

Transformer 強大的泛化能力再次證明!
近年來,基於Transformer的結構在各種任務中展現出色的性能,引起了全球的關注。利用這種結構並結合大量數據,產生的大型語言模型(LLM)等模型可以很好地適用於實際應用場景。
儘管在某些領域取得了成功,但基於 Transformer 的結構和 LLM 仍然面臨挑戰,尤其是在處理規劃和推理任務方面。先前的研究表明,LLM 在應對多步驟規劃任務或高階推理任務時存在困難。
為了提升 Transformer 的推理和規劃性能,近年來研究社群也提出了一些方法。一個最常見且有效的方法是模擬人類的思考過程:先生成中間「思維」,然後再輸出回應。例如思考鏈(CoT)提示法就是鼓勵模型預測中間步驟,進行步驟的「思考」。思考樹(ToT)則使用了分支策略和評判方法,讓模型產生多個不同的思考路徑,然後從中選出最佳路徑。儘管這些技術通常是有效的,但也有研究表明,在許多案例中,這些方法會讓模型的表現下降,原因包括自我強制(self-enforcing)。
在某個資料集上表現良好的技術,可能在處理其他資料集時效果不佳。這可能是因為所需的推理類型發生了變化,例如從空間推理轉變為數學推理或常識推理。
相較之下,傳統的符號規劃和搜尋技術展現了出色的推理能力。此外,這些傳統方法所計算出的解決方案通常擁有形式上的保證,因為符號規劃演算法通常遵循著明確定義的基於規則的搜尋過程。
為了讓 Transformer 具備複雜推理能力,Meta FAIR 田徑棟團隊近日提出了 Searchformer。

論文標題:Beyond A∗: Better Planning with Transformers via Search Dynamics Bootstrapping
#論文地址:https://arxiv.org/pdf/2402.14083.pdf
Searchformer 是一種Transformer 模型,但針對迷宮導航和推箱子等多步驟規劃任務,它卻能計算出最優規劃且所用搜尋步驟數也能遠少於A∗ 搜尋等符號規劃演算法。
