2 月 16 日,OpenAI Sora 的發布無疑標誌著影片生成領域的重大突破。 Sora 是基於 Diffusion Transformer 架構,和市面上大部分主流方法(由 2D Stable Diffusion 擴展)並不相同。 為什麼Sora 堅持使用Diffusion Transformer,其中的原因從同時期發表在ICLR 2024(VDT: General-purpose Video Diffusion Transformers via Mask Modeling)的論文可以窺見一二。 這項工作由中國人民大學研究團隊主導,並與加州大學柏克萊分校、香港大學等進行了合作,最早於2023 年5 月公開在arXiv 網站。研究團隊提出了基於 Transformer 的 Video 統一生成框架 - Video Diffusion Transformer (VDT),並對採用 Transformer 架構的原因給出了詳細的解釋。 
- 論文標題:VDT: General-purpose Video Diffusion Transformers via Mask Modeling
- 文章地址: Openreview: https://openreview.net/pdf?id=Un0rgm9f04
- #arXiv網址: https://arxiv.org/abs/2305.13311
- #專案地址:VDT: General-purpose Video Diffusion Transformers via Mask Modeling
- 程式碼位址:https://github.com/RERV/VDT
研究者表示,採用Transformer 架構的VDT 模型,在視訊生成領域的優越性體現在:
- 與主要為影像設計的U-Net 不同,Transformer 能夠借助其強大的token 化和注意力機制,捕捉長期或不規則的時間依賴性,從而更好地處理時間維度。
- 只有當模型學習(或記憶)了世界知識(例如空間時間關係和物理法則)時,才能產生與現實世界相符的影片。因此,模型的容量成為視訊擴散的關鍵組成部分。 Transformer 已被證明具有高度的可擴展性,例如PaLM 模型就擁有高達540B 的參數,而當時最大的2D U-Net 模型大小僅2.6B 參數(SDXL),這使得Transformer 比3D U-Net 更適合應對影片生成的挑戰。
- 影片產生領域涵蓋了包括無條件生成、視訊預測、插值和文字到圖像生成等多項任務。過去的研究往往聚焦於單一任務,常常需要為下游任務引入專門的模組進行微調。此外,這些任務涉及多種多樣的條件訊息,這些資訊在不同幀和模態之間可能有所不同,這需要一個能夠處理不同輸入長度和模態的強大架構。 Transformer 的引入能夠實現這些任務的統一。
- 將Transformer 技術應用於基於擴散的視訊生成,展現了Transformer 在視訊生成領域的巨大潛力。 VDT 的優勢在於其出色的時間依賴性擷取能力,能夠產生時間上連貫的視訊幀,包括模擬三維物件隨時間的物理動態。
