

大型語言模型(LLMs)的進步在很大程度上推動了程式碼生成領域的發展。在先前的研究中,強化學習(RL)與編譯器的回饋訊號結合在一起,用於探索LLMs的輸出空間,以優化程式碼產生的品質。
但當下還存在兩個問題:
#1. 強化學習探索很難直接適應「複雜的人類需求」,即要求LLMs產生「長序列碼」;
2. 由於單元測試可能無法覆寫複雜的程式碼,因此使用未執行的程式碼片段來最佳化LLMs是無效的。
為了回應這些挑戰,研究人員提出了一種名為StepCoder的新型強化學習框架,該框架由復旦大學、華中科技大學和皇家理工學院的專家共同開發。 StepCoder包含兩個關鍵組件,旨在改善程式碼產生的效率和品質。
1. CCCS透過將長序列程式碼產生任務分解為程式碼完成子任務課程來解決探索挑戰;
2. FGO透過封鎖未執行的程式碼片段來最佳化模型,以提供細粒度最佳化。

論文連結:https://arxiv.org/pdf/2402.01391.pdf
項目連結:https://github.com/Ablustrund/APPS_Plus
#研究人員也建立了用於強化學習訓練的APPS 資料集,手動驗證以確保單元測試的正確性。
實驗結果表明,該方法提高了探索輸出空間的能力,並在相應的基準測試中優於最先進的方法。
在程式碼產生過程中,普通的強化學習探索(exploration)很難處理「獎勵稀疏且延遲的環境」和涉及「長序列的複雜需求」。
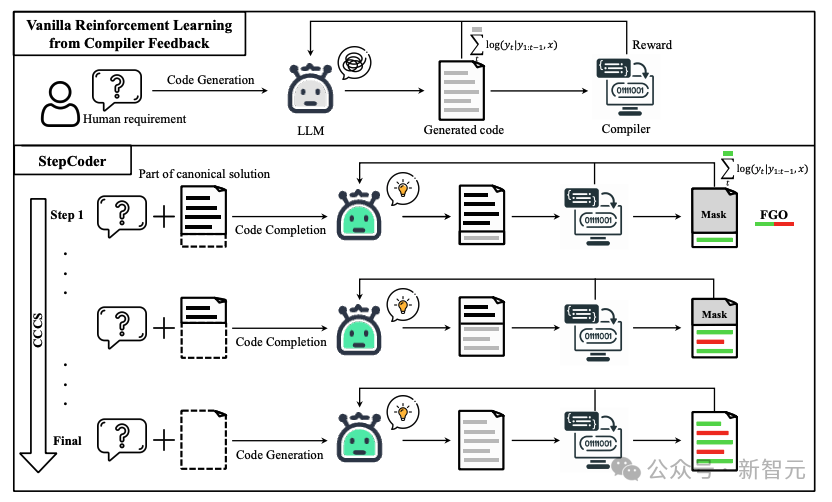
在CCCS(Curriculum of Code Completion Subtasks)階段,研究人員將複雜的探索問題分解為一系列子任務。利用標準解(canonical solution)的一部分作為提示(prompt),LLM可以從簡單序列開始探索。
獎勵的計算只與可執行的程式碼片段相關,因此用整個程式碼(圖中紅色部分)來最佳化LLM是不精確的(圖中灰色部分)。
在FGO(Fine-Grained Optimization)階段,研究人員對單元測試中未執行的tokens(紅色部分)進行遮罩,只使用已執行的tokens(綠色部分)計算損失函數,從而可以提供細粒度的最佳化。
預備知識
假定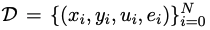 是用於程式碼產生的訓練資料集,其中x、y、u分別表示人類需求(即任務描述)、標準解和單元測試樣本。
是用於程式碼產生的訓練資料集,其中x、y、u分別表示人類需求(即任務描述)、標準解和單元測試樣本。
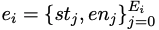 是透過自動分析標準解yi的抽象語法樹所得出的條件語句列表,其中st和en分別表示語句的起始位置和結束位置。
是透過自動分析標準解yi的抽象語法樹所得出的條件語句列表,其中st和en分別表示語句的起始位置和結束位置。
對於人類需求x,其標準解y可表示為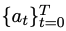 ;在程式碼產生階段,給定人類需求x,最終狀態是透過單元測試u的程式碼集合。
;在程式碼產生階段,給定人類需求x,最終狀態是透過單元測試u的程式碼集合。
方法細節
#StepCoder整合了兩個關鍵元件:CCCS和FGO,其中CCCS的目的是將程式碼產生任務分解為程式碼完成子任務的課程,可以減輕RL中的探索挑戰;FGO專為程式碼產生任務而設計,透過只計算已執行程式碼片段的損失來提供細粒度優化。
CCCS
#在程式碼產生過程中,要解決複雜的人類需求,通常需要策略模型採取較長的動作序列。同時,編譯器的回饋是延遲且稀疏的,也就是說,策略模型只有在產生整個程式碼後才會收到獎勵。在這種情況下,探索非常困難。
該方法的核心是將這樣一長串探索問題分解為一系列簡短、易於探索的子任務,研究人員將程式碼產生簡化為程式碼補全子任務,其中子任務由訓練資料集中的典型解決方案自動建構。
對於人類需求x,在CCCS的早期訓練階段,探索的起點s*是最終狀態附近的狀態。
具體來說,研究人員提供人類需求x和標準解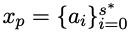 #的前半部分,並訓練策略模型來根據x'=(x, xp)完成程式碼。
#的前半部分,並訓練策略模型來根據x'=(x, xp)完成程式碼。
假定y^是xp和輸出軌跡τ的組合序列,即yˆ=(xp,τ),獎勵模型根據以y^為輸入的程式碼片段τ的正確性提供獎勵r。

