在當前智慧對話模型的發展中,強大的底層模型起著至關重要的作用。這些先進模型的預訓練往往依賴高品質且多樣化的語料庫,而如何建立這樣的語料庫,已成為業界的一大挑戰。 在備受矚目的 AI for Math 領域,由於高品質的數學語料相對稀缺,這限制了生成式人工智慧在數學應用方面的潛力。 為了回應這項挑戰,上海交通大學生成式人工智慧實驗室推出了「MathPile」。這是一套專門針對數學領域的高品質、多樣化預訓練語料庫,其中包含約 95 億 tokens,旨在提升大型模型在數學推理方面的能力。 此外,實驗室也推出了 MathPile 的商業版 ——「MathPile_Commercial”,進一步拓寬其應用範圍和商業潛力。 
- #研究使用:https://huggingface.co/datasets /GAIR/MathPile
- 商業版本:https://huggingface.co/datasets/GAIR/MathPile_Commercial
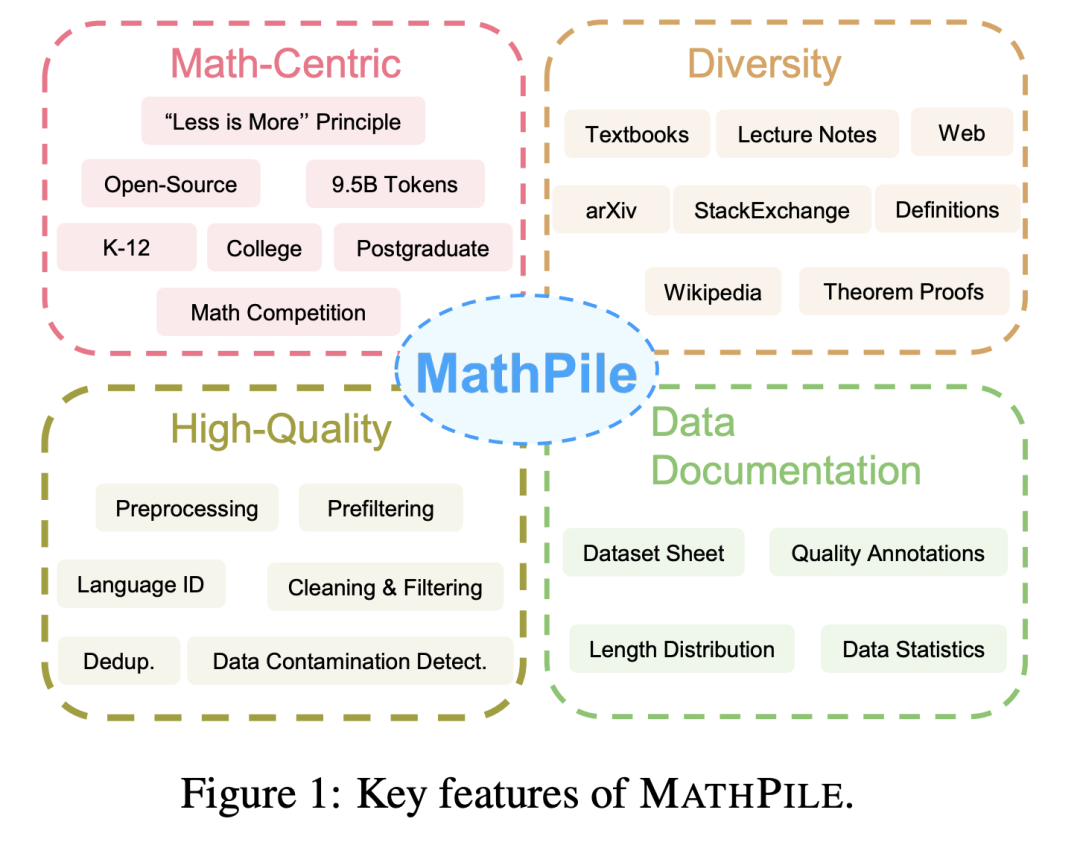
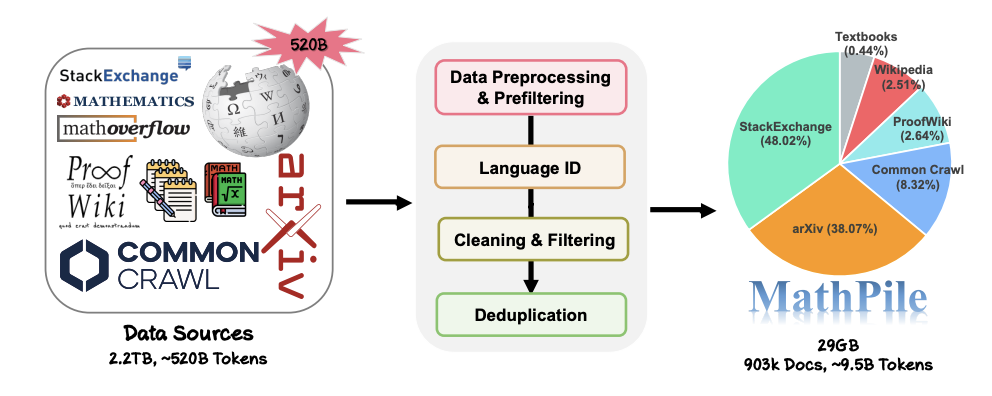
1. 以數學為中心:不同於過去專注於通用領域的語料,如 Pile, RedPajama, 或多語言語料ROOTS 等等,MathPile 專注於數學領域。雖然目前已經有一些專門的數學語料,但要不是沒有開源(例如 Google 用來訓練 Minerva 的語料,OpenAI 的 MathMix),要嘛不夠豐富多樣(例如 ProofPile 和最近的 OpenWebMath)。 2. 多樣性:MathPile 的資料來源廣泛,例如公開開源的數學教科書,課堂筆記,合成的教科書,arXiv 上的數學相關的論文,Wikipedia 上關於數學相關的條目,ProofWiki 上的引理證明和定義,StackExchange(社區問答網站)上的高質量數學問題和答案,以及來自Common Crawl 上的數學網頁。以上內容涵蓋了適合中小學,大學,研究生以及數學競賽等內容。 MathPile 首次涵蓋了 0.19B tokens 的高品質數學教科書。 3. 高品質:研究團隊在收集過程中遵循「less is more」(少即是多) 的理念,堅信資料質量優於數量,即使在預訓練階段也是如此。