- 提出統一的時空掩碼建模機制,使VDT 能夠處理多種視訊生成任務,實現了技術的廣泛應用。 VDT 靈活的條件資訊處理方式,如簡單的 token 空間拼接,有效地統一了不同長度和模態的資訊。同時,透過與該工作提出的時空掩碼建模機制結合,VDT 成為了一個通用的視訊擴散工具,在不修改模型結構的情況下可以應用於無條件生成、視訊後續幀預測、插幀、圖生影片、影片畫面補全等多種影片生成任務。
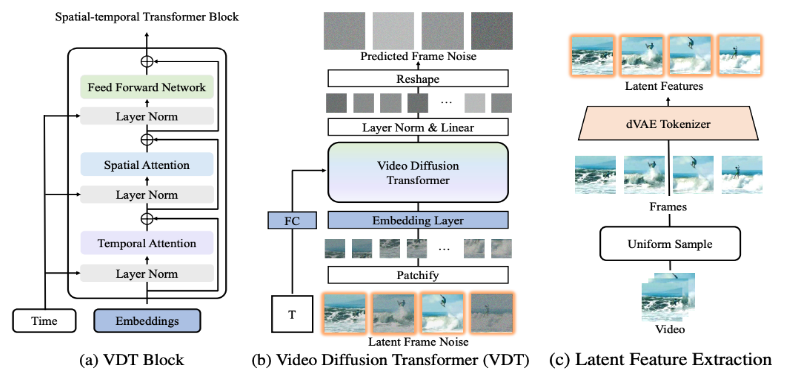
#
VDT 框架與 Sora 的框架非常相似,包括以下幾部分:輸入 / 輸出特徵。 VDT 的目標是產生一個 F×H×W×3 的影片片段,由 F 幀大小為 H×W 的影片組成。然而,如果使用原始像素作為 VDT 的輸入,尤其是當 F 很大時,將導致計算量極大。為解決這個問題,受潛在擴散模型(LDM)的啟發,VDT 使用預先訓練的 VAE tokenizer 將視訊投影到潛在空間中。將輸入和輸出的向量維度減少到潛在特徵/ 雜訊的F×H/8×W/8×C,加速了VDT 的訓練和推理速度,其中F 幀潛在特徵的大小為H/8×W/8 。這裡的 8 是 VAE tokenizer 的下取樣率,C 表示潛在特徵維度。 線性嵌入。遵循 Vision Transformer 的方法,VDT 將潛在視訊特徵表示劃分為大小為 N×N 的非重疊 Patch。 時空 Transformer Block。受到視訊建模中時空自註意力成功的啟發,VDT 在 Transformer Block 中插入了一個時間注意力層,以獲得時間維度的建模能力。具體來說,每個 Transformer Block 由一個多頭時間注意力、一個多頭空間注意力和一個全連接前饋網路組成,如上圖所示。 比較 Sora 最新發布的技術報告,可以看到 VDT 和 Sora 在實作細節上僅存在一些細微差別。 首先,VDT 採用的是時空維度上分別進行注意力機制處理的方法,而Sora 則是將時間和空間維度合併,透過單一的注意力機制來處理。這種分離注意力的做法在影片領域已經相當常見,通常被視為在顯存限制下的一種妥協選擇。 VDT 選擇採用分離注意力也是出於計算資源有限的考量。 Sora 強大的視訊動態能力可能來自於時空整體的注意力機制。 其次,不同於 VDT,Sora 也考慮了文字條件的融合。之前也有基於Transformer 進行文本條件融合的研究(如DiT),這裡猜測Sora 可能在其模組中進一步加入了交叉注意力機制,當然,直接將文本和噪聲拼接作為條件輸入的形式也是一種潛在的可能。 在 VDT 的研究過程中,研究者將 U-Net 這個常用的基礎骨幹網路替換為 Transformer。這不僅驗證了 Transformer 在視訊擴散任務中的有效性,展現了便於擴展和增強連續性的優勢,也引發了他們對其潛在價值的進一步思考。 隨著GPT 模型的成功和自回歸(AR)模型的流行,研究者開始探索Transformer 在視訊生成領域的更深層次應用,思考其是否能為實現視覺智能提供新的途徑。