研究人員使用近端策略優化(PPO)演算法,透過利用獎勵r和軌跡τ來優化策略模型πθ 。
在最佳化階段,用於提供提示的規範解代碼段xp將被屏蔽,這樣它就不會對策略模型πθ更新的梯度產生影響。
CCCS透過最大化反對函數來最佳化策略模型πθ,其中π^ref是PPO中的參考模型,由SFT模型初始化。
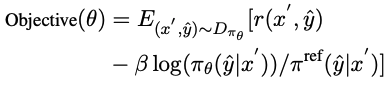
隨著訓練的進行,探索的起點s*會逐漸向標準解的起點移動,具體來說,為每個訓練樣本設定一個閾值ρ,每當πθ產生的程式碼段的累計正確率大於ρ時,就將starting point往beginning移動。
在訓練的後期階段,此方法的探索過程等同於原始強化學習的探索過程,即s*=0,策略模型僅以人類需求為輸入產生程式碼。
在條件語句的起始位置對初識點s*進行取樣,以完成剩餘的未寫程式碼段。
具體來說,條件語句越多,程式的獨立路徑就越多,邏輯複雜度就越高,複雜性要求更頻繁地採樣以提高訓練質量,而條件語句較少的程式則不需要那麼頻繁地取樣。
這種取樣方法可以均衡地抽取具有代表性的程式碼結構,同時兼顧訓練資料集中複雜和簡單的語意結構。
為了加速訓練階段,研究者將第i個樣本的課程數量設定為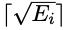 ,Ei是其條件語句的數量。第i個樣本的訓練課程跨度為
,Ei是其條件語句的數量。第i個樣本的訓練課程跨度為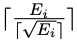 ,而不是1。
,而不是1。
CCCS的主要觀點可歸納如下:
1. 從接近目標的狀態(即最終狀態)開始探索很容易;
2. 從距離目標較遠的狀態開始探索具有挑戰性,但如果能利用已經學會如何達到目標的狀態,探索就會變得容易。
FGO
#程式碼產生中獎勵與行動之間的關係不同於其他強化學習任務(如Atari ),在程式碼生成中,可以排除一組與計算生成程式碼中的獎勵無關的動作。
具體來說,對於單元測試,編譯器的回饋只與執行的程式碼片段,然而,在普通RL最佳化目標中,軌跡上的所有動作都會參與到梯度計算中,而梯度計算是不精確的。
為了提高最佳化精確度,研究人員屏蔽了單元測試中未執行的行動(即tokens),策略模型的損失。

