


標題:DECO: Query-Based End-to-End Object Detection with ConvNets
論文:https://arxiv.org/pdf/2312.13735 .pdf
原始碼:https://github.com/xinghaochen/DECO
原文:https://zhuanlan.zhihu.com/p/686011746@王雲鶴
引入Detection Transformer(DETR)後,目標偵測領域掀起了一股熱潮,許多後續研究都在精度和速度方面對原始DETR進行了改進。然而,關於Transformer是否能夠完全主導視覺領域的討論仍在持續。一些研究如ConvNeXt和RepLKNet表明,CNN結構在視覺領域仍具有巨大的潛力。
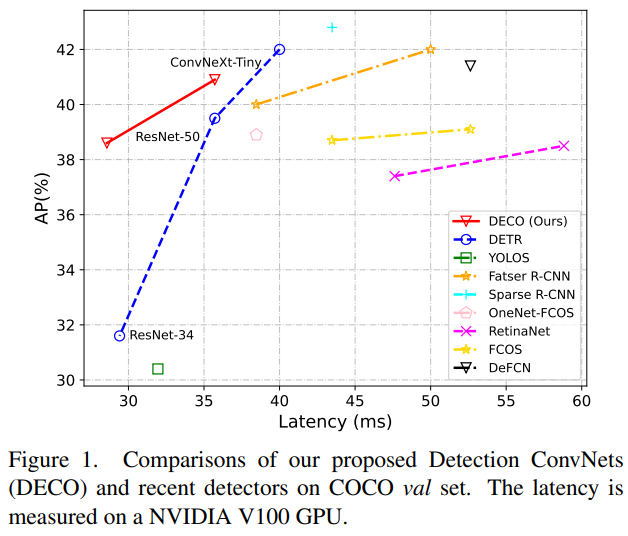
我們這個工作探究的就是如何利用純卷積的架構,來得到一個效能能打的類別 DETR 框架的偵測器。致敬 DETR,我們稱我們的方法為DECO (Detection ConvNets)。採用 DETR 類似的結構設定,搭配不同的 Backbone,DECO 在 COCO 上取得了38.6%和40.8%的AP,在V100上取得了35 FPS和28 FPS的速度,取得比DETR更好的性能。搭配類似RT-DETR的多尺度特徵等模組,DECO取得了47.8% AP和34 FPS的速度,整體表現跟很多DETR改進方法比都有不錯的優勢。
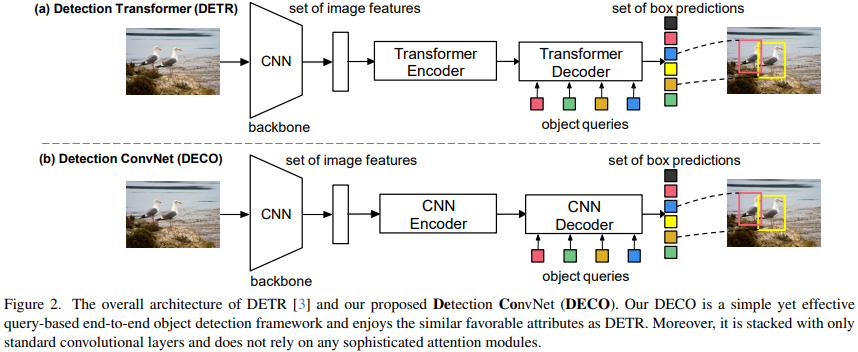
DETR的主要特點是利用Transformer Encoder-Decoder的結構,對一個輸入影像,利用一組Query跟著影像特徵交互,可以直接輸出指定數量的偵測框,從而可以擺脫對NMS等後處理操作的依賴。我們提出的DECO總體架構上跟DETR類似,也包括了Backbone來進行圖像特徵提取,一個Encoder-Decoder的結構跟Query進行交互,最後輸出特定數量的檢測結果。唯一的不同在於,DECO的Encoder和Decoder是純卷積的結構,因此DECO是一個由純卷積構成的Query-Based端對端檢測器。
DETR 的 Encoder 結構替換相對比較直接,我們選擇使用4個ConvNeXt Block來構成Encoder結構。具體來說,Encoder的每一層都是透過疊加7x7的深度卷積、一個LayerNorm層、一個1x1的捲積、一個GELU活化函數以及另一個1x1卷積來實現的。此外,在DETR中,因為Transformer架構對輸入具有排列不變性,所以每層編碼器的輸入都需要添加位置編碼,但是對於卷積組成的Encoder來說,則無需添加任何位置編碼