為了做到這一點,團隊提出了一種新方法:搜尋動態引導(search dynamics bootstrapping)。此方法首先是訓練一個Transformer 模型來模仿A∗ 的搜尋過程(如圖1 所示,然後對其進行微調,使其能用更少的搜尋步數找到最優規劃。

#更詳細地說,第一步,訓練一個模仿A∗ 搜尋的Transformer 模型。在這裡,該團隊的做法是針對隨機生成的規劃任務實例執行A* 搜尋。在執行A∗時,團隊會記錄執行的計算和最優規劃並將其整理成詞序列,即token。這樣一來,所得到的訓練資料集就包含了A∗ 的執行軌跡並編碼了有關A∗ 本身的搜尋動態的資訊。然後,訓練一個Transformer 模型,讓其能針對任意規劃任務沿最優規劃生成這些token 序列。
第二步,使用專家迭代(expert iteration)方法進一步提升使用上述經過搜尋增強的序列(包含A∗ 的執行軌跡)訓練的Searchformer。專家迭代方法可讓Transformer 憑藉較少的搜尋步驟產生最佳解。這個過程會得到一種神經規劃演算法,其隱含編碼在該Transformer 的網路權重之中,且它有很高的機率以少於A∗ 搜尋的搜尋步數找到最優規劃。比如說,在執行推箱子任務時,新模型能解答93.7% 的測試任務,同時搜尋步數比A∗ 搜尋平均少26.8%。
該團隊表示:這為Transformer 超越傳統符號規劃演算法鋪平了道路。
##實驗
#為了更好地理解訓練資料和模型參數量對所得模型表現的影響,他們進行了一些消融研究。他們使用了兩類資料集訓練模型:一種的token序列中只包含解(solution-only,其中只有任務描述和最終規劃);另一種則是搜尋增強型序列(search-augmented,其中包含任務描述、搜尋樹動態和最終規劃)。實驗中,團隊使用了A∗ 搜尋的一種確定性和非確定性變體來產生每個序列資料集。##迷宮導航######################################################## #在第一個實驗中,團隊訓練了一組編碼器- 解碼器Transformer 模型來預測30×30 迷宮中的最優路徑。###
