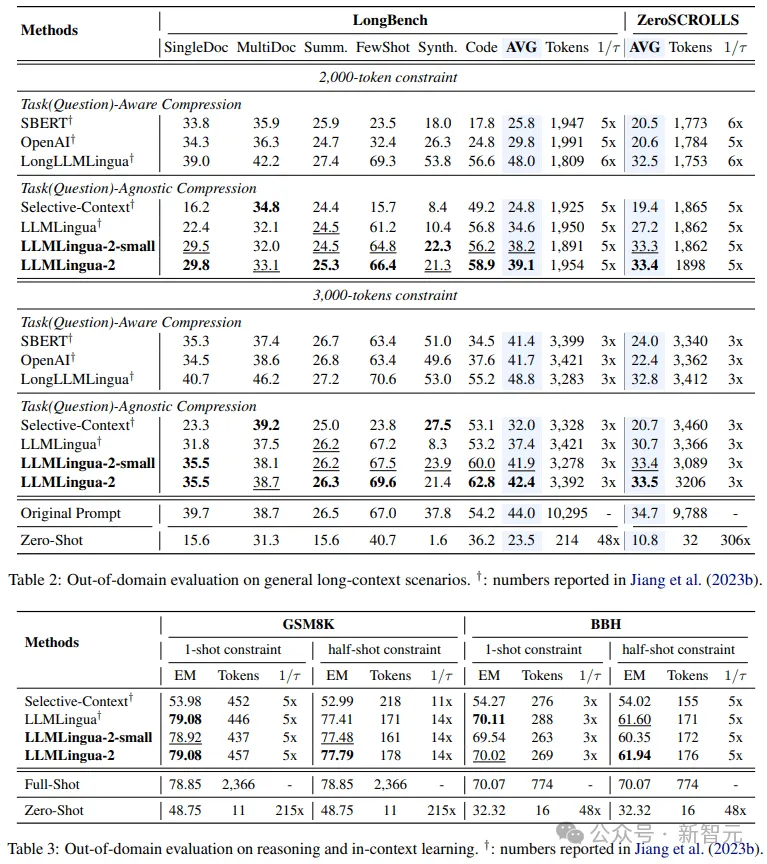
即使是研究人員的較小模型(BERT-base大小),也能達到與原始提示相當的性能,在某些情況下甚至略高於原始提示。
雖然研究人員的方法取得了可喜的成果,但與其他任務感知壓縮方法(如Longbench上的LongLLMlingua)相比,研究人員的方法仍有不足。
研究人員將這種表現差距歸因於它們從問題中獲得的額外資訊。不過,研究人員的模型具有與任務無關的特點,因此在不同場景中部署時,它是一種具有良好通用性的高效選擇。
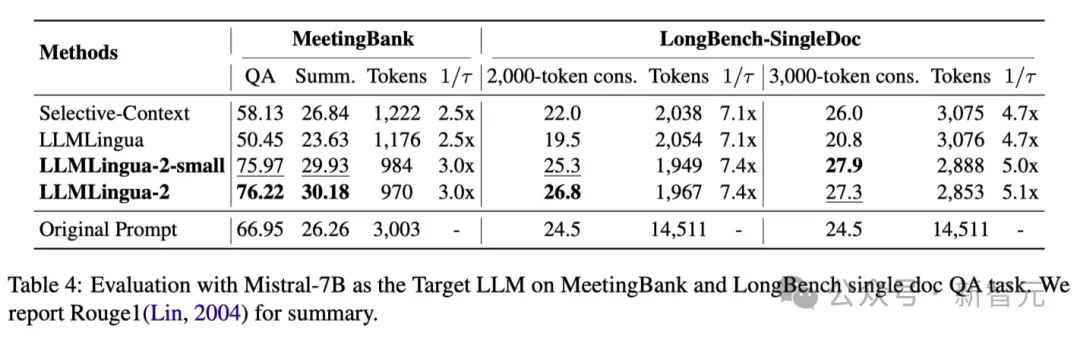
上表4列出了使用Mistral-7Bv0.1 4作為目標LLM的不同方法的結果。
與其他基準方法相比,研究人員的方法在表現上有明顯的提升,展示了其在目標LLM上良好的泛化能力。
值得注意的是,LLMLingua-2的效能甚至優於原始提示。
研究者推測,Mistral-7B在管理長上下文的能力可能不如GPT-3.5-Turbo。
研究人員的方法透過提供資訊密度更高的短提示,有效提高了 Mistral7B 的最終推理效能。
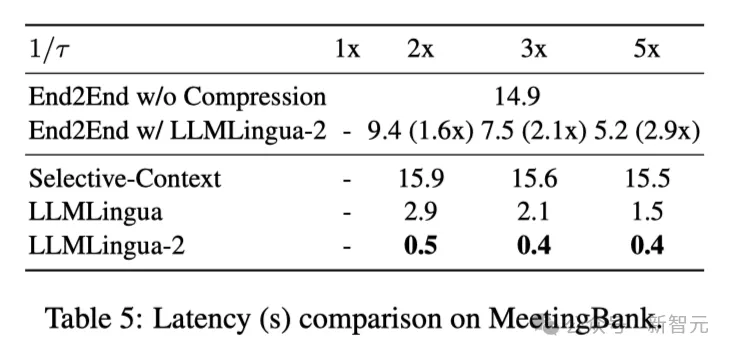
上表5顯示了不同系統在不同壓縮比的V100-32G GPU上的延遲。
結果表明,與其他壓縮方法相比,LLMLingua2的計算開銷要小得多,可以實現1.6倍到2.9倍的端到端速度提升。
此外,研究人員的方法還能將GPU記憶體成本降低8倍,進而降低硬體資源的需求。
上下文意識觀察 研究人員觀察到,隨著壓縮率的增加,LLMLingua-2可以有效地保持與完整上下文相關的資訊量最大的單字。
這要歸功於雙向上下文感知特徵提取器的採用,以及明確朝著及時壓縮目標進行優化的策略。
研究人員觀察到,隨著壓縮率的增加,LLMLingua-2可以有效地保持與完整上下文相關的資訊量最大的單字。
這要歸功於雙向上下文感知特徵提取器的採用,以及明確朝著及時壓縮目標進行優化的策略。
最後研究者讓GPT-4 從 LLMLingua-2壓縮提示中重構原始提示音。
結果表明,GPT-4可以有效地重建原始提示,這表明在LLMLingua-2壓縮過程中並沒有遺失基本資訊。
以上是清華微軟開源全新提示字壓縮工具,長度驟降80%! GitHub怒砍3.1K顆星的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