比較而言,Decoder的替換則複雜得多。 Decoder的主要作用為對影像特徵和Query進行充分的交互,使得Query可以充分感知到影像特徵訊息,從而對影像中的目標進行座標和類別的預測。 Decoder主要包括兩個輸入:Encoder的特徵輸出和一組可學的查詢向量(Query)。我們把Decoder的主要結構分成兩個模組:自互動模組(Self-Interaction Module, SIM)和交叉互動模組(Cross-Interaction Module, CIM)。
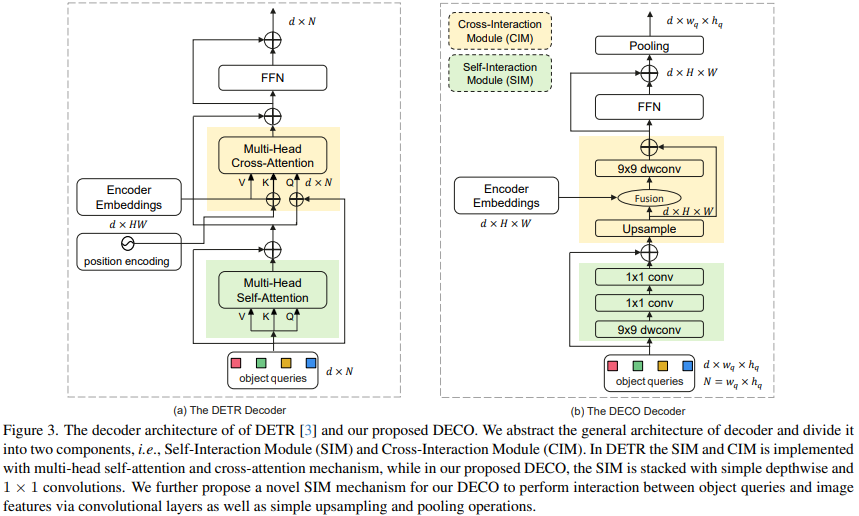
這裡,SIM模組主要融合Query和上層Decoder層的輸出,這部分的結構,可以利用若干個卷積層來組成,使用9x9 depthwise卷積和1x1卷積分別在空間維度和通道維度進行資訊交互,充分獲取所需的目標資訊以送到後面的CIM模組進行進一步的目標檢測特徵提取。 Query為一組隨機初始化的向量,該數量決定了檢測器最終輸出的檢測框數量,其具體的值可以隨實際需要進行調節。對DECO來說,因為所有的結構都是由卷積構成的,因此我們把Query變成二維,例如100個Query,則可以變成10x10的維度。
CIM模組的主要作用是讓影像特徵和Query進行充分的交互,使得Query可以充分感知到影像特徵訊息,從而對影像中的目標進行座標和類別的預測。對於Transformer結構來說,利用cross attention機制可以很方便地實現這一目的,但對於卷積結構來說,如何讓兩個特徵進行充分交互,則是一個最大的困難。
要把大小不同的SIM輸出和encoder輸出全域特徵融合,必須先把兩者進行空間對齊然後進行融合,首先我們對SIM的輸出進行最近鄰上採樣:

使得上採樣後的特徵與Encoder輸出的全局特徵有相同的尺寸,然後將上採樣後的特徵和encoder輸出的全局特徵進行融合,然後進入深度卷積進行特徵交互後加上殘差輸入:
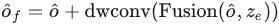
最後將交互後的特徵透過FNN進行通道資訊交互,之後pooling到目標數大小得到decoder的輸出embedding:
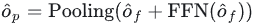
最後我們將得到的輸出embedding送入偵測頭,以進行後續的分類和迴歸。