圖 4 表明,透過預測中間計算步驟,可在資料量少時獲得更穩健的效能表現。
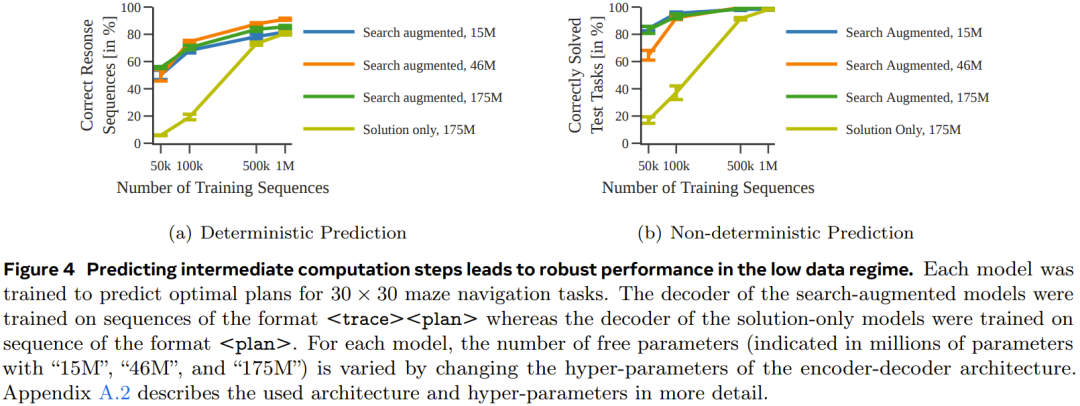
圖 5 給出了僅使用解訓練的模型的表現。
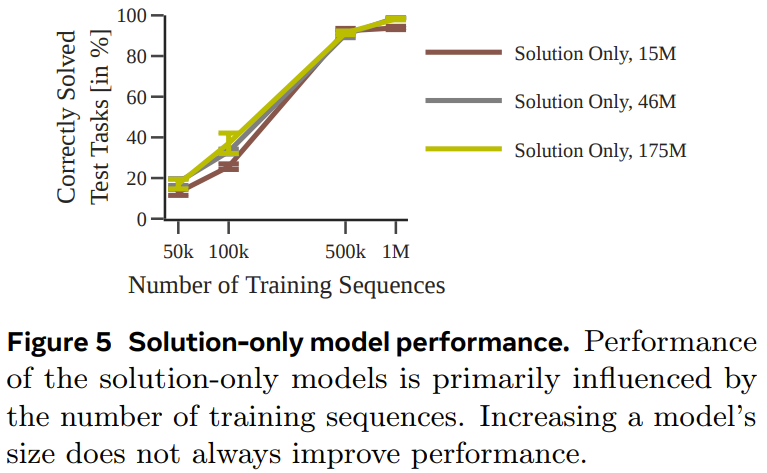
圖 6 展示了任務難度對每個模型的表現的影響。
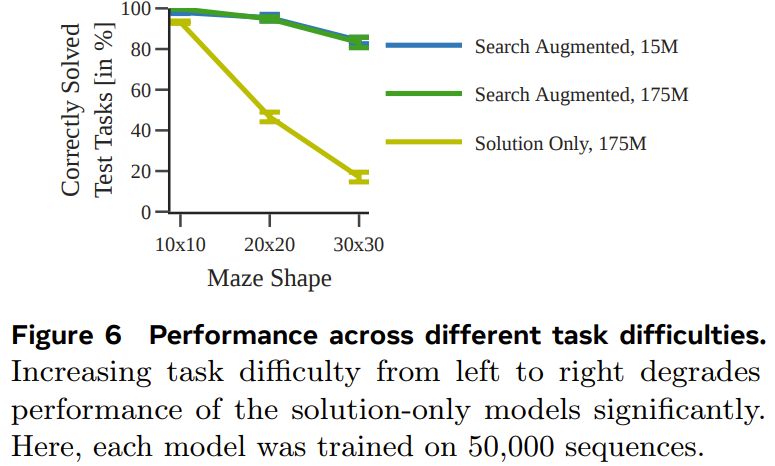
整體而言,儘管當使用的訓練資料集足夠大且足夠多樣化時,僅使用解訓練的模型也能預測得到最優規劃,但當數據量少時,經過搜尋增強的模型的表現明顯好得多,並且也能更好地擴展用於更困難的任務。
推盒子

為了測試能否在不同且更複雜的任務(具有不同的token 化模式)上得到類似的結果,團隊也產生了一個推箱子的規劃資料集進行測試。
圖 7 展示了每種模型針對每個測試任務產生正確規劃的機率。
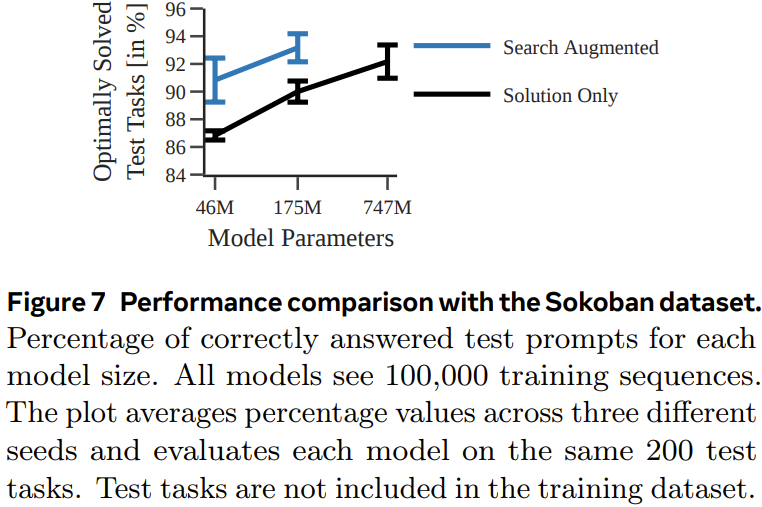
可以看到,和上一個實驗一樣,透過使用執行軌跡進行訓練,搜尋增強型模型的表現優於僅使用解訓練的模型。
Searchformer:透過引導方法提升搜尋動態
最後一個實驗,該團隊研究了搜尋增強模型可以如何迭代提升,從而憑藉更少的搜尋步數計算出最優規劃。這裡的目標是在縮短搜尋軌跡長度的同時依然得到最優解。
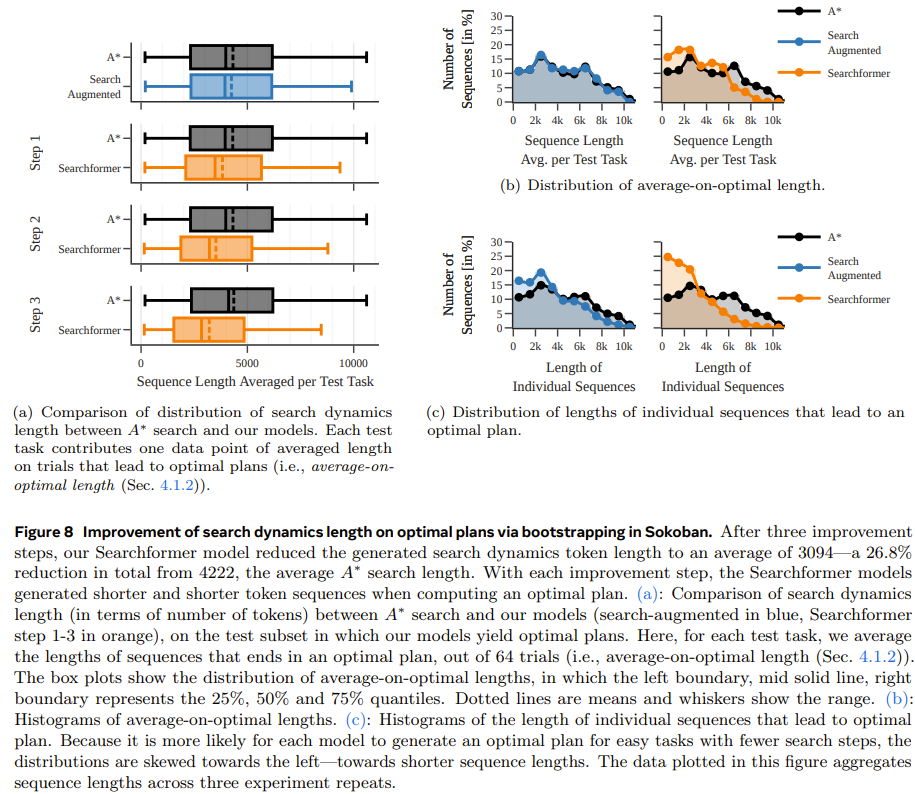
圖 8 表明,新提出的搜尋動態引導方法能夠迭代式地縮短 Searchformer 模型產生的序列的長度。
以上是補齊Transformer規劃短板,田徑棟團隊的Searchformer火了的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