他們從~520B tokens(大約 2.2TB)的資料來源中,經過一套嚴謹複雜的預處理,預先過濾,語言識別,清潔,過濾和去重等步驟,來確保語料庫的高品質。值得一提的是,OpenAI 所用的 MathMix 也只有 1.5B tokens。 4. 資料文檔化:為了增加透明度,研究團隊對 MathPile 進行了文件記錄,提供了 dataset sheet。在資料處理過程中,研究團隊也對來自 Web 的文檔進行了「品質標註」。例如,語言辨識的分數,文件中符號與單字的比例,方便研究者根據自身需求進一步過濾文件。他們還對語料進行了下游測試集的污染檢測,來消除像來自 MATH,MMLU-STEM 這樣的基準測試集中的樣本。同時,研究團隊也發現了 OpenWebMath 中也存在大量的下游測試樣本,這說明在製作預訓練語料時應該格外小心,避免下游的評測失效。
MathPile 的資料收集和處理過程。
#
在大模型領域競爭愈演愈烈的今天,許多科技公司都不再公開他們的數據,還有他們的資料來源,配比,更不用說詳細的預處理細節。相反,MathPile 在前人探索的基礎上總結了一套適用 Math 領域的資料處理方法。 在資料的清洗和過濾部分,研究團隊採用的具體步驟是:
- ##偵測包含「lorem ipsum」的行,如果將行中「lorem ipsum」替換掉少於5 個字符,便移除該行;
- 偵測包含「javescript 」且同時包含「enable」,「disable」或「browser」 的行,且該行的字元數量小於200 字符,便過濾掉該行;
##過濾掉少於10 個字並且包含「Login」, “sign-in”, “read more...”, 或 “items in cart” 的行;過濾掉大寫單字佔比超過40% 的文件;過濾掉以省略號結尾的行佔比整個文件超過30% 的文件;過濾掉非字母單字的比例超過80% 的文檔;過濾掉文檔平均英文單字字元長度介於(3,10)區間以外的文檔;過濾掉不包含至少兩個停用詞(如the, be, to, of, and, that, have 等)的文檔;過濾掉省略號與單字比例超過50% 的文件;過濾掉項目符號開始的行佔比超過90% 的文件;過濾掉移除掉空格和標點符號後少於200 個字元的文件;...