視訊生成領域有一個與之密切相關的任務 —— 影片預測。將預測下一個視訊幀作為通往視覺智慧的路徑這一想法看似簡單,但它實際上是許多研究者共同關注的問題。 基於這個考慮,研究者希望在影片預測任務上進一步適配和最佳化他們的模型。視訊預測任務也可以視為條件生成,這裡給定的條件幀是影片的前幾幀。 VDT 主要考慮了以下三種條件產生方式: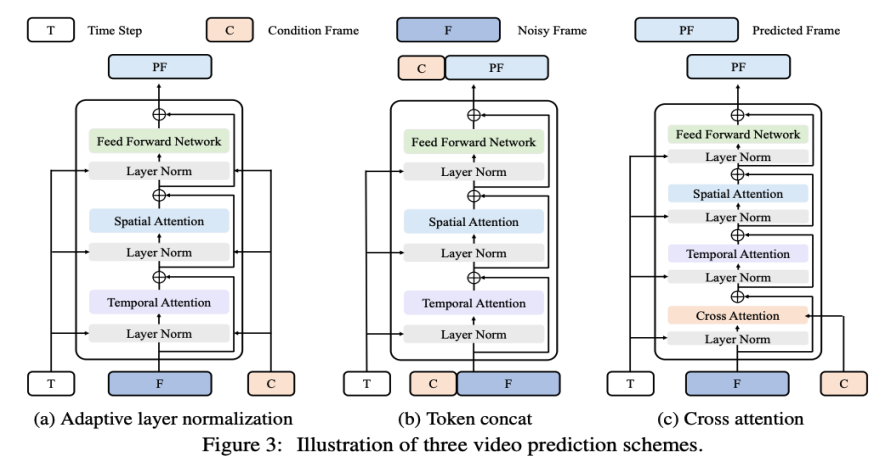
#
自適應層歸一化。實現視訊預測的一種直接方法是將條件幀特徵整合到 VDT Block 的層歸一化中,類似於我們如何將時間資訊整合到擴散過程中。 交叉注意力。研究者還探索了使用交叉注意力作為視訊預測方案,其中條件幀用作鍵和值,而噪聲幀作為查詢。這允許將條件資訊與噪聲幀融合。在進入交叉注意力層之前,使用 VAE tokenizer 提取條件幀的特徵並 Patch 化。同時,還添加了空間和時間位置嵌入,以幫助我們的 VDT 學習條件幀中的對應資訊。 Token 拼接。 VDT 模型採用純粹的 Transformer 架構,因此,直接使用條件幀作為輸入 token 對 VDT 來說是更直觀的方法。研究者透過在 token 層級拼接條件影格(潛在特徵)和雜訊影格來實現這一點,然後將其輸入到 VDT 中。接下來,他們將 VDT 的輸出幀序列分割,並使用預測的幀進行擴散過程,如圖 3 (b) 所示。研究者發現,這種方案展示了最快的收斂速度,與前兩種方法相比,在最終結果上提供了更優的表現。此外,研究者發現即使在訓練過程中使用固定長度的條件幀,VDT 仍然可以接受任意長度的條件幀作為輸入,並輸出一致的預測特徵。 在 VDT 的框架下,為了實現視訊預測任務,不需要對網路結構進行任何修改,只需改變模型的輸入即可。這項發現引出了一個直觀的問題:我們能否進一步利用這種可擴展性,將VDT 擴展到更多樣化的視訊生成任務—— 例如圖片生成視訊——而無需引入任何額外的模組或參數。 透過回顧 VDT 在無條件產生和視訊預測中的功能,唯一的差異在於輸入特徵的類型。具體來說,輸入可以是純雜訊潛在特徵,或是條件和雜訊潛在特徵的拼接。然後,研究者引入了 Unified Spatial-Temporal Mask Modeling 來統一條件輸入,如下圖 4 所示: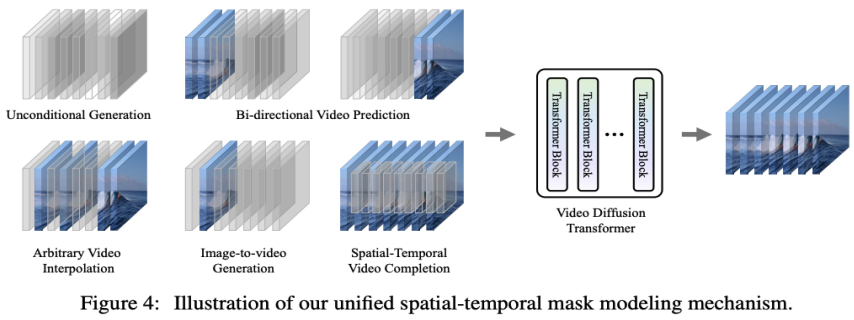
透過上述方法,VDT 模型不僅可以無縫地處理無條件影片產生和影片預測任務,還能夠透過簡單地調整輸入特徵,擴展到更廣泛的視訊生成領域,如視訊幀插值等。這種靈活性和可擴展性的體現,展示了 VDT 框架的強大潛力,為未來的視訊生成技術提供了新的方向和可能性。

有趣的是,除text-to-video 外,OpenAI 還展示了Sora 非常驚人的其他任務,包括基於image 生成,前後video predict 以及不同video clip相融合的例子等,和研究者提出的Unified Spatial-Temporal Mask Modeling 所支援的下游任務非常相似;同時在參考文獻中也引用了kaiming 的MAE。所以,這裡猜測 Sora 大概率底層也使用了類 MAE 的訓練方法。