跟原始的DETR一樣,上述框架得到的DECO有個共同的短板,即缺少多尺度特徵,而這對於高精度目標檢測來說是影響很大的。 Deformable DETR透過使用一個多尺度的可變形注意力模組來整合不同尺度的特徵,但這個方法是跟Attention算子強耦合的,因此沒法直接用在我們的DECO上。為了讓DECO也能處理多尺度特徵,我們在Decoder輸出的特徵之後,採用了RT-DETR提出的一個跨尺度特徵融合模組。實際上,DETR誕生之後衍生了一系列的改進方法,我們相信很多策略對DECO來說同樣是適用的,這也希望有興趣的人共同來探討。
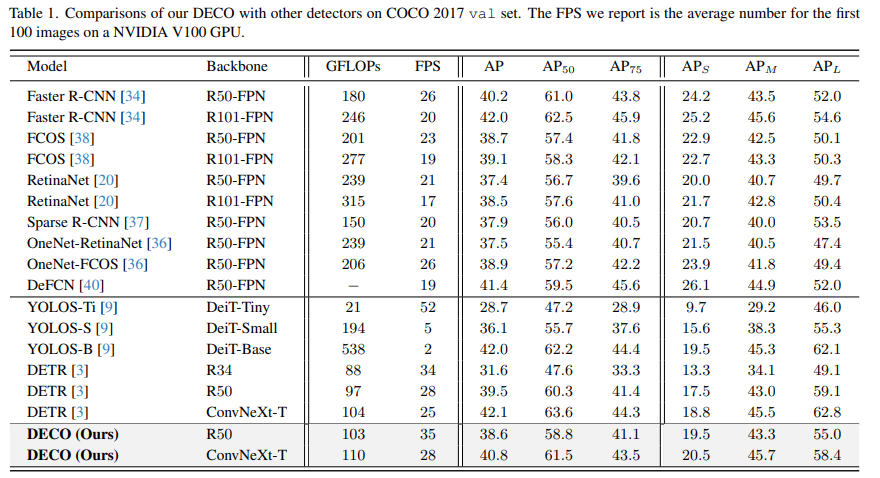
我們在COCO上進行了實驗,在保持主要架構不變的情況下將DECO和DETR進行了比較,例如保持Query數量一致,保持Decoder層數不變等等,僅將DETR中的Transformer結構依上文所述換成我們的捲積結構。可以看出,DECO取得了比DETR更好的精度和速度的Tradeoff。
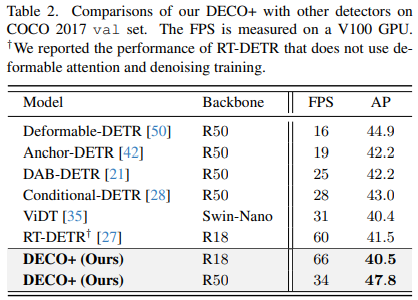
我們也把搭配了多尺度特徵後的DECO跟更多目標檢測方法進行了對比,其中包括了很多DETR的變體,從下圖中可以看到,DECO取得了很不錯的效果,比許多以前的偵測器都取得了更好的效能。
文章中DECO的結構進行了許多的消融實驗及視覺化,包括在Decoder中選用的具體融合策略(相加、點乘、Concat),以及Query的維度怎麼設定才有最優的效果等,也有一些比較有趣的發現,更詳細的結果和討論請參考原文。
本文旨在研究是否能夠建構一個基於查詢的端到端目標偵測框架,而不採用複雜的Transformer架構。提出了一種名為Detection ConvNet(DECO)的新型檢測框架,包括主幹網路和卷積編碼器-解碼器結構。透過精心設計DECO編碼器和引入一種新穎的機制,使DECO解碼器能夠透過卷積層實現目標查詢和影像特徵之間的交互作用。在COCO基準上與先前檢測器進行了比較,儘管簡單,DECO在檢測準確度和運行速度方面取得了競爭性表現。具體來說,使用ResNet-50和ConvNeXt-Tiny主幹,DECO在COCO驗證集上分別以35和28 FPS獲得了38.6%和40.8%的AP,優於DET模型。希望DECO提供了設計目標偵測框架的新視角。
以上是DECO: 純卷積Query-Based檢測器超越DETR!的詳細內容。更多資訊請關注PHP中文網其他相關文章!




