此外,研究團隊也提供了許多清洗過程中的資料範例。下圖為透過 MinHash LSH 演算法去重檢測出來的 Common Crawl 中的近似重複的文檔(如粉紅色高亮處所示)。 如下圖所示,研究團隊在進行資料外洩偵測過程中發現了來自 MATH 測試集的問題(如黃色高亮處所示)。
資料集統計與範例
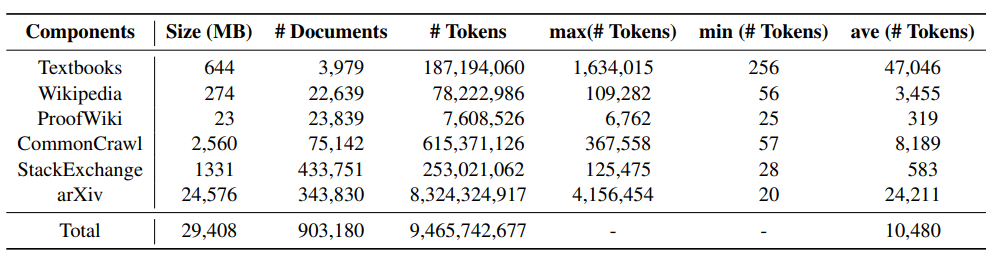
#下表展示了MathPile 各個組成部分的統計信息,可以發現arXiv 論文,教科書通常文檔長度較長,wiki 上的文檔相對偏短。
下圖是 MathPile 語料中一個教科書的範例文檔,可以看出其中的文檔結構較為清晰,品質較高。
實驗結果
研究團隊也揭露了一些初步的實驗結果。他們在目前頗受歡迎的 Mistral-7B 模型的基礎上進行了進一步的預訓練。接著透過少量樣本提示(few-shot prompting)方法,在一些常見的數學推理基準資料集上進行了評估。目前已獲得的初步實驗數據如下:
這些測試基準涵蓋了各個層次的數學知識,包括小學數學(例如GSM8K、TAL-SCQ5K-EN 和MMLU- Math),高中數學(如MATH、SAT-Math、MMLU-Math、AQuA 和MathQA),以及大學數學(例如MMLU-Math)。研究團隊初步發表的實驗結果顯示,透過在 MathPile 中的教科書和維基百科子集上進行繼續預訓練,語言模型在不同難度級別的數學推理能力上均實現了比較可觀的提升。
研究團隊也強調,相關實驗仍在持續進行中。
結語
MathPile 自發布之日起便受到了廣泛關注,並被多方轉載,目前更是榮登 Huggingface Datasets 趨勢榜單。研究團隊表示,他們將持續對資料集進行最佳化和升級,進一步提升資料品質。
MathPile 登 Huggingface Datasets 趨勢名單。 MathPile 被知名 AI 部落客 AK 轉發,圖片來源:https://twitter.com/_akhaliq/status/1740571256234057798。
目前,MathPile 已更新至第二版,旨在為開源社群的研究發展做出貢獻。同時,其商業版資料集也已向公眾開放。
以上是為大模型惡補數學,交開源MathPile語料庫,95億tokens,還可商用的詳細內容。更多資訊請關注PHP中文網其他相關文章!