研究者同時探討了產生模型 VDT 對簡單物理規律的模擬。他們在 Physion 資料集上進行實驗,VDT 使用前 8 幀作為條件幀,並預測接下來的 8 幀。在第一個範例(頂部兩行)和第三個範例(底部兩行)中,VDT 成功地模擬了物理過程,包括一個沿著拋物線軌跡運動的球和一個在平面上滾動並與圓柱體碰撞的球。在第二個範例(中間兩行)中,VDT 捕捉到了球的速度 / 動量,因為球在碰撞圓柱體前停了下來。這證明了 Transformer 架構是可以學習到一定的物理規律。

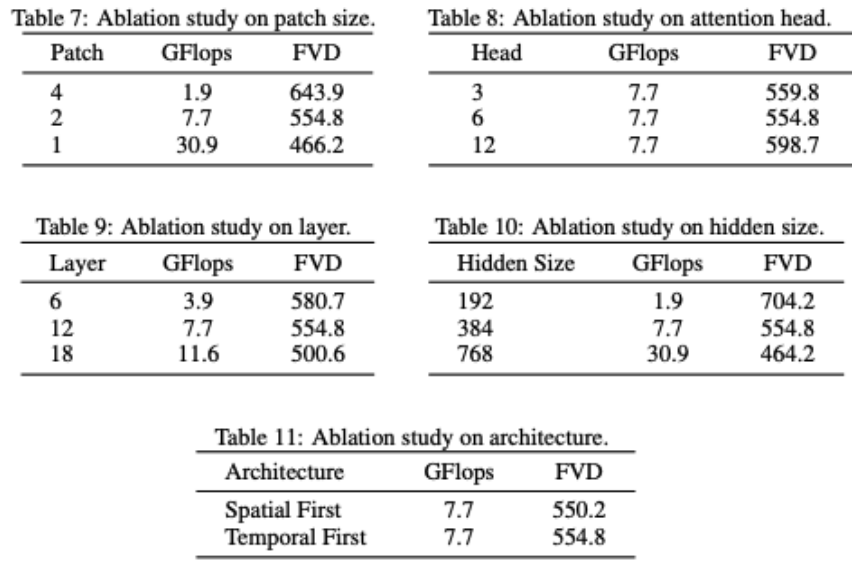 VDT 对网络结构进行部分消融。可以发现模型性能和 GFlops 强相关,模型结构本身的一些细节反而影响不是很大,这个和 DiT 的发现也是一致的。研究者还对 VDT 模型进行了一些结构上的消融研究。结果表明,减小 Patchsize、增加 Layers 的数量以及增大 Hidden Size 都可以进一步提高模型的性能。Temporal 和 Spatial 注意力的位置以及注意力头的数量对模型的结果影响不大。在保持相同 GFlops 的情况下,需要一些设计上的权衡,总体而言,模型的性能没有显著差异。但是,GFlops 的增加会带来更好的结果,这展示了 VDT 或者 Transformer 架构的可扩展性。VDT 的测试结果证明了 Transformer 架构在处理视频数据生成方面的有效性和灵活性。由于计算资源的限制,VDT 只在部分小型学术数据集上进行了实验。我们期待未来研究能够在 VDT 的基础上,进一步探索视频生成技术的新方向和应用,也期待中国公司能早日推出国产 Sora 模型。
VDT 对网络结构进行部分消融。可以发现模型性能和 GFlops 强相关,模型结构本身的一些细节反而影响不是很大,这个和 DiT 的发现也是一致的。研究者还对 VDT 模型进行了一些结构上的消融研究。结果表明,减小 Patchsize、增加 Layers 的数量以及增大 Hidden Size 都可以进一步提高模型的性能。Temporal 和 Spatial 注意力的位置以及注意力头的数量对模型的结果影响不大。在保持相同 GFlops 的情况下,需要一些设计上的权衡,总体而言,模型的性能没有显著差异。但是,GFlops 的增加会带来更好的结果,这展示了 VDT 或者 Transformer 架构的可扩展性。VDT 的测试结果证明了 Transformer 架构在处理视频数据生成方面的有效性和灵活性。由于计算资源的限制,VDT 只在部分小型学术数据集上进行了实验。我们期待未来研究能够在 VDT 的基础上,进一步探索视频生成技术的新方向和应用,也期待中国公司能早日推出国产 Sora 模型。
以上是國內大學打造類Sora模型VDT,通用視訊擴散Transformer被ICLR 2024接收的詳細內容。更多資訊請關注PHP中文網其他相關文章!