#APPS 資料集
強化學習需要大量高品質的訓練數據,在研究過程中,研究人員發現在目前可用的開源資料集中,只有APPS符合這項要求。
但APPS中存在一些不正確的實例,例如缺少輸入、輸出或標準解,其中標準解可能無法編譯或無法執行,或執行輸出存在差異。
為了完善APPS資料集,研究人員過濾掉了缺少輸入、輸出或標準解的實例,然後對輸入和輸出的格式進行了標準化,以方便單元測試的執行和比較;然後對每個實例進行了單元測試和人工分析,剔除了程式碼不完整或不相關、語法錯誤、API誤用或缺少庫依賴關係的實例。
對於輸出中的差異,研究人員會手動審核問題描述,修正預期輸出或消除實例。
最後建構了得到APPS 資料集,包含了7456個實例,每個實例包括程式設計問題描述、標準解決方案、函數名稱、單元測試(即輸入和輸出)和啟動程式碼(即標準解決方案的開頭部分)。

#為了評估其他LLM和StepCoder在程式碼產生方面的效能,研究人員在APPS 資料集上進行了實驗。
結果表明,基於RL的模型優於其他語言模型,包括基礎模型和SFT模型。
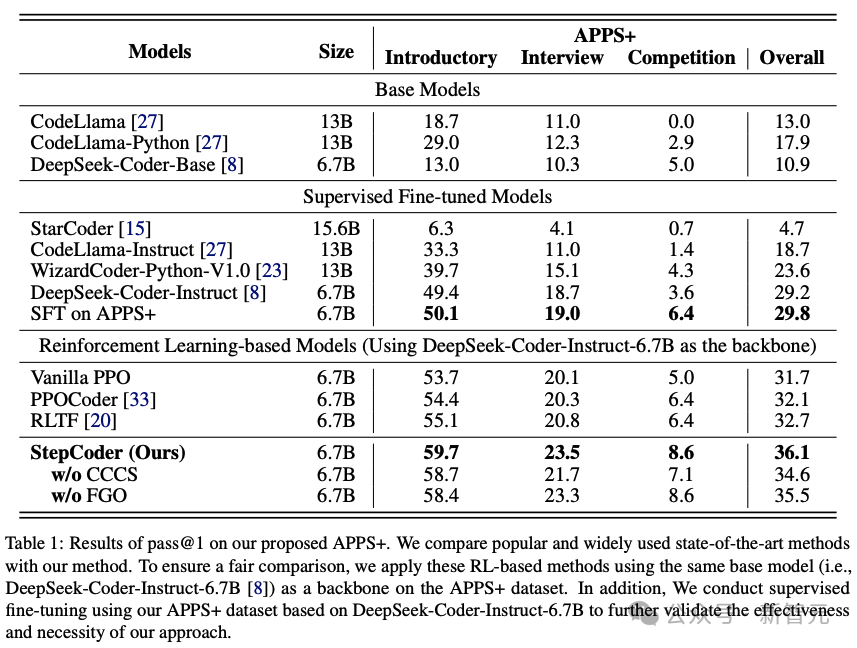
研究人員有理由推斷,強化學習可以在編譯器回饋的指導下,更有效地瀏覽模型的輸出空間,從而進一步提高程式碼生成的品質。
此外,StepCoder超越了所有基準模型,包括其他基於RL的方法,獲得了最高分。
具體來說,方法在「入門」(Introductory)、「訪談」(Interview)和「競賽」(Competition)層級的測試題目中分別獲得了59.7%、 23.5%和8.6%的高分。
與其他基於強化學習的方法相比,該方法透過將複雜的程式碼生成任務簡化為程式碼完成子任務,在探索輸出空間方面表現出色,並且FGO過程在精確優化策略模型方面發揮了關鍵作用。
也可以發現,在基於相同架構網路的APPS 資料集上,StepCoder的效能優於對微調進行有監督的LLM;與骨幹網路相比,後者幾乎沒有提高生成程式碼的通過率,這也直接表明,使用編譯器回饋優化模型的方法比程式碼生成中的下一個token預測更能提高生成程式碼的品質。
以上是刷榜「程式碼生成」任務!復旦等發布StepCoder框架:從編譯器回饋訊號強化學習的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