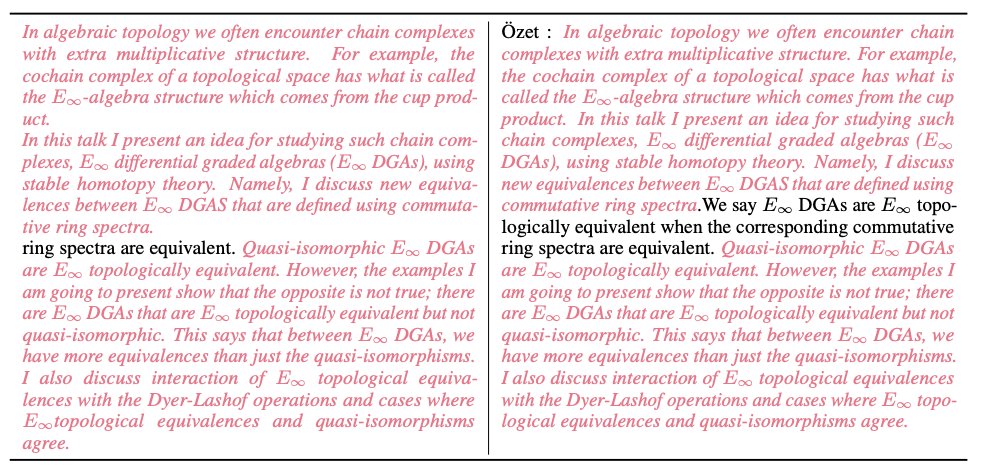 如下圖所示,研究團隊在進行資料外洩偵測過程中發現了來自 MATH 測試集的問題(如黃色高亮處所示)。
如下圖所示,研究團隊在進行資料外洩偵測過程中發現了來自 MATH 測試集的問題(如黃色高亮處所示)。 

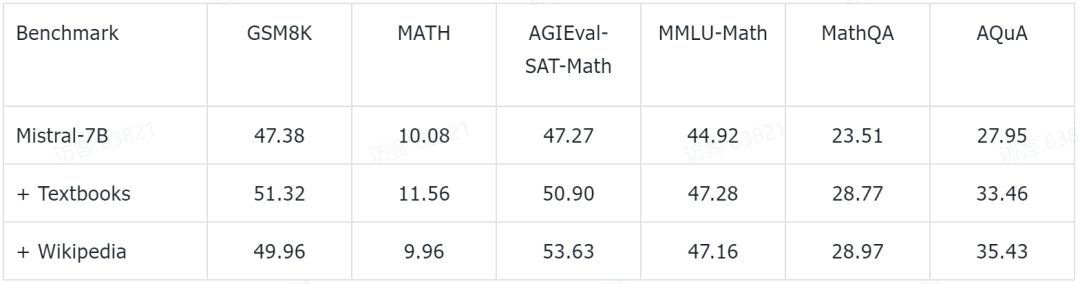 這些測試基準涵蓋了各個層次的數學知識,包括小學數學(例如GSM8K、TAL-SCQ5K-EN 和MMLU- Math),高中數學(如MATH、SAT-Math、MMLU-Math、AQuA 和MathQA),以及大學數學(例如MMLU-Math)。研究團隊初步發表的實驗結果顯示,透過在 MathPile 中的教科書和維基百科子集上進行繼續預訓練,語言模型在不同難度級別的數學推理能力上均實現了比較可觀的提升。
這些測試基準涵蓋了各個層次的數學知識,包括小學數學(例如GSM8K、TAL-SCQ5K-EN 和MMLU- Math),高中數學(如MATH、SAT-Math、MMLU-Math、AQuA 和MathQA),以及大學數學(例如MMLU-Math)。研究團隊初步發表的實驗結果顯示,透過在 MathPile 中的教科書和維基百科子集上進行繼續預訓練,語言模型在不同難度級別的數學推理能力上均實現了比較可觀的提